인과추론 추천시스템 (Causal Inference in Recommender Systems) - 3장
1. 데이터 결측 해결 및 노이즈 제거
추천시스템에서 수집한 데이터는 보통 부족한데 이는 전체 아이템 풀에 비해서 유저의 참여도가 낮기 때문이다.
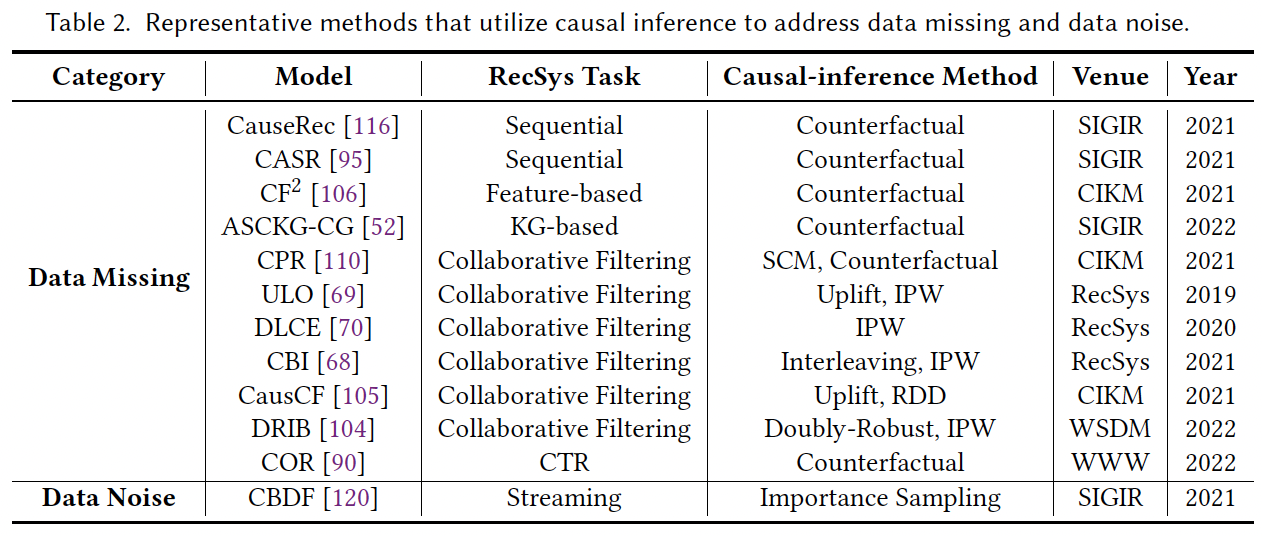
1) 인과추론을 활용한 데이터 결측 문제 해결: Counterfactual Data Augmentation
사용자와 항목 간 상호작용은 사실적인 데이터로, 추천 플랫폼에서 실제로 발생하는 일을 나타내며 사용자의 관심을 직접적으로 반영한다. 그러나 사실적 데이터는 일반적으로 부족하기 때문에, 추천 시스템이 데이터에 숨겨진 사용자 관심을 정확하게 파악하는 데는 충분하지 않다. 이때, 떠올려볼 수 있는 아이디어는 "실제로 일어나지 않은 더 많은 샘플을 생성하여 훈련 데이터를 보강하는 것" 이다. 이러한 데이터 증강은 반사실적인 세계에서 "만약 A이면 어떻게 될 것인가"라는 질문에 답하는 것을 목표로 하며, 이는 컴퓨터 비전 및 자연어 처리와 같은 여러 연구 분야에서 채택되었다. 추천 측면에서는 반사실적 데이터 증강이 사실적 데이터가 수집된 실제 경우와 다른 상황에서 더 많은 상호작용을 생성하는 것을 목표로 한다.
