Today, I will introduce a paper, Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation, which was recently accepted to WACV 2025!
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Paper: https://arxiv.org/pdf/2404.08181
Github: https://github.com/sinahmr/NACLIP
Paper Overview
The paper introduces Neighbor-Aware CLIP (NACLIP), a training-free model designed for open-vocabulary semantic segmentation (OVSS). OVSS tasks extend semantic segmentation beyond predefined class sets, enabling the model to segment more diverse visual categories that are relevant in real-world applications. To handle the text-image correspondence required for such tasks, the powerful zero-shot transfer abilities of the CLIP model have often been leveraged. However, CLIP’s reliance on the class token for training creates limitations for dense prediction tasks. NACLIP addresses this with three key modifications to CLIP’s visual encoder:
- Incorporates a Gaussian kernel in the attention map to enforce spatial locality.
- Modifies similarity calculation method into key-key similarity in the self-attention mechanism, enhancing spatial focus.
- Removes image-level specialized units in the final block, notably the feed-forward module and skip connection, to better adapt to dense prediction.
Through these modifications, NACLIP could improve the visual encoder of CLIP in the aspect of spatial consistency. This improvement leads NACLIP to achieve state-of-the-art performance across multiple benchmarks without any additional data or training process.
💡 Keywords: Training-Free, OVSS, CLIP
1. Problem Definition
Open-Vocabulary Semantic Segmentation
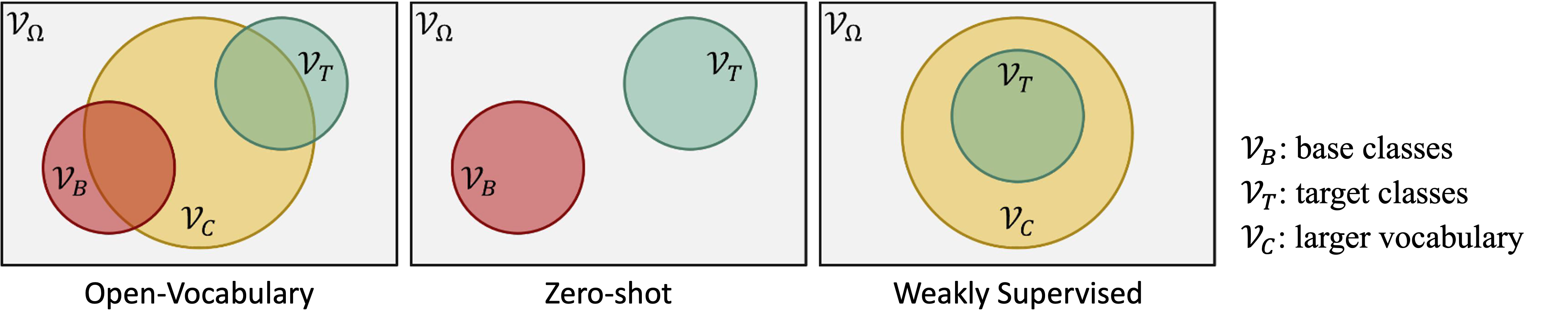
Open-vocabulary semantic segmentation (OVSS) aims to identify and segment new concepts within an image, even if they haven’t been seen in the training process. While traditional segmentation tasks are limited to predefined classes, OVSS focuses on providing more flexible and adaptable image understanding. As shown in the figure below, OVSS can be applied to a broader and more realistic variety of objects. (Img Referene: MaskCLIP)

Open Vocabulary
Open vocabulary refers to performing tasks (e.g., detection, segmentation) on classes outside the predefined categories. This concept was first introduced in the work of Zareian, Alireza, et al. (CVPR 2021).
Why Training-Free ?
Many existing OVSS methods rely heavily on supervised learning or pre-trained models. However, most of them require extensive re-training or additional data when applied to new datasets, which limits their practical use in real-world applications. This additional training requirement creates a bottleneck in real-world applications. Therefore, a training-free approach without these constraints is well-suited for the OVSS task, and this work proposes a methodology based on this approach.
