[코드잇] 정규표현식
- 레슨 수 : 25강
- 난이도 : 초급
강의 소개 : 정규 표현식은 문자열을 일정한 패턴으로 표현하는 방식입니다. 한번 잘 배워두면 프론트엔드, 백엔드, 데이터 분석 등 여러 가지 분야에서 활용할 수 있죠. 다양한 실습 예제를 통해 정규 표현식의 문법을 익혀 봅시다.
정규 표현식 (정규식, Regular Expression, Regex)
| 시작기호 | 정규식 패턴 | 종료기호 | 플래그 |
|---|---|---|---|
| / | [bce]car | / | gi |
실제 값은 다르지만 패턴은 서로 동일한 문자열을 표현할 때 사용되는 형식 언어
- 회원 가입 시 비밀번호 조건
/^(?=.*[a-zA-Z])(?=.*[0-9]).{8,}/
#'영문, 숫자 조합 8자 이상'인 문자열을 탐색하는 정규 표현식
# 이 외엔 비밀번호 생성이 되지 않도록 막는다.- 개인정보 외부전달 시 비식별화
# 원하는 문자열을 선택하여 값을 치환해 주는 상황에서 정규 표현식
(\d{6}[ ,-]-?[1-4]\d{6})|(\d{6}[ ,-]?[1-4]) # 주민번호
(\d{2}-\d{2}-\d{6}-\d{2}) # 운전면허번호
(\d{2,3}[ ,-]-?\d{2,4}[ ,-]-?\d{4}) # 핸드폰 번호
(([\w!-_\.])*@([\w!-_\.])*\.[\w]{2,3}) # 메일 주소
([a-zA-Z]{1}|[a-zA-Z]{2})\d{8} # 여권 번호
([0-9,\-]{3,6}\-[0-9,\-]{2,6}\-[0-9,\-]) # 계좌 번호정규 표현식 사이트
FLAVOR- 언어 기반 설정하기TEST STRING- 텍스트 본문 입력하는 곳REGULAR EXPRESSION- 원하는 정규 표현식 작성하는 곳EXPLANATION- 정규 표현식의 해석 내용 & 문법 설명MATCH INFORMATION- 필요한 정규 표현식 문법 검색
REGULAR EXPRESSION에 작성 ➡️ TEST STRING에서 하이라이트 처리
플래그(Flag) 설정
정규 표현식에 적용되는 설정을 조절해 주는 옵션 (기본 : gm)
REGULAR EXPRESSION 우측에 위치
g- 패턴과 일치하는 모든 것 추출 (생략할 경우 일치하는 것 중 가장 먼저 발견되는 것 하나만 추출)i- 대소문자 구분 없이 추출m- 문자열을 하나의 문장이 아니라 여러 줄로 인식하게 하기 (줄 바꿈을 문장의 경계로 인식)s-.이 줄 바꿈 문자\n도 포함하게 설정
기본 문법
1. 메타 문자 (Meta Sequence)
문자열의 특정한 규칙을 표현하기 위해서 사용
문자열의 특정한 규칙을 좀 더 쉽게 표현할 수 있도록 만들어진 예약어
[],-,^,문자 클래스,.등
🔹 집합 (범위 표현, 고르기)
표현하고 싶은 문자를 대괄호 []에 넣는 식으로 사용
# 고르기
[bce]ar ➡️ bar car ear 추출문장에 있는 숫자 추출
# REGULAR EXPRESSION
[012345678]
# TEST STRING
010-1234-5678 ➡️ 0 1 0 1 2 3 4 5 6 7 8 추출대문자 추출
[ABCDEFGHIJKLMNOPQRSTUVWXYZ]
소문자 추출
[abcdefghijklmnopqrstuvwxyz]
대문자와 소문자 붙어서 나오는 부분 추출
[ABCDEFGHIJKLMNOPQRSTUVWXYZ][abcdefghijklmnopqrstuvwxyz]'하이픈 -' 으로 문자 사이의 범위 더 간단하게 표현 가능
[0123456789] = [0-9]⚠️ 하이픈은 아스키코드를 기준으로 범위를 계산 (낮은문자-높은문자 형식)
더 자세한 내용은 아스키코드표 참고
'캐럿 ^' 으로 집합 안의 특정 문자들을 제외하여 선택 가능 ^허용문자
[^0-9] ➡️ 숫자를 제외한 모든 문자 추출⚠️ 캐럿은 가장 앞에 작성해야 한다.
