Normalization 일반화
데이터에 scale을 조정하는 작업, Sampling,Scaling
너무 도드러지는 데이터를 줄여서 일괄되게 유지하는 것
Regularization정규화
predict function에 복잡도를 조정하는 작업
규칙들을 제어해서 우리가 원하는 결과를 내는 것
l1 제약: Lasso 제약이 먹힘
feature들의 속성들이 있을때, 강한 feature은 계속 더 강하게 두고, 약한것은 0에 가까워지게 제약을 건다. 제약을 걸수록 Linear Regression에 가까워진다.
alpha값이 부여되면 오차를 줄이려고 계속 반복
max_iter=50000 : 50000번 이내에서 반복시키기, 한계치까지 풀어주는 개념
-lasso의 alpha값이 0이라면 의미가 없음
l2 제약 : Ridge 제약
feature들의 속성들이 있을때, 각각의 특성에 맞는 가중치가 적용
전체속성이 있을때 전반적으로 제약을 거는것.
하지만 제약에 대해서는 귀납적 접근을 해야한다.=해봐야 안다.
일반적으로는 ridge제약이 성공할 확률이 높음
기울기가 0이 되는 지점을 찾아서 제약을 거는 과정
파이썬 패키지가 다르다 = 다른 알고리즘
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
LinearSVC
옵션을 지정하는 것 = parameter
Hyper parameter 작업 : Parameter조정을 통해 우리가 원하는 값에 근접해가는 과정
ex) 반복적으로 문제를 푼다= 횟수 지정해줄수 있음 = max_iter 사용
preprocceing 전처리 작업->알고리즘 선택 ->Hyper parameter 작업 ->최적화 모델 생성
logistic은 C 라는 옵션(parameter)을 사용가능(지정을 안했을 때는 디폴트값 1)
C(대문자) parameter : 오류에 대한 허용치, 높을수록 허용 하지 않겠다, 기울기가 가파라짐
선형데이터를 기준으로 'A/B'로 나누는데 오류를 많이 허용할수록 학습정확도는 높아질수있지만,
도리어 테스트정확도가 낮아질수 있다.
3개이상의 데이터를 구별하는 알고리즘
make_blob
BLOB(Binary large object) 스트리지 : 텍스트 뿐만 아니라 이진 데이터 형태를 그대로 보관하기 때문에, 사진이나 파일,동영상 같은 바이너리 자료들을 데이터베이스에 보관할 수 있음
xw + b
line*coef[0]+intercept 로 기울기를 표현
x w bprint(linear_svm.coef_) 의 output
[[-0.17492936 0.23140212] 기울기1
[ 0.47621563 -0.06937438] 기울기2
[-0.18914382 -0.20399609]] 기울기3mglearn.discrete_scatter(X[:,0],X[:,1], y)
X에 0을 넣은것을 X축으로 X에 1를 넣은것을 y축으로 색상은 y로linearline이 3개 필요하다
클래스가 겹치거나 클래스 갯수가 많아질수록 분류를 못하는 영역이 많아진다.
서로의 영역을 침범하는 데이터일 경우 정확도 떨어질 수 밖에없다.
Tree
트리 알고리즘은 종류가 지금 이 순간에도 증가중, 하지만 주로 쓰는건 존재함
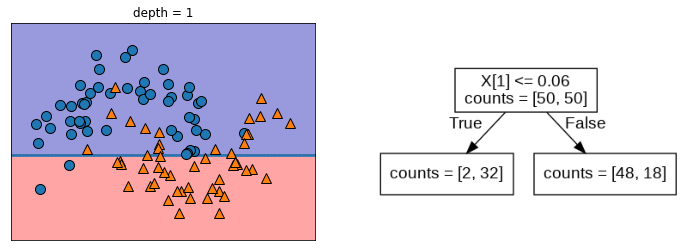
depth 1
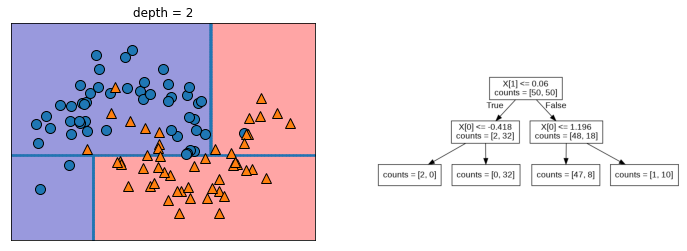
depth 2
depth 9
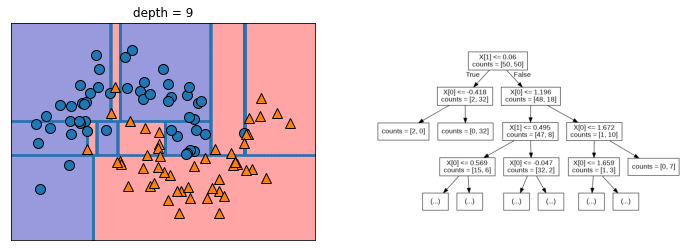
깊이(depth)가 내려갈수록 세밀하게 구별가능하지만, 과적합문제가 발생할 수 있다.