Why Should We Modify the Original CLIP Model ?
In this work, the proposed approach, NACLIP, makes only minor adjustments to the CLIP model to address the challenges of training-free OVSS. Since CLIP can understand text-image relationships, along with its remarkable zero-shot performance, it is an ideal foundation model for recognizing new concepts in images.
Zero-Shot Learning
Zero-shot learning is a learning method in which a model is able to predict new classes or objects it hasn’t seen in training by using text descriptions or class attributes. This approach enhances generalization, especially when data is limited. The concept was first introduced in the work of Larochelle, Hugo, et al.
But why should we modify CLIP? We can find the answer by examining the inherent characteristics of CLIP, especially in its pre-training process. CLIP is highly effective at general image understanding tasks, such as image classification, because it trains with natural language caption and single image pair. However, it encounters challenges in more detailed prediction tasks like segmentation. That's because the structure of CLIP emphasizes global information, limiting its capacity to capture fine spatial details within each patch. Thus, some adjustments to achieve precise segmentation are necessary, ensuring that CLIP’s architecture aligns better with the requirements of OVSS.
Background: CLIP 📎
CLIP: Contrastive Language-Image Pre-training
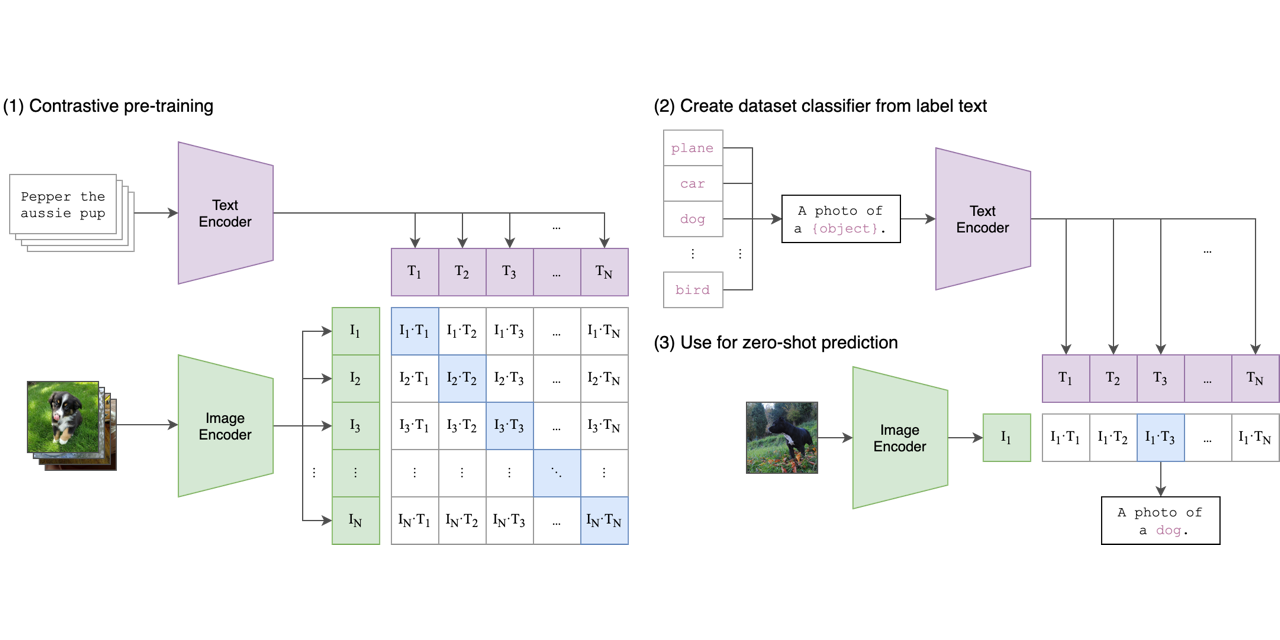
CLIP is a model introduced by OpenAI in 2021. Designed to predict novel objects and concepts in a zero-shot manner, CLIP learns the relationship between images and text without additional training for each new class. Through this approach, CLIP demonstrates its potential to handle a wide range of downstream tasks in zero-shot manners.
