비지도 학습
라벨이 없는 데이터들의 군집을 찾는 머신러닝 알고리즘이다. 대표적인 알고리즘 중 K-means clustering을 알아보자.
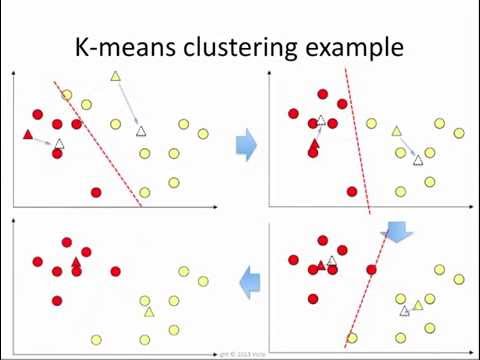
K-means 순서
1) k개의 cluster을 정한다. => 초기값 설정
2) 임의의 중심 centroid를 설정한다.
3) centroid와 데이터간의 거리를 구해 가장 까가운 cluster에 할당한다.
4) cluster들의 중심점을 다시 계산해 재설정 한다.
5) 각 데이터들이 소속 cluster가 바뀌지 않을 때까지 2-4 과정을 반복한다.
알고리즘
: 클러스터내 오차 제곱합 (cluster inertia, 왜곡값)
: 이 k번째 클러스터에 속한다 안속한다 표현 {0,1}
: n번째 데이터
: k번째 클러스터스터
위 를 최소화 시켜주는 것이 알고리즘의 핵심이다.
최적화, 최대, 최소 문제에서 언제나 그렇듯 미분이 필요하다.
이따 계속 써야지...
K-means의 한계점
1. centroid 직접 설정
- centroid를 사용자가 직접 설정 해주어야한다.
2. 유클리드 거리를 사용한다는 점
- 유클리드 거리는 feature들이 동일한 weight를 갖는다 즉 한 특징이 결과에 중요한 역할을 하는데, 동일한 weight를 갖는다면 결과가 부정확 할 수 있다.
3. Hard Clustering
- c1에 속학 확률 40%, c2에 속할 확률 60% 이런식이 아닌, 넌 c1! c2! hard 하게 확정지어서 soft clustering 해줄 필요가 있다.
2,3 문제점은 Gaussian Mixture 로 해결이 가능하다고 한다. 다음 포스트에서 알아보도록 하겠다.
참고
AAILab Kaist 문일철 교수님 유튜브 강의
https://www.youtube.com/watch?v=RF9eUtW4wsw

Feedback is a gift