[Paper review] Top-N Recommendation with Counterfactual User Preference Simulation (CIKM'21)
1. 요약
Top-N 추천은 사용자의 순위 기반 선호도를 학습하는 것을 목표로 하며, 다양한 응용 분야에서 오랫동안 기본적인 문제로 여겨져 왔다. 전통적인 모델들은 주로 다양한 가정에 기반한 복잡하거나 맞춤형 아키텍처를 설계함으로써 자신들을 동기화한다.하지만, 추천 시스템의 훈련 데이터는 매우 희소하고 불균형할 수 있어, 추천 성능을 향상시키는 데 큰 도전이 된다.
이 문제를 완화하기 위해, 본 논문에서는 인과 추론 프레임워크 내에서 추천 작업을 재구성하는 것을 제안한다. 이는 데이터 부족 문제를 처리하기 위해 사용자의 순위 기반 선호도를 카운터팩츄얼하게 시뮬레이션할 수 있게 한다. 이 모델의 핵심은 카운터팩츄얼 질문에 있습니다: "추천된 아이템이 달랐다면 사용자의 결정은 어떻게 되었을까?". 이 질문에 답하기 위해, 저자는 관찰된 데이터를 기반으로 최적화된 매개변수를 가진 일련의 구조 방정식 모델(SEMs)로 추천 과정을 처음으로 정식화한다. 그 다음, 데이터셋에 기록되지 않은 많은 추천 리스트(인과 추론 용어로는 개입이라고 함)를 적극적으로 지시하고, 새로운 훈련 샘플을 생성하기 위해 학습된 SEMs에 따라 사용자 피드백을 시뮬레이션한다.
또한, 저자는 무작위로 추천 리스트에 개입하는 대신, 더 유익한 훈련 샘플을 발견하기 위한 학습 기반 방법을 설계한다. 학습된 SEMs가 완벽하지 않을 수 있기 때문에, 마지막으로, 생성된 샘플의 수와 모델 예측 오류 사이의 관계를 이론적으로 분석하고, 예측 오류에 의해 가져온 부정적인 영향을 제어하기 위한 휴리스틱 방법을 설계한다. 본 프레임워크의 효과를 입증하기 위해 합성 및 실제 세계 데이터셋을 기반으로 광범위한 실험이 수행된다.
2. 기여 사항
이 논문의 주요 기여는 다음과 같이 요약된다:
- Pearl의 인과 추론 프레임워크 내에서 추천 문제를 정식화하여, 모델 최적화를 위해 더 많은 훈련 샘플을 생성할 수 있게 한다.
- 더 유익한 훈련 샘플을 생성하여 대상 순위 모델을 최적화할 수 있는 학습 기반 개입 방법을 설계한다.
- 구조 방정식 모델의 잠재적 예측 오류와 생성된 샘플 수 사이의 관계를 이론적으로 분석한다.
- 위 이론에 영감을 받아 생성된 샘플의 질을 제어하는 휴리스틱 방법을 제안한다.
- 합성 및 실제 세계 데이터셋을 기반으로 광범위한 실험을 수행하여 모델의 효과를 검증한다.
3. 방법
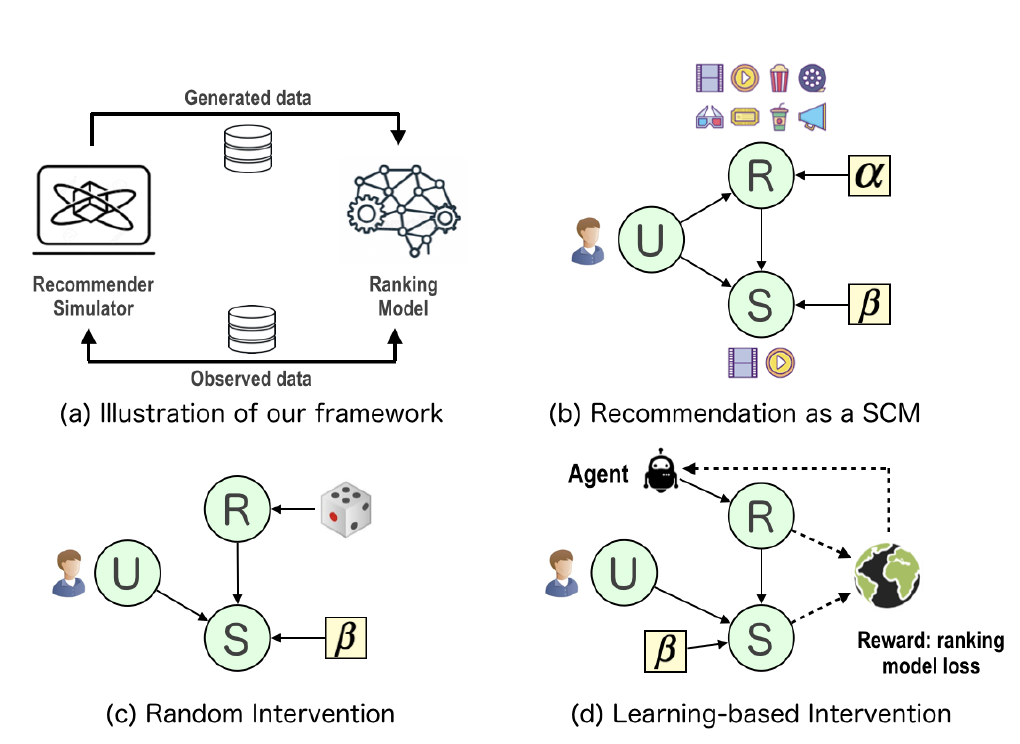
위 그림으로 이 논문의 알고리즘이 설명된다. U는 유저, R은 추천리스트, 그리고 S는 최종 선택한 아이템을 뜻한다. 일반적인 추천 과정을 SCM으로 모델링하면 (b)처럼 할 수 있다. 여기서 와 는 exogenous 변수로 실제로 우리가 관측할 수 없는 변수를 뜻한다. 인과추론 프레임워크의 첫번째 스텝은 prior distribution인 (은 관측데이터를 뜻함)을 밝혀내며 이때 변분추론 (variational inference) 기법을 사용한다. 그 다음 스텝은 개입을 통해 추천리스트를 생성하는 건데, (c)는 랜덤으로 추천리스트를 생성하는 것이고, (d)는 강화학습을 통해 생성하는 방법이다.