The diagram below illustrates the pre-training of CLIP and its application to zero-shot classification. Part (1) shows the pre-training process, while Parts (2) and (3) demonstrate how the pre-trained CLIP model is applied to zero-shot classification tasks.
For more details, visit CLIP's blog!
2. Preliminaries: CLIP Architecture
Since the paper’s main method involves modifying the CLIP architecture, it is important to understand the original architecture of CLIP!
In the CLIP model, the visual encoder consists of multiple encoder blocks, each processing a sequence of tokens representing patches from an image. Each encoder block includes two main components: the self-attention module and the feed-forward network, with layer normalization and skip connections between these components. The figure below illustrates the detail structure of single block in CLIP ViT.
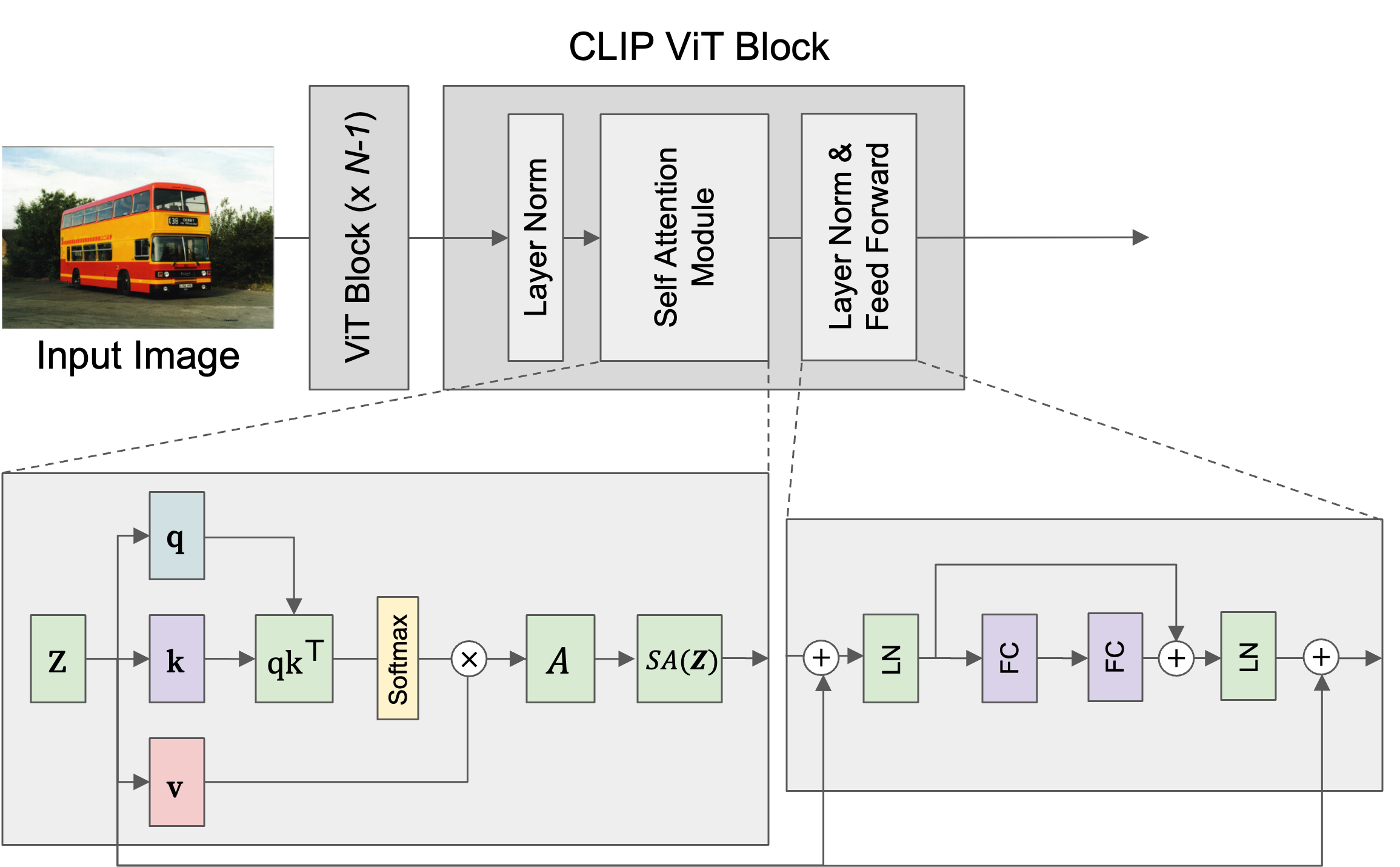
Encoder Block
Each block receives a sequence of tokens from the previous block and processes it through layer normalization ( ), self-attention ( ), and a feed-forward network ( ).
