검색 알고리즘 (탐색 알고리즘)이란 검색 문제를 해결하는 어떠한 알고리즘이다. 연속 변수나 이산 변수를 사용하여, 일부 데이터 구조 안에 저장된 정보를 검색하거나 문제 도메인의 검색 공간에서 계산을 하기 위해 사용된다.
- 데이터 구조 내에서 특정 항목이나 값을 찾는 프로세스를 자동화하는 알고리즘
- 컴퓨터 과학과 정보 기술에서 중요한 역할
- 데이터가 저장된 컬렉션(배열, 리스트, 트리, 그래프, 데이터베이스 등)에서 특정 값을 찾는 작업은 다양한 응용 프로그램에서 중요함
- 배열 검색, 연결 리스트 검색, 이진 검색 트리 검색, 문자열 검색 등
검색 (탐색) Search : 복수의 원소로 이루어진 데이터에서 특정 원소를 찾아내는 작업
선형 탐색 (Linear Search): 무작위로 늘어 놓은 선형 데이터 구조에서 특정 원소를 찾기 위해 처음부터 끝까지 순차적으로 탐색하는 알고리즘. 시간 복잡도O(n)이진 탐색 (Binary Search): 정렬된 배열에서 중간 값을 선택하여 찾고자 하는 원소와 비교하며 탐색 범위를 반으로 줄여가는 알고리즘. 시간 복잡도O(log n)그래프 탐색 알고리즘: DFS, BFS 등 그래프 자료구조에서 특정 노드나 경로를 찾는 알고리즘
깊이 우선 탐색 (Depth-First Search, DFS): 그래프나 트리와 같은 비선형 데이터 구조에서 깊이를 우선하여 탐색하는 알고리즘. 스택 또는 재귀 함수를 사용하여 구현너비 우선 탐색 (Breadth-First Search, BFS): 그래프나 트리에서 현재 노드의 인접한 모든 노드를 먼저 탐색하고, 그 다음 레벨의 노드로 이동하는 알고리즘. 큐를 사용하여 구현
이진 트리 탐색 (Binary Tree Search): 이진 트리에서 원소를 찾는 알고리즘으로, 루트 노드부터 시작하여 비교하면서 왼쪽 또는 오른쪽 서브트리로 이동해시 테이블 (Hash Table): 해시 함수를 사용하여 데이터를 해시 맵에 저장하고, 원하는 값을 빠르게 찾는 알고리즘. 추가/삭제가 자주 일어나는 데이터 집합에서 빠른 검색 가능. 평균 시간 복잡도O(1)이중 포인터 (Two Pointer): 정렬된 배열에서 합이 특정 값이 되는 두 원소를 찾을 때 사용되는 알고리즘. 두 개의 포인터를 사용하여 배열을 순차적으로 탐색분할 정복 (Divide and Conquer): 큰 문제를 작은 부분 문제로 분할하고, 작은 부분 문제를 해결한 다음 결과를 합치는 방식의 알고리즘. 병합 정렬과 퀵 정렬이 이 방법을 사용특화된 탐색 알고리즘: 특정한 문제나 데이터 구조에 맞게 설계된 탐색 알고리즘. 예를 들어 A* 알고리즘은 경로 탐색 문제에 사용되며, KMP 알고리즘은 문자열 검색에 사용
1. 선형 탐색 Linear search
순차 탐색 (sequential search)
순차적으로 모든 원소를 탐색하여 원하는 값을 찾아내는 방법
- 배열의 길이에 비례하는 시간이 소요
O(n)(while 반복문에 의해) - 공간 복잡도
O(1) - 최악의 경우엔 배열에 있는 모든 원소를 전부 검사
# 선형 탐색 1
def linear_search(x, L) -> int :
i = 0
while i < len(L) and L[i] != x :
i += 1
if i < len(L) :
return i
else :
return -1
# 선형 탐색 2
def linear_search(x, L) :
i = 0
while i < len(L) :
if L[i] == x :
return i
i += 1
return -1
# 선형 탐색 3
def linear_search(x, L) :
i = 0
while True:
if i == len(L) :
return -1
if L[i] == x :
return i
i += 1
# 선형 탐색 4
def linear_search(x, L) :
for i in range(len(L)) :
if L[i] == x:
return i
return -1보초법(Sentinel Search)
선형 탐색의 종료 조건은 검색 실패, 검색 성공 2가지 이다. 보초법을 통해 이러한 종료 조건을 검사하는 비용을 반으로 줄일 수 있다.
검색할 값 x 을 배열 L 의 맨 끝에 추가하면, 종료 조건이 검색 성공 뿐이며, 반복을 종료하기 위해 판단하는 횟수가 절반으로 줄어든다.
