
Case문 활용
데이터베이스 Call을 반복적으로 일으키는 프로그램을 One-SQL로 통합했을 때 얻는 성능개선 효과는 매우 극적이다.
하나의 업무에 대해서

이렇게 쿼리를 작성하면 같은 테이블을 여러 번 접근해야 한다는 점에서 효율적이지 못하다.

이렇게 CASE문을 활용한다면 복잡한 처리절차를 ONE-SQL로 구현하여 효율적인 구문을 작성할 수 있다. (DECODE 함수도 마찬가지)
데이터 복제 기법 활용
SQL을 작성하다 보면 데이터 복제 기법을 활용해야 할 때가 많다. 전통적으로 많이 쓰던 방식은 아래와 같은 복제용 테이블을 미리 만들어두고 이를 활용하는 것이다.
create table copy_t(no number, no2 varchar(2));
insert into copy_t select rownum, lpad(rownum, 2, '0') from big_table where rownum <= 31;
alter table copy_t add constraint copy_t_pk primary key(no);
create unique index copy_t_no2_idx on copy_t(no2);이렇게 복제용 테이블을 생성한 후...
select * from emp a, copy_t b where b.no <= 2;이런 식으로 구문을 작성해주면 기존 emp 테이블을 두 배로 복사해준다. 일단 copy_t의 행 수는 2개가 될 것이며 emp 테이블과 조인 관계가 없으므로 카티션 곱이 발생하게 되기 때문이다.
참고로 Oracle 9i부터는...
select * from emp a, (select rownum no from dual connect by level <= 2) b;이렇게 dual 테이블을 사용하여 편하게 결과를 보여줄 수도 있다.
Union All을 활용한 M:M 관계의 조인
M:M 관계의 조인을 해결하거나 Full Outer Join을 대체하는 용도로 Union All을 활용할 수 있다.
select nvl(a.상품, b.상품) as 상품 ,
nvl(a.계획연월, b.판매연월) as 연월 ,
nvl(계획수량, 0) 계획수량 ,
nvl(판매수량, 0) 판매수량
from ( select 상품,
계획연월,
sum(계획수량) 계획수량
from 부서별판매계획
where 계획연월 between '200901' and '200903'
group by 상품, 계획연월 ) a
full outer join
( select 상품,
판매연월,
sum(판매수량) 판매수량
from 채널별판매실적
where 판매연월 between '200901' and '200903'
group by 상품, 판매연월 ) b
on a.상품 = b.상품 and a.계획연월 = b.판매연월;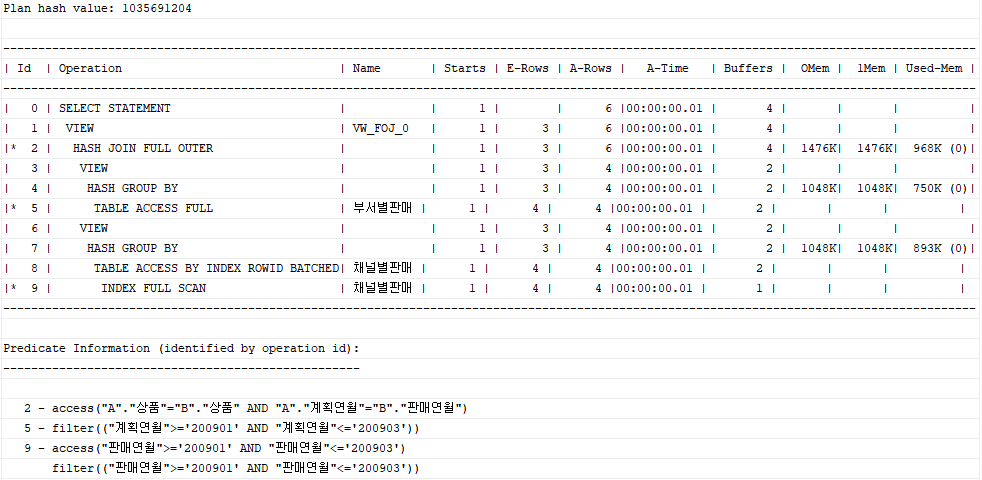
Full Outer Join은 구문을 비효율적으로 처리하는 경향이 있다. 이럴 때...