The operations in each block can be summarized as:
Self-Attention Module
This module computes three sequences of vectors: query , key and value , through a linear transformation on the input sequence .
It then calculates a similarity score between tokens by computing the dot product between and (representing the query and key for each patch), which is then scaled and processed with softmax to obtain attention weights.
The final output of self-attention for each patch is computed as:
These components allow CLIP’s encoder to align visual representations with textual information at the image level, a foundational structure for semantic understanding in dense tasks.
3. Method
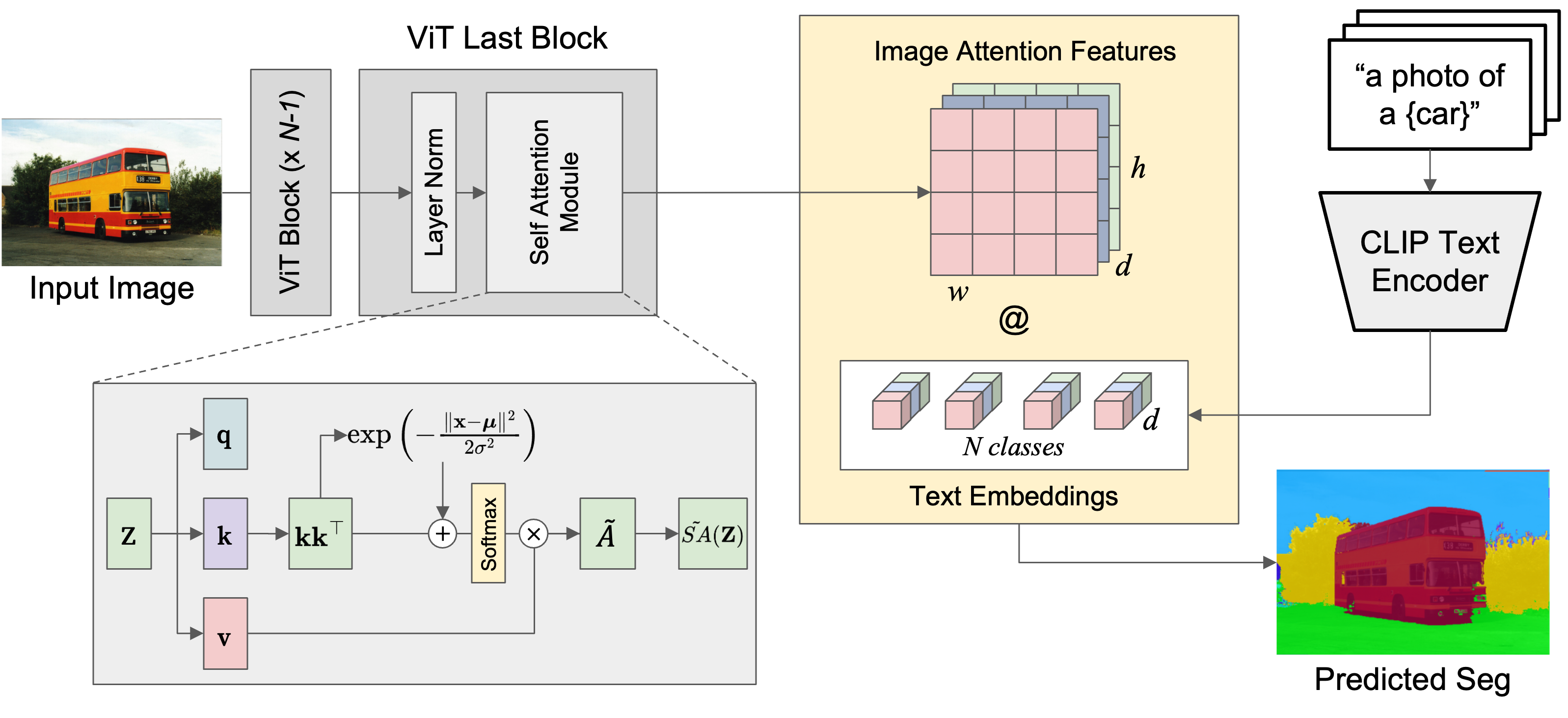
Model Overview
Based on the description in the paper, I drew the diagram below to illustrate the structure of the NACLIP model. The paper presents three main approaches for NACLIP, which we will go through one by one.
