Min-Max Scaling
데이터 전처리 매우 중요하다
주로 사용하는 방법

pd.read_csv('data/abalone.txt', header=None, names=abalone_columns)데이터를 읽어보고 header가 없다면, header=None을 해줘야지 데이터를 해치지않음
names : header 정보를 일일이 다 입력하기['a,'b','c'] or 정보가 포함된 변수 넣기
.strip() : 문자열의 양쪽 공백을 없애주지만, 중간의 공백은 제거해주지않는다.
.head() : 간략하게 제일 처음 5개 데이터만 보여줌
.shape() : 행과 열의 수 알려줌, 전체적인 데이터 구조를 파악 가능
.describe() 요약 통계량 : 개수, 평균, 표준편차 등 기초 통계량(데이터 양)을 볼 수 있다.
.info() 정보: 자료의 형태 알 수 있음, 결측치가 있는 항의 갯수를 알 수 있음
del data['SEX'] 삭제하는 함수 : data의 'SEX' 칼럼 삭제
label 과 feature
SEX를 label 이나 target(스켈링X),
나머지를 feature로 SEX를 주로해서 분류(스켈링의 대상)
fit().trsnsform() (X)
fit_transform() (0)data의 타입은 pandas데이터 ( 파일을 가져와서 표형식으로 만들었기 때문)
mMscaler타입은 numpy배열 (array 형식)
numpy로 바꿔서 다루는게 좋다
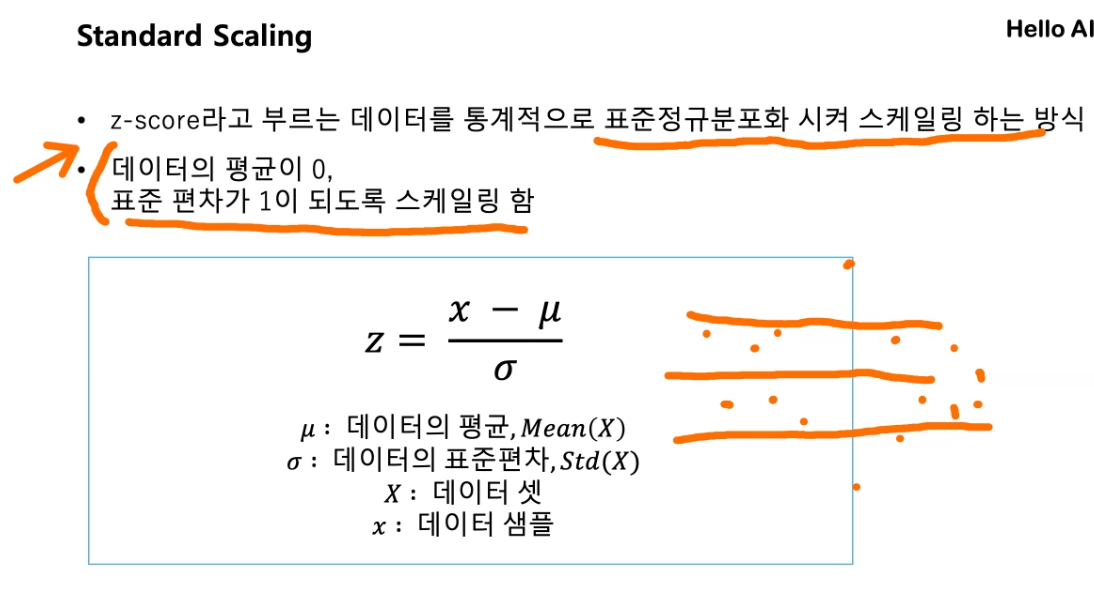
Standard Scaling
z-score 방식, 표준편차랑 관련 됨 = 값들이 -1~1 사이에 존재
Sampling
오버 샘플링은 많이 진행

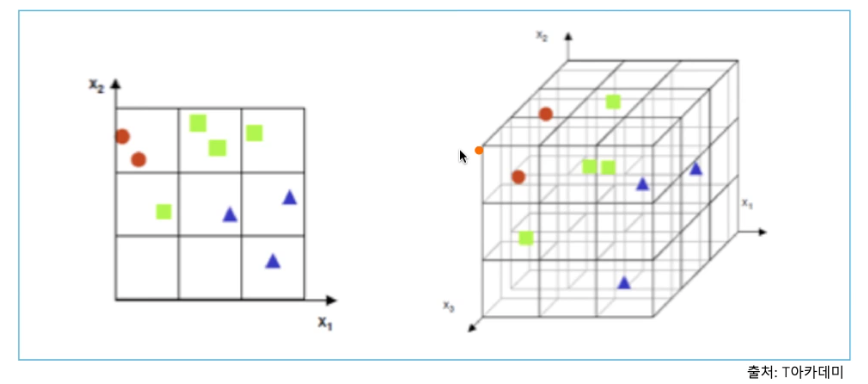
차원의 저주
고차원에서 데이터를 분석하거나 다룰 때 발생
- 고차원 = 공간의 크기 증가
- 공간의 크기 증가 ->데이터가 존재하지않는 빈공간 생김
- 빈공간 -> 데이터 해석할 때 문제 발생
특징을 잡을수없다=데이터를 학습할 수 없다.
