Nested Loop Join
조인의 기본은 NL 조인이다. NL 조인은 인덱스를 이용한 조인으로 이를 정확하게 이해하고 나면 다른 조인 방식도 쉽게 이해할 수 있다.
예를 하나 들어보자.
select e.사원명, c.고객명, c.전화번호
from 사원 e, 고객 c
where e.입사일자 >= '19960101'
and c.관리사원번호 = e.사원번호;이 쿼리 수행 과정을 생각했을 때 가장 쉽게 생각할 수 있는 방식은 사원 테입르에서 1996년 1월 1일 이후에 입사한 사원을 찾아 '건건이' 사원의 사원 번호와 고객의 관리사원번호가 같은 행을 찾는 것이다. 이것이 바로 Nested Loop 조인이 사용하는 알고리즘이다.
<Java>
for(int i = 0; i < 100; i++){ // Outer Loop
for(int j = 0; j < 100; j++){ // Inner Loop
// Do Anything...
}
}<PL/SQL>
for outer in 1..100 loop
for inner in 1..100 loop
dbms_output.put_line(outer || ':' || inner);
end loop;
end loop;NL 조인은 위 중첩 루프문과 같은 수행 구조를 사용한다.
begin
for outer in (select 사원번호, 사원명, from 사원 where 입사일자 >= '19960101')
loop
for inner in (select 고객명, 전화번호 from 고객 where 관리사원번호 = outer.사원번호)
loop
dbms_output.put_line(
outer.사원명 || ' : ' || inner.고객명 || ' : ' || inner.전화번호);
end loop;
end loop;
end;일반적으로 NL 조인은 Outer와 Inner 양쪽 테이블 모두 인덱스를 이용한다. Outer쪽 테이블은 사이즈가 크지 않으면 인덱스를 이용하지 않고 Table Full Scan을 할 수 있는(어차피 한 번만 읽기 때문에) 반면, Inner쪽 테이블은 인덱스를 사용해야 한다. 그렇지 않으면 Outer 루프에서 읽은 건수 만큼 Table Full Scan을 반복하기 때문이다.
(만약 Outer루프에서 읽은 건수가 100건이고 Inner 테이블의 행 수가 100개라면 총 100번 Table Full Scan을 하여 10000개의 행을 읽어야 한다.)
NL 조인을 제어할 때는 use_nl 힌트를 사용한다.
select /*+ ordered use_nl(c) */ e.사원명, c.고객명, c.전화번호
from 사원 e, 고객 c
where e.입사일자 >= '19960101'
and c.관리사원번호 = e.사원번호;참고로 ordered는 from절에 기술한 순서대로 조인하라고 옵티마이저에게 지시할 때 사용한다. 즉, 위 쿼리는 사원 e를 기준으로 고객 c와 NL Join을 하라는 의미이다.
ordered 대신 leading(e, c)와 같이 사용할 수도 있다. 이 힌트를 사용하면 from절을 바꾸지 않고도 마음껏 순서를 제어할 수 있어 편리하다.
ordered나 leading을 사용하지 않는다면 조인 순서는 옵티마이저가 스스로 정하도록 맡기겠다는 의미다.
NL 조인의 특징
- 랜덤 액세스 위주의 조인 방식. 레코드 하나를 읽으려고 블록을 통째로 읽는 랜덤 액세스 방식은 설령 메모리 버퍼에서 빠르게 읽더라도 비효율이 존재함.
- 조인을 한 레코드씩 순차적으로 진행함. 부분범위 처리 활용 시 매우 빠른 응답 속도를 낼 수 있으며 먼저 액세스되는 테이블 처리 범위에 의해 전체 일량이 결정됨.
- 다른 조인 방식과 비교할 때 인덱스 구성 전략이 특히 중요함.
NL 조인은 소량 데이터를 주로 처리하거나 부분범위 처리가 가능한 온라인 트랜잭션 처리(OLTP) 시스템에 적합한 조인 방식이다.
NL 조인 확장 메커니즘
-
전통적으로는 위에서 설명한 방식으로 작동한다.
-
테이블 Prefetch
인덱스를 이용해 테이블을 액세스하다가 디스크 I/O가 필요해지면, 이어서 곧 읽게 될 블록까지 미리 읽어서 버퍼캐시에 적재하는 기능이다.
실행계획에 인덱스 rowid에 의한 Inner 테이블 액세스가 Nested Loops 위쪽에 표시되면, Prefetch 기능이 활성화됨을 의미한다. -
배치 I/O
디스크 I/O Call을 미뤘다가 일정 블록이 일정량 쌓이면 한꺼번에 처리하는 기능이다.
