VMware SE가 알려주는 Private Cloud - vSphere 기반의 Kubernetes 환경에서의 vGPU 세팅, LLM 배포, Fine tuning과 결과 해석까지; End to End
VMware
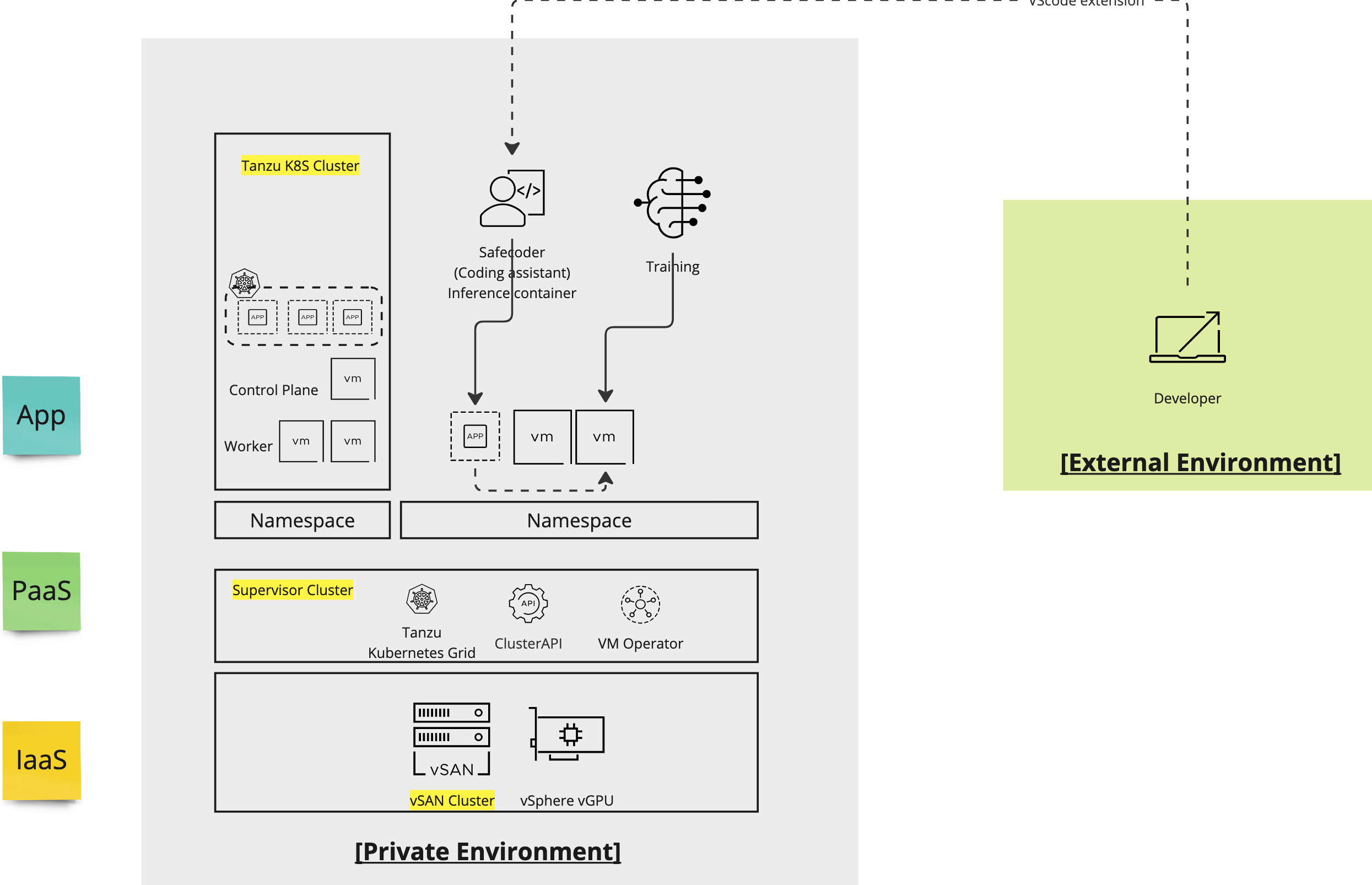
Private Cloud 환경에서의 vGPU setting, LLM 배포 그리고 Fine tuning과 결과 해석까지 - vGPU + Kubernetes + LLM + Fine tuning END TO END
들어가며
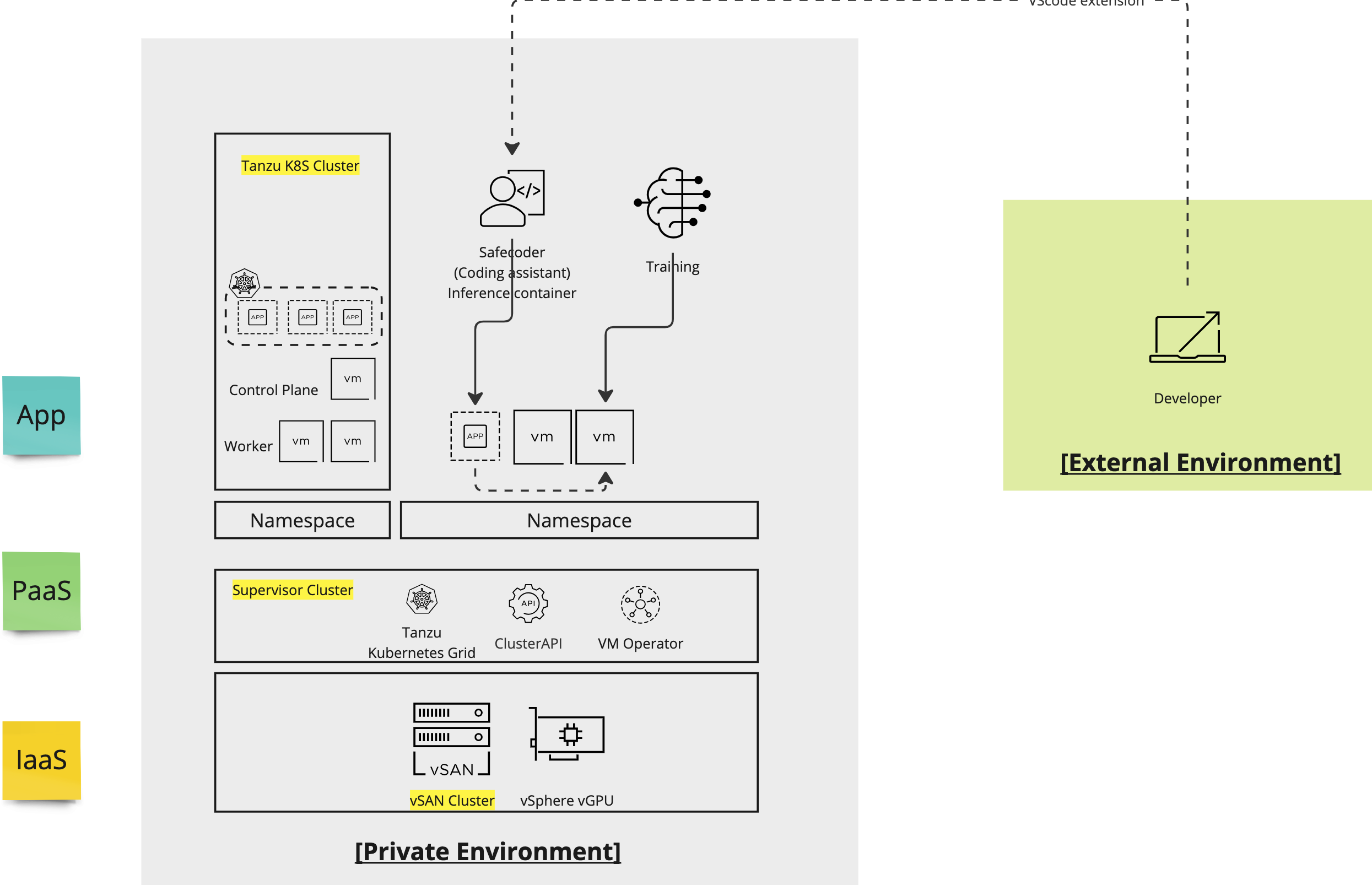
재직 중인 팀에서 GPU server를 제공받아 LLM fine tuning 플레이그라운드 프로젝트를 하게 된 것이 이 posting의 배경입니다. 정말 '박스' computing server를 제공받은 것으로부터 시작해 LLM fine tuning 에 prompting 진행까지 End to End로 실험해 본 아주 좋은 기회였는데요. Architecture는 대략적으로 위 그림과 같습니다. 사실 저는 이번 프로젝트 main 담당자는 아니어서 대부분의 installation과 이 대장정을 혼자 이끌어간 동기 Brian 에게 정말 엄청난 respect를 보냅니다. DevOps 출신인 저는 아무래도 중간 과정부터인 LLM을 위한 K8S 환경 구성, troubleshooting, LLM 결과 해석 쪽에 조금이나마 contribution 할 수 있었고, 정말 행운이었습니다!