# 선형 탐색 - 보초법 이용
import copy
def linear_search(x, L):
l = copy.deepcopy(L)
l.append(x)
i = 0
while True :
if l[i] == x:
break
i += 1
return -1 if i == len(L) else i2. 이진 탐색 Binary search
크기 순으로 정렬되어 있는 정렬을 반씩 제외하며 탐색하는 방법
탐색하려는 배열이 이미 정렬되어 있는 경우에만 적용할 수 있다. 배열의 가운데 원소와 찾으려 하는 값을 비교하면, 왼쪽이나 오른쪽 어디에 있을 지를 알 수 있다.
- 탐색하려는 리스트가 이미 정렬되어 있는 경우에만 적용 가능
- 크기 순으로 정렬되어 있다는 성질 이용
- 왼쪽, 오른쪽을 비교하여 반씩 제외하며 탐색하는 방법 (divide & conquer)
- 시간 복잡도
O(log n)- 검색에 실패할 경우log(n+1), 성공할 경우log(n-1)번 - 공간 복잡도
O(1)
# 이진 탐색
# L : 배열 리스트, x : 찾고자 하는 값
def binary_search(L, x):
low = 0 # start_index
high = len(L) - 1 # end_index
while low <= high:
middle = (low + high) // 2
if L[middle] == x:
return middle
elif L[middle] > x:
high = middle - 1
else:
low = middle + 1
return None- 이진탐색과 선형탐색 비교 -
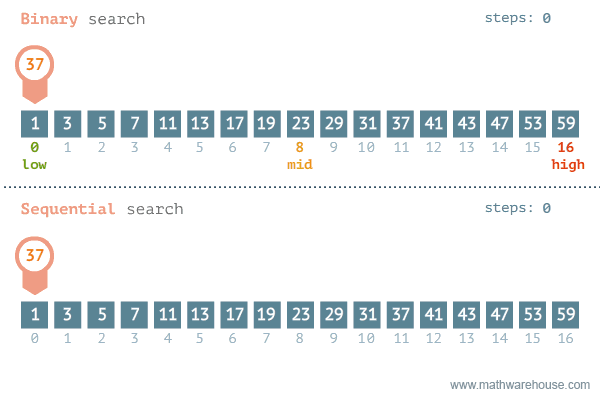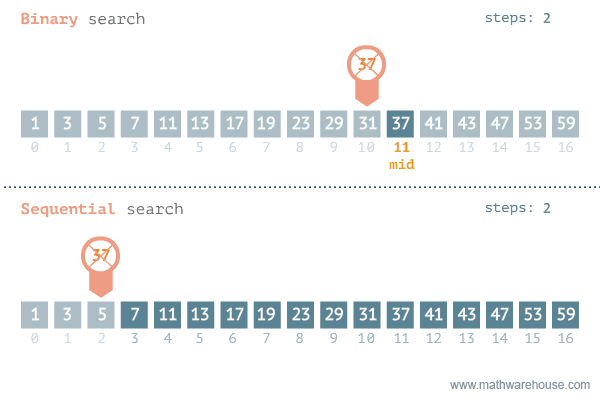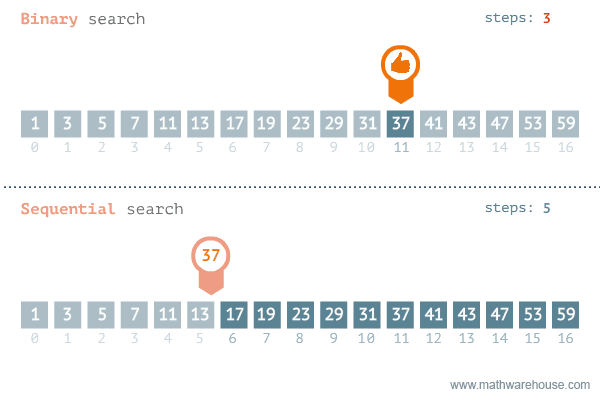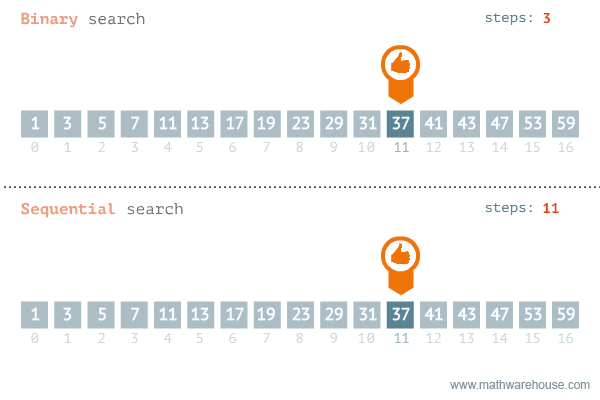
| 선형 탐색 | 이진 탐색 | |
|---|---|---|
| 검색 방법 | 배열의 처음부터 끝까지 순차적으로 탐색 | 정렬된 배열을 절반씩 범위를 줄여가며 탐색 |
| 배열 정렬 요구 | 상관없음 | 반드시 정렬되어 있어야 함 |
| 평균 시간 복잡도 | O(n) | O(log n) |
| 공간 복잡도 | 상수 공간을 사용하므로 O(1) | 상수 공간을 사용하므로 O(1) |
| 데이터 크기와 성능 | - 작은 배열 또는 리스트에 적합 - 데이터 크기에 대한 제한 없음 | - 대량의 데이터에 대해 효과적 - 큰 배열에서 빠른 검색 제공 |
- 그래프 탐색 vs 경로 탐색 -
- 그래프 탐색 알고리즘 안에 경로 탐색 알고리즘이 속한다
- 그래프 내의 노드를 탐색