강화학습을 통한 추천리스트 뽑는 알고리즘을 기술하면 아래와 같다. 모든 강화학습이 그렇듯이 특정 액션을 설정한 다음 리워드를 관측하고 그 리워드를 최대화하는 방향으로 리스트를 뽑는다.

4. 실험 결과
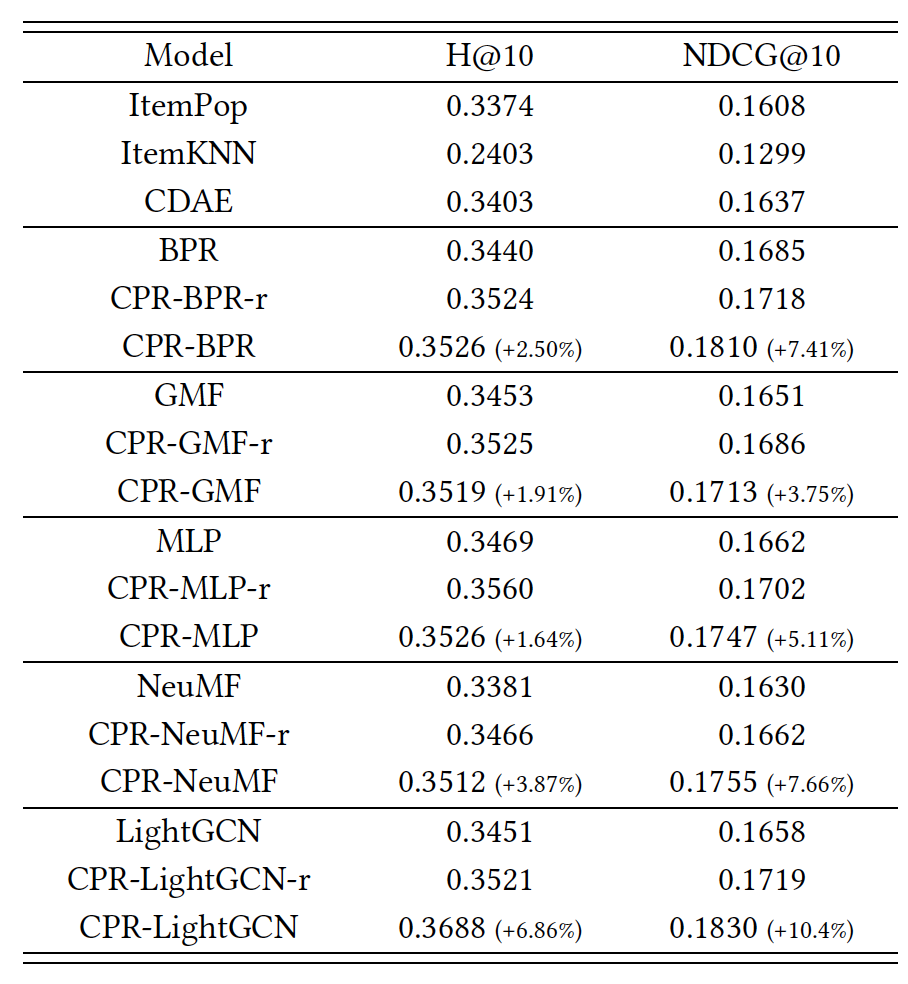
Synthetic 데이터셋에 대한 성능은 아래와 같다. -r이 붙어있는 모델은 랜덤으로 추천 리스트를 뽑은 모델이고 없는 것은 위의 강화학습 방법으로 추천 리스트를 뽑은 모델이다. 위 알고리즘은 model-agnostic한 방법으로 다양한 backbone 모델(BPR, GMF, MLP, NeuMF, LightGCN)에 대해서 실험을 진행하여 모든 모델에서 성능이 좋다는 걸 보여주고 있다. 측정 메트릭은 추천시스템에서 많이 사용되는 Hit Ratio (HR) and Normalized Discounted Cumulative
Gain (NDCG)을 사용했다. 전체적으로 랜덤 모델도 성능이 좋지만, 강화학습을 사용한 방법이 성능에 더 큰 개선이 있는 걸 볼 수 있다.
