셀레니움을 사용할 브라우저로 크롬을 사용할 것이기 떄문에 크롬 브라우저를 다운받아 같은 경로 상에 위치 시켜준다.
그 후 selenium의 기본적인 코드를 구글링해서 가져온다
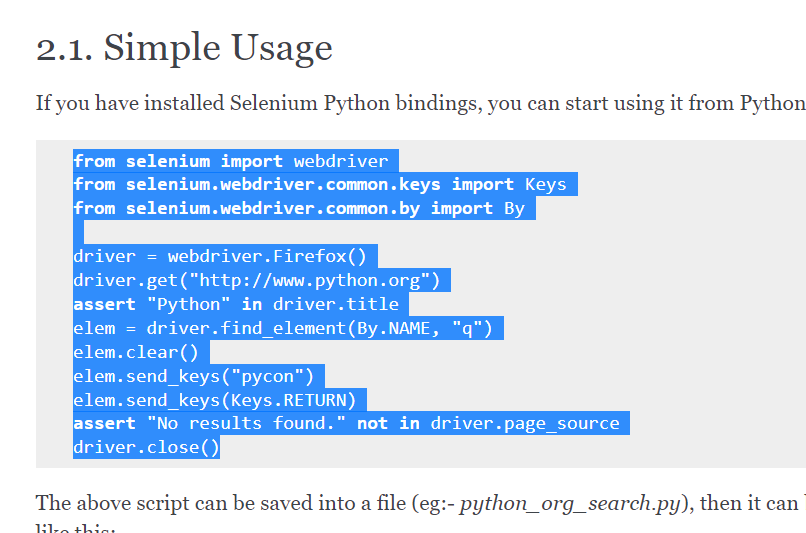
그 후 위 두 줄만 남기고 실행시키게 되면
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://www.naver.com")
# assert "Python" in driver.title
# elem = driver.find_element(By.NAME, "q")
# elem.clear()
# elem.send_keys("pycon")
# elem.send_keys(Keys.RETURN)
# assert "No results found." not in driver.page_source
# driver.close()아래처럼 자동화된 테스트 소프트웨어에 의해 제어되고 있다는 문구가 뜨면서 naver에 접속하게 된다.
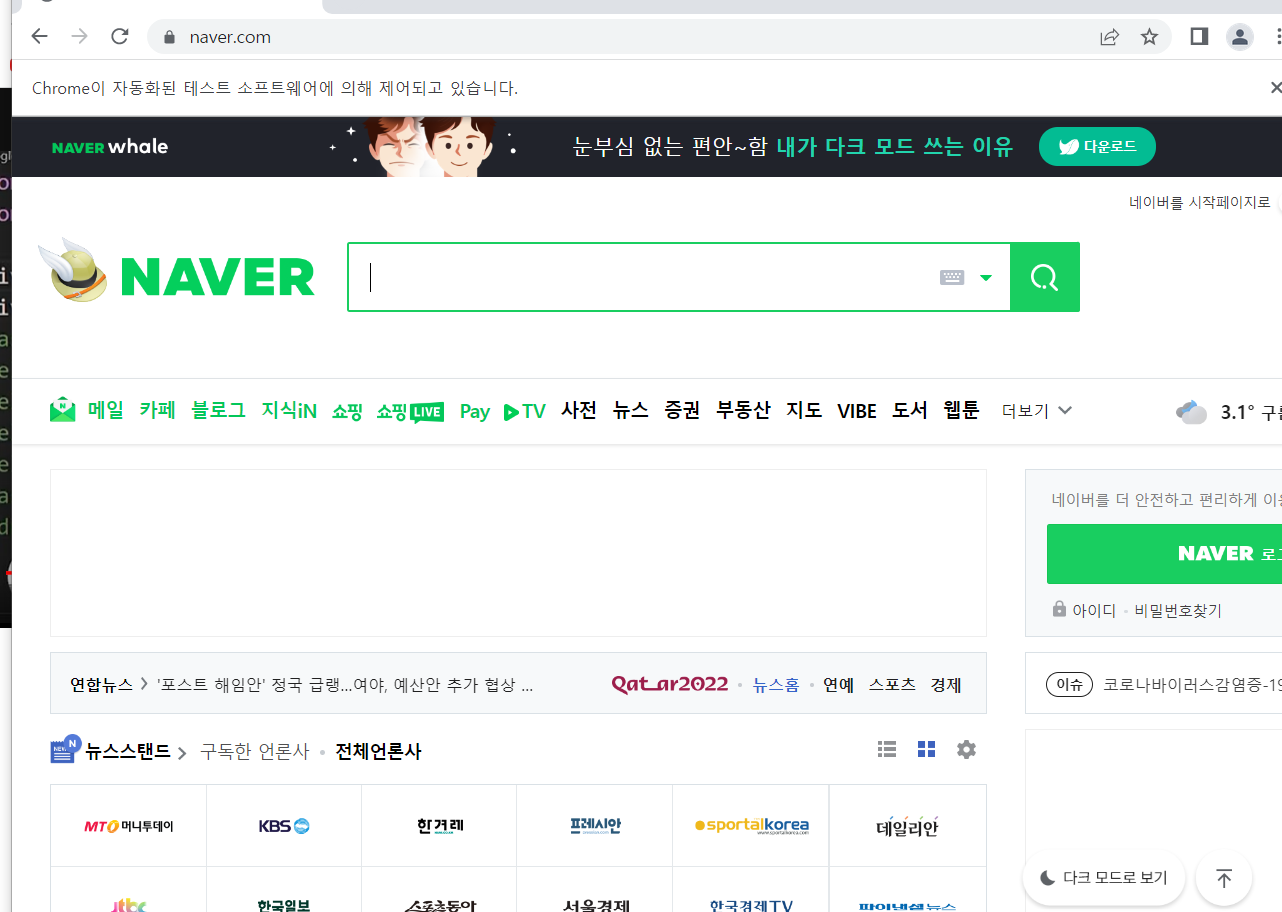
이제 검색을 해서 이미지들에 주목을 해보자.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("사과")
elem.send_keys(Keys.RETURN)
이미지를 클릭했을 때 나오는 url로 get요청을 하고 q라는 네임의 element를 찾는다.
그리고 사과라는 key를 입력하고
keys.RETURN으로 엔터키를 친다.
이것을 실행하면 이 과정들이 자동화로 실행된다.
아래 코드에서 find_element그리고 click을 통해 인덱스 2번에 이미지를 클릭까지 한다
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("사과")
elem.send_keys(Keys.RETURN)
driver.find_element(By.CSS_SELECTOR, ".rq_i.Q4LuWd")[2].click()
아래는 최종적으로 크롤링을 하는 코드이다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