예제 : '이름 나이' 형태의 데이터에서 30대인 사람 찾는 정규표현식
[가-힣][가-힣] [34][0-9]🔹 문자 클래스
자주 사용하는 집합들을 좀 더 쉽게 사용할 수 있도록 한 일종의 예약어로,
보통 백슬래시 \ 뒤에 특정 알파벳을 합쳐서 표기한다.
| 의미 | 집합 표현 | 문자 클래스 |
|---|---|---|
| 숫자 | [0-9] | \d |
| 영어 대소문자+숫자+언더바 | [a-zA-Z0-9_] | \w |
| 공백 문자 | [\t\n\r\f\v] | \s |
부정의 의미를 가진 문자 클래스 :
| 의미 | 집합 표현 | 문자 클래스 |
|---|---|---|
| 숫자가 아닌 것 | [^0-9] | \D |
| 영어 대소문자+숫자+언더바가 아닌 것 | [^a-zA-Z0-9_] | \W |
| 공백 문자가 아닌 것 | [^\t\n\r\f\v] | \S |
🔹 Dot(.)
모든 문자를 의미
# REGULAR EXPRESSION
.
# TEST STRING
hi hello ➡️ hi hello 추출# REGULAR EXPRESSION
h.
# TEST STRING
hi hello ➡️ hi he 추출기본적으로 줄바꿈문자 \n은 표현하지 못하지만, Flag에 s 를 추가하면 포함 가능하다.
2. 이스케이핑( \ )
정규 표현식의 시작과 끝을 나타내는 구분문자(delimiter)로 사용되는 /와 더불어 [], ^, . 등의 문자를 메타 문자가 아니라 일반 문자로 사용하고 싶을 때,
앞에 \ 입력하여 처리한다.
3. 수량자
하나의 문자가 아니라 여러 번 반복되는 문자나 문자열을 선택하고 싶을 때
문자의 반복 횟수를 설정하는 문법 - 반복하고 싶은 문자{수량자}
- 4자리 숫자 추출 :
\d{4}=\d\d\d\d=[0-9][0-9][0-9][0-9]
{min,max} 형태로 사용하면 수량자 범위 지정도 가능하다. (❗공백 X❗)
최대값을 빈칸으로 두면 최솟값 이상 글자가 모두 표시된다.
- 3~6자리 숫자 추출 :
\d{3,6} - 2자리 이상 숫자 추출 :
\d{2,}
수량자의 메타 문자로는 *, +, ? 가 있다.
*- 제한 없이 모든 숫자, 앞에 문자가 하나도 없어도 선택 (0~무한대)+- 제한 없이 모든 숫자, 앞에 최소 1개의 문자 반드시 필요 (1~무한대)?- 문자가 아예 없거나 하나만 있을 경우 (0 or 1)
\d*원
원 # 추출
1원 # 추출
\d+원
원 # 추출 X
1원 # 추출jpe?g
jpg # 추출
jpeg. # 추출* 잘못 사용 시, 최대한 큰 덩어리의 문자열을 찾으려고 하는 특성 때문에 탐욕적(greedy) 수량자 발생한다.
# REGULAR EXPRESSION
".*"
# TEST STRING
"Aa" "Bb" "Cc"
----------------------------------------------------------
Aa Bb Cc 각각이 추출되는 것이 아니라, "Aa" "Bb" "Cc" 가 통째로 추출따라서 문자를 원하는 만큼만 일치시키기 위해 ? 통해 게으른 수량자 사용하면 된다.
.*대신".*?"사용
4. 경계
1) 단어 경계 - 위치를 나타내는 메타 문자 \b, \B
\b- 문자\w와 문자가 아닌 곳\W사이의 위치에 해당하는 경계\B- 단어의 경계가 아닌 위치
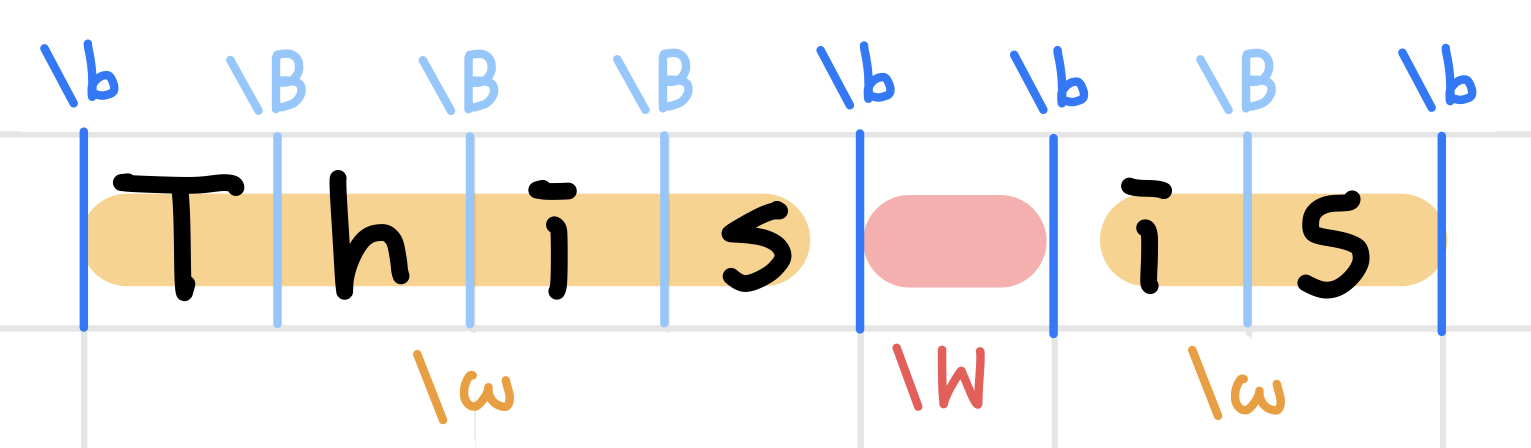
# 뒤에 오는 is만 선택
\bis\b# This에 있는 is 선택
\Bis\b2) 문장 경계 - 문장의 시작점 ^, 문장의 끝 지점$
^선택하고 싶은 문장$^은 집합 안에서 쓰이면 부정, 밖에서 쓰이면 경계의 의미를 갖는다.
