정렬 알고리즘이란 원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘이다. 효율적인 정렬은 탐색이나 병합 알고리즘처럼 다른 알고리즘을 최적화하는 데 중요하다. 또 정렬 알고리즘은 데이터의 정규화나 의미있는 결과물을 생성하는 데 유용히 쓰인다.
정렬 알고리즘은 데이터를 교환, 선택, 삽입하면서 정렬을 완료한다.
정렬 Sort (with. lambda)
복수의 원소로 주어진 데이터를 정해진 기준에 따라 새로 늘어놓는 작업
- 파이썬 내장 함수
sorted() - 리스트 메서드
.sort()
- 순서 :
오름차순(기본, reverse=False),내림차순(reverse=True) - 기준 설정 :
key=lambda 함수
# key에 lambda 함수를 이용하여 원하는 기준으로 정렬하기
# 1. 문자열 길이에 따라 지정하기
L = ['abcd', 'efg', 'a']
sorted(L, key=lambda x: len(x))
>>> ['a', 'efg', 'abcd']
# 2. 딕셔너리에서 이용하기
L = [{'name': 'jain', 'score': 80}, {'name': 'alex', 'score': 70}]
L.sort(key=lambda x: x['score'], reverse=True)
>>> 점수 높은 순으로 정렬
👉 다양한 상황에서의 정렬 알고리즘의 퍼포먼스 확인하기
- 거의 정렬된 리스트의 정렬 : 삽입 정렬이 가장 빠름
- 무작위 순서 리스트의 정렬 : 힙 정렬이 가장 빠름
- 정반대로 정렬된 리스트의 정렬 : 삽입 정렬이 오래 걸림
- 선택 정렬, 합병 정렬은 상황에 영향을 받지 않고 일정한 시간이 소요됨
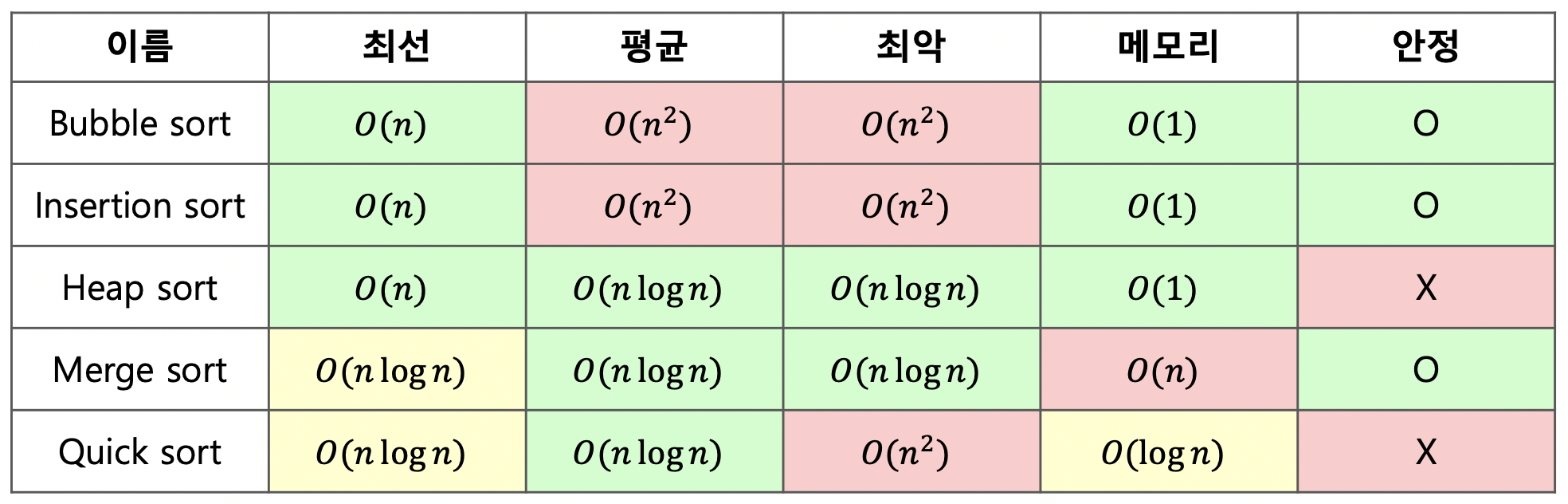
1. 버블 정렬 (Bubble Sort):
- 최선/평균/최악 시간 복잡도:
O(n^2) - 간단하고 이해하기 쉬운 알고리즘으로, 작은 크기의 데이터에 적합
2. 선택 정렬 (Selection Sort):
- 가장 기본적인 정렬
- 각 위치에 어떤 값이 들어갈지
- 최선/평균/최악 시간 복잡도:
O(n^2) - 비교 횟수가 일정하기 때문에 데이터 크기에 관계없이 항상 동일한 시간이 소요
3. 삽입 정렬 (Insertion Sort):
- 각 값이 어떤 위치에 들어갈지
- 최선 시간 복잡도:
O(n)- 이미 정렬된 데이터에 대해 - 평균/최악 시간 복잡도:
O(n^2) - 작은 크기의 데이터에 적합하며, 데이터가 이미 거의 정렬되어 있을 때 효율적
4. 병합 정렬 (Merge Sort):
- 최선/평균/최악 시간 복잡도:
O(n log n) - 데이터 크기와 무관하게 항상 일정한 시간이 걸림
5. 퀵 정렬 (Quick Sort):
- 최선/평균 시간 복잡도:
O(n log n) - 최악 시간 복잡도:
O(n^2) - 대부분의 경우 효율적이며 대용량 데이터에 적합
6. 힙 정렬 (Heap Sort):
- 최선/평균/최악 시간 복잡도:
O(n log n) - 우선순위 큐와 관련된 힙 자료 구조를 사용하는 정렬 알고리즘
7. 빠른 정렬 (Tim Sort):
- 최선/평균 시간 복잡도:
O(n log n) - 최악 시간 복잡도:
O(n^2) - 병합 정렬과 삽입 정렬을 결합한 알고리즘으로, Python 내장 sorted() 함수에 사용
- 네이버 D2 참고
1. 버블 정렬 Bubble sort
이웃한 두 원소의 대소 관계를 비교하여 필요에 따라 교환을 반복하는 알고리즘 단순 교환 정렬
- 원소 수가 n인 배열에서 n-1번
패스 pass(비교/교환하는 과정)를 하면 가장 작은 원소가 맨 앞으로 이동한다.
비교 comparison & 교환 swap - 시간 복잡도
O(n²) - 단순하지만 느리다.
알고리즘 :
- 배열 (오른쪽) 끝에 있는 연속된 두 원소 비교한 후 위치 설정
- 한 자리씩 (왼쪽으로) 이동하며 배열의 (왼쪽) 끝에 도달할 때까지 두 숫자 비교 및 교환
- 배열이 완성될 때까지 1~2를 반복 수행
# 버블 정렬 - 기본형
def bubble_sort(L):
n = len(L)
for i in range(n-1):
for j in range(n-1, i, -1):
if L[j-1] > L[j] :
L[j-1], L[j] = L[j], L[j-1]
# 버블 정렬 - 교환 횟수에 따른 중단
def bubble_sort(L):
n = len(L)
for i in range(n-1):
exchange = 0
for j in range(n-1, i, -1):
if L[j-1] > L[j] :
L[j-1], L[j] = L[j], L[j-1]
exchange += 1
if exchange == 0:
break
# 버블 정렬 - 스캔 범위 제한
def bubble_sort(L):
n = len(L)
k = 0
while k < n-1 :
last = n-1
for j in range(n-1, k, -1):
if L[j-1] > L[j] :
L[j-1], L[j] = L[j], L[j-1]
last = j
k = last
# 효율 : 기본형 < 교환 횟수에 따른 중단 < 스캔 범위 제한셰이커 정렬 shaker sort
버블 정렬을 개선한 알고리즘
양방향 버블 정렬 bidirectional bubble sort=칵테일 정렬 cocktail sort=칵테일 셰이커 정렬 cocktail shaker sort
# 셰이커 정렬
def shaker_sort(L) :
left = 0
right = len(L) - 1
last = right
while left < right:
for i in range(right, left, -1):
if L[i-1] > L[i]:
L[i-1], L[i] = L[i], L[i-1]
last = i
left = last
for j in range(left, right):
if L[j] > L[j+1]:
L[j], L[j+1] = L[j+1], L[j]
last = j
right = last2. 선택 정렬 Selection sort
가장 작은 원소부터 선택해 알맞은 위치로 옮기는 작업을 반복하며 정렬하는 알고리즘 (선형 탐색을 응용한 알고리즘으로, 각 위치에 어떤 값이 들어갈지 찾는다)
단순 선택 정렬 straight selection sort- 선형 탐색 횟수
(n-1) + (n-2) + ... + 1 번 - 시간 복잡도
O(n²)- 하지만, 버블 정렬보다 2배 빠르다 - 이해하기 쉽지만 반복문 2개를 중첩하여 구현한다.