import os
currentPath= os.getcwd()
os.chdir(currentPath)
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl")
elem = driver.find_element_by_name("q")
# 검색창에 사과라고 침
elem.send_keys("사과")
# 엔터키를 침
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
# 브라우저 끝까지 스크롤을 내리겠다.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
# 작은 이미지 선택하기(첫번쨰)
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
count =1
for image in images:
try:
image.click()
time.sleep(2)
# 큰이미지 주소 찍음
imgUrl = driver.find_element_by_xpath('/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div[1]/div[1]/div/div[2]/a/img').get_attribute("src")
# 이미지 다운받음
urllib.request.urlretrieve(imgUrl, "박보검 "+str(count) + ".jpg")
count = count +1
except:
pass
driver.close()
코드를 보게 되면 자바스크립트 문을 실행해서 스크롤하는 부분이 나오게 되는데 끝까지 스크롤을 해야 더 많은 이미지를 크롤링 할 수 있기 떄문이다.
중간에 클릭이 있는 이유는 구글의 로고 더보기 버튼 때문이다.
그렇게 끝까지 이미지를 로드한 뒤 작은 이미지를 클릭하고 큰 이미지의 주소를 가져와 내 컴퓨터로 다운로드하며 카운트로 이미지 번호를 매기면서 하나씩 크롤링 해올 수 있다.
허용된 웹사이트에서 마구잡이를 데이터를 담아오는 이것이 크롤링이다.

개발/보안