버블 정렬 (Bubble Sort)
버블정렬은 서로 인접해 있는 요소 간의 대소 비교를 통해 정렬한다.
동작 방식은 인접한 두 요소간의 대소 비교를 진행한다.
최선 : O(n)
평균 : O(n^2)
최악 : O(n^2)
코드(Kotlin)
val arr = intArrayOf(1,5,3,2,4)
fun bubbleSort(){
for(i in arr.indices){
for(j in 0 until arr.size-i-1){
if(arr[j] > arr[j+1]){
val tmp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = tmp
}
}
}
println(arr.contentToString())
}출력
[1,2,3,4,5]
삽입 정렬(Insert Sort)
삽입 정렬이란 정렬을 진행할 원소의 index보다 낮은 곳에 있는 원소들을 탐색하며 알맞은 위치에 삽입해주는 정렬 알고리즘이다.알고리즘이 동작하는 동안 계속해서 정렬이 진행되므로 반드시 맨 왼쪽 index까지 탐색하지 않아도 된다는 장점이 있다.
최선 : O(n)
평균 : O(n^2)
최악 : O(n^2)
코드(Kotlin)
val arr = intArrayOf(1, 5, 3, 2, 4)
fun insertSort() {
for (i in 1 until arr.size) {
for (j in i downTo 1) {
if (arr[j - 1] > arr[j]) {
val tmp = arr[j - 1]
arr[j - 1] = arr[j]
arr[j] = tmp
}
}
}
println(arr.contentToString())
}출력
[1,2,3,4,5]
선택 정렬(Selection Sort)
선택 정렬이란 배열에서 최소값을 반복적으로 찾아 정렬하는 알고리즘이다.
1. 주어진 배열에서 최소값을 찾는다.
2. 최소값을 맨 앞의 값과 바꾼다.
3. 바꿔준 맨 앞 값을 제외한 나머지 원소를 동일한 방법으로 바꿔준다
반대로 하면 내림차순으로 정렬할 수 있다.
최선 : O(n^2)
평균 : O(n^2)
최악 : O(n^2)
코드(Kotlin)
val arr = intArrayOf(1, 5, 3, 2, 4)
fun selectionSort() {
for (i in arr.indices) {
var idx = i
for (j in i + 1 until arr.size) {
if (arr[idx] > arr[j]) {
idx = j
}
}
val tmp = arr[idx]
arr[idx] = arr[i]
arr[i] = tmp
}
println(arr.contentToString())
}출력
[1,2,3,4,5]
퀵 정렬(Quick Sort)
퀵 정렬은 분할정복법과 재귀를 사용해 정렬하는 알고리즘이다.
하나의 리스트를 피벗(pivot)을 기준으로 두 개의 부분리스트로 나누어 하나는 피벗보다 작은 값들의 부분리스트, 다른 하나는 피벗보다 큰 값들의 부분리스트로 정렬한 다음, 각 부분리스트에 대해 다시 위 처럼 재귀적으로 수행하여 정렬하는 방법이다.
최선 : O(nlogn)
평균 : O(nlogn)
최악 : O(n^2)
코드(Kotlin)
val array = intArrayOf(1, 5, 3, 2, 4)
fun quickSort(array : IntArray, low : Int, high : Int){
//low가 high 보다 크거나 같다면 정렬 할 원소가 1개 이하이므로 return
if(low >= high){
return
}
val pivot = partition(array,low,high)
quickSort(array, low, pivot - 1)
quickSort(array, pivot + 1, high)
}
fun partition(array: IntArray, left : Int, right : Int) : Int{
var low = left
var high = right
//부분 배열의 왼쪽 요소를 pivot으로 설정
val pivot = array[left]
//low가 high보다 작을 때 까지만 반복
while(low < high){
//array[high]가 pivot보다 크고 high가 low보다 클때 high 감소
while(array[high] > pivot && low < high){
high--
}
//array[lpw]가 pivot보다 작거나 같고 high가 low보다 클때 low증가
while(array[low] <= pivot && low < high){
low++
}
//교환 할 두 요소를 찾았으면 두 요소 swap
val tmp = array[low]
array[low] = array[high]
array[high] = tmp
}
//마지막으로 맨 처음 pivot 설정했던 위치의 원소와 array[low]원소 스왑
val tmp = array[left]
array[left] = array[low]
array[low] = tmp
//두 요소가 교환되면 피벗 요소가 low 위치에 있으므로 low 반환환
return low
}
출력
[1,2,3,4,5]
병합 정렬(Merge Sort)
병합 정렬은 분할정복과 재귀 알고리즘을 사용하는 정렬 알고리즘이다.