Basic environment, Resource planning
GPU
파트너사에서 제공해주신 A100 GPU * 1장

제가 GPU 전문가는 아닙니다만, A100은 NVIDIA의 ampere 아키텍처 기반으로 ML / DL 등 대규모 data 처리에 최적화 되어 있는 그래픽카드입니다. Datacenter용은 80GB GPU memory를 가지고 MIG(Multi Instance GPU, GPU를 가상화하여 여러 가상 GPU로 나누는 방식) 7 slice까지 지원하는 GPU입니다. 이번에 제공받은 GPU는 A100 40GB 모델이었고, 그랬기 때문에 어쩔 수 없이 Fine tuning을 Falcon 7B 모델로 진행하게 되었습니다 ( 메모리 이슈로 어쩔 수 없었음.)
Hardware resource planning
| Component | Description |
|---|---|
| CPU | * Intel(R) Xeon(R) Gold @2.50GHz |
| Memory | 768GB |
| Storage | vSAN Datastore |
| Network | Intel Ethernet Controller for 10GbE SFP (Management) |
Software resource planning
| Software | version | 비고 |
|---|---|---|
| vSphere | 8.0u3 | |
| vSAN | 8.0 | |
| Tanzu Kubernetes | 1.24.9 | |
| NVAIE GPU Operator | v23.3.1 | Helm 설치 진행 |
| NVAIE Network Operator | v23.5.0 | Helm 설치 진행 |
vSphere(가상화 환경) 에서 GPU를 이용하기 위한 Basic settings
1. NVIDIA GPU License Server 설치
Prerequisites : VM (4vCPU / 8GB)

NVIDIA GPU를 사용하는 시스템에서 라이센스 관리를 위해 NVIDIA License Server (이하 NLS)를 설치해야합니다. 이번 프로젝트의 경우에는 vSphere 환경에서 vGPU를 사용하기 때문에 NVIDIA enterprise site에서 ova file을 다운받아 .ovf 템플릿을 배포했습니다. 이번에 알게된 사실인데, NLS에도 Connected 모델 / Disconnected model이 나뉘어져 있고 각각 Connected type의 경우 CLS(Cloud License Server)라고 해서 NVIDIA에서 hosting합니다. 하지만 이번 Lab 케이스에서는 Private 환경에 구축을 목표로 했기 때문에 DLS (Delegated License Server) 모델로, Hosted in our own environment 방식으로 인스턴스를 배포했습니다.
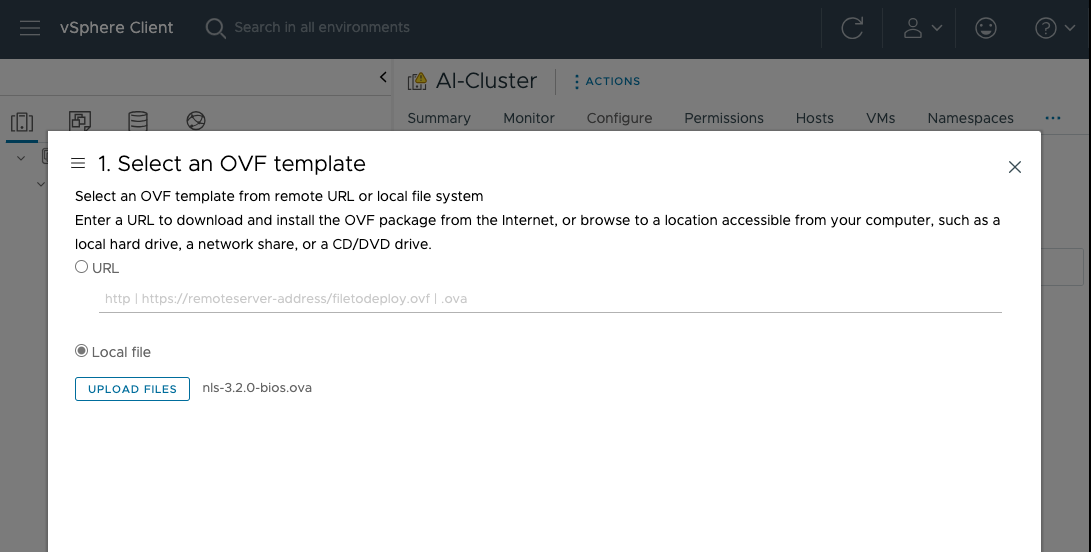
배포 이후에 전원이 켜지면 NLS 서버에게 IP를 지정해주기 위해서 디폴트 id: dls_admin / pw: welcome 으로 로그인해서 스크립트 하나를 실행합니다.
/etc/adminscripts/set-static-ip-cli.sh몇가지 주의해야할 점이 있습니다.
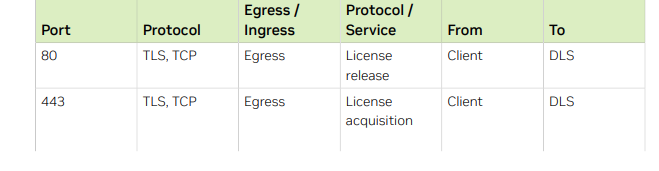
-
Port open
80번 / 443번 포트를 열어야 기본적으로 licensed client와 DLS 인스턴스 간에 communication이 가능합니다. 방화벽 설정 등에 기본적으로 80 / 443이 오픈되어 있는지 체크합니다. -
Sizing
VM sizing같은 경우는 4vCPU / 8GB로 배포하면 5개의 client를 1초당 처리해 74ms 정도의 average response time을 기록하는 정도입니다. (출처: Nvidia License System user guide)
6vCPU / 12GB 또는 High throughput을 위해서는 8vCPU / 16GB 의 VM으로 배포하는 옵션도 있습니다.