- 요소의 개수가 작은 배열에서 유용하다.
- 요소의 개수가 많은 배열에서는 버블 정렬보다 조금 더 나은 성능을 제공한다.
알고리즘 :
- 선형 탐색을 사용하여 (처음부터 끝까지 탐색하여) 배열에서 가장 작은 숫자를 찾는다.
- 가장 왼쪽에 위치한 숫자와 위치를 바꾼다.
- 정렬된 인덱스를 제외하고, 1~2를 반복한다.
배열의 모든 숫자가 정렬될 때까지 반복 수행한다.
# 단순 선택 정렬
def selection_sort(L) :
n = len(L)
for i in range(n-1):
min = i
for j in range(i+1, n):
if L[j] < L[min]:
min = j
L[i], L[min] = L[min], L[i]
3. 삽입 정렬 Insertion sort
- 시간 복잡도 : 최선
O(n), 평균O(n²), 최악O(n²) - 각 값이 어떤 위치에 들어갈지 찾으며, 널리 사용된다.
- 선택 정렬보다 효율적이다.
알고리즘 :
- 1번 인덱스부터 차례대로 0번 인덱스까지 앞의 인덱스 숫자들과 하나씩 비교하여 정렬
- 1번 인덱스와 왼쪽 인덱스를 비교하여, 더 크면 그대로, 더 작으면 왼쪽으로 삽입
- 다음 2번 인덱스와 왼쪽 인덱스를 하나씩 비교하여, 더 크면 그대로, 더 작으면 왼쪽으로 (1번 인덱스와 비교 후 0번 인덱스와 다시 비교)
- 배열의 모든 숫자가 정렬될 때까지 반복 수행
# 단순 삽입 정렬
def insertion_sort(L):
n = len(L)
for i in range(1, n):
j = i
tmp = L[i]
while j > 0 and L[j-1] > temp:
L[j] = L[j-1]
j -= 1
L[j] = tmp
# 이진 삽입 정렬 - 효율성 개선
def binary_insertion_sort(L):
n = len(L)
for i in range(1, n):
key = L[i]
l = 0
r = i-1
while True:
m = (l+r) // 2
if L[m] == key:
break
elif L[m] < key:
l = m+1
else :
r = m-1
if l > r:
break
x = m + 1 if l <= r else r + 1
for j in range(i, x, -1):
L[j] = L[j-1]
L[x] = key
# 이진 삽입 정렬 - 모듈 이용
import bisect
def binary_insertion_sort(L):
for i in range(1, len(L)):
bisect.insort(L, L.pop(i), 0, i)4. 셀 정렬 Sell sort
- 삽입 정렬을 더 효율적으로 실행하는 알고리즘
삽입 정렬 장점 : 이미 정렬을 마쳤거나 정렬이 끝나가는 상태에서 속도 빠름
삽입 정렬 단점 : 삽입할 위치가 멀리 떨어져 있으면 이동 횟수가 많아짐 - 정렬한 배열의 원소를 그룹으로 나눠 각 그룹별로 정렬을 수행한 후, 정렬된 그룹을 합치는 작업을 반복하여 원소의 이동 횟수를 줄이는 방법
- 시간 복잡도 : 최선
O(n), 평균O(n^1.5), 최악O(n²)
알고리즘 :
- 요소를 몇 개 단위로 묶은 후 단위마다 삽입 정렬을 실행
- 이후 단위 요소 수를 줄여 묶은 후 삽입 정렬을 실행
- 단위 요소 수가 1이 될 때까지 반복 수행
# 셀 정렬
def shell_sort(L):
n = len(L)
h = n // 2
while h > 0:
for i in range(h, n):
j = i - h
tmp = L[i]
while j >= 0 and L[j] > tmp:
L[j + h] = L[j]
j -= h
L[j + h] = tmp
h //= 2
# 셀 정렬 - h*3+1 수열 사용
def shell_sort(L) :
n = len(L)
h = 1
while h < n // 9 :
h = h * 3 + 1
while h > 0 :
for i in range(h, n):
j = i - h
tmp = L[i]
while j >= 0 and L[j] > tmp :
L[j + h] = L[j]
j -= h
L[j + h] = tmp
h //= 35. 병합 정렬 Merge sort
분할 정복 Divide and conquer: 데이터를 반으로 나누어 정렬을 수행하는 알고리즘- (일반적인) 시간 복잡도
O(nlogn) - 재귀 함수를 사용하여 입력 데이터를 계속 나누므로, 재귀 횟수에 따라 복잡도가 달라진다.
