YOLO란?
수많은 딥러닝 모델 중에서 실시간 대상 감지용으로 유명한 모델이다.
CNN은 계산량이 많기 때문에, 하드웨어의 성능이 중요한데
라즈베리파이와 같이 낮은 성능 환경에 딱 올리기 좋은 모델이다.
YOLO는 You Only Look Once 의 줄임말이다.
이게 사실 논문인데, 필자는 기술보고서로 주장한다고 한다.
뭐든 간에 내가 이해할 수 없는 어려운 글임에는 분명하다.
v3는 세 번째 버전을 의미하는데 현재는 v5까지 나온거 같다.
나온지 좀 되어서 자료가 충분한 v3를 직접 구현해보았다.
나는 훌륭한 분들이 옮겨놓은 코드를 가져다 쓸 뿐이다.
파일 다운로드
yolo v3 모델은 아래 사이트에서 받을 수 있다.
cfg와 weights 두 개의 파일을 받아야 하는데, weights는 클릭만으로 받을 수 있고
cfg 파일은 해당 깃허브로 연결되는데, 깃허브 페이지에서 다운로드 버튼을 찾아볼 수 없다.
어차피 텍스트 파일이므로 복사해서 저장하든지
아니면 상위 폴더로가서 압축파일을 받은 다음에 원하는 것만 압축을 풀면된다.
weights는 모델의 가중치를 담고있고, cfg는 모델의 구조에 대한 정보를 담고 있다고 한다.
나중에 코드에 넣어줄건데, 텍스트파일임에도 동작하도록 함수가 잘 만들어져 있나보다.
위 사이트에 들어가보면 YOLOv3-320, 416, 608, tiny가 있다.
뒤에 숫자는 처리할 영상의 크기를 말한다. (가로 세로가 동일하다)
FPS를 보게되면 당연히 크기가 작을수록 높은 속도를 보이는데, tiny가 압도적으로 빠르다.
정확도는 대신에 떨어진다고 한다.
라즈베리파이에 올릴 목적이라면 tiny가 적절하겠다.
영상 크기에 따라 파일이 분리되어 있지만 받아보니
tiny를 제외하고는 모두 동일한 파일이다.
추가로 80개의 클래스 이름이 저장된 아래 깃허브의 텍스트 파일이 필요하다.
참고로 딥러닝에서는 분류 대상 하나하나를 '클래스'라고 부른다.
객체 지향에서 말하는 '클래스'와 혼동하지 말자.
굳이 텍스트 파일을 안 쓰고 싶다면 일일이 리스트로 작성하는 방법도 있다.
코드 분석
이제 코드를 보자.
쓰게될 코드는 모두 아래 유튜브 영상을 보고 따라친 수준이다.
비록 한국어가 아니지만 인도 영어라 잘 들리는 편이다.
import cv2
import numpy as np보다시피 파이썬으로 작성했다.
우선 두 가지 모듈이 필요하다.
OpenCV와 Numpy
내가 실행한 환경은 아래와 같다.
python 3.7.10
opencv 3.4.2
numpy 1.19.2
상수 설정
device = 0
cap = cv2.VideoCapture(device)
whT = 320
confThreshold_1 = 0.5
confThreshold_2 = 0.7
nmsThreshold = 0.3
classesFile = 'coco.names'
with open(classesFile, 'rt') as f:
classNames = f.read().split('\n')절차 지향의 코드임에도 순서대로 설명을 한다는 것이 쉽지 않은 것 같다.
뒤에 코드를 보지 않고서는 여기있는 변수들이 무엇인지 이해하기 힘들다.
우선 영상을 가져오기 위해서 기본적인 opencv의 함수인 VideoCapture를 사용했다.
device는 노트북일 경우 0을 넣으면 내장캠이 실행된다.
whT는 변경될 영상 크기이다. 불러온 영상을 처리하기 위해 whT 크기로 손질한다.
그리고 세가지의 threshold 변수가 등장하는데 threshold는 번역하면 문턱이라는 뜻이다.
주로 디지털 자료를 다룰 때 기준점이 되는 역할이다.
마지막 부분은 클래스 이름이 저장된 coco.names 파일을 열어서 파일 내용을 저장한다.