Inner쪽 인덱스만으로 조인을 하고나서 테이블과의 조인은 나중에 일괄처리하는 메커니즘으로 테이블 액세스는 나중에 하지만 부분범위처리는 정상적으로 작동한다.
인덱스와의 조인을 모두 완료하고 나서 테이블을 액세스하는 것이 아니라 일정량씩 나누어 처리한다.(부분범위처리)
Inner쪽 테이블 블록을 모두 버퍼캐시에서 읽는다면 데이터 출력 순서도 100% 같아 어떤 방식으로 수행하든 성능에 차이가 없다. 하지만 일부를 디스크에서 읽게 되면 성능에 차이가 나타날 수도 있고, 배치 I/O 실행계획이 나타날 때는 결과집합의 정렬 순서도 다를 수 있어 주의가 필요하다.
Sort Merge Join
Sort Merge Join은 두 테이블을 각각 정렬한 다음에 두 집합을 머지하면서 조인을 수행한다.
- 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬한다.
- 머지 단계 : 정렬된 양쪽 집합을 서로 머지한다.
소트 단계는 PGA를 할당받아 그 공간에서 이루어진다. 여기서 PGA(Process/Program/Private Global Area)는 각 오라클 서버 프로세스에 할당된 메모리 영역이며, 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용한다. 할당받은 PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블 스페이스를 이용한다.
만약 조인 컬럼에 인덱스가 있다면 소트 단계를 거치지 않고 바로 조인할 수도 있다. Oracle은 조인 연산자가 부등호이거나 아예 조인 조건이 없어도 Sort Merge Join으로 처리할 수 있지만, SQL Server는 조인 연산자가 '='일 때만 Sort Merge Join을 수행한다.
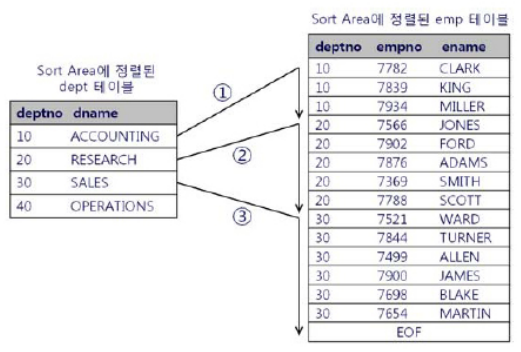
이 경우 Inner 집합인 emp 테이블이 정렬되어 있기 때문에 조인에 실패하는 레코드를 만나는 순간 멈출 수 있다는 사실이다. 1번 스캔 중 deptno가 20일 때 멈추고 2번 스캔을 진행한다. 1번에서 멈췄을 때 그 지점을 기억했다가 2번 스캔을 진행할 때는 그 지점부터 바로 시작하면 되기 때문에 스캔 시작접을 매번 탐색하지 않아도 된다.
Sort Merge Join의 특징
- 조인하기 전에 양쪽 집합을 조인 컬럼 기준으로 정렬한다.
정렬해야 할 집합이 초대용량 테이블이면 정렬 자체가 큰 비용을 수반하기 때문에 성능 개선 효과를 얻지 못할 수도 있지만 일반 인덱스나 클러스터형 인덱스처럼 미리 정렬된 오브젝트를 이용하면 정렬작업을 하지 않고 바로 조인을 수행할 수 있어 Sort Merge Join이 좋은 대안이 될 수 있다. - 부분적으로, 부분범위처리가 가능한다.
Outer 집합이 조인 컬럼 순으로 미리 정렬된 상태에서 사용자가 일부 로우만 Fetch 하다가 멈춘다면 Outer 집합은 끝까지 읽지 않아도 된다. - 테이블별 검색 조건에 의해 전체 일량이 좌우된다.
- 스캔 위주의 조인 방식이다.
Merge 과정에서 Inner 테이블을 반복 액세스하지 않으므로 Random 액세스가 발생하지 않는 것이다. 하지만, 각 테이블 검색 조건에 해당하는 대상 집합을 찾을 때는 인덱스를 이용한 Random 액세스 방식으로 처리될 수 있고, 이때 발생하는 Random 액세스량이 많다면 Sort Merge Join의 이점이 사라질 수 있다. - Sort Area에 저장한 데이터 자체가 인덱스 역할을 하므로 소트 머지 조인은 조인 컬럼에 인덱스가 없어도 사용할 수 있는 조인 방식이다.
Sort Merge Join은 조인 조건식이 등치(=) 조건이 아닌 대량 데이터를 조인할 때나 조인 조건식이 아예 없는 조인(Cross Join, 카테시안 곱)을 할 때 사용한다.