Method 1: Introducing spatial consistency
In this work, a 2D Gaussian kernel is introduced into the attention map to guide each patch to focus on its neighboring patches. This adjustment addresses the limitation of the Vision Transformer (ViT) model in the original CLIP, which does not sufficiently incorporate positional information for each patch. As shown in the figure below, this approach enables the model to form a coherent attention map that considers neighboring patches for each location.
At first, the Gaussian kernel is defined as follows, where is the center position and is the covariance matrix:
If , which means that is a diagonal matrix, this formula can be simplified:
This kernel assigns higher values when the Euclidean distances between and is small, and smaller values when the distance is large.
Thus, attention intensity is maximized at the patch and gradually diminishes for neighboring patches.
Using this approach, can be defined to focus the attention of patch on its surrounding area as follows, where refers to Gaussian window:
We can generalize this formula to consider similarity information together, by incorporating similarity:
In this form, the attention map combines similarity information with the Gaussian window , maintaining spatial consistency across patches and enhancing segmentation performance.
You can confirm the enhanced attention map in the figure below:
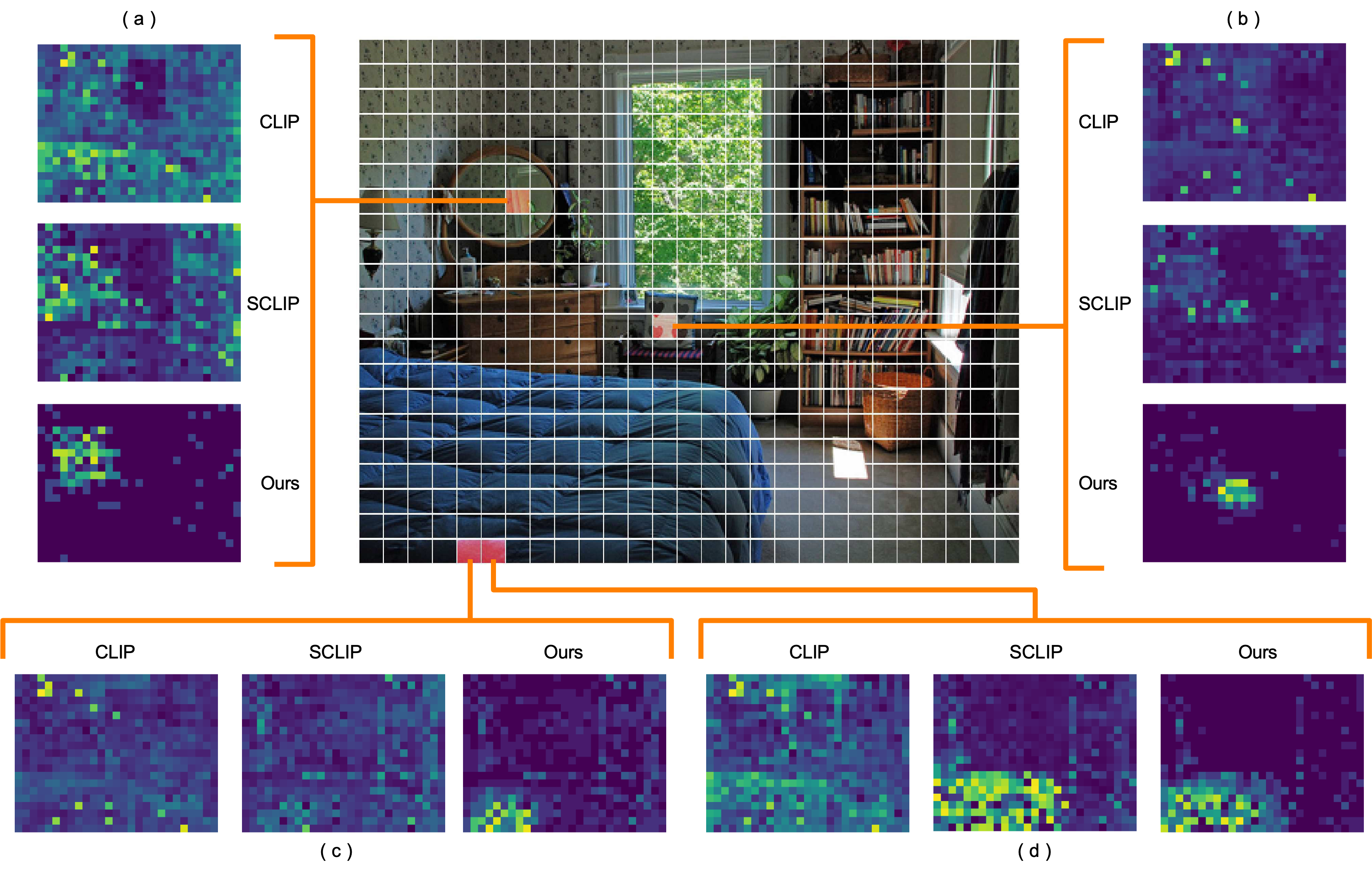
Method 2: Measure of similarity
In NACLIP, the self-attention mechanism has been modified to use a different similarity measurement from its original, making it better suited for detailed image prediction tasks.