: 그래프는 노드(또는 정점)와 노드를 연결하는 간선(또는 에지)으로 구성된다. 주로 그래프 내의 노드를 방문하거나 그래프 내의 경로를 찾는 데 사용된다. - 주어진 그래프에서 두 노드 사이의 경로 찾기
: 출발점과 도착점 사이의 경로를 찾거나 최단 경로, 최소 비용 경로 등을 찾는 데 사용된다. - BFS와 DFS는 최단 경로 탐색 (BFS이용), 경로 존재 여부 확인에서 경로 탐색 알고리즘으로 작동할 수 있다. 이처럼 그래프 탐색 알고리즘 중 일부는 경로 탐색에 활용될 수 있지만, 그래프 탐색과 경로 탐색은 서로 다른 목적을 가지고 있다.
3-1. 그래프 탐색 알고리즘
Graph search algorithm
백트래킹 : 모든 경우를 다 탐색해 문제의 해답을 찾는 알고리즘.
어떤 규칙으로 정해진 해답을 찾지 못하면 다시 처음으로 돌아와 다른 규칙으로 문제의 해답을 찾는다. 보통 트리 데이터 구조에서는 BFS, DFS를 이용해 백트래킹을 실행한다.
1) 너비 우선 탐색 BFS
Breadth-first search- 시작 노드에서 가장 가까운 노드부터 시작하여 모든 노드를 광범위하게 탐색
- 0층에서 시작하며 다음 층으로 이동하기 전에 해당 층의 모든 노드를 방문할 때까지 수평으로 이동
- 즉, 한 번 거친 노드 순서를 저장한 후 다시 꺼내는
선입선출원칙으로 탐색 - 보통
큐데이터 구조로 구현 - 두 노드 사이에 경로가 있는지 확인하고 그 사이의 최단 경로를 결정
2) 깊이 우선 탐색 DFS
Depth-first search- 시작 노드와 직접 연관된 하위 노드의 끝까지 모두 탐색한 후 다음 하위 노드를 탐색하는 방법
- 경로 하나의 모든 층을 탐색한 후 그 다음에 다른 경로의 모든 층을 탐색
- 보통
재귀 호출이나스택을 명시하는 방법으로 구현
3) 크루스칼 알고리즘
Kruskal's Algorithm
4) 프림 알고리즘
Prim's Algorithm
3-2. 경로 탐색 알고리즘
경로 탐색 기법의 두 가지 유형 :
탐욕적 접근법: 항상 현재의 관점에서 적합한 경로를 선택, 하지만 문제 전체를 고려하지 않고 하나의 단계만 기준으로 하여 결정을 내린다.휴리스틱 접근법 (간편 추론 접근법): 확률론을 토대로 문제의 대략적인 해결책을 제공, 그리고 완벽한 논리가 아닌 사람의 직감으로 판단하는 영역을 그대로 구현하는 방법이므로 실전에서 문제없이 사용할 수 있을 정도로 안정성이 입증되어 있다.
1) 데이크스트라 알고리즘
Dijkstra algorithm- 가중 그래프에서 동작하고 그래프의 노드 하나에서 다른 노드까지의 최단 경로를 찾는다.
그래프의 가중치 :비용 cost(음수가 아니어야 함) - 즉, 그래프의 시작 노드에서 목표 노드까지의 최소 비용을 찾는다.