-
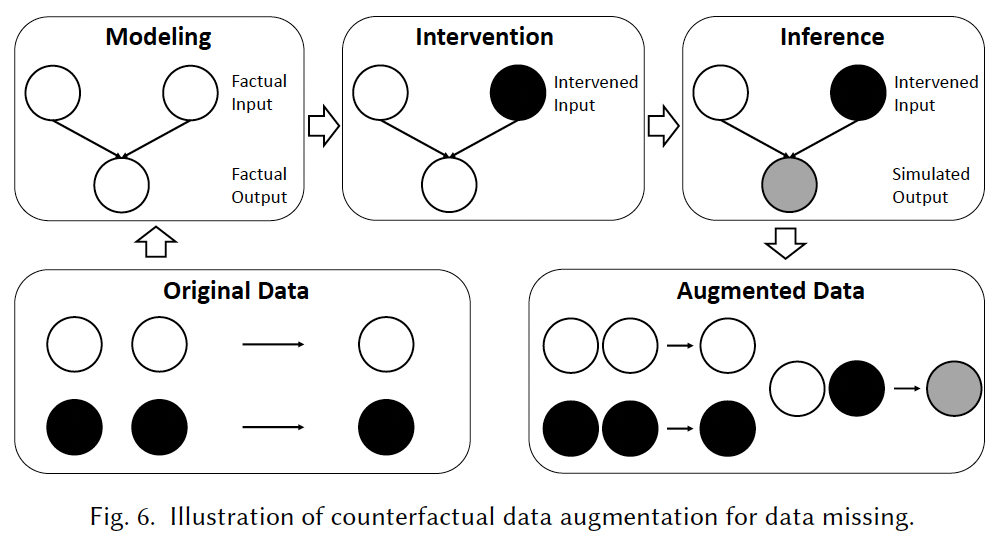
Modeling
요약: 이 단계에서는 데이터 생성 프로세스(data generating process)를 캡처하며 우리가 흔히 사용하는 머신러닝 모델로 관측한 데이터를 학습시킨다.
구체적으로, 이 단계는 추천 모델 자체 또는 다른 독립적인 모델일 수 있는 데이터 생성 프로세스를 캡처하며, 일반적으로 사실적인 데이터에 맞게 훈련된 매개변수 모델(parametric model)을 사용한다. 다시 말해, 사실적 데이터에 존재하는 특정 사용자 및 항목이 주어지면, 모델은 관찰된 상호작용으로 훈련되어 나중에 관찰되지 않은 상호작용을 생성하는 시뮬레이터 역할을 한다. 시뮬레이터는 일반적인 추천 테스크처럼 기존의 실제 데이터로 훈련된다. 훈련이 잘 된 시뮬레이터가 얻어지면 추론(inference) 시, 입력은 실제 경우와 다르게 개입되며, 시뮬레이터는 반사실적 결과를 생성하는 데 사용된다.
예를 들어, Yang et al. [110]은 먼저 추천 프로세스를 표현하기 위해 구조적 인과 모델(structural causal model, SCM)을 구축하고 나중에 사용자 및 아이템 임베딩 간의 내적을 사용하여 SCM을 구현한다. Xiong et al. [106]은 사용자 및 아이템의 특성 벡터를 입력으로 사용하는 neural network를 활용하고, 이후에는 요소별 곱셈 또는 어텐션과 같은 병합 연산자를 사용하여 사용자 및 항목의 특성 수준 속성을 통합합니다.
Zhang et al. [116] 및 Wang et al. [95]는 모델에 중립적인 반사실적 데이터 증강을 제안하여 모델을 마켓에서 직접 사용할 수 있는 순차적 추천 모델로 만들 수 있습니다. -
Intervention
요약: 이 단계에서는 입력값이 사실적 데이터와 다른 값으로 세팅된다.
구체적으로, 값을 세팅할 때, 휴리스틱한 방법 혹은 다른 학습된 모델로 반사실적 케이스를 생성해낸다. 휴리스틱 반사실적 개입(heuristic-based counterfactual intervention)은 보통 무작위성을 기반으로 한다. 예를 들어, [95]와 [116] 논문에서는 랜덤한 아이템, 인덱스로 반사실적 상호작용 시퀀스(counterfactual interaction sequence)를 생성한다.