2. Host vGPU Driver 설치
NVIDIA GPU를 가상화 환경에서 이용하려면 2가지 driver의 설치가 필요합니다.
Host driver: Host driver는 가상화 환경에서 실제 물리적 GPU를 관리하는데 사용됩니다. 이 Driver를 통해 NVIDIA GPU를 Host system에서 인식하고, VM에게 vGPU를 제공하게 됩니다.Guest Driver: Guest driver는 말 그대로 Guest VM 내에서 동작하는데, Host system에 할당된 vGPU를 제어하는 역할입니다. Guest driver를 통해 VM에 vGPU를 표시합니다.
Driver install to ESXi
준비된 Driver vib파일을 vSAN Datastore에 올리고, esxcli를 통해 vib install합니다.
주의사항 : ESXi host를 Maintanance mode로 먼저 전환한 이후에 driver 설치를 진행합니다.
$ esxcli software vib install -d /vmfs/volumes/datastore/host-driver-component.zip
Edit Graphic Device Settings
vSphere Client의 Hardware > Graphic 설정에서 Shared Direct 를 설정합니다.
2가지 옵션에 대해 보다 자세히 알아보면,
Shared: VM의 graphic을 담당하는 메모리를 Host의 일반적인 system memory와도 공유하는 옵션Shared Direct: 말그대로 Direct!하게 VM에 할당된 GPU를 사용하여 VM이 Host s ystem의 특정 Graphic card를 직접 공유하는 옵션입니다. 우리가 LLM을 배포할 VM이 Host system memory를 공유할 필요가 없고, GPU memory만 access하면 되기 때문에 Shared Direct 옵션으로 선택했습니다.

첫번째 vGPU 상식: vSphere에서 GPU를 이용하는 2가지 방식 : vGPU or DirectPath I/O?
vSphere환경에서 GPU를 사용할 때, 2가지 방식 중 하나를 선택할 수 있습니다. VM에서 물리적인 GPU에 독점적인 access를 얻는 DirectPath I/O 방식과, vGPU 기술 (Time sliced / MIG) 를 사용하여 여러 가상머신이 GPU 리소스를 공유하도록 하는 vGPU 방식입니다. DirectPath I/O의 경우 GPU workload가 큰 경우에 독점적인 access로 인한 최대 성능 효과를 기대할 수 있지만, 만약에 할당된 VM의 GPU workload 작업부하가 작은 경우에는 비싸고 귀한 GPU를 낭비 하게될 수 있습니다. workload의 특성에 따라 선택하는 것이 중요합니다!
두번째 vGPU 상식: vGPU의 MIG mode와 Time sliced mode
만약 GPU를 여러 가상 머신이 나누어 쓰는 형태에 적합한 workload라면, MIG(Multi Instance GPU)와 Time sliced 모드의 차이 또한 고려해야합니다. 둘 다 커다란 GPU를 나눠서 쓰는 방식이지만, 어떻게 VM단에서 나눠서 사용하는지의 소비 방식에서 차이가 있습니다.
간단하게는, MIG는 ampere 이상에서만 사용 가능하며, 각 GPU 인스턴스가 실제로 격리되어 있어 Time sliced mode보다 "더" 격리된 환경을 제공해 VM간 interference(간섭)가 적습니다.
Time slice mode는 GPU를 쓰고 싶어하는 VM들끼리 GPU를 시간 단위로 나누어쓰는데, 시간적으로 나누어진 자원을 공유하므로 일정 시간 동안 GPU를 독점적으로 사용하긴 하나 MIG의 격리 수준보다는 낮습니다.
MIG 같은 경우는 vSphere7부터 tech preview로 공개되어 vSphere 8부터 GA 되었습니다.
참고로 vGPU를 추상화하는 vSphere의 논리적 단위인 vSphere vGPU Profile은 8개까지, passthrough device의 경우 VM당 32개까지 지원합니다.
Deploy VM for Training Server
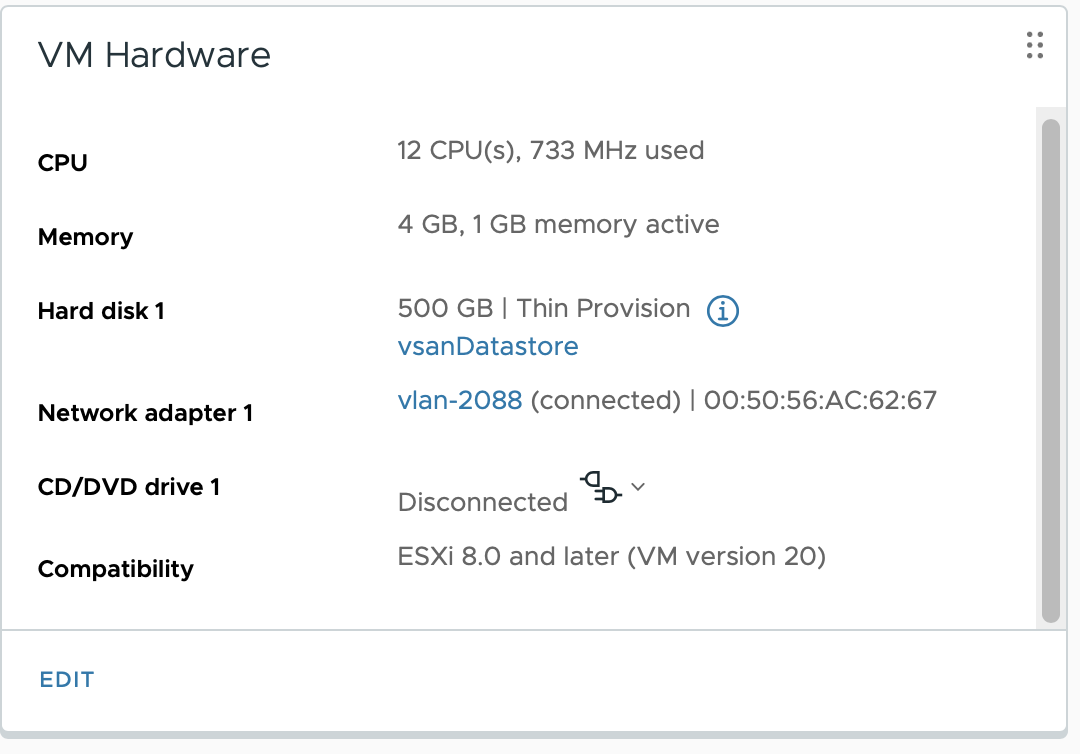
이제 LLM training을 위한 VM을 하나 배포하는데, VM Sizing은 12vCPU / 30GB로 배포했습니다. VM Sizing의 기준은 배포할 모델과 사용할 Parameter 수에 따라야 합니다.