아직 파일을 읽고 쓰는 것이 익숙하지 않아서 제일 어색한 코드다.
읽기 모드로 파일을 열고, 읽은 데이터를 \n 띄어쓰기를 기준으로 잘라서 리스트 형태로 저장한다.
(split 함수를 쓰면 문자열 타입으로, 그리고 리스트 자료형으로 저장된다.)
모델 불러오기
model_config = 'yolov3-tiny.cfg'
model_weights = 'yolov3-tiny.weights'
net = cv2.dnn.readNetFromDarknet(model_config, model_weights)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)이제 yolov3 모델을 불러오는 과정이다.
보면 알겠지만, 이미 너무 유명한 모델이라
opencv 자체에서 함수로 API를 제공하고 있다.
이건 API가 그런 것이니 따로 설명할게 없다. 그냥 그대로 쓰면된다.
(API에 대한 개념을 정확히 몰라서 잘못된 말일 수도 있다. 무슨 의도로 한 말인지는 이해할거라 생각한다.)
객체 식별 함수
def findObjects(outputs, img):
hT, wT, cT = img.shape
bbox = []
classIds = []
confs = []
for output in outputs:
for det in output:
scores = det[5:]
classIds = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold_1:
w, h = int(det[2]*wT), int(det[3]*hT)
x, y = int((det[0]*wT) - w/2), int((det[1]*hT) - h/2)
bbox.append([x,y,w,h])
classIds.append(classId)
confs.append(float(confidence))
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold_2, nmsThreshold)
print(f"식별된 대상 : {len(indices)} 개")
for i in indices:
i = i[0]
box = bbox[i]
x, y, w, h = box[0], box[1], box[2], box[3]
cv2.rectangle(img, (x,y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(img, f"{classNames[classIds[i]].upper()} {int(confs[i]*100)}%",
(x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)무시무시한 함수가 하나 등장해버렸다.
함수의 역할부터 말하자면 이미지를 yolo 모델에 통과시킨 결과들을 정리해서
미리 학습한 클래스에 속한 대상일 확률이 높은 것들만 영상에서 박스 쳐주는 함수다.
yolo 모델을 통과한 output은 총 3개이다.
이 세가지 output 들이 저장된 리스트가 outputs이다.
output 리스트 내부구조
output들은 각각 300, 1200, 4800개의 식별된 대상에 대한 정보를 가지고 있다.
그 원소 하나하나는 또 85개의 정보를 담고 있는데 다음과 같다.
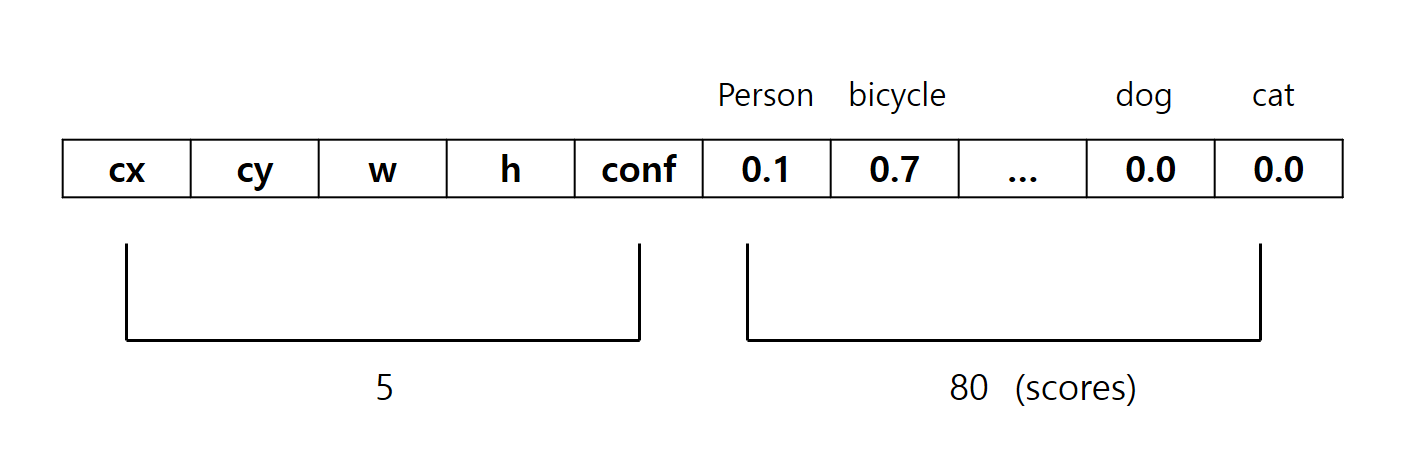
cx ,cy는 대상의 중점 좌표이고 w, h는 대상의 너비, 높이이다.
