📗서론
모델의 학습 과정에서 발생하는 모든 log 데이터를 바탕으로 학습이 제대로 이루어 지고 있는지 판단하고 데이터 수정 및 파라미터 설정을 통해 최적의 모델로 만들어 보자
참고 : MLflow를 통한 모델 추적 및 관리
1. 너무 빠른 수렴
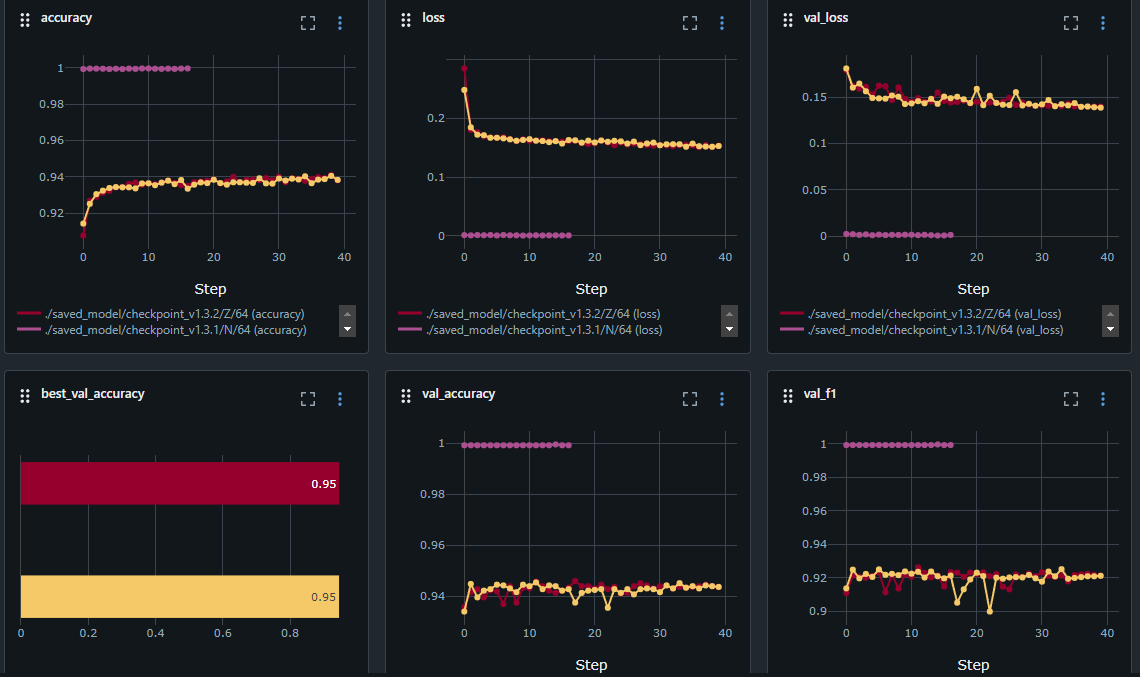
위의 사진에서 보라색 모델의 학습 과정을 보면 accuracy는 1로, loss와 val_loss는 0으로 몇 epoch 돌지 않았음에도 너무 빠르게 수렴하는 모습을 보이고 있다. 정확도가 높다고 해서 좋은 모델이라고 할 수는 없다.
1. 과적합: 모델이 훈련 데이터에 너무 잘 맞춰져서, 새로운 데이터(검증 데이터)에 대해 일반화하지 못할 수 있다. 이런 경우, 훈련 데이터에서의 성능은 높지만 실제 적용 시 성능이 저하될 수 있다.
2. 데이터의 질: 데이터셋이 너무 작거나 단순하여 모델이 쉽게 패턴을 학습할 수 있는 경우에도 이런 결과가 나올 수 있다.
3. 평가 지표의 신뢰성: 너무 높은 성능 지표는 종종 데이터셋에 문제가 있음을 나타낼 수 있다. 예를 들어, 레이블이 잘못되었거나 데이터가 중복된 경우.
4. 모델의 복잡도: 너무 복잡한 모델을 사용하면 데이터에 대해 과적합될 가능성이 높아진다.
- 해결책
1. 데이터셋 검토: 데이터의 품질과 양을 점검하고, 더 다양한 데이터로 학습 시도
2. 정규화 기법 사용: 드롭아웃이나 L2 정규화 등의 기법을 통해 모델의 일반화 성능을 높인다.
3. 검증 데이터 확인: 검증 데이터셋이 훈련 데이터와 겹치지 않는지 확인한다.
4. 하이퍼파라미터 튜닝: 모델의 복잡도를 조정하거나 다른 하이퍼파라미터를 조정한다.