The traditional approach, which calculates the similarity between patches based on the dot product of the query(q) and key(k) vectors, was inadequate for some tasks like segmentation. Because this approach measures similarity according to "what each patch is searching for", rather than focusing on the actual content of each patch. To perform some fine-grained tasks, where it is essential to emphasize the unique features of each patch, capturing more semantic consistency is important.
To address this, NACLIP calculates similarity by using the key(k) vectors alone — referred to as key-key similarity — basing similarity on "what each patch represents". This change allows each patch to focus more consistently on its own value(v) vector, reinforcing spatial and semantic coherence. The formula is as follows:
As shown in the figure below, the attention map equation is updated from Method 1 to incorporate this modification:

Method 3: Eliminating image-level specialized units
NACLIP points out that the final encoder block of CLIP's ViT is not well-suited for dense prediction tasks and modifies it to be more appropriate for semantic segmentation.
It removes the feedforward block, since its parameters are optimized for image-level tasks (e.g., classification) rather than dense prediction.
Also, it eliminates the skip connection. Since skip connection emphasizes the output of the previous encoder block and reduces the importance of the output from the self-attention module, it becomes less practical for this task.
By performing these adjustments, the last ViT encoder block is simplified into a Reduced Architecture as follows:
4. Code Implementation
To see how the methods have been implemented, visit the NACLIP github!