아래 VMware docs Requirements에서는 16vCPU, 64GB RAM이 필요하다고 했습니다만
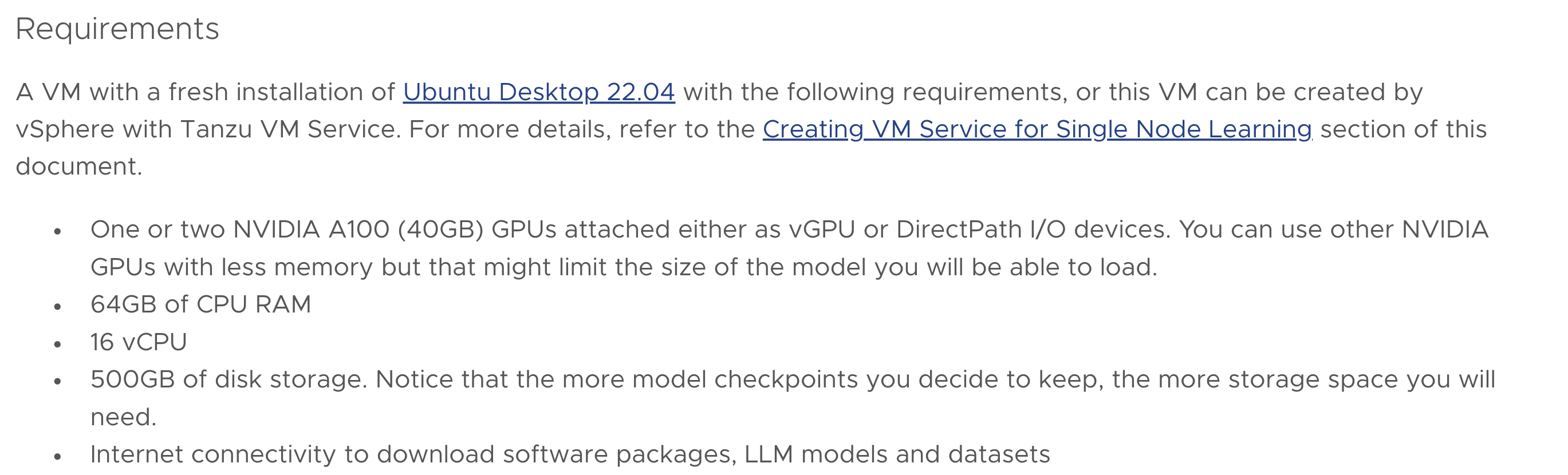
A100 40GB짜리 밖에 없는 환경이어서 어쩔 수 없이 더 작게 배포했습니다.
만약에 환경 별로 사용할 모델에 맞는 VM의 sizing이 custom하게 결정되어 있는 경우, VM Class를 custom하게 지정해 원하는 user에게 Training용 VM을 권한별로 creation 할 수 있도록 하는 것이 VMware Private AI의 장점인 것 같습니다.
예를 들어, OS image나 복잡한 python dependency까지 미리 구워진 VM Image들을 contents library에 저장해놓고, VM Class 에서의 지정을 통해 (ex. AWS에서 t3.small / t3.medium 등 instance type이 이미 정해져서 end user가 클릭만 하듯이) 우리 Data scientist들도 Training / inferencing에 사용될 모델에 따라 VM Class만 선택하면 되는 것입니다.
3. Kubernetes cluster에서 vGPU를 이용하는 방식 (Plus 성능..)
LLM은 대체로 컨테이너 환경에 배포되며, 우리의 비싼 NVIDIA GPU를 효율적으로 이용해 workload들의 용도와 사이즈에 맞게끔 container를 잘 할당 해주는 것이 Best입니다. 이런 이상적인 시나리오를 위해서는, 먼저 우리 Kubernetes cluster가 GPU에 access 하도록 세팅하는 것이 첫걸음이 되겠습니다. (하지만 첫걸음부터 아주 어려웠음)
NVIDIA GPU Operator와 NVIDIA Network operator를 이용해 K8S Cluster가 GPU에 access하도록, 또 성능을 위해 K8S Cluster에서 RDMA를 enable하는 방식을 소개합니다.
NVIDIA GPU Operator
What it is?
Kubernetes에서는 K8S Cluster가 NVIDIA GPU라던가, Smart NIC 와 같은 special hardware resource로의 access를 통해 리소스를 이용할 수 있도록 여러가지 방법을 지원합니다. Device plugin framework를 이용하여 end-to end로 개발할 수도 있지만, 보통 drivers, container runtime이나 library 등 여러가지 dependency를 한번에 관리하는 operator를 주로 이용해 NVIDIA software compenents를 한번에 설치하는게 편합니다. (CUDA enable을 위한 NVIDIA driver / GPU를 위한 K8S device plugin, NVIDIA container toolkit 등)
GPUDirect - RDMA
GPU Operator의 역할 중에 하나는 Kubernetes Cluster에서 GPUDirect RDMA 기능을 사용하게 해주는 기능입니다.
RDMA는 Remote Direct Memory Access의 약자로, PCIe 인터페이스를 통해서 Third party peer device와 직접적인 데이터 통신을 가능하게 하는 기능입니다. 만약 Workload가 K8S 클러스터의 한 container A에서 다른 GPU가 달린 다른 Host의 container B와의 통신이 필요한 형태라면, 이러한 GPU 메모리 간 직접적인 Data 통신이 성능 향상에 큰 도움이 되겠죠.

아니 어떻게 다른 GPU의 Memory에 직접 access가 가능한가?
userspace CUDA API + NVIDIA Peermem + Mellanox 3조합으로!
NVIDIA에서 개발한 CUDA는 NVIDIA GPU에서 병렬 computing application을 실행하도록 합니다. userspace에서 CUDA API가 제공된다는 것은, 커널 코드 수정 없이 일반적인 응용프로그램처럼 CUDA 기능을 활용하는 프로그램을 사용한다는 것을 의미하는데, 그래서 응용프로그램 레벨에서 개발자는 CUDA API를 활용해 GPU에서의 parallel programming을 진행할 수 있습니다.
CUDA 11.4 부터는 .run 확장자를 가진 nvidia-peermem 커널 모듈이 NVIDIA 표준 driver installer에 제공됩니다. 이 kernel module은 GPUDirect RDMA에서 Mellanox InfiniBand나 RoCE 어댑터를 통해서 GPU간에 peer-to-peer Read / Write 액세스를 제공합니다.
4. NVIDIA Network Operator
What it is?
NVIDIA Network Operator는 NVIDIA GPU를 사용하는 K8S cluster에서 GPU 리소스의 Network에 관련한 설정을 도와주는 도구입니다.
NVIDIA Network Operator는 위에 설치한 NVIDIA GPU operator와 커뮤니케이션하며 high-throughput과 low-latency의 GPU computing cluster를 운용할 수 있도록 돕습니다.
보다 자세하게는 RDMA 실행과 GPUDirect RDMA workload가 kubernetes cluster에서 enable되도록 하는 역할인데, 여기서 RDMA는 Remote Direct Memory Access의 약자로 두 장치 간에 CPU를 거치지 않고 메모리에 직접 액세스해 데이터를 전송하는 기술입니다. 즉, Kubernetes cluster에서 Cluster가 배포된 Host의 CPU를 거치지 않고, 장착된 GPU memory에 직접 access할 수 있도록 지금 설치하고 있는 network operator가 도와주는 것입니다.