반면에, 학습 기반의 반사실적 개입은 데이터 증강을 위해 더 유익한 샘플을 만들한다. 다시 말해, 이는 모델 최적화에 더 높은 중요성을 가진 반사실적 데이터를 생성한다. 예를 들어, [110] 논문에서는 반사실적 추천 목록은 더 큰 손실 값, 즉 어려운 샘플들을 선택하여 생성된다. 이때, 강화학습을 기반으로 더 큰 손실 값을 보이는 샘플들을 선택한다. 해당 논문에서 얘기한 문구를 인용해보면 아래와 같다.We design a learning-based method to select the counterfactual recommendation list. Our key idea is to make the generate samples more infromative for the target ranking model. It has been studied in the previous work that the samples with larger loss can usually probvide more knowledge for the model to learn. They can well challenge the model and bring more inspirations to improve the performance. Following these studies, we use the loss of the target ranking model as the reward, and build a learning-based method to generate a counterfactual recommendation list.
[95] 및 [106]에서는 결정 경계에 있는 아이템이 선택되어 최소한의 변경으로 보다 효과적인 반사실적 상호작용 순서 및 입력 특성을 만들기 위해 수정된다.
-
Inferene
이 단계에서는 반사실적 출력값이 위의 반사실적 입력값과 시뮬레이터에 의해 생성되며 이를 추천 목록 혹은 모델 학습에도 사용될 수 있다.
2) 인과추론을 활용한 데이터 노이즈 문제 해결
유저와 아이템 간의 상호작용은 데이터 수집의 촉박한 시간 창으로 인해 노이즈가 발생하여 부정확 할 수 있다. 예를 들어, 사용자의 피드백은 즉각적인 상호작용 이후에 지연될 수 있으며, 이는 상품을 장바구니에 추가 한 후 며칠 후에 구매될 수 있다. 실시간 추천에서는 완전한 보상이 관측되기 전에 이러한 샘플이 모델 훈련에 사용된다. 따라서 이러한 지연된 피드백은 초기 시간에 보상이 노이즈가 있고, 상품이 장바구니에 추가 될 때는 구매 여부가 알려지지 않기 때문에 도전적일 수 있다. Zhang et al.[120]은 인과 추론의 도움을 받아 지연된 피드백의 위기를 해결하는, 구체적으로, 중요도 샘플링(importance sampling)을 활용하여 원래의 보상을 재조정하고 대조적 세계에서 수정된 보상을 얻는다.
다음 포스팅은 위 논문들 중에서 현재 업무와 관련깊은 CTR (click-through rate) 예측 도메인에서 인과추론을 적용한 COR [90] 논문, "Causal Representation Learning for Out-of-Distribution Recommendation" (WWW'22)을 소개하려 한다.
Reference
[95] Zhenlei Wang, Jingsen Zhang, Hongteng Xu, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. Counterfactual data-augmented sequential recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 347–356.
[106] Kun Xiong, Wenwen Ye, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, Binbin Hu, Zhiqiang Zhang, and Jun Zhou. 2021. Counterfactual Review-based Recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2231–2240.
[110] Mengyue Yang, Quanyu Dai, Zhenhua Dong, Xu Chen, Xiuqiang He, and Jun Wang. 2021. Top-N Recommendation with Counterfactual User Preference Simulation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2342–2351.
[116] Shengyu Zhang, Dong Yao, Zhou Zhao, Tat-Seng Chua, and Fei Wu. 2021. Causerec: Counterfactual user sequence synthesis for sequential recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 367–377.
[120] Xiao Zhang, Haonan Jia, Hanjing Su, Wenhan Wang, Jun Xu, and Ji-Rong Wen. 2021. Counterfactual Reward Modification for Streaming Recommendation with Delayed Feedback. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 41–50.