Hash Join
Hash Join은 NL Join이나 Sort Merge Join이 효과적이지 못한 상황을 해결하고자 나온 조인 방식이다. 이는 둘 중 작은 집합(Build Input)을 읽어 해시 테이블을 생성하고, 반대쪽 큰 집합을 읽어 해시 테이블을 탐색하면서 조인하는 방식이다.
Build 단계 : 작은 쪽 테이블(Build Input, 생성 입력)을 읽어 해시 테이블을 생성한다.
Probe 단계 : 큰 쪽 테이블(Probe Input)을 읽어 해시 테이블을 탐색하면서 조인한다.
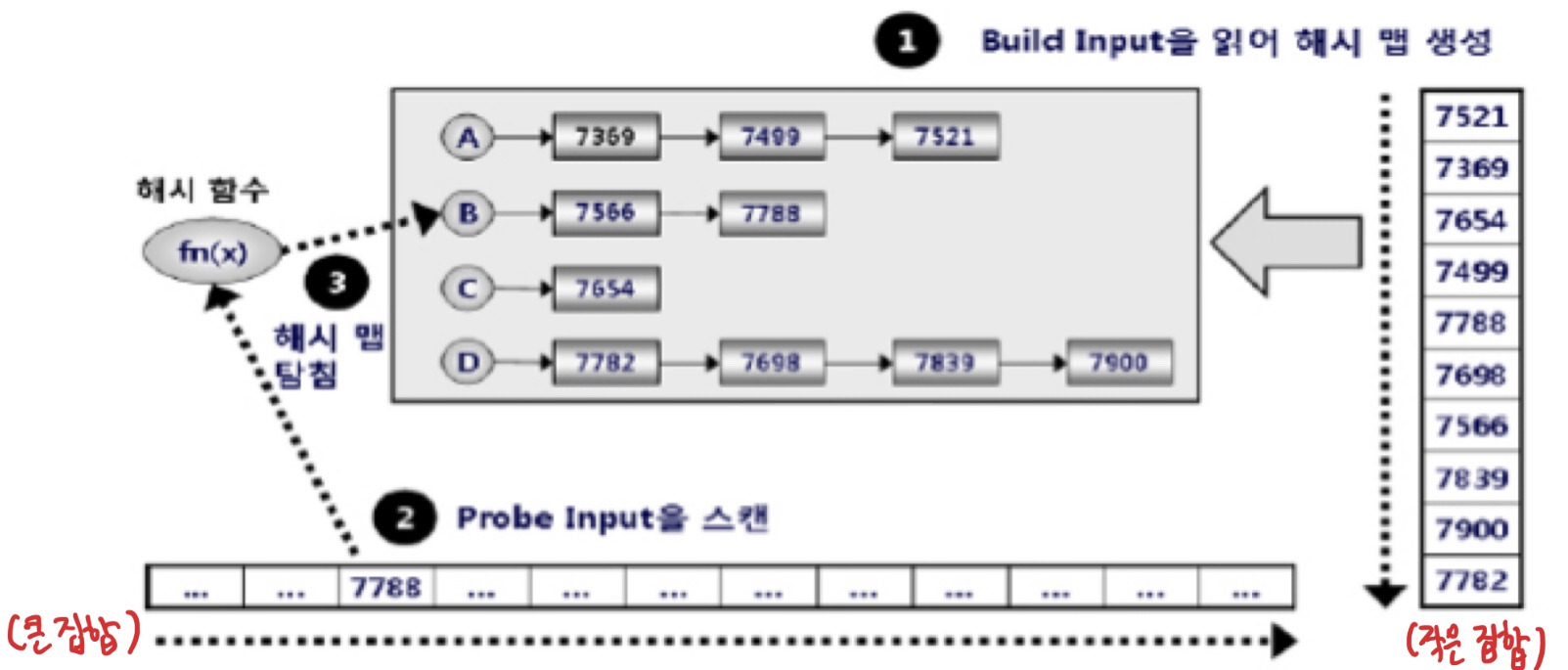
- 작은 집합 내의 조인 컬럼을 테이블 키 값으로 사용하여 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에 데이터를 연결한다. 해시 테이블은 PGA 영역에 할당된 Hash Area에 저장하고, 해시 테이블이 너무 커 PGA에 담을 수 없으면, Temp 테이블스페이스에 저장한다.
- 큰 집합 내의 조인 컬럼을 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인을 스캔해서 같은 값을 찾으면 조인에 성공한 것이고, 못찾으면 실패한 것이다.