select a.상품, a.연월, sum(nvl(a.계획수량, 0)) as 계획수량, sum(nvl(a.실적수량, 0)) as 실적수량
from
(select '계획' as 구분, 상품, 계획연월 as 연월, 판매부서, null as 판매채널, 계획수량, to_number(null) as 실적수량
from 부서별판매계획
where 계획연월 between '200901' and '200903'
union all
select '실적' as 구분, 상품, 판매연월 as 연월, null as 판매부서, 판매채널, to_number(null) as 계획수량, 판매수량
from 채널별판매실적
where 판매연월 between '200901' and '200903') a
group by a.상품, a.연월;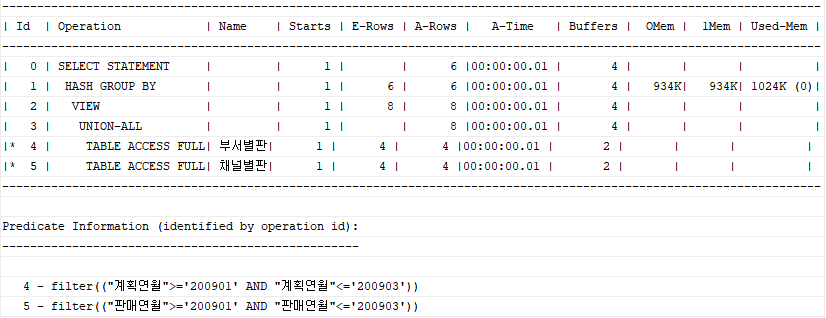
Union All을 활용하면 좀 더 효율적으로 처리할 수 있게 된다. Full Outer Join 중 조인 조건으로 합친 부분을 group by로 대신해서 처리하였다.
페이징 처리
조회할 데이터가 일정량 이상이고 수행빈도가 높으면 반드시 페이징 처리를 해야한다.
일반적인 페이징 처리용 SQL
select *
from (select rownum no, 거래일시, 체결건수, 체결수량, 거래대금, count(*) over() cnt
from (select 거래일시, 체결건수, 체결수량, 거래대금
from 시간별종목거래
where 종목코드 = :isu_cd and 거래일시 >= :trd_time
order by 거래일시)
where rownum <= :page*:pgsize + 1)
where no between (:page - 1) * :pgsize + 1 and :page * :pgsize;trd_time : 사용자가 입력하는 거래일시
pgsize : 페이지 크기(페이지 당 데이터 개수)
page : 현재 페이지
isu_cd : 사용자가 입력하는 종목코드
인라인 뷰의 cnt는 다음 페이지에 읽을 데이터가 있는지를 알기 위한 용도다. 말 그대로 전체 행의 개수를 나타내고 있으며 현재 페이지의 마지막 행 번호인 :page :pgsize보다 크다면 다음 데이터가 존재한다는 것을 알 수 있다. 현재 :page :pgsize보다 크다(데이터가 더 있다)는 것을 담기 위해 인라인 뷰 내의 인라인 뷰에서 조건절에
rownum <= :page * :pgsize + 1
이라고 써둔 것이다. 지금까지 누적된 행 수보다 하나 더 많도록 설정해둔 것이다.
성능과 I/O 효율을 위해서는 [종목코드 + 거래일시] 순으로 구성된 인덱스가 필요하며, 이 인덱스의 도움을 받을 수만 있다면 정렬작업을 수행하지 않아도 되므로 전체 결과집합이 아무리 크더라도 첫 페이지만큼은 가장 최적의 수행 속도를 보인다. 따라서 사용자가 주로 앞쪽 일부 데이터만 조회할 때 아주 효과적인 구현 방식이다.
뒤쪽 페이지까지 자주 조회할 때
만약 사용자가 '다음' 버튼을 계속 클릭해서 뒤쪽으로 많이 이동하는 업무라면 위 쿼리는 비효율적이다. 인덱스 도움을 받아 NOSORT 방식으로 처리하더라도 앞에서 읽었던 레코드들을 계속 반복적으로 액세스해야 하기 때문이다. 뒤쪽 어떤 페이지로 이동하더라도 빠르게 조회되도록 구현하려면 앞쪽 레코드를 스캔하지 않고 해당 페이지 레코드로 바로 찾아가도록 구현해야 한다.