You can easily find this part at NACLIP/clip/model.py.
if self.attn_strategy in ['naclip', 'nonly']:
addition = self.addition_cache.get(n_patches)
if addition is None:
window_size = [side * 2 - 1 for side in n_patches]
window = VisionTransformer.gaussian_window(*window_size, std=self.gaussian_std)
addition = VisionTransformer.get_attention_addition(*n_patches, window).unsqueeze(0).to(x.dtype).to(x.device)
self.addition_cache[n_patches] = addition
if self.attn_strategy == 'naclip':
attn_weights = torch.bmm(k, k.transpose(1, 2)) * scale
omega = addition
elif self.attn_strategy == 'nonly':
attn_weights = torch.zeros((num_heads, num_tokens, num_tokens)).to(x.dtype).to(x.device)
omega = addition * (scale * torch.einsum('hop,hPO->hpP', q.norm(dim=2).unsqueeze(1), k.norm(dim=2).unsqueeze(2)).mean().item())
else:
raise NotImplemented
attn_weights += omega
attn_weights = F.softmax(attn_weights, dim=-1)5. Experiments & Results
Main Result
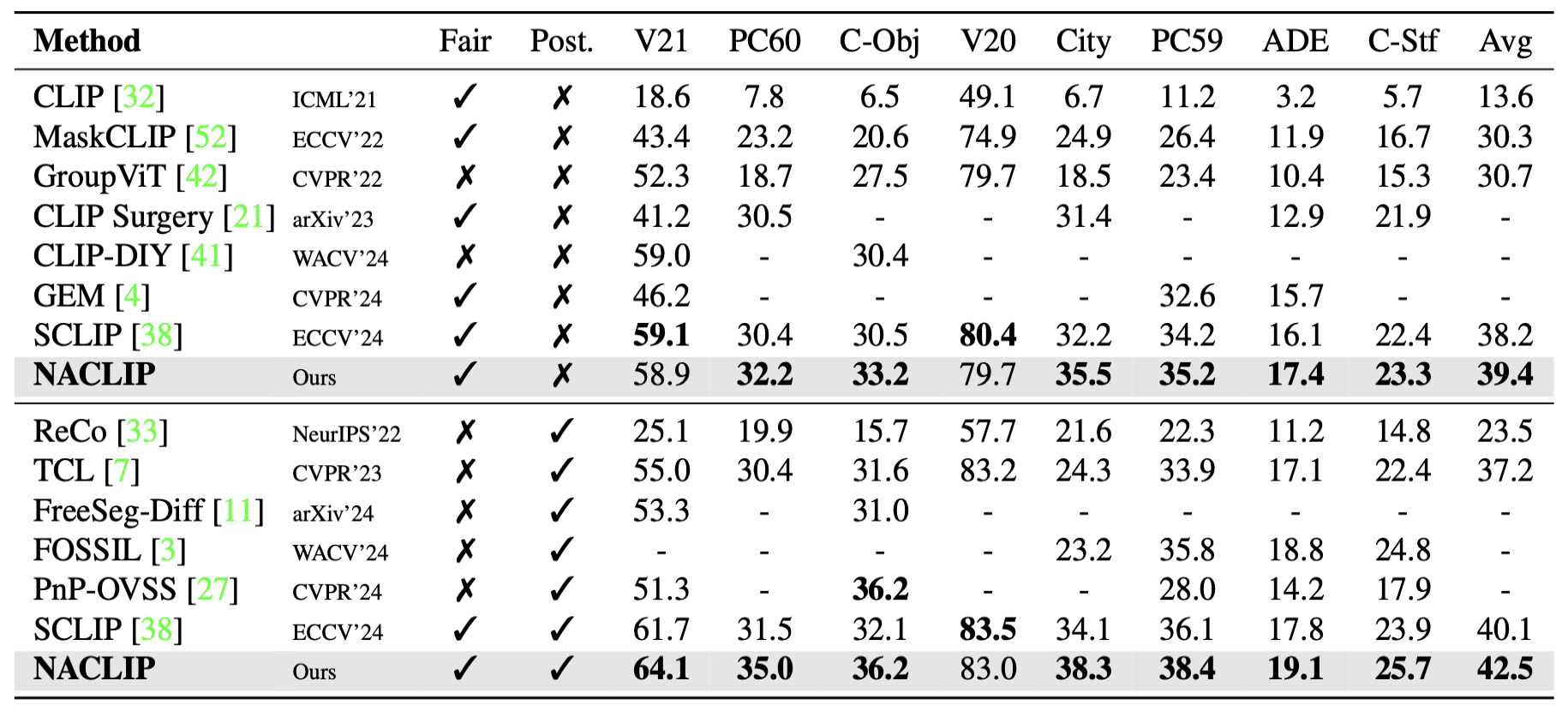
The evaluation was conducted on a total of 8 datasets.