차원을 오히려 축소해서 해결함
예를 들면 (4,4,4) => (4,16) 으로 바꿔서 해결
digits.data.shape 의 output : (1797,64) data[0].reshape(8,8)64개로 이루어진 차원이 1797개 있는데 1번째 차원([0])을 가져와서
이 차원의 1행 64열로 되어 있는 데이터를
8행 8열의 데이터로 바꾸는 것
PCA Principal Component Analysis 주 성분 분석 패키지
대표적인 차원 축소 기법
데이터를 가장 잘 표현하는 축(데이터의 분산을 잘 표현하는 축)으로 Projection 하는 방법
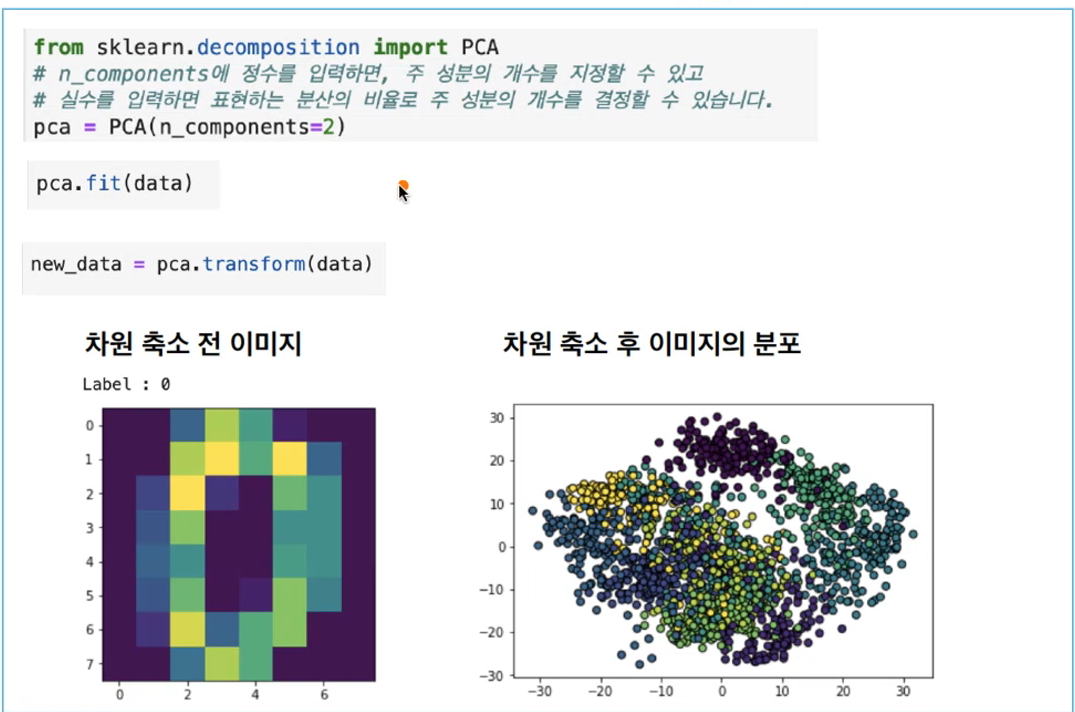
n_components=2 : 2차원으로 줄이겠다
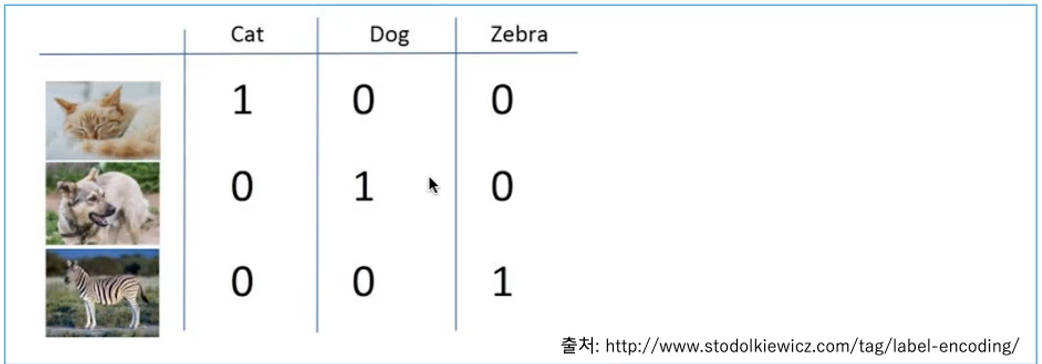
Categorical Variable to Numeric Variable
범주형 데이터를 수치형 데이터로 바꾸기, 수치화라고 하기도 함
소형,중형, 대형 같이 범주로 분류하는것을
0,1,2 식으로 식별화함으로 처리속도를 높일수있다.Label encoding
연속적인 숫자로 바꾸는 것, 단순화 하기 제일 좋은 방법
One-hot Encoding
n개의 범주형 데이터를 n개의 비트 벡터로 표현
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(sparse=False)sparse : true는 matrix, false는 array(배열),
강의에서는 배열을 주로 다루고있어서 false로 함, 기본값은 True
비 지도학습, 자율 학습
입력값에 대한 목표치(정답)이 주어지지않는다.
clustering 군집
Hierarchical Clustering(계층적군집)과
Point assignment clustering 두가지 방법
k-means clustering
가장 가까운 중심점을 찾아 그 중심점에 해당하는 클러스터 할당
n_clusters=3 : 중심점 근처의 3개의 클러스터(점)Manhattan Distance 각 축에 대해 '수직'으로 이동
Euclidean Distance 점과 점 사이의 가장 짧은거리(두 점 사이의 거리)을 계산
hierarchical clustering 계층적 군집
거리, 유사도를 기반으로 클러스터 형성
Step 1: 각 데이터 포인드를 n개의 클러스터로 할당
2 : 가까운 클러스터끼리 병합
3 : 1개의 클러스터가 될때까지 반복 = 토너먼트
TIP
.DESCR : 메소드X, 어떤데이터의 요약통계량 데이터를 의미, 목차값 또는 라벨값,타겟값 등으로 보면됨
.concatenate : 배열을 합쳐주는 메소드