select 거래일시, 체결건수, 체결수량, 거래대금
from (select 거래일시, 체결건수, 체결수량, 거래대금
from 시간별종목거래 a
where :페이지이동 = 'NEXT' and 종목코드 = :isu_cd and 거래일시 >= :trd_time
order by 거래일시)
where rownum <= 11;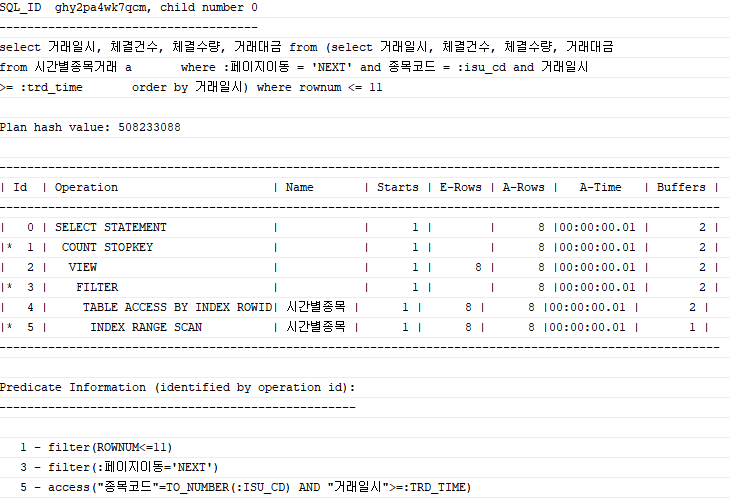
한 페이지에 데이터 10개씩 출력한다고 가정하고 작성한 쿼리다.
:페이지이동 = 'NEXT' 일 때 현재 페이지의 마지막 거래일시를 trd_time 변수에 입력해주면 된다.
(rownum <= 11이라고 했고 한 페이지에 10개씩 출력한다고 했으니 다음 페이지의 첫 번째 데이터의 거래일시는 이전 페이지의 11번째 데이터의 거래일시가 된다.)
이전 페이지로 넘어갈 때 사용하는 쿼리도 마찬가지다. 좀 전의 상황을 거꾸로 생각해주면 된다. :페이지이동 = 'PREV' 일 때 현재 페이지의 맨 첫 번째 데이터의 거래일시를 이전 페이지의 마지막 데이터의 거래일시로 입력해주면 된다.
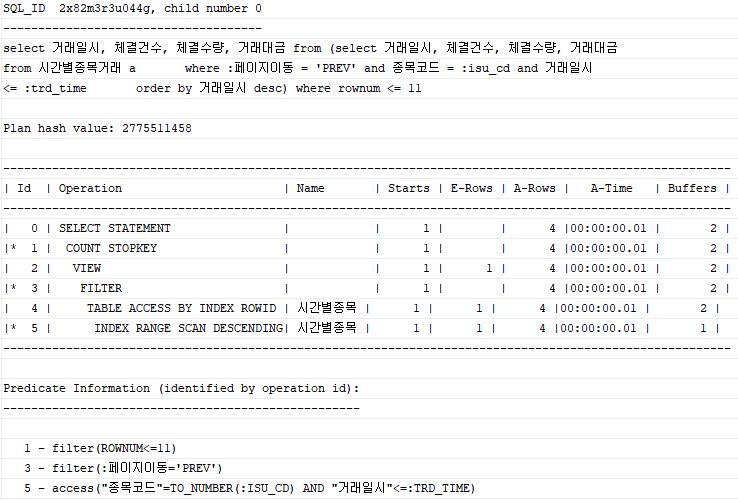
select 거래일시, 체결건수, 체결수량, 거래대금
from (select 거래일시, 체결건수, 체결수량, 거래대금
from 시간별종목거래 a
where :페이지이동 = 'PREV' and 종목코드 = :isu_cd and 거래일시 <= :trd_time
order by 거래일시 desc)
where rownum <= 11
order by 거래일시;인라인 뷰의 order by는 해당 페이지의 첫 번째 데이터를 맨 밑으로 보낸 후 그 값을 가져오기 위한 용도다. 바깥쪽 order by는 인덱스를 거꾸로 읽었지만 화면에는 오름차순으로 출력되도록 하기 위한 용도이다.
Union All 활용
위에서는 사용자가 어떤 버튼(조회, 다음, 이전)을 눌렀는지에 따라 별도의 SQL을 호출하는 방식이다. Union All을 활용하면 하나의 SQL로 처리하는 것도 가능하다.
윈도우 함수 활용
Oracle에 의해 처음 소개된 윈도우 함수(분석 함수)가 지금은 ANSI 표준으로 채택돼 대부분 DBMS에서 지원하고 있다.
