개요
varchar 타입의 속성을 가지고 인덱스를 생성하고, 조회 시 인덱스를 타도록 하여 Table Full Scan을 방지하여 성능을 개선할 수 있다. 하지만, 일반적인 인덱스만으로는 다음과 같이 검색할 경우 얘기가 좀 달라진다.
문장 : 저는 4학년입니다.
검색 단어 : "4학년"
물론 다음과 같은 쿼리로 검색이 가능하긴 하다.
SELECT * FROM table_name WHERE column_name LIKE "%4학년%";하지만, 인덱스를 걸어놓은 컬럼에 대해서 LIKE절을 쓰게 되면 넓은 범위를 탐색하게 된다. 특히, 위의 쿼리처럼 단어 앞뒤에 '%'를 사용할 경우 Index Full Scan이 발생하여 오히려 성능이 Table Full Scan보다도 못하게 된다.
(정정) 위처럼 쿼리를 실행하게 되면 인덱스를 타지 못하고 Table Full Scan이 발생한다. 이러한 경우 MySQL에서 제공하는 FullText Index를 이용하여 성능을 개선할 수 있다.
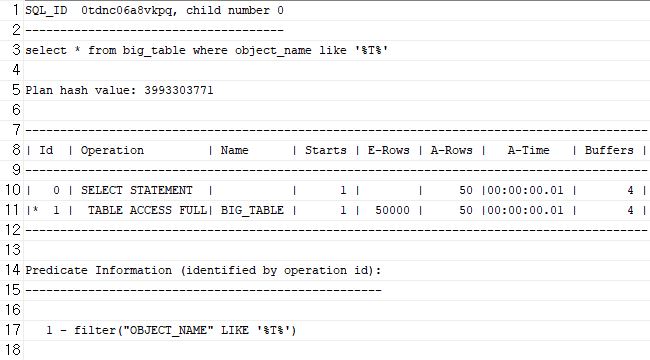
(참고) WHERE절 LIKE의 와일드카드(%)
1) 우변에만 % 사용select * from big_table where object_name like 'T%';
T로 시작하는 단어에 대한 인덱스를 탈 수 있게 되어 Index Range Scan이 일어난다.
2) 좌변에 % 사용select * from big_table where object_name like '%T%';
포함될 단어가 어떤 문자로 시작하는지 알 수 없다. 따라서 인덱스 자체를 타기 못하고 Full Table Scan이 발생하게 된다.
MySQL에서는 FullText Search를 지원한다.
FullText Search
FullText Search는 일반적인 인덱스와는 달리 매우 빠르게 모든 텍스트 필드를 검색한다. 이는 자연어를 이용하여 데이터를 검색할 수 있도록 모든 데이터의 문자열 단어를 저장한다.
이 때 사용하는 알고리즘에 대해 정리해볼 예정이다.
인덱스 알고리즘
1. Stopword(구분자)
문장의 내용을 공백이나 Tab, 문장 기호, 또는 사용자가 정의한 문자열을 구분자로 등록한다. 테이블이 아래와 같이 있다고 가정해보자.
table_name
| id | text |
|---|---|
| 1 | 텍스트 |
| 2 | 텍스트입니다. |
| 3 | 나도텍스트입니다. |
이제 "텍스트"가 포함된 문자열을 검색하고자 한다. 다음과 같은 구문을 사용하면 된다.
SELECT * FROM table_name WHERE MATCH (text) AGAINST ('텍스트');결과는 다음과 같다.
table_name
| id | text |
|---|---|
| 1 | 텍스트 |
id가 2인 row와 3인 row는 결과에 포함되지 않았다. 그 이유는 FullText Index 생성 시 공백을 구분자로 단어 단위로만 저장하게 된다. 따라서 완전히 일치한 단어만 검색 결과에 포함되게 된다.
기존 MySQL의 FullText Search 엔진은 Stopword 방식으로만 인덱싱이 가능했다. 하지만 우리는 "텍스트"라고 써도, "스트"라고 써도 table_name의 모든 행을 결과에 포함시키고 싶다.
그럴 때 사용하는 것이 N-gram이다.
2. N-gram
그렇다면 N-gram은 무엇인가? N-gram은 FullText 검색에서 여러 단어가 띄어쓰기 없이 쓰였을 때 연속적으로 나열된 음절들을 뜻한다.
예시
"20180764"
N = 1 : "2", "0", "1", "8", "0", "7", "6", "4"
N = 2 : "20", "01", "18", "80", "07", "76", "64"
N = 3 : "201", "018", "180", "807", "076", "764"
N = 4 : "2018", "0180", "1807", "8076", "0764"
문장이 주어졌을 때 다음과 같이 쪼개질 수 있다.
MySQL에서는 "WITH PARSER ngram" 구문을 사용해 추가할 수 있다.
(참고로, MySQL 5.7.6 이상의 버전에서만 사용이 가능하다.)
인덱스 생성 시
CREATE FULLTEXT INDEX index_name ON table_name(table_column) WITH PARSER ngram;ALTER TABLE table_name ADD FULLTEXT_INDEX index_name(name) WITH PARSER ngram;
테이블 생성 시CREATE TABLE table_name( id BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(20), FULLTEXT INDEX index_name(name) WITH PARSER ngram ) Engine=InnoDB CHARACTER SET utf8mb4;
토큰 크기 단위를 결정하는 innodb_ft_max_token_size와 innodb_ft_min_token_size를 무시하고 N-gram에서 토큰을 제어하기 위해서는 ngram_token_size를 지정한다.
토큰 단위 결정 방법
토큰 단위는 설정 파일에 적어줌으로써 결정할 수 있다. 설정 파일은my.ini 또는 my.cnf가 있다.
(Windows 계열에서는 my.ini, 리눅스 계열에서는 my.cnf가 있다.)
참고로 Windows 계열에서 my.ini는,
C:\ProgramData\MySQL\MySQL Server 8.0 에 있다.
1. Stopword(구분자)
innodb_ft_min_token_size = 2
innodb_ft_max_token_size = 4
이런 식으로 최소 토큰 크기와 최대 토큰 크기를 결정할 수 있다.
참고 : MySQL 공식 문서
innodb_ft_min_token_size
innodb_ft_max_token_size
2. N-gram
ngram_token_size = 2
이런 식으로 설정한다. N-gram에서는 위의 innodb_ft_min_token_size와 innodb_ft_max_token_size를 무시하게 된다.
3. 검색 모드의 종류
1. 자연어 검색(natural search)
검색 문자열을 단어 단위로 분리한 후, 해당 단어 중 하나라도 포함되는 행을 찾는다.
select *
from match table_name
where match('column_name') against ('word' in natural language mode); 2. 불린 모드 검색(boolean mode search)
검색 문자열을 단어 단위로 분리한 후, 해당 단어가 포함되는 행을 찾는 규칙을 추가적으로 적용하여 해당 규칙에 매칭되는 행을 찾는다.
select *
from table_name
where match(column_name) against ('word' in boolean mode);특징
- 검색의 정확도에 따라 결과가 정렬되지 않는다.
- 필수(+), 예외(-), 부분("*"), 구문(" ") 연산자를 사용할 수 있다.
+ : keyword가 포함된 행 반환
- : keyword가 포함된 행 제외
* : keyword로 시작하는 행 반환. (단, keyword로 끝나는 행을 찾는 것은 불가한 것 같다.)
"" : ""사이 keyword 반환. 해당 전체 구문 그대로 포함된 글 검색.
참고 레퍼런스
InnoDB 전문 검색 : N-gram Parser
MySQL FullText Search 전문검색 기능
N-gram 파서