- 주어진 리스트를 절반으로 분할하여 부분리스트로 나눈다.
- 해당 부분리스트의 길이가 1이 아니라면 1번 과정을 되풀이한다.
- 인접한 부분리스트끼리 정렬하여 합친다.
최선 : O(nlogn)
평균 : O(nlogn)
최악 : O(nlogn)
코드(Kotlin)
val arr = intArrayOf(1, 5, 3, 2, 4)
val sortedArr = IntArray(arr.size)
mergeSort(arr, sortedArr, 0, arr.size - 1)
println(arr.contentToString())
fun mergeSort(arr: IntArray, sortedArr: IntArray, start: Int, end: Int) {
//start == end는 부분배열이 1개 원소만 갖고 있으므로 return
if (start == end) {
return
}
val mid = (start + end) / 2
mergeSort(arr, sortedArr, start, mid)
mergeSort(arr, sortedArr, mid + 1, end)
merge(arr, sortedArr, start, mid, end)
}
fun merge(arr: IntArray, sortedArr: IntArray, start: Int, mid: Int, end: Int) {
var left = start
var right = mid + 1
var idx = start
while (left <= mid && right <= end) {
//왼쪽 부분배열 첫 번째 원소가 오른쪽 부분 배열 r번째 원소보다 작거나 같을 경우
//왼쪽의 첫번째 원소를 새 배열을 넣고 1과 idx를 1 증가
if (arr[left] <= arr[right]) {
sortedArr[idx] = arr[left]
idx++
left++
}
//오른쪽 부분배열 r 번째 원소가 왼쪽 부분 배열 첫번째 원소보다 작거나 같을 경우
//오른쪽의 r번째 원소를 새 배열을 넣고 r과 idx를 1 증가
else {
sortedArr[idx] = arr[right]
idx++
right++
}
}
/*
* 왼쪽 부분배열이 먼저 모두 새 배열에 채워졌을 경우 (l > mid)
* 오른쪽 부분배열 원소가 아직 남아있을 경우
* 오른쪽 부분리스트의 나머지 원소들을 새 배열에 채워준다.
*/
if (left > mid) {
while (right <= end) {
sortedArr[idx] = arr[right]
idx++
right++
}
}
/*
* 오른쪽 부분배열이 먼저 모두 새 배열에 채워졌을 경우 (right > end)
* 왼쪽 부분배열 원소가 아직 남아있을 경우
* 왼쪽 부분배열의 나머지 원소들을 새 배열에 채워준다.
*/
else {
while (left <= mid) {
sortedArr[idx] = arr[left]
idx++
left++
}
}
for (i in start..end) {
arr[i] = sortedArr[i]
}
}
출력
[1,2,3,4,5]
힙 정렬(Heap Sort)
힙이란 트리 기반의 자료구조로서, 두 개의 노드를 가진 완전 이진 트리를 의미한다. 따라서 힙 정렬이란 완전 이진 트리를 기반으로 하는 정렬 알고리즘이다. 힙의 분류는 크게 최대 힙과 최소 힙 두 가지로 나뉜다. 최대 힙은 내림차순 정렬에 사용하며, 최소 힙은 오름차순 정렬에 사용한다.