NVIDIA Network Operator를 helm chart를 통해 구성했더니 아래와 같은 component들이 배포되었습니다.
- NVIDIA network operator node : NVIDIA networking 자원을 관리하는 역할.
- CNI Plugin : Pod의 인터페이스를 생성하고 구성합니다. 만약 클러스터에 pod가 새로 생성된 경우, network operator가 이 CNI plugin을 사용하여 IP와 DNS 정보를 할당받습니다.
- IP address management (IPAM) plugin 과 다른 component들
- Mofed-ubuntu20.04 : Mellanox OFED는 Ethernet 네트워크, 주로 대규모 컴퓨팅 클러스터와 High Performance Computing 시스템 등에서 성능 향상을 위해 RDMA를 활용해 데이터를 효율적으로 전송할 수 있도록 하는 오픈소스입니다. NVIDIA GPU 에서도 Mofed를 사용해 CPU 개입 없이 RDMA를 가능하도록 하며, kubernetes cluster에서도 고성능 vGPU 가상화 환경을 가능하게 하기 위해 NVIDIA network operator component에 포함되어 배포된 것으로 생각됩니다.
- SR-IOV device plugin : SR-IOV는 Single Root I/O Virtualization의 약자로, VM이나 Container한테 물리적인 NIC같은 hardware resource를 할당해줍니다. Kubernetes cluster에서도 SR-IOV 기능을 사용해서 클러스터에 배포될 container에게 가상 network interface를 관리하도록 하는 역할일 듯 싶습니다.
K8S Cluster에 Network Operator 배포해보기
(본 배포는 VMware ESXi hypervisor에서 동작하는 Tanzu Kubernetes Cluster에서 실행되었습니다)
Network operator는 NGC(Nvidia GPU Cloud) portal에 접속하기 위한 email / API key를 가지고 만든 secret을 기반으로 helm chart를 이용해 배포합니다.
먼저 node를 worker라고 라벨을 달아줍니다.
kubectl label node <노드 이름> node-role.kubernetes.io/worker=worker다음으로 network operator를 위한 namespace를 만들어주고,
kubectl create namespace nvidia-network-operatorNGC 정보를 가진 secret도 만들어줍니다.
kubectl create secret docker-registry ngc-image-secret -n nvidia-network-operator --docker-server=nvcr.io --docker-username='$oauthtoken' --docker-password='YOUR NVIDIA API KEY' --docker-email='YOUR NVIDIA NGC EMAIL'
Network operator를 위한 values file같은 경우는 This repo를 참고했습니다.
NVIDIA operator를 위한 helm chart 로딩을 위해 helm repo add를 해주고, 이어서 helm hart 설치까지 해줍니다.
### helm chart 로드
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
--username='$oauthtoken' --password=${NGC_API_KEY} \
&& helm repo update
### Helm chart 설치 with values.yaml 파일
helm install network-operator nvidia/network-operator -n nvidia-network-operator --create-namespace --version v23.5.0 -f values.yaml --debug배포결과
vmkadmin@ubuntu01:~$ kubectl -n nvidia-network-operator get pods
NAME READY STATUS RESTARTS AGE
cni-plugins-ds-75z4c 1/1 Running 0 7s
cni-plugins-ds-j6ngw 1/1 Running 0 7s
cni-plugins-ds-zjc4d 1/1 Running 0 7s
kube-multus-ds-czsd8 1/1 Running 0 7s
kube-multus-ds-f277l 1/1 Running 0 7s
kube-multus-ds-gdt2p 1/1 Running 0 7s
network-operator-57cf95446-d74hs 1/1 Running 0 14s
network-operator-node-feature-discovery-master-848d8b8cdf-678k8 1/1 Running 0 14s
network-operator-node-feature-discovery-worker-5fmmt 1/1 Running 0 15s
network-operator-node-feature-discovery-worker-f8bzd 1/1 Running 0 15s
network-operator-node-feature-discovery-worker-gg7cc 1/1 Running 0 14s
network-operator-node-feature-discovery-worker-nt9pn 1/1 Running 0 14s
whereabouts-448c5 1/1 Running 0 4s
whereabouts-5fhr2 1/1 Running 0 4s
whereabouts-zm78v설치한 component들이 각각 어떤 역할을 하는지 좀 자세히 보겠습니다.
Network-operator-node: NVIDIA Network controller와 agent간의 상호 작용을 관리CNI-Plugin: NVIDIA Networking 기능을 사용해 Pod의 network 구성 관리 (Network interfce 생성 및 구성 / Pod networking traffic 관리 등)MOFED ubuntu: Pod OS에 SR-IOV 기능을 사용하려고 설정하는데 필요한 모듈 설치. (Ubuntu OS). 우리 Lab에서도 Ubuntu 계열의 PhotonOS(VMware 개발 오픈소스 리눅스 운영체제) 환경이었는데도 왜 component설치가 안되었는지 아직도 모르겠습니다..sriov-device-plugin: Kubernetes Cluster level에서 SR-IOV 기능을 사용하도록 필요한 모듈을 설치
이렇게 Container 환경에서도 vGPU를 사용할 준비가 되었네요 :)
Host Device Network에 대하여..
배포가 정상적으로 끝나면, network operator는 구성되었지만 이것으로 끝난것은 아닙니다.
Host Device component를 추가적으로 배포해서 Kubernetes networking이 해당 operator를 사용하도록 설정해야합니다.
저는 여기서 network operator 설치를 실패했는데요.. Host Device Network에 대해 몰랐기 때문이 아닌가 싶습니다.
일반적으로 container는 격리된 환경에서 실행되기 때문에 host system의 자원에 직접 access하지 않습니다. 그치만, 우리가 배포하고자 하는 virtual function들은 GPU를 직접 access해서 성능을 높이고 싶죠. 이런 경우에, HostDeviceNetwork을 설정하면 GPU Device를 container에서 직접 사용할 수 있게 됩니다.
HostDeviceNetwork는 K8S CRD로 배포되고, NVIDIA GPU를 사용하는 pod가 특정 범위 내에서 동작하도록 하기 위해 IP 주소를 whereabouts설정을 통해 관리합니다.
apiVersion: mellanox.com/v1alpha1
kind: HostDeviceNetwork
metadata:
name: hostdev-net
spec:
networkNamespace: "default"
resourceName: "nvidia.com/hostdev"
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "10.109.208.140/26",
"exclude": [
10.109.208.141
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info"위 yaml에서 range 와 exclude를 환경에 맞게 조정하고 배포합니다.
5. LLM Fine Tuning
GPU부터 가상화 vSphere / Tanzu Kubernetes(Container) 환경의 인프라를 구성하며 LLM 과 Generative AI와 관련된 다양한 작업을 실행할 준비가 이제 다 되었기 때문에, VMware LLM 예제 를 참고해 LLM Fine tuning을 진행해보겠습니다.
LoRA와 RLHF기법을 사용한 LLM Fine tuning
HuggingFace Hub와 같은 곳에서 다양한 Large Language Model을 Open source로 지속적으로 공개합니다. 이번 Lab에서는 Falcon-7B 모델을 사용했고, Falcon 7B에서 7B란 Parameter 70억개짜리의 대규모 언어 모델을 의미합니다. 코드 / 이미지 / 텍스트 등 광범위한 Dataset에 대해 훈련하여 상용으로 제공되어 Text 생성(코드, 대본, 시, 음악, 이메일..등) / 번역 / QnA 등에 사용되는 인기있는 대규모 언어 모델입니다.