conf는 confidence의 줄임인데, 앞의 4가지 정보에 의해 생성된 박스 내부에 대상이 존재할 확률이다.
그리고 나머지 80개의 정보는 미리 학습된 80개의 클래스에 대해서
앞의 4가지 정보가 가리키는 대상이 해당 클래스일 확률을 의미한다.
(참고로 클래스 순서는 위와 다르다. 맨 끝 두 클래스는 dog, cat이 아니다. 내가 임의로 넣은거다.)
아무튼 이렇게 복잡한 데이터가 총 300+1200+4800 = 6300개나 있는거다.
영상 한 프레임에 박스를 6300개씩이나 그리고 있을순 없으니까, 이 중에서 확률이 높은 것만 걸러낸다.
한 가지 오해의 소지가 있을 수 있는데, 위 코드에서 말하는 confidence는
표에서 나타난 5번째 원소를 가리키는 것이 아니라
80개의 클래스 확률 중에서 가장 높은 확률을 의미한다.
6300개의 데이터를 하나씩 차근차근 for문을 돌면서
우선 '클래스 확률' 원소들만 따로 분리해서 scores 변수에 넣고
np.argmax 함수를 사용해서 scores 중 가장 높은 확률을 가진 클래스의 인덱스를
classId 변수에 저장한다.
그리고 그 클래스의 확률을 confidence 변수에 저장한다.
이 confidence가 미리 설정한 threshold 값인 0.5를 넘긴 데이터들만 저장하는데
cx, cy, w, h가 소수점으로 표기되어 있기 때문에
미리 저장해둔 image의 픽셀 값들을 곱해줘야 원하는 값이 된다.
cx, cy는 중점이므로 w/h, h/2를 빼주어서 박스의 시작 꼭짓점으로 만들어준다.
그리고 픽셀값은 정수형이므로 타입변환을 해준다.
NMS 알고리즘
이렇게 걸러진 것들을 한 번더 걸러주는데
아래 사진처럼 같은 대상에 대해서 크기가 서로 다른 박스가 여러개 그려지는 것을 예방하기 위함이다.

이 때 사용하는 것이 NMS (None Maximum Suppression)이라는 알고리즘? 이다.
대충 대장빼고 자투리는 버린다는 뜻이다.
내가 설명하는 것은 정확한 알고리즘 동작 방식은 아니고 NMS 를 사용하기 위해서
NMSBoxes 함수의 인자들을 커스터마이징 할 수 있는 수준의 이해결과이다.
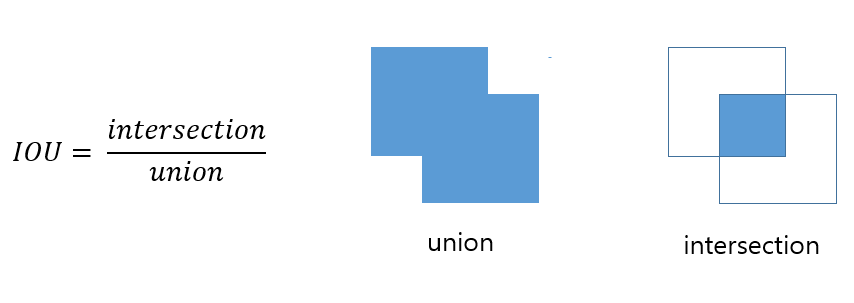
IOU
우선 IOU (Intersection Over Union)라는 것을 알아야한다.
모든 수학에 통용되는 개념인지는 모르겠으나
여기서는 겹치는 두 사각형의 합집합 면적에 대한 교집합 면적의 비율이다.