Flag에 m이 설정되어 있지 않으면, 줄 바꿈 되는 부분을 문장의 경계로 인식하지 않는다. 설정을 해야 불 바꿈이 된 지점 또한 문장의 경계로 인식한다.
5. 하위 표현식
()
정규 표현식 안에서 특정 패턴을 나타내는 표현식을 하나의 항목으로 처리하는 것
하위 표현식의 용도 :
1) 가독성
010-\d{3,4}-\d{4} 보다 (010)-(\d{3,4})-(\d{4}) 가 좀 더 의미를 직관적으로 이해하기 쉽다.
2) 표현식의 반복
(표현식){n} 형태로, 표현식 내용을 n번 만큼 반복한다.
3) OR | 연산자 활용
(A|B) 형태로, A내용 또는 B내용을 포함한다.
실습
ID 생성 규칙 만들기
알파벳 소문자, 대문자, 숫자만 사용 가능
[^\w]docx 파일 찾아내기
.*\.docx주민번호 찾기
\d{6}-[1-4]\d{6]대문자로 시작하지 않는 문단 찾기
^[^A-Z].*$사칙 연산 가능한 계산기 만들기
^(\d+[+\-*\/])*\d+$심화 문법
1. 역참조
하위표현식에 일치하는 문자열을 추출하여 다른 곳에서 그 패턴을 사용할 수 있다.
- n 번째 하위 표현식 =
\n
# 중복 추출 - 단어1 공백 단어1
(\w+)\s\1
# (\w+) = \1# html 코드 제대로 작동되는지 확인하기
<h(\d)>.*<\/h\1>2. 치환
특정 패턴과 일치하는 문자열을 찾아서 원하는 문자열로 바꿀 수 있다.
FUNCTION⏩Substitution이용REGULAR EXPRESSION에 바꿀 문자열 입력,SUBSTITUTION에 치환하고 싶은 문자열 입력- 공백문자(
\n,\t등)와 역참조($)를 제외한 문법은 사용되지 않음
역참조를 활용하여 치환할 수도 있다.
# REGULAR EXPRESSION
(\w+)\s\1
# TEST STRING
Time is is gold
# SUBSTITUTION
$1
Time is gold3. 전방탐색, 후방탐색
하위 표현식이지만 결과에는 반영되지 않고 특정 문자열을 찾기 위한 조건 역할만 하는 문법으로, 문자열을 찾기 위한 패턴의 일부가 되지만 해당 정규 표현식으로 찾아지는 문자열 결과에는 반영되지 않는 하위 표현식이다.
전방탐색 (lookahead)
(?= )- 문자열의 앞부터 탐색하여 조건에 해당하는 부분이 확인되면 해당 조건 뒤쪽의 부분을 생략한다.
- 문자열의 뒷부분에서 사용 - 해당 조건이 있는 지점부터 뒷부분을 생략하는 용도
- 문자열의 앞부분에서 사용 - 문자열 안에 특정 문자가 포함되었는지 여부를 체크하는 용도
후방탐색 (lookbehind)
(?<= )- 문자열을 뒤쪽부터 탐색하여 조건에 해당하는 부분이 확인되면 걸린 부분을 제외한 나머지 값들을 선택한다.
부정 전방탐색 (Negative lookahead)
(?! )- 일치하지 않는 조건을 거는 데 사용된다.
부정 후방탐색 (Negative lookbehind)
(?<! )- 일치하지 않는 조건을 거는 데 사용된다.
실습하기
# 정규표현식
regex = r'0\d{1,2}[ -]?\d{3,4}[ -]?\d{3,4}'
# 주소록
search_target = '''Luke Skywarker 02-123-4567 luke@daum.net
다스베이더 070-9999-9999 darth_vader@gmail.com
princess leia 010 2454 3457 leia@gmail.com'''
# 정규표현식과 일치하는 부분을 모두 찾아주는 파이썬 코드
import re
result = re.findall(regex, search_target)
print("\n".join(result))