70억개의 Parameter?
매개변수(Paremeter)는 신경망에서 학습 가능한 가중치(weight) 와 편향(bias)입니다. Paremeter가 많을수록 신경망이 더 복잡한 패턴을 학습할 수 있게 됩니다.
이번 Lab에서도 LLM Training을 진행하며 이후 과정에서 weight와 bias를 조정하는 과정을 거쳐 Model의 성능을 개선하고 특정 작업과 지식 도메인에 대한 능력을 향상시킬 수 있는 Fine Tuning을 최종적으로 수행하게 됩니다. weight를 조정한다는 것은 입력 신호의 크기를 조절하여 출력 신호에 미치는 영향을 결정합니다. Bias 를 조정하는 것은, 출력 신호의 기준점을 조정합니다. 예를 들자면 이렇게 설명할 수 있을 것 같습니다.
weight 조정을 통한 입력 신호의 중요도 조절 예시 : 예를 들어, QnA LLM model이 "대한민국의 수도는 어디입니까?" 라는 질문에 대답해야한다고 가정하면, 이 질문에 대한 답은 "대한민국" 이라는 단어에 크게 의존합니다. 따라서 "대한민국" 이라는 단어에 대한 가중치를 높여(입력 신호의 크기 조정) 이 단어의 중요도를 높일 수 있습니다.
bias 조정을 통한 출력 신호의 기준점 조절 예시 예를 들어, QnA LLM model이 "서울의 인구는 몇 명입니까?" 에 대한 질문에 답해야한다고 가정해볼 때, 이 질문에 대한 답은 숫자이므로, 출력 신호의 기준점인 bias를 조정해 Model이 생성하는 숫자의 범위를 제한해 잘못된 값을 생성할 가능성을 줄일 수 있습니다.
특정 유형의 오류 방지 예를 들어 "프랑스의 수도는 서울입니까?" 에 대한 질문에 답해야하면, 모델은 잘못된 대답을 생성할 가능성이 높아 오류를 방지하기 위해 가중치와 편향을 조정합니다.
"프랑스" 라는 단어에 대한 weight를 낮추거나, "프랑스" 와 "서울" 이라는 단어 사이의 거리를 증가시킵니다.
Fine Tuning 기법: LoRA와 RLHF
여기서 1가지 의문이 생겼습니다. LLM을 Fine tuning 시키려면 내 Dataset의 모든 단어(token)에 대한 weight / bias를 하나하나 다 어떻게 조정하는가? 인프라 입장에서 생각해보면, weight / bias 를 조정하는데 들어가는 값비싼 Computing resource, Human resource.. 등이 결국 다 비용일 수 있기 때문에, Fine tuning을 최적화하는 방법을 제시합니다.
PEFT (Parameter Effective Fine Tuning) 기법을 이용한 Fine tuning 단순화
LoRA (Low Rank Adaption)
LLM의 Fine tuning 과정을 단순화하는 여러 가지 기법이 있습니다만, LoRA (Low-Rank Adaption)가 인기 있는 기법 중 하나입니다.
LoRA에서는 Pre-trainined 된 Model의 일부 weight을 고정 시키고, 나머지 weight만 조정해 Training 시간을 단축합니다.
RHLF (Reinforcement Learning from Human Feedback)
인간 Feedback으로부터의 강화학습을 통해 인간의 전문 지식과 도메인별 지식에서 학습할 수 있도록 합니다. Model이 Feedback을 기반으로 정교화되어서 보다 정확하고 맥락적으로 적절한 답변을 얻어낼 수 있습니다.
Prerequisites: VM & Few Software
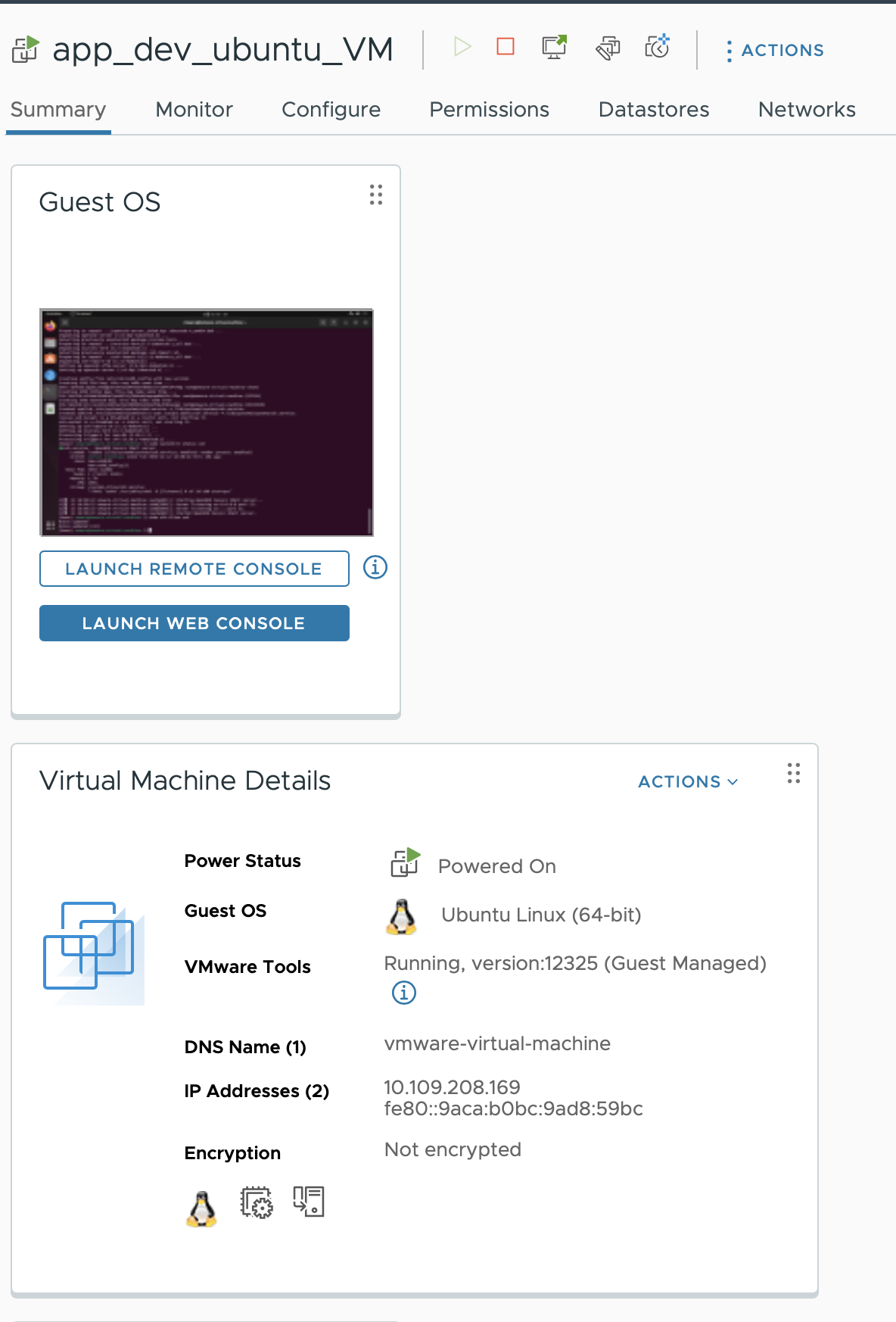
- Training server를 위한 VM (12vCPu / 30GB RAM / 400GB vSAN)
| Software | Descritpion | Shell |
|---|---|---|
| NVIDIA Guest Driver | NVIDIA vGPU를 VM에서 이용하기 위해 NVIDIA driver와 CUDA toolkit download | wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run |
| CUDA 설치 | sudo sh cuda_11.8.0_520.61.05_linux.run | |