import DecisionTreeClassifier 의사결정 트리 분류법
max_depth : 과적합을 막기위해
학습 적합도는 내려가고 (제약 때문에)
테스트적합도는 내려갈수록 올라갈수도있음 (제약이 걸리면서 새로운 데이터에 대한 대응력이 좋아진것)
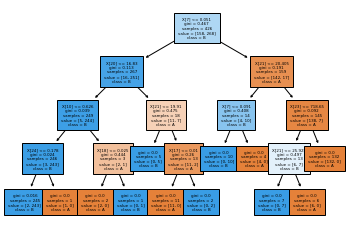
from sklearn.tree import plot_tree 트리 알고리즘 그림그리기 패키지
plot_tree(tree, class_names=['A','B'], filled=True, fontsize=4)\nsamples 는 해당되는 갈림길에 대해서 몇개단위로 쪼갯는가 확인 (output에 있음)
fill: 색상을 채울수있는가?
classnames : 항목 이름을 부여하는것, 기본값은 0,1
0(파랑)이면 멈추고 1(갈색)이면 내려간다.
색도 구별요소인데
색이 흰색: 1번 class가 좀 더 많이 섞여있는 것
연한색 : 섞여있어서 확실하진 않지만 어느쪽에 가깝다는 표현함
plt.semilogy 세미로그와이
y축을 로그스케일로 바꾸는 것
plt.yticks y축 단위의 폰트네임을 지정할 수 있음, Arial=영문폰트
[:np.newaxis] numpy배열에서 새로운 축을 만들어 주는 것 2차원배열=>3차원, 3차원배열->4차원
= .reshape 메소드 비슷한 역할 수행
np.log 함수 : log에 순차적으로 값을 넣으면 x의 값의 상승폭에 비해 y상승폭은 낮아서 x값의 변화를 판단하기 쉬움, 변별력을 높일 수 있음
np.exp 함수 : log 함수를 다시 풀어주는 것, logx=y, y가 로그가적용됐으니까 이것을 풀어줘야됨
RandomForestClassifier
forest = RandomForestClassifier(n_estimators=5)
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):n_estimators : int, 기본값=100, 포레스트에 있는 트리의 갯수, 트리의 갯수로 펼쳐보고 마지막에 합하는것
forest.estimators : 5가 들어갔음을 알려주는 '내부 속성'
enumerate 함수 : 열거형으로 만들어 주는 함수, 반복가능한 자료형(index 넘버가붙음, ()안의 내용들이 합쳐서 내용으로 들어간다.) 평소에 잘 안쓰임
GradientBoostingClassifier(GB) 그라디언트부스트
1.무작위성이 없음, 보정하는 알고리즘이 내재되 있음
2. depth를 깊게 안내려가도 데이터가 괜찮음 (1~5) = 메모리를 적게 쓰면서 동작
보통 안정적인 random forest를 먼저 사용,
다른 방식이 잘 작동하더라도 예측 시간이 중요하거나 머신러닝 모델에서 성능을 끌어내기위해 쓸 수 있음
매겨변수로
larning_rate 학습률 : 학습량 조절할 수 있음, 수치가 크면 보정을 강하게 해서 복잡한 모델이 된다.
그룹 만들기
y = y%2 로 홀짝 구별 : 0 나오면 짝수 1나오면 홀수, %가 나머지를 버리는 개념
Tip
내부적인 속성은 _ (언더바)가 붙는다
importances , coef, intercept, estimators
import os : 운영체계랑 관련있는 패키지
plt.yticks(fontname = 'Arial') y축 단위의 폰트 네임 지정, Arial=영문폰트
data_train.date.to_numpy() : data_train.date는 Series객체라서 numpy객체로 변환시키기 위해 to_numpy()를 씀
make_moons : 초승달 모양의 두개의 클러스터를 만들어주는 함수
parameter으로 noise 사용: 일부로 오류를 내는 것
ravel(), reshape()은 메모리를 서로 공유하므로, 값의 변경이 서로에게 영향을 준다.
그에 반해 flatten()은 배열을 copy하는 것이므로 메모리를 공유하지 않고, 값의 변경이 서로에게 영향이 없다.
ravel()과 faltten()은 둘다 데이터를 1차원으로 바꾸는 메소드
import numpy as np
origin = np.array([[1, 2], [3, 4]])
print(f"origin ndarray: {origin}")
raveled = origin.ravel()
print(f"raveled ndarray: {raveled}")
flattened = origin.flatten()
print(f"flattened ndarray: {flattened}")
origin ndarray: [[1 2]
[3 4]]
raveled ndarray: [1 2 3 4]
flattened ndarray: [1 2 3 4]
ax=axes[-1,-1], #맨끝에서 1,1 이랑 똑같다.
eps=0.5 매개변수에서 0.5보다 낮은 숫자가 있으면 무시한다.
가끔 일정 숫자 이하의 숫자가 들어오기때문에, 무시하도록 넣음
plt.rcParams['figure.figsize'] = [15,10]
그림 사이즈 조절