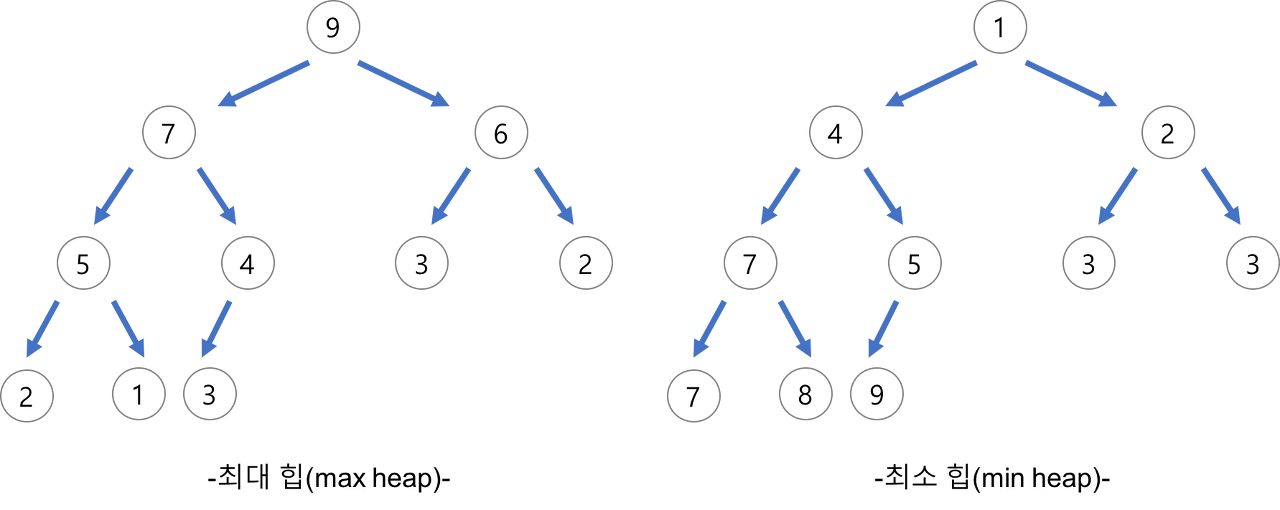
최대힙의 경우 부모 노드가 항상 자식노드 보다 크다는 특징을 가진다. 반대로 최소힙의 경우 부모 노드가 항상 자식노드 보다 작다는 특징을 가진다. 이러한 힙에서 오해할 수 있는 특징은 힙은 정렬된 구조가 아니다. 부모 자식 간의 대소 관계만 나타내며 좌우 관계는 나타내지 않기 때문이다. 예를 들어 최소 힙에서 대부분 왼쪽 노드가 오른쪽 노드보다 작지만 4의 자식 노드인 7과 5는 왼쪽이 오른쪽보다 크다.
최선 : O(nlogn)
평균 : O(nlogn)
최악 : O(nlogn)
코드
val arr = intArrayOf(1, 5, 3, 2, 4)
Sorting().heapSort(arr)
println(arr.contentToString())
fun heapSort(arr: IntArray) {
val size = arr.size
// 부모노드와 heaify과정에서 음수가 발생하면 잘못 된 참조가 발생하기 때문에
// 원소가 1개이거나 0개일 경우는 정렬 할 필요가 없으므로 바로 함수를 종료한다.
if (size < 2) {
return
}
// 가장 마지막 노드의 부모 노드 인덱스
val parentIdx = (size - 2) / 2
// max heap 만들기
for (i in parentIdx downTo 0) {
// 부모노드(i값)을 1씩 줄이면서 heap 조건을 만족시키도록 재구성한다.
heapify(arr, i, size - 1)
}
// 정렬 과정
for (i in size - 1 downTo 1) {
/*
* root인 0번째 인덱스와 i번째 인덱스의 값을 교환해준 뒤
* 0 ~ (i-1) 까지의 부분트리에 대해 max heap을 만족하도록
* 재구성한다.