| Docker Engine | Huggingface container 사용하기 위해 | sudo apt-get install docker-ce docker-ce-cli containerd.io |
| Miniconda installation | Package, 환경 관리자로 여러 가지 version의 python과 다양한 Library와 package를 설치하고 관리하는데 도움이 됨 | wget -nc https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh < Perform a Miniconda silent installation> bash ./Miniconda3-latest-Linux-x86_64.sh -b -p ($HOME/miniconda/bin/conda shell.bash hook)" <With this activated shell, install conda's shell functions > conda init |
Python VENV
- LLM Fine tune code를 담고 있는 Jupyter notebook git clone
## Cloning the git repo
# Verify git is installed
git –version
# If git is not installed, install it with these two commands
sudo apt update
sudo apt install git
# Clone the git repo containing the fine-tune Jupyter notebook
git clone https://github.com/vmware-ai-labs/VMware-generative-ai-reference-architecture.git
# Enter the repo’s root directory로 이동
cd VMware-generative-ai-reference-architecture/LLM-fine-tuning-example/- LLM Tasks를 위해 conda env를 이용해 virtual environment 생성
conda env create -f llm-env.yaml
conda activate llm-env
wandb login- Jupyter lab session 시작
jupyter-lab --ip <YOUR_IP>
Fine Tuning Job Running하기
Code는 VMware Generative Reference AI Architecture Github 를 참고했습니다.
1. 사전 학습된 model의 tokenizer를 load하는 단계
Jupytor Lab session (Notebook-falcone-finetune.ipynb) script의 cell을 순차적으로 실행해 Falcon7B Training Process에 대한 monitoring을 진행합니다.
처음에 Huggingface의 transform library를 사용해 AutoTokenizer.from_pretrained (MODEL_NAME, trust_remote_code) cell을 실행해 선택한 model의 tokenizer를 불러오고, loading합니다.
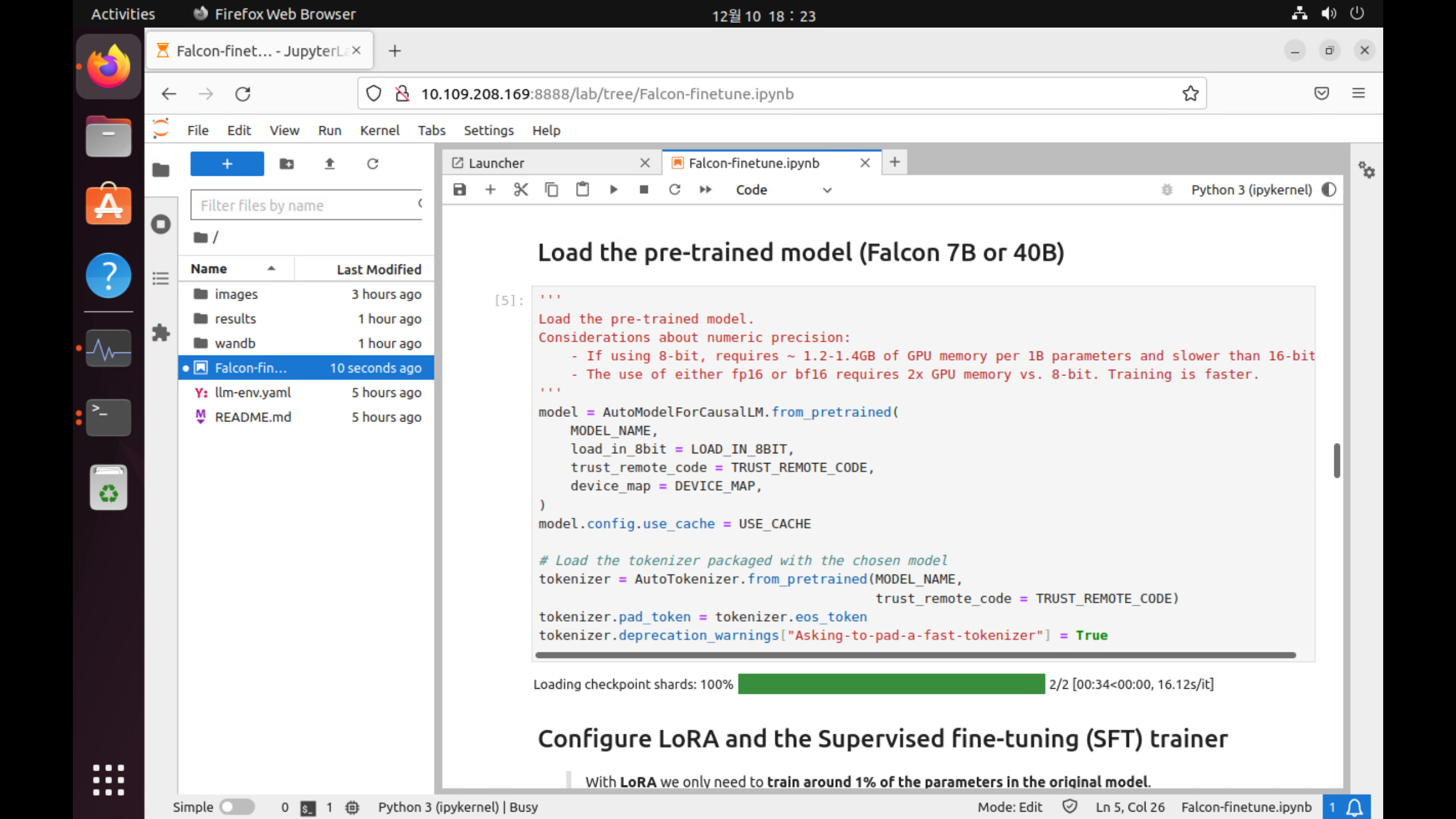
2. Fine tune the model 단계
Training loop 를 for문으로 반복하며 frainer.train() 으로 학습을 시작하는 것을 볼 수 있습니다.

Fine Tuning Monitoring 결과 해석
1. Training Process
Job Run History

Training process가 끝나면 결과값을 summary해서 보여줍니다.
Global step 64 training step에 따른 결과값으로, Training step 별 loss 값을 비교해보았을 때, training step 64일 때 best checkpoint를 기록하는 결과를 볼 수 있습니다. 일반적으로 LLM 훈련 중에는 정기적으로 모델의 성능을 평가하고 모델의 checkpoint (가중치 및 설정)을 저장하는데, 이 때 best global training checkpoint란 특정 지표가 최적이었던 global step 에서의 model check point를 기록하는 것을 의미합니다.