목표 노드에 도달할 때까지 한 번에 하나의 경로씩 계속 반복해서 계산하며 각 노드까지의 최단 경로를 찾는다. - 한계점 : 알고리즘이 탐색하는 공간에 대한 정보가 없어서
블라인드 탐색 blind search또는무정보 탐색 uninformed search으로 알려진 동작을 수행하는 데 많은 시간과 자원을 소비한다. - 장점이 강력하여
지도,내비게이션 서비스등에서 많이 사용하는 알고리즘 - 개선 :
벨먼-포드 알고리즘 bellman-ford algorithm(그래프에서 최단 경로를 찾는 데 사용, 가중치가 음수인 에지를 갖는 그래프에서도 동작)
2) A* 알고리즘
A star algorithm- (데이크스트라와 마찬가지로) 노드 사이의 최단 경로를 찾는 알고리즘
- '데이크스트라 알고리즘의 접근법'과 '탐색할 때마다 최선의 휴리스틱을 찾아서 그에 따라 노드를 탐색하는
최선 우선 탐색 best first search알고리즘의 요소'를 결합하여 훌륭한 휴리스틱적 해결책을 제공하고, 그 결과 전체 순회 비용이 가장 낮은 경로를 선택한다. - 비용 계산에 실패할 수도 있지만 A* 알고리즘을 사용하면 적어도 최단 경로를 찾는 것이 보장된다.
- 로봇 공학, 인공지능에 이용
알고리즘 :
- 시작 노드에서 인접 노드로 이동하는 비용, 목표 노드까지의 예상 비용을 계산한다.
- 계산이 끝나면, 인접 노드 중 비용이 가장 낮은 노드를 선택한다.
이를탐색이 완료된 노드로 간주한다. - 탐색이 완료된 노드를 기준으로 모든 인접 노드의 비용을 계산하고, 그 중 가장 낮은 비용의 노드를 선택하여 탐색이 완료된 노드로 간주한다.
이를 목표 노드에 도달할 때까지 반복한다.
구현 :
A* 알고리즘은 휴리스틱 함수의 선택, 데이터 구조의 구현, 그리고 잘 정의된 노드와 간선 정보가 필요한 고급 경로 탐색 알고리즘이다. 구현이 복잡할 수 있으며, 효율적인 데이터 구조와 자료 구조 라이브러리를 사용하여 구현하는 것이 좋다.
노드와 간선 정의: 시작 노드, 목표 노드, 각 노드 간의 연결된 간선 정보 저장휴리스틱 함수 (Heuristic Function) 정의: 각 노드까지의 예상 비용을 계산 (맨해튼 거리, 유클리드 거리, 또는 다른 예측 모델을 사용)오픈 리스트 (Open List), 닫힌 리스트 (Closed List) 초기화: 시작 노드를 오픈 리스트에 추가, 빈 닫힌 리스트 초기화오픈 리스트에서 노드 선택: 오픈 리스트에서 휴리스틱 함수 값이 가장 작은 노드를 선택, 이 노드는 현재 탐색할 노드로 선택선택한 노드 검사: 선택한 노드가 목표 노드인지 확인 (만약 목표 노드라면 알고리즘을 종료하고 최단 경로를 구성)인접 노드 검사: 선택한 노드와 연결된 인접 노드를 확인, 각 인접 노드의 예상 비용 계산, 이미 닫힌 리스트에 있는 노드는 무시오픈 리스트 업데이트: 각 인접 노드를 오픈 리스트에 추가, 현재 노드를 부모로 설정 (이때, 각 노드의 총 비용 (실제 비용 + 휴리스틱 비용) 계산 후 정렬된 순서로 유지)닫힌 리스트 업데이트: 현재 노드를 닫힌 리스트에 추가반복: 목표 노드가 나타날 때까지 4-8단계 반복최단 경로 복원: 각 노드의 부모 노드를 따라가며 최단 경로를 복원
데이크스트라 vs A* 알고리즘
- 탐욕적 접근법 vs 휴리스틱 접근법
- 그래프에서 가능한 모든 경로를 탐색 vs 어림짐작한 최단 경로의 비용이 실제 최단 경로의 비용에 가까울 수 있어 더 효율적
3) 벨만-포드 알고리즘
4. 해시 테이블
해시 테이블 Hash table: 키 key, 값 value 쌍으로 이뤄진 값들의 리스트해시법 Hashing: key를 가져와 해시값으로 변환하는 과정해시 함수 Hash function: 해싱하는 과정에 사용한 코드
검색 알고리즘 (탐색 알고리즘)에 대한 자세한 내용은 여기서!
출처
코드 없는 알고리즘과 데이터 구조
Do it! 자료구조와 함께 배우는 알고리즘 입문 (파이썬 편)