알고리즘 :
- 모든 배열에 하나의 숫자만 남을 때까지 반복해서 배열을 반으로 나눈다.
- 두 배열씩 결합하며 정렬한다.
- 결합을 반복하며 점점 배열의 크기를 늘려나간다.
- 완전히 정렬된 하나의 배열을 얻을 때까지 반복한다.
# 병합 정렬
6. 퀵 정렬 Quick sort
분할 정복방식 이용- 시간 복잡도
O(nlogn) - 배열이 완전히 정렬될 때까지 배열을 작게 나눠가며 정렬을 수행한다.
파티션 Partition수행 :피벗 pivot을 기준점으로 작은 수는 왼쪽, 큰 수는 오른쪽에 정렬하는 과정
알고리즘 :
- 자세한 내용은 Quick sort process 참고
- 배열의 맨 처음 요소를 마커 이동의 기준이 되는
피벗 pivot으로 설정 - 피벗 바로 오른쪽에 위치한 요소와 배열 맨 오른쪽에 위치한 요소를 각각
왼쪽 마커 left market,오른쪽 마커 right marker로 설정 왼쪽 마커 L는 오른쪽으로 이동하며피벗 P보다 크거나 같은 첫 번째 숫자를 선택오른쪽 마커 R는 왼쪽으로 이동하며피벗 P보다 작은 첫 번째 숫자를 선택- 각 마커가 숫자를 선택하면
L,R두 마커의 숫자를 바꿈 (반복) L과R이 서로 교차하는 상태가 되면R과P의 숫자를 바꿈P보다 작은 숫자는 배열의 왼쪽에, 큰 숫자는 오른쪽에 위치하게 됨P의 왼쪽과 오른쪽에 있는 배열의 맨 왼쪽 요소를 새로운 피벗으로 삼아 처음부터 다시 반복
# 파티셔닝 -> 이것을 발전시키면 퀵 정렬이 됨
def partition(L) :
n = len(L)
l = 0
r = n - 1
x = L[n // 2]
while l <= r:
while L[l] < x :
l += 1
while L[r] > x :
r -= 1
if l <= r :
L[l], L[r] = L[r], L[l]
l += 1
r -= 1
# 퀵 정렬 (재귀적)
def qsort(L, left, right) :
l = left
r = rignt
x = L[(left + right) // 2]
while l <= r:
while L[l] < x : l += 1
while L[r] > x : r -= 1
if l <= r :
L[l], L[r] = L[r], L[l]
l += 1
r -= 1
if left < r : qsort(L, left, r)
if l < right : qsort(L, l, right)
def quick_sort(L):
qsort(L, 0, len(L)-1)
# 퀵 정렬 (비재귀적)
def qsort(L, left, right) :
range = Stack(right - left + 1)
range.push((left, right))
while not range.is_empty() :
l, r = left, right = range.pop()
x =.L[(left, right) // 2]
while l <= r:
while L[l] < x : l += 1
while L[r] > x : r -= 1
if l <= r :
L[l], L[r] = L[r], L[l]
l += 1
r -= 1
if left < r : range.push((left, r))
if l < right : range.push((l, right))
def quick_sort(L):
qsort(L, 0, len(L)-1)7. 힙 정렬 Heap sort
- 힙 데이터 구조의 각 노드를 최대 힙 혹은 최소 힙 상태로 정렬하는 방법
- 시간 복잡도 항상
O(nlogn): 바로 옆에 있는 부모 및 자식 노드를 상대 비교하기 때문에
알고리즘 :
- 최대/최소인 노드를 찾는다.
