Machine Learning
1.내가 이해한 서포트 벡터 머신 SVM (1)
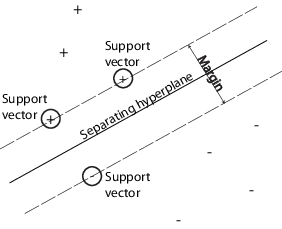
서포트 벡터 머신(SVM)은 Decision Boundary, 결정 경계선의 기준을 찾는 모델이다. 그 말인 즉, 결정 경계선의 위치가 모델의 성능을 결정한다는 뜻! SVM은 최적의 결정 경계를 찾는 알고리즘이라고 할 수 있다. 위 그림처럼 결정 경계(Separ
2021년 3월 27일
2.K-means Clustering
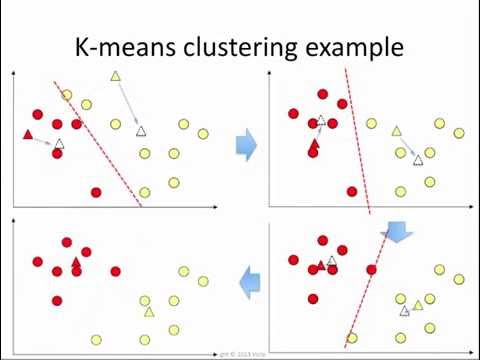
비지도 학습 라벨이 없는 데이터들의 군집을 찾는 머신러닝 알고리즘이다. 대표적인 알고리즘 중 K-means clustering을 알아보자. K-means 순서 1) k개의 cluster을 정한다. => 초기값 설정 2) 임의의 중심 centroid를 설정한다. 3)
2021년 3월 30일