실제 조인을 수행하는 2번 단계는 NL조인과 다르지 않다.
Hash Join의 특징
- 해시 테이블을 PGA 영역에 할당하기 때문에 NL Join보다 빠르다. 하지만 Hash Join도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼캐시를 경유할 때 인덱스를 사용하기도 하여 이 과정에서 생기는 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 해시 조인이라도 피할 수 없다.
해시 테이블에 조인 키 값만 저장하게 되면 조인에 성공한 컬럼에 대한 나머지 정보를 읽으려면 rowid로 다시 테이블 블록에 액세스 해야하므로 해시 조인의 장점이 사라진다. 해시 테이블에는 조인 키값뿐만 아니라 SQL에 사용된 컬럼을 모두 저장한다.
인덱스 rowid로 테이블을 랜덤 액세스하는 NL조인의 단점 때문에 소트 머지 조인과 해시 조인이 탄생한 것이다!
Sort Merge Join과 Hash Join은 모두 조인 오퍼레이션을 PGA에서 처리함에도 불구하고 일반적으로 Hash Join이 더 빠르다. 그 이유는 무엇일까?
두 조인 메소드의 성능 차이는 조인 오퍼레이션을 시작하기 전, 사전 준비작업에 기인한다.
Sort Merge Join에서 사전 준비작업은 양쪽 집합을 모두 정렬해서 PGA에 담는 작업이다. PGA는 그리 큰 메모리 공간이 아니므로 두 집합 중 어느 하나가 중대형 이상이면 Temp 테이블스페이스, 즉 디스크에 쓰는 작업을 반드시 수반한다.
Hash Join에서 사전 준비작업은 양쪽 집합 중 어느 '한쪽'을 읽어 해시 맵을 만드는 작업이다. 해시 조인은 둘 중 작은 집합을 해시 맵 Build Input으로 선택하므로 두 집합 모두 Hash Area에 담을 수 없을 정도로 큰 경우가 아니면, Temp 테이블스페이스, 즉 디스크에 쓰는 작업은 전혀 일어나지 않는다. 설령 Temp 테이블스페이스를 쓰게 되더라도 대량 데이터 조인할 때는 일반적으로 해시 조인이 가장 빠르다.
Hash Join 사용 기준
- 조인 컬럼에 적당한 인덱스가 없어 NL Join이 비효율적일 때
- 조인 컬럼에 인덱스가 있더라도 NL Join 드라이빙 집합에서 Inner쪽 집합으로의 조인 액세스량이 많아 Random 액세스 부하가 심할 때
- Sort Merge Join 하기에는 두 테이블이 너무 커 소트 부하가 심할 때
- 수행빈도가 낮고 조인할 때
Hash Join은 수행 빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 조인할 때(->배치 프로그램, DW, OLAP성 쿼리) 주로 사용해야 한다.
일반적인 조인 메소드 선택 기준
소량 데이터 조인할 때 -> NL 조인
대량 데이터 조인할 때 -> 해시 조인
대량 데이터 조인인데 해시 조인으로 처리할 수 없을 때, 즉 조인 조건식이 등치(=) 조건이 아닐 때(조인 조건식이 아예 없는 카테시안 곱 포함) -> 소트 머지 조인
대량 데이터 조인의 기준?
NL조인 기준으로 '최적화했는데도' 랜덤 액세스가 많아 만족할만한 성능을 낼 수 없다면, 대량 데이터 조인에 해당한다.
- 최적화된 NL 조인과 해시 성능 조인이 같으면, NL 조인
- 해시 조인이 약간 더 빨라도 NL조인
- NL 조인보다 해시 조인이 매우 빠른 경우, 해시 조인
NL 조인에 사용하는 인덱스는 DBA가 Drop하지 않는 한 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조다. 반면, 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조다.
## 서브쿼리 조인 서브쿼리는 하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록을 말한다. 쿼리에 내장된 또 다른 쿼리이다.
- 인라인 뷰(Inline View) : From절에 사용한 서브쿼리를 말한다.
- 중첩된 서브쿼리(Nested Subquery) : 결과집합을 한정하기 위해 WHERE절에 사용한 서브쿼리를 말한다. 특히, 서브쿼리가 메인쿼리 컬럼을 참조하는 형태를 '상관관계 있는(Correlated) 서브쿼리' 라고 부른다.
- 스칼라 서브쿼리(Scalar Subquery) : 한 레코드당 정확히 하나의 값을 반환하는 서브쿼리다. 주로 SELECT-LIST에서 사용하지만 몇 가지 예외사항을 제외하면 컬럼이 올 수 있는 대부분 위치에서 사용할 수 있다.
