인공지능
인공지능은 "컴퓨터가 생각할 수 있는가" 라는 질문을 하면서 시작되었다. 이 분야에 대한 간결한 정의는 다음과 같다.
- 보통의 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구활동
이처럼 ai는 머신러닝과 딥러닝을 포괄하는 종합적인 분야이다.
- 심볼릭 ai
초기 체스 프로그램은 프로그래머가 만든 하드코딩된 규칙만을 가지고 있었고 머신러닝으로 인정받지 못했다.
아주 오랜기간동안 많은 전문가는 프로그래머들이 명시적인 규칙을 충분하게 많이 만들어 지식을 다루면 인간 수준의 인공지능을 만들 수 있다고 믿었다. 이런 접근방법을 심볼릭 ai라고 한다.
심볼릭 ai가 체스 게임처럼 잘 정의된 논리적인 문제를 푸는 데 적합하다는 것이 증명되었지만 이미지분류, 음성 인식, 언어 번역과 같은 더 복잡하고 불분명한 문제를 해결하기 위한 명확한 규칙을 찾는 것은 어려운 일이다. 이런 심볼릭 ai를 대체 하기 위한 새로운 방법이 머신러닝이다.
머신러닝
머신러닝은 이런 질문에서 시작한다.
"우리가 어떤것을 작동시키기 위해
어떻게 명령할지 알고있는 것이상을 컴퓨터가 처리하는 것이 가능한가? 그리고 특정 작업을 수행하는 법을 스스로 학습할 수 있는 가? 컴퓨터가 우리를 놀라게 할 수 있을까? 프로그래머가 직접 만든 데이터 처리 규칙 대신 컴퓨터가 데이터를 보고 자동으로 이런 규칙을 학습할 수 있을까?"
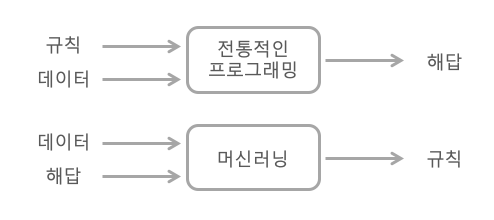
심볼릭 ai
- 심볼릭 ai의 패러다임에서는 규칙(프로그램)과 이 규칙에 따라 처리될 데이터를 입력하면
해답이 출력된다. - 머신러닝에서는 데이터와 이 데이터로부터 기대되는 해답을 입력하면
규칙이 출력된다.
머신러닝 시스템은 프로그램되는 것이 아니라 훈련되는 것이다. 작업과 관련있는 많은 샘플을 제공하면 이 데이터에서 통계적 구조를 찾아 그 작업을 자동화하기 위한 규칙을 만들어 낸다. 예를 들어 여행 사진을 태깅하는 일을 자동화하고 싶다면 사람이 이미 태그해 놓은 다수의 사진 샘플을 시스템에 제공하여 특정 사진에 태그를 연관시키기 위한 통계적 규칙을 학습할 수 있을 것이다.
데이터에서 표현을 학습하기
머신 러닝을 하기 위해서는 세가지가 필요하다.
- 입력데이터 포인트: 예를 들어 주어진 문제가 음성인식이라면 사람의 대화가 녹음된 사운드 파일이다. 만약 이미지 태깅에 관한 작업이라면 데이터 포인트는 사진이 된다.
- 기대 출력: 음성 인식 작업에서는 사람이 사운드 파일을 듣고 옮긴 글이다. 이미지 작업에서 기대하는 출력은 '강아지', '고양이' 등과 같은 태그이다.
- 알고리즘의 성능을 측정하는 방법: 알고리즘의 현재 출력과 기대 출력 간의 차이를 결정하기 위해 필요하다. 측정값은 알고리즘의 작동방식을 교정하기 위한 신호로 다시 피드백된다. 이런 수정 단계를 learning이라고 한다.
딥러닝
딥러닝의 딥은 연속된 층(layer)으로 표현을 학습한다는 개념을 나타낸다. 데이터로부터 모델을 만드는 데 얼마나 많은 층을 사용했는지가 그 모델의 깊이가 된다. 이 분야에 대한 다른 이름은 층기반 표현 학습(layered representations learning) 또는 계층적 표현 학습(hierarchical representations learning)이 될 수 있다. 최근의 딥러닝 모델은 표현 학습을 위해 수십 개, 수백 개의 연속된 층을 가지고 있다. 이 층들을 모두 훈련 데이터에 노출해서 자동으로 학습시킨다. 다른 머신 러닝 접근 방법은 1~2개의 데이터 표현 층을 학습하는 경향이 있다.
신경망
딥러닝에서는 기본층을 겹겹이 쌓아 올려 구성한 신경망이라는 모델을 사용하여 표현 층을 학습한다. 신경망이란 단어는 신경 생물학의 용어이다. 딥러닝의 일부 핵심 개념이 뇌 구조를 이해하는 것에서부터 영감을 얻어 개발된 부분이 있지만 딥러닝 모델이 뇌를 모델링한 것은 아니다. 딥러닝은 그냥 데이터로부터 표현을 학습하는 수학 모델일 뿐이다.