- 이 노드를 바로 위 부모 노드와 비교하여, 더 큰/작은 노드를 부모로 둔다. (루트 노드에 가깝게 둔다.)
- 부모 노드의 끝까지 반복한다.
- 모든 노드가 정렬될 때까지 다음으로 큰 노드를 찾아 1-3번을 반복한다.
# 힙 정렬 - 모듈 이용
import heapq
def heap_sort(L) :
heap = []
for i in L :
heapq.heappuch(heap, i)
for i in range(len(L)) :
L[i] = heapq.heappop(heap)
# 힙 정렬
def heap_sort(L) :
def down_heap(L, left, right) :
temp = L[left]
parent = left
while parent < (right + 1) // 2 :
l = parent * 2 + 1
r = l + 1
child = r if r <= right and L[r] > L[l] else l
if temp >= L[child] :
break
L[parent] = L[child]
parent = child
L[parent] = temp
n = len(L)
for i in range((n-1) // 2, -1, -1):
down_heap(L, i, n-1)
for i in range(n-1, 0, -1):
L[0], L[i] = L[i], L[0]
down_heap(L, 0, i-1)8. 버킷 정렬 Bucket sort
- 요소들을 어떤 기준이 있는 버킷에 나눠 넣은 후 정렬 수행
버킷: 여러 데이터를 저장하는 장소- 버킷의 기준 : 10진수의 자릿수
- 시간 복잡도 : 버킷 내에서 요소를 정렬할 때의 시간 복잡도를 따름
최악O(n²), 평균O(n+n²/m+m)(m:버킷 수) - 자릿수를 기준으로 버킷을 만들어 그에 해당하는 요소를 나눠 넣은 후 버킷 안에서 정렬해 정렬 처리 속도를 높인다.
알고리즘 :
- 어떤 순서가 있는 버킷으로 사용할 기억 공간 (배열이나 리스트)을 준비한다.
- 버킷을 만들 때의 기준에 따라 요소를 분류해 넣는다.
- 버킷별로 버킷 내에서 요소를 정렬한다.
- 버킷의 순서에 따라 나열해서 정렬을 완료한다.
9. 기수 정렬 Radix sort
- 버킷 정렬과 기본 원리는 같지만, 버킷 정렬과 다르게 특정 기준이 정해져 있다.
- 특정 기준이 정해져 있는 버킷 정렬
(특정 기준 : 요솟값의 특정 자릿수끼리 비교해서 정렬하는 것) - 시간 복잡도 : 최악의 경우
O(mn)(m:요소의 자릿수)
알고리즘 :
- 숫자 0~9에 해당하는 버킷 9개를 만든다.
- 1의 자릿수를 기준으로 요소를 분류해 넣는다.
- 10의 자릿수를 기준으로 요소를 분류해 넣는다. 이 때, 요솟값이 1의 자릿수 숫자면 그 앞이 0이라고 간주한다.
- 100, 1000, ...의 자릿수를 기준으로 순서대로 정렬될 때까지 계속 반복한다.
10. 도수 정렬 Counting sort
분포수 세기 정렬 distribution counting sort- 대소 관계를 판단하지 않고 빠르게 정렬하는 알고리즘
알고리즘 :
- 도수 분포표 만들기
- 누적 도수 분포표 만들기
- 작업용 배열 만들기
- 배열 복사하기
# 도수 정렬
def fsort(L, max) :
n = len(L)
f = [0] * (max + 1) # 누적 도수 분포표 배열
b = [0] * n # 작업용 배열
for i in range(n) :
f[L[i]] += 1
for i in range(1, max+1) :
f[i] += f[i-1]
for i in range(n-1, -1, -1) :
f[L[i]] -= 1
b[f[L[i]]] = L[i]
for i in range(n) :
L[i] = b[i]
def counting_sort(L):
fsort(L, max(L))정렬 알고리즘에 대한 자세한 내용은 여기서!
출처
programmerse
코드 없는 자료구조와 알고리즘

planning design development with data