아래 그림을 보면 쉽게 이해할 수 있다.
NMSBoxes함수는 박스에 대한 정보를 받고
클래스에 대한 confidence_threshold와 NMS_threshold를 인자로 받는다.
confidence_threshold도 인자로 받는 것을 보면
굳이 앞에서 if 조건문을 통과시켜서 한 번 걸러줄 필요가 없다.
여기서 한 번에 confidence와 NMS로 거를 수 있다.
if 조건문을 없애고 실행해보니 실제로 잘 동작했다.
하지만 성능에 어떤 차이가 있는지 확실히 알 수 없어서
우선은 내가 참고한 유튜브 영상에서 하는 방식을 따랐다.
다만 내가 변형한 것은 confidence_threshold를 두개로 나누어서
NMSBoxes 함수를 사용할 때는 threshold값을 더 높였다.
더 미세한 거름망을 준비한 것이라 볼 수 있겠다.
NMS_threshold는 보통 0.3이나 0.5를 많이 사용하는 것 같은데
0.5를 해보니 같은 대상에 두 박스가 그려지는 현상을 볼 수 있었다.
NMS가 제대로 작동하지 않은 것인가??
그 이유는 NMS_threshold가 IOU 값이기 때문이다.
가령, 면적이 두 배 이상 차이나는 두 개의 박스가 있을 때,
작은 박스가 큰 박스에 완전히 겹쳐진다면 IOU는 0.5보다 작다.
이 때, NMS_threshold가 0.5라면, 이 경우는 NMS 알고리즘에 의해 걸러지지 않는다.
그래서 NMS_threshold 값을 너무 크게하면 앞서 본 사진과 같이
큰 박스와 작은 박스들이 동일한 대상에 함께 그려지는 현상이 나타난다.
어쨌든 NMSBoxes함수는 걸러진 박스 데이터의 인덱스들을 리스트 속의 리스트로 반환해준다.
이제 걸러진 데이터들을 토대로 이미지에 그리기만 하면된다.
rectangle함수의 마지막 인자는 두께를 나타낸다.
opencv에서 주의할 점은 원점이 남서쪽에 있는게 아니라 북서쪽에 있다.
그래서 박스위에 클래스명을 적어주기위해
putText함수는 시작위치의 y값에 10만큼 빼주는 것이다.
while 루프
while True:
success, img = cap.read()
if not success:
break
blob = cv2.dnn.blobFromImage(img, 1/255, (whT, whT), [0,0,0], True, crop=False)
net.setInput(blob)
layerNames = net.getLayerNames()
outputNames = [layerNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
outputs = net.forward(outputNames)
findObjects(outputs, img)
cv2.imshow("Image", img)
key = cv2.waitKey(1)
if key == 27:
break준비는 끝났다. 실행할 while 루프만 짜면된다.
VideoCapture를 read함수로 읽어들이면 img뿐만 아니라
성공적으로 읽어들였는지를 확인할 bool 값을 반환한다.
성공했을 때 True 값이 반환된다.
blob 이라는 굉장히 생소한 것이 등장하는데 binary large object의 줄임말이다.
주로 이미지, 비디오, 사운드 같은 큰 데이터 객체를 이진수로 변환하여 저장할 때 사용한다고 한다.
'영상을 컴퓨터가 더 다루기좋게 전처리한다.' 정도로 알아두면 될 것 같다.
blobFromImage함수의 파라메터는 아래와 같다.
blobFromImage(image, scalefactor, size, mean, swapRB, crop)
-
scalefactor는 채도 값에 대한 계수를 말한다.
tensorflow에서와 같이 학습된 데이터와 동일하게 맞춘다고255로 나누는 것 같다. -
size는 변환될 크기,mean은 채도값을 이 평균값으로 빼준다.
근데 여기서는[0,0,0]이므로 빼지 않는다. -
swapRB는RGB를BGR순으로 또는 그 역으로 바꾸는건데
opencv는 기본적으로BGR순으로 되어있다. -
crop은 이미지 크기를 변환할 때
상태 그대로 크기만 늘리고 줄일 건지 자르면서 크기를 줄일건지를 결정한다.