The 'Fair' column indicates whether the method does not use any additional data or pre-trained model. (i.e., same condition with NACLIP)
The 'Post' column informs whether any post-processing step for mask refinement is included. (e.g., PAMR)
The main result shows that NACLIP outperforms other training-free OVSS methods on 7 out of 8 benchmarks.
Qualitative Result
The figures below are the segmentation maps generated by NACLIP on the COCO-Object (C-Obj) and Pascal VOC 59 (PC59) datasets. These examples highlight the significant performance improvement of NACLIP over CLIP, particularly in its ability to understand and focus on the context between adjacent patches.


Ablation Study
The paper conducts two main types of ablation studies.
The first, shown in the table on the left, examines the effects of applying Method 1 (Gaussian Kernel) and Method 2 (Key-Key similarity). From top to bottom, the table shows the results for cases with neither method applied, Method 1 only, Method 2 only, and both methods applied. The results indicate that each method is effective.
The second, shown in the table on the right, tests Method 3 (reducing the architecture of the ViT last block). A significant performance improvement is observed compared to the baseline.

6. Conclusion
Contribution
- The paper introduces NACLIP, which modifies CLIP to enhance zero-shot generalization for open-vocabulary semantic segmentation (OVSS).
- NACLIP improves spatial accuracy by removing elements that are not suitable for dense prediction and reinforcing local consistency in self-attention maps.
- Without extra data or additional training, NACLIP achieves state-of-the-art performance on 7 of 8 benchmarks, proving effective for real-world applications.
Limitation
Since it relies strongly on the CLIP model, which specializes in image-level tasks, it faces fundamental limitations in achieving fully dense predictions.
Discussion
The content above covers the main points from the NACLIP paper, and below are my personal views about this work.
It was interesting that the significant performance improvement was achieved with only minor modifications to the base CLIP model. Additionally, the fact that this Training-Free approach is a considerable advantage.
However, I also notice a few shortcomings in this paper.
Firstly, there was no structural diagram of the model included in the paper. While the modifications to the base CLIP model may be minimal and might not have warranted a detailed figure, adding one could have improved the paper’s quality.
I also felt that the experiments were somewhat limited. For instance, it raises the question of whether other combinations of q, k, and v could be explored for attention instead of relying solely on key-key similarity. Additionally, although it was not discussed in detail for clarity, the ablation study on the CLIP ViT backbone was only conducted on two datasets, which could weaken the paper's persuasive power.
Addressing these aspects could make this an even stronger paper.
That’s it for today’s post!
Feel free to leave a comment if you have any questions! 😊

4개의 댓글

NACLIP (National Association of Commercial and Legal Investigators Professionals) provides valuable resources for professionals in the legal and investigative fields. With a focus on networking, certification, and continuing education, NACLIP helps individuals build credibility and stay informed about industry trends. For businesses looking to improve their online reputation, incorporating business google review tips can significantly enhance visibility. By actively encouraging satisfied clients to leave positive reviews, businesses can improve their search engine ranking and attract new customers. NACLIP’s tools and strategies can be beneficial in guiding professionals toward enhancing their online presence and reputation management.
NACLIP (National Association of Commercial and Legal Investigators Professionals) provides valuable resources for professionals in the legal and investigative fields. With a focus on networking, certification, and continuing education, NACLIP helps individuals build credibility and stay informed about industry trends. For businesses looking to improve their online reputation, incorporating business Google review tips can significantly enhance visibility. By actively encouraging satisfied clients to leave positive reviews, businesses can improve their search engine ranking and attract new customers. NACLIP’s tools and strategies can be beneficial in guiding professionals toward enhancing their online presence and reputation management.