서브쿼리를 참조하는 메인 쿼리도 하나의 쿼리 블록이며, 옵티마이저는 쿼리 블록 단위로 최적화를 수행한다.
필터 오퍼레이션
no_unnest 힌트를 사용하면 서브쿼리를 풀어내지 말고 그대로 수행하라고 옵티마이저에게 지시한다. 이렇게 하면 서브 쿼리를 필터 방식으로 처리하게 된다.
필터(Filter) 오퍼레이션은 기본적으로 NL 조인과 처리 루틴이 같다. 처리 루틴을 해석할 때는 'FILTER'를 'NESTED LOOPS'로 치환하고 처리 루틴을 해석하면 된다. NL 조인처럼 부분 범위 처리도 가능하다. 차이가 있다면...
- 필터는 메인쿼리의 한 로우가 서브쿼리의 한 로우와 조인에 성공하는 순간 진행을 멈추고, 메인쿼리의 다음 로우를 계속 처리한다. 이렇게 처리해야 메인쿼리 결과집합이 서브쿼리 M쪽 집합 수준으로 확장되는 현상을 막을 수 있다.
- 필터는 캐싱 기능을 갖는다. 이는 필터 처리한 결과, 즉 서브쿼리에 입력 값에 따른 반환값을 캐싱하는 기능이다. 이 기능이 작동하므로 서브쿼리를 수행하기 전에 항상 캐시부터 확인한다. 캐시에서 true/false 여부를 확인할 수 있다면, 서브쿼리를 수행하지 않아도 되므로 성능을 높이는데 큰 도움이 된다.
캐싱은 쿼리 단위로 이루어진다. 쿼리를 시작할 때 PGA 메모리에 공간을 할당하고, 쿼리를 수행하면서 공간을 채워나가며, 쿼리를 마치는 순간 공간을 반환한다. - 필터 서브쿼리는 일반 NL 조인과 달리 메인쿼리에 종속되므로 조인 순서가 고정된다. 항상 메인쿼리가 드라이빙 집합이다.
서브쿼리 Unnesting
서브쿼리 Unnesting은 메인과 서브쿼리 간의 계층구조를 풀어 서로 같은 레벨로 만들어준다는 의미에서 '서브쿼리 Flattening'이라고 부르기도 한다.
서브쿼리에 unnest 힌트를 사용하면 되며 nl_sj와 같이 쓰면 nl 세미조인 방식으로 실행하도록 한다.
NL 세미조인은 기본적으로 NL 조인과 같은 프로세스로 진행되며 조인에 성공하는 순간 진행을 멈추고 메인 쿼리의 다음 로우를 계속 처리한다는 점만 다르다.
서브쿼리를 Unnesting 하는 이유는 무엇일까? Unnesting된 서브쿼리는 NL 세미조인 외에도 다양한 방식으로 실행될 수 있다. 필터방식은 항상 메인쿼리가 드라이빙 집합이지만, Unnesting된 서브쿼리는 메인 쿼리 집합보다 먼저 처리될 수 있다.
서브쿼리 Pushing
Unnesting 되지 않은 서브쿼리는 항상 필터 방식으로 처리되며, 대개 실행계획 상에서 맨 마지막 단계에 처리된다.
하지만 Pushing 서브쿼리를 사용한다면 서브쿼리 필터링을 가능한 한 앞 단계에서 처리하도록 강제하며, push_subq/no_push_subq 힌트로 제어한다.
이 기능은 Unnesting 되지 않은 서브쿼리에만 작동한다. 따라서 push_subq 힌트는 항상 no_unnest 힌트와 같이 기술하는 것이 올바른 사용법이다. Pushing 서브쿼리와 반대로, 서브쿼리 필터링을 가능한 한 나중에 처리하게 하려면 no_unnest와 no_push_subq를 같이 사용하면 된다.
조인조건 Push Down
메인 쿼리를 실행하면서 조인 조건절 값을 건건이 뷰 안으로 밀어 넣는 기능이다. 이 기능을 사용하면 부분범위 처리가 가능해진다. 뷰를 독립적으로 실행할 때처럼 당월 거래를 모두 읽지 않아도 되고, 뷰를 머징할 때처럼 조인에 성공한 전체 집합을 Group By하지 않아도 된다.
이 기능을 제어하는 힌트는 push_pred이다. 옵티마이저가 뷰를 머징하면 힌트가 작동하지 않으니 no_merge 힌트를 함께 사용하는 습관이 필요하다.