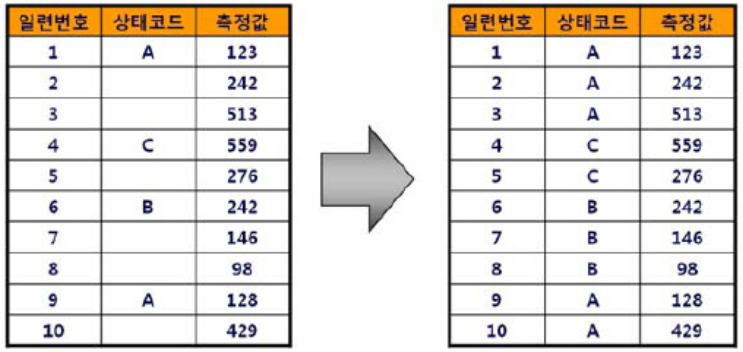
왼쪽의 장비측정 테이블에서 오른쪽과 같은 결과를 얻고자 한다.
여기서 한 가지 의문이 들었다. 위에서부터 채워나가기 위해서는 맨 윗줄부터 현재 행까지 쭉 훑어보고 NULL이 아닌 마지막 값을 현재 행의 상태코드로 지정해줘야 하는데... 책에서는 이런 구문을 주었다.
SELECT 일련번호, 측정값 ,(SELECT MAX(상태코드) FROM 장비측정 WHERE 일련번호 <= O.일련번호 AND 상태코드 IN NOT NULL) 상태코드 FROM 장비측정 O ORDER BY 일련번호;이렇게 짜면 맨 첫 번째 행부터 현재 행까지 중 상태코드가 NULL이 아닌 가장 큰 값을 현재 행의 상태코드로 지정해주라는 구문이 아닐까...?
6번째 행에서 구문을 수행할 때 B가 출력되어야 정상이다. 하지만 MAX를 적용하면 B보다 C가 더 크므로 C가 출력된 것이 아닐까 싶다...
(추가)
같은 결과를 보여주기 위한 구문으로 윈도우 함수를 사용하지 않고 두 가지 방법으로 작성해보았다.
1.select a.일련번호, b.상태코드, a.측정값 from (select 일련번호, (select max(일련번호) from 장비측정 where 일련번호 <= o.일련번호 and 상태코드 is not null ) 상태번호, 측정값 from 장비측정 o order by 일련번호) a, 장비측정 b where a.상태번호 = b.일련번호;
SELECT 일련번호, 측정값 ,(SELECT 상태코드 FROM (SELECT 일련번호, 상태코드 FROM 장비측정 WHERE 일련번호 <= O.일련번호 AND 상태코드 IS NOT NULL ORDER BY 일련번호 DESC) WHERE ROWNUM <= 1 ) 상태코드 FROM 장비측정 O ORDER BY 일련번호;
더 좋은 구문이 있을 것 같은데 당장은 이 방법밖에 떠오르지 않는다...
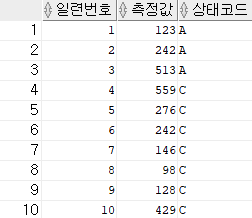
위와 같은 결과를 출력하기 위해서 윈도우 함수를 사용한 구문을 보면 다음과 같다.
select 일련번호,
측정값,
last_value(상태코드 ignore nulls) over (order by 일련번호 rows between unbounded preceding and current row) 상태코드
from 장비측정 order by 일련번호;With 구문 활용
With절을 처리하는 DBMS 내부 실행 방식에는 두 가지가 있다.
- Materialize 방식 : 내부적으로 임시 테이블을 생성함으로써 반복 재사용
- Inline 방식 : 물리적으로 임시 테이블을 생성하지 않으며, 참조된 횟수만큼 런타임 시 반복 수행. SQL문에서 반복적으로 참조되는 집합을 미리 선언함으로써 코딩을 단순화하는 용도(인라인 뷰와는, 메인 쿼리에서 여러 번 참조가 가능하다는 점에서 다름)
Materialize 방식의 With절을 통해 생성된 임시 데이터는 영구적인 오브젝트가 아니어서, With절을 선언한 SQL문이 실행되는 동안만 유지된다.
With절은 두 개 이상 선언할 수 있으며, With절 내애서 다른 With절을 참조할 수도 있다. With절 내의 쿼리 결과(Subquery)가 여러 번 사용될 때 유용하다.
WITH ALIAS AS (Subquery);
SELECT 컬럼명 FROM ALIAS명;