2. validation loss가 튀거나 증가하는 현상
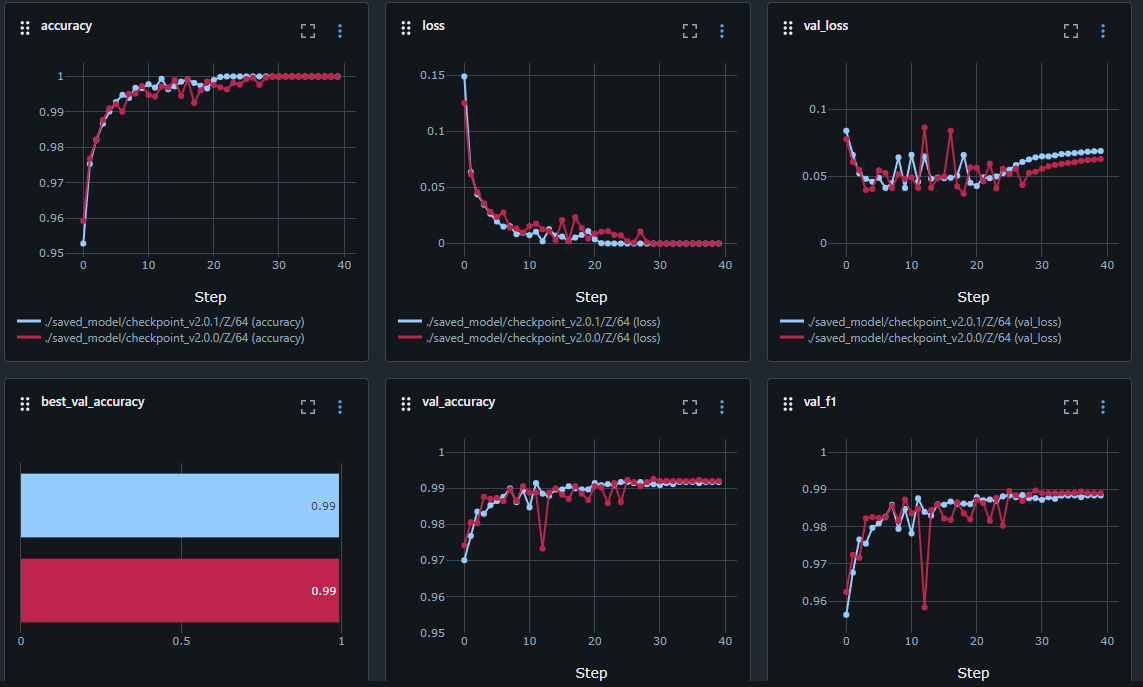
accuracy와 loss만 보면 어느정도 이상적인 학습이 진행된 것처럼 보이지만 val_loss를 보면 값이 튀다가 특정 구간에서부터 점점 증가하는 모습을 보인다.
1. 과적합: 모델이 훈련데이터에 너무 잘 적합되어 검증 데이터에 대한 일반화 성능이 떨어질 때 발생한다.
2. 훈련 데이터와 검증 데이터의 분포차이: 훈련 데이터와 검증 데이터가 다른 분포를 가지고 있는 경우 val_loss가 불안정하게 변동할 수 있다.
3. 하이퍼파라미터: 학습률(learning rate)이 너무 높거나 낮은경우 val_loss가 튈 수 있다. 너무 높은 학습률은 손실이 큰 변동성을 가져오고, 너무 낮은 학습률은 손실의 감소 속도가 느리다.
4. 배치 사이즈: 배치 크기가 너무 작으면 훈련 중에 발생하는 노이즈로 인해 손실 값의 변동폭이 커서 val_loss가 튀는 현상이 발생한다.
5. 데이터의 노이즈: 데이터셋에 노이즈가 많거나 잘못 라벨링된 샘플이 포함되어 있을 경우, 모델이 이를 학습하게 되어 val_loss가 튈 수 있다.
6. 모델의 복잡성: 모델이 너무 복잡하여 훈련 데이터에 맞춰 과적합되고, 검증 데이터에서는 성능이 떨어지는 경우
- 해결책
1. 데이터셋 검토: 더 많은 데이터로 훈련하거나 데이터 증강 기법을 사용하고, 드롭아웃과 L2정규화와 같은 정규화 기법을 적용하여 모델의 복잡성을 줄인다.
2. 데이터 분포 균형: 데이터셋이 균형 잡히고 대표성이 있도록 하여 두 데이터셋의 분포를 유사하게 만든다.
3. 학습률 조정: learning rate나 다른 최적화 알고리즘을 적용하여 시도해본다.
4. 배치크기 조정: 배치 크기를 늘리면 변동성을 줄일 수 있다.
5. 데이터 전처리: 데이터 전처리를 통해 이상치를 제거하거나 데이터를 정제하는 과정을 통해 최적의 데이터셋을 만든다.
6. 모델 구조 단순화: 모델이 너무 복잡한 경우 구조를 간소화 하거나 정규화를 추가하여 과적합을 방지한다.
