[PYTHON] 웹스크래핑(beautifulsoup, lxml)
beautifulsoup을 이용하여 데이터를 가공하고 lxml을 파서로 사용한다.
아래 코드를 보자
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
print(soup.title)
print(soup.title.get_text())네이버 웹툰에 들어가서 get 요청을 받은 후 받은 html코드를 BeautifulSoup으로 가공하고 lxml로 객체로 정리한다.
soup 객체에는 네이버웹툰에 대한 정보가 깔끔하게 정돈 되어 있고 soup.title과 soup.tite.get_text()를 출력한 내용은 아래와 같다.

import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
# print(soup.title)
# print(soup.title.get_text())
print(soup.a)위처럼 soup의 a태그를 지정하면 처음으로 발견되는 a태그를 반환한다.
결과는 아래와 같다.

import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
# print(soup.title)
# print(soup.title.get_text())
#print(soup.a)
print(soup.a.attrs)위처럼 attrs는 그 태그의 속성을 반환해주고 결과는 아래와 같다.

import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
# print(soup.title)
# print(soup.title.get_text())
#print(soup.a)
#print(soup.a.attrs)
print(soup.a["href"])위와 같이 대괄호를 사용하고 그 안에 원하는 속성값을 적으면 그에 대한 값이 나온다.
첫 a태그의 href는 브라우저 상에서 #menu로 이동한다.
결과는 아래와 같다.

import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
# print(soup.title)
# print(soup.title.get_text())
#print(soup.a)
#print(soup.a.attrs)
#print(soup.a["href"])
print(soup.find("a",attrs={"class" : "Nbtn_upload"}))
처음 웹사이트에 구조를 잘 모를 수 있긴 때문에 위처럼 find함수를 사용하고 a태그의 class가 "Nbtn_uplad"를 찾아달라는 명령을 내릴 수 있다.
그럼 그에 해당하는 첫번째 element를 반환하다.
결과는 아래와 같다.

다음으로는 xpath를 이용하는 것이다.
아래처럼 next_sibling으로 해당 요소의 다음 요소를 반환할 수 있다.
두번 가야하면 두번 하면된다.
그럼 그 요소의 다음 위치인 형제 요소가 반환된다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
#데이터를 가공 후 lxml로 BeautifulSoup 객체로 만든다.
# print(soup.title)
# print(soup.title.get_text())
#print(soup.a)
#print(soup.a.attrs)
#print(soup.a["href"])
#print(soup.find("a",attrs={"class" : "Nbtn_upload"}))
rank1 = soup.find("li",attrs={"class":"rank01"})
rank2 = rank1.next_sibling.next_sibling
rank3 = rank1.next_sibling.next_siblingprevious_sibling으로 전 위치로도 갈 수 있다.
parant_sibling으로 부모 요소로 갈 수 있다.
find_next_sibling()으로 다음 요소들 중 필요한 요소에만 접근할 수 있다.
그럼 정보를 이제 모두 다 빼내와보자
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
cartoons = soup.find_all("a",attrs={"class":"title"})
for cartoons in cartoons:
print(cartoons.get_text())
코드를 보면 cartoons에 a태그이고 class가 title인 모든 속성을 담고
반복문으로 cartoons의 text들을 출력한다.
결과는 아래와 같다.
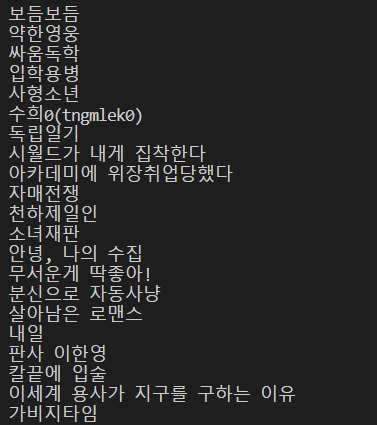
아래처럼 제목과 링크를 같이 가져올 수 도 있다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/list?titleId=641253&weekday=fri"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text,"lxml")
cartoons = soup.find_all("td",attrs={"class":"title"})
title = cartoons[0].a.get_text()
link = cartoons[0].a["href"]
print(title)
print("https://comic.naver.com"+link)
결과는 아래와 같다.