(참고로, CPR은 counterfactual personalized ranking의 약자이다.)
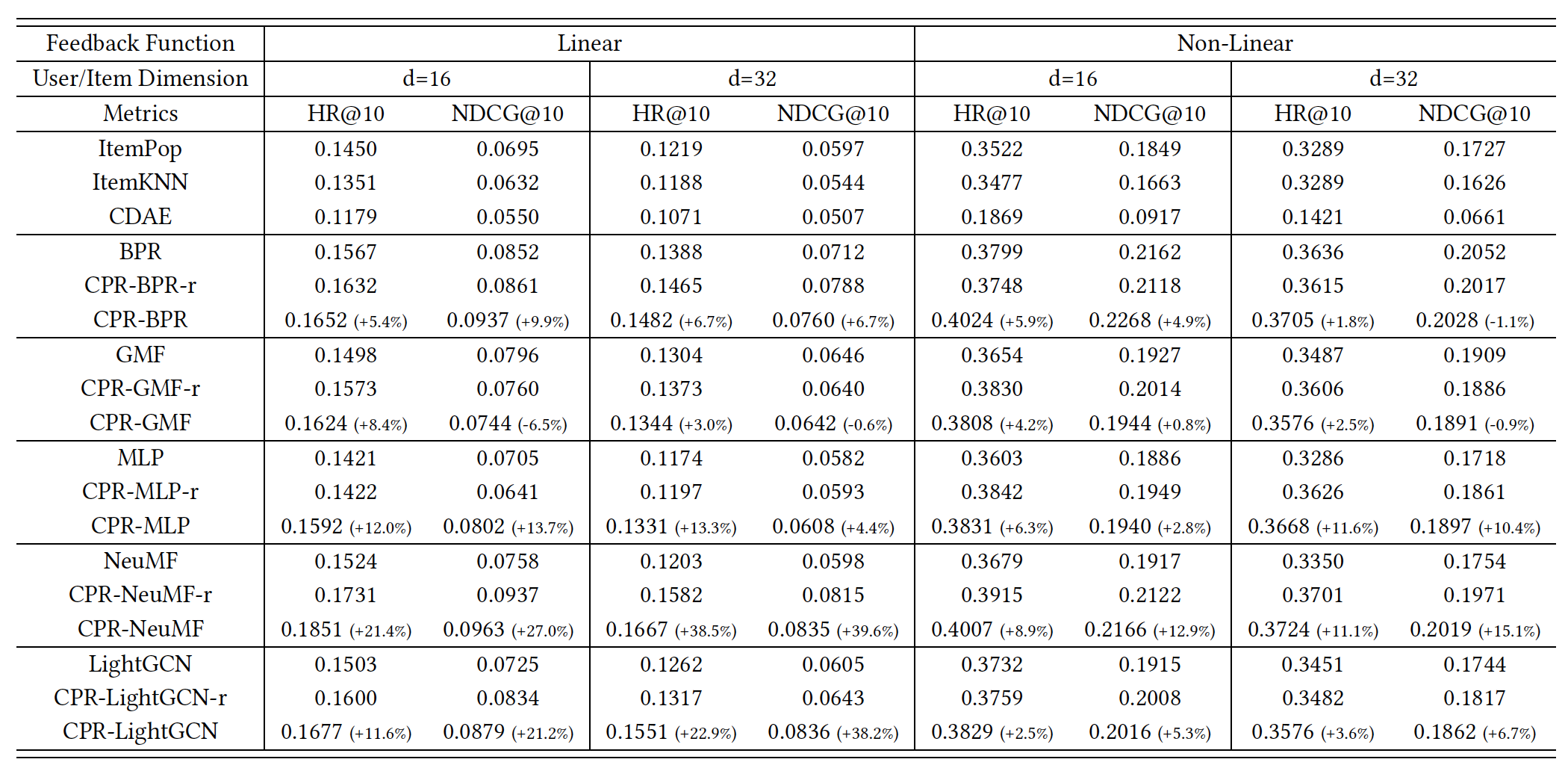
Real-world 데이터셋에 대한 성능은 아래와 같다. 어떤 backbone 모델에서는 랜덤 모델이 좋고, 다른 backbone 모델에서는 강화학습 모델이 성능이 좋은 것을 볼 수 있다.