*/
val tmp = arr[0]
arr[0] = arr[i]
arr[i] = tmp
heapify(arr, 0, i - 1)
}
}
fun heapify(arr: IntArray, parentIdx: Int, lastIdx: Int) {
var pIdx = parentIdx
var leftChildIdx = 0
var rightChildIdx = 0
var largestIdx = 0
/*
* 현재 부모 인덱스의 자식 노드 인덱스가
* 마지막 인덱스를 넘지 않을 때 까지 반복한다.
*
* 이 때 왼쪽 자식 노드를 기준으로 해야 한다.
* 오른쪽 자식 노드를 기준으로 범위를 검사하게 되면
* 마지막 부모 인덱스가 왼쪽 자식만 갖고 있을 경우
* 왼쪽 자식노드와는 비교 및 교환을 할 수 없기 때문이다.
*/
while ((pIdx * 2) + 1 <= lastIdx) {
leftChildIdx = (pIdx * 2) + 1
rightChildIdx = (pIdx * 2) + 2
largestIdx = pIdx
/*
* left child node와 비교
* (범위는 while문에서 검사했으므로 별도 검사 필요 없음)
*/
if (arr[leftChildIdx] > arr[largestIdx]) {
largestIdx = leftChildIdx
}
/*
* right child node와 비교
* right child node는 범위를 검사해주어야한다.
*/
if (rightChildIdx <= lastIdx && arr[rightChildIdx] > arr[largestIdx]) {
largestIdx = rightChildIdx;
}
/*
* 교환이 발생했을 경우 두 원소를 교체 한 후
* 교환이 된 자식노드를 부모 노드가 되도록 교체한다.
*/
if (largestIdx != pIdx) {
val tmp = arr[pIdx]
arr[pIdx] = arr[largestIdx]
arr[largestIdx] = tmp
pIdx = largestIdx
} else {
return;
}
}
}
계수 정렬(Counting Sort)
카운팅 정렬은 수많은 정렬 알고리즘 중 시간복잡도가 𝚶(𝑛) 으로 엄청난 성능을 보여주는 알고리즘이다.
- array 를 한 번 순회하면서 각 값이 나올 때마다 해당 값을 index 로 하는 새로운 배열(counting)의 값을 1 증가시킨다.
- counting 배열의 각 값을 누적합으로 변환시킨다.
- 해당 값에 대응되는 위치에 배정한다.
최선 : O(n)
평균 : O(n+k)
최악 : O(n+k)
단점은 counting 배열이라는 새로운 배열을 선언해주어야 한다. array 안에 있는 max값의 범위에 따라 counting 배열의 길이가 달라지게 된다. 예로들어 10개의 원소를 정렬하고자 하는데, 수의 범위가 0~1억이라면 메모리가 매우 낭비가 된다.
즉, Counting Sort가 효율적인 상황에서 쓰려면 수열의 길이보다 수의 범위가 극단적으로 크면 메모리가 엄청 낭비 될 수 있다는 것. 그렇기 때문에 각기 상황에 맞게 정렬 알고리즘을 써야하는데, 퀵 정렬이나 병합정렬 등이 선호되는 이유도 이에 있다.
Quick 정렬의 경우 시간복잡도 평균값이 𝚶(nlogn) 으로 빠른편이면서 배열도 하나만 사용하기 때문에 공간복잡도는 𝚶(𝑛) 으로 시간과 메모리 둘 다 효율적이라는 점이다.
val arr = intArrayOf(1, 5, 3, 2, 4)
val res = IntArray(arr.size)
Sorting().countingSort(arr, res)
println(res.contentToString())
fun countingSort(arr: IntArray, res: IntArray) {
val counting = IntArray(arr.maxOrNull()!! + 1)
// 첫 번째
for (i in arr.indices) {
counting[arr[i]]++
}
//두 번째
for (i in 1 until counting.size) {
counting[i] += counting[i - 1]
}
//세 번째
for (i in arr.size - 1 downTo 0) {
val value = arr[i]
counting[value]--
res[counting[value]] = value
}
}참고한 레퍼런스
https://st-lab.tistory.com/233
https://roytravel.tistory.com/328