True로 놓으면 축소시킬때 가운데를 기준으로 잘라서 줄어든 형태로 반환할거다. (추정이다)
getUnconnectedOutLayers 함수는 yolo 모델의 여러가지 layer들 중 output layer의 이름만 뽑아낸다.
여기까지가 설명이다.
실행하기
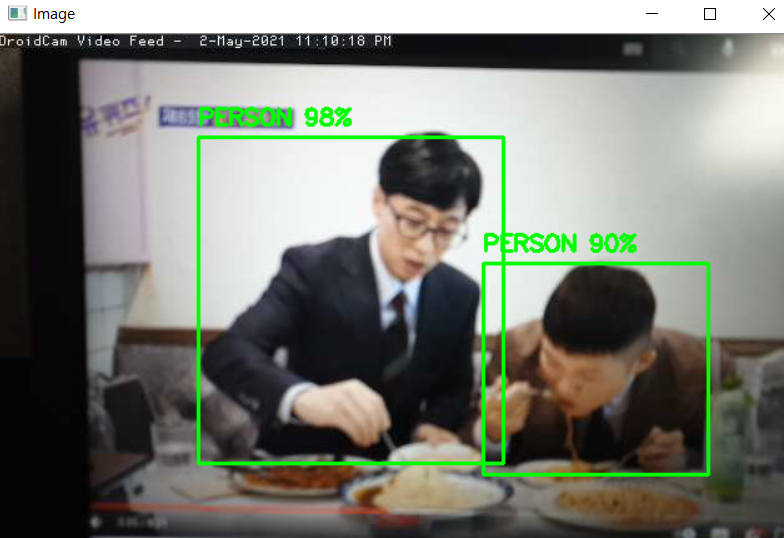
작동은 droidcam이라는 어플을 사용해서 스마트폰으로 노트북의 유튜브 영상을 촬영해봤다.
유재석씨와 조세호씨를 사람으로 잘 판단하고 있다.
동일 대상에 대해서 작은 박스들이 한번씩 나타났는데 NMS_threshold 값을 더 낮추면 좋을 것 같다.
droidcam의 사용법은 간단하다.
노트북과 스마트폰을 같은 와이파이로 잡고
droidcam 어플을 실행시키면 IP Cam Access: 라고 두가지 주소가 나오는데
그 중에서 /video 로 끝나는 주소를 그대로 위 코드의 device 변수에 0 대신 넣어주면 된다.
근데 어플명에서도 유추할 수 있듯이 아이폰은 안 되는걸로 알고있다.
전체코드
import cv2
import numpy as np
device = 0
cap = cv2.VideoCapture(device)
whT = 320
confThreshold_1 = 0.5
confThreshold_2 = 0.7
nmsThreshold = 0.3
classesFile = 'coco.names'
with open(classesFile, 'rt') as f:
classNames = f.read().split('\n')
model_config = 'yolov3-tiny.cfg'
model_weights = 'yolov3-tiny.weights'
net = cv2.dnn.readNetFromDarknet(model_config, model_weights)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
def findObjects(outputs, img):
hT, wT, cT = img.shape
bbox = []
classIds = []
confs = []
for output in outputs:
for det in output:
scores = det[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold_1:
w, h = int(det[2]*wT), int(det[3]*hT)
x, y = int((det[0]*wT) - w/2), int((det[1]*hT) - h/2)
bbox.append([x,y,w,h])
classIds.append(classId)
confs.append(float(confidence))
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold_2, nmsThreshold)
print(f"식별된 대상 : {len(indices)} 개")
for i in indices:
i = i[0]
box = bbox[i]
x, y, w, h = box[0], box[1], box[2], box[3]
cv2.rectangle(img, (x,y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(img, f"{classNames[classIds[i]].upper()} {int(confs[i]*100)}%",
(x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
while True:
success, img = cap.read()
if not success:
break
blob = cv2.dnn.blobFromImage(img, 1/255, (whT, whT), [0,0,0], True, crop=False)
net.setInput(blob)
layerNames = net.getLayerNames()
outputNames = [layerNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
outputs = net.forward(outputNames)
findObjects(outputs, img)
cv2.imshow("Image", img)
key = cv2.waitKey(1)
if key == 27:
break