이 모니터링 지표에서 더 좋은 성능 갖는 경우, 해당 훈련 단계의 모델 weight를 저장하고, 다음 prompting 단계에서 이렇게 기록된 best LLM Checkpoint를 referencing 하여 실험적으로 적용해볼 수 있습니다.
Eval Loss
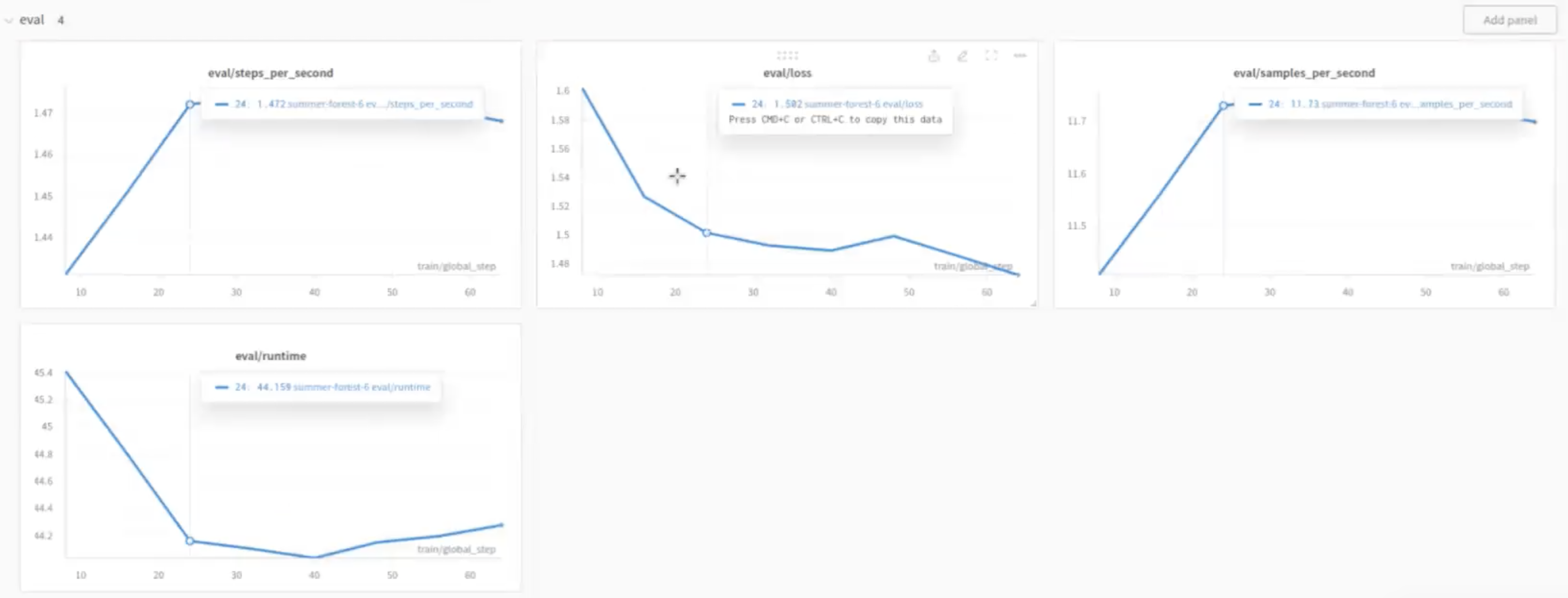
- 2번째 :
eval/loss: Training step이 늘어날수록 eval loss metric이 감소하는 결과를 보이는 하향 그래프를 기록합니다. 훈련 중에 모델이 최적화될 수록 loss metric이 감소하는 것으로, 복잡한 Data를 더 잘 처리하고 예측을 정확하게 수행하는 결과를 기록했습니다. - 4번째:
eval/runtime: Training step이 증가할수록 runtime시간이 줄어들다가 최적의 step이후에 다시 증가하는 양상입니다.
Infra monitoring

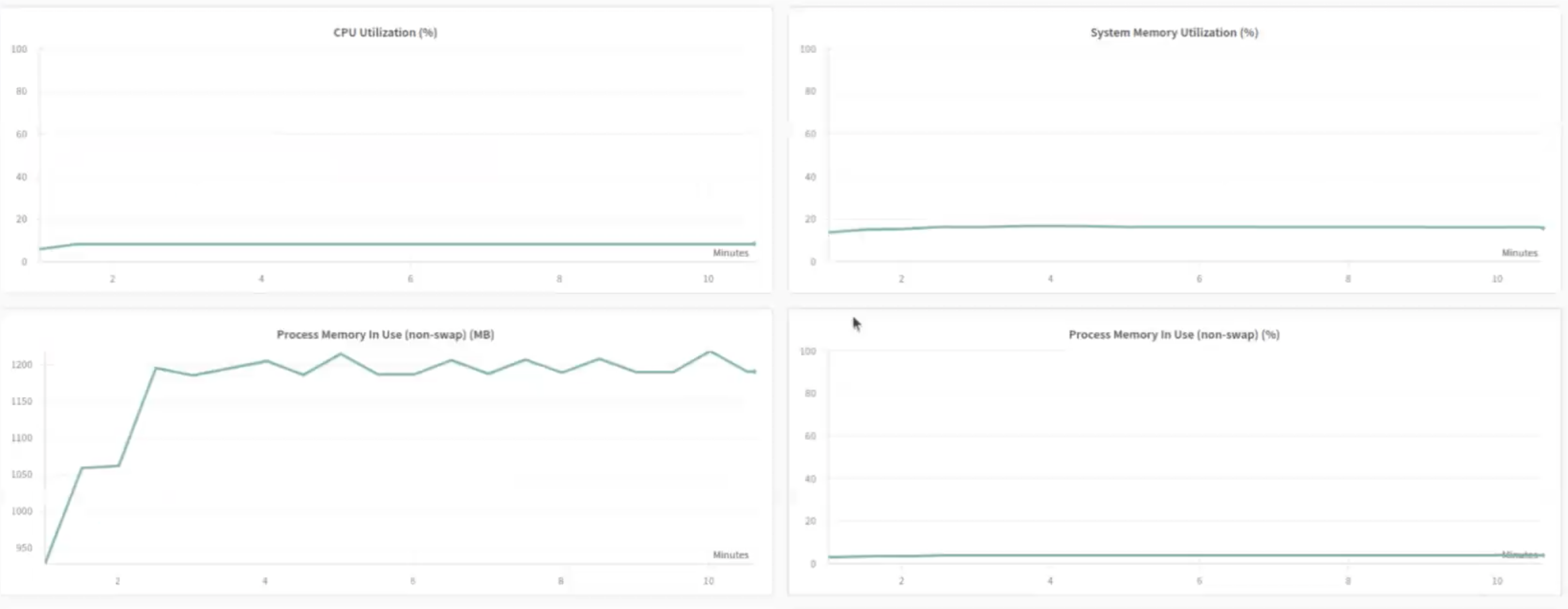
- Falcon 7B 기준, A100 GPU (Memory 40GB)는 평균 약 40%, 평균 70%의 utilization rate을 보여줍니다.
Train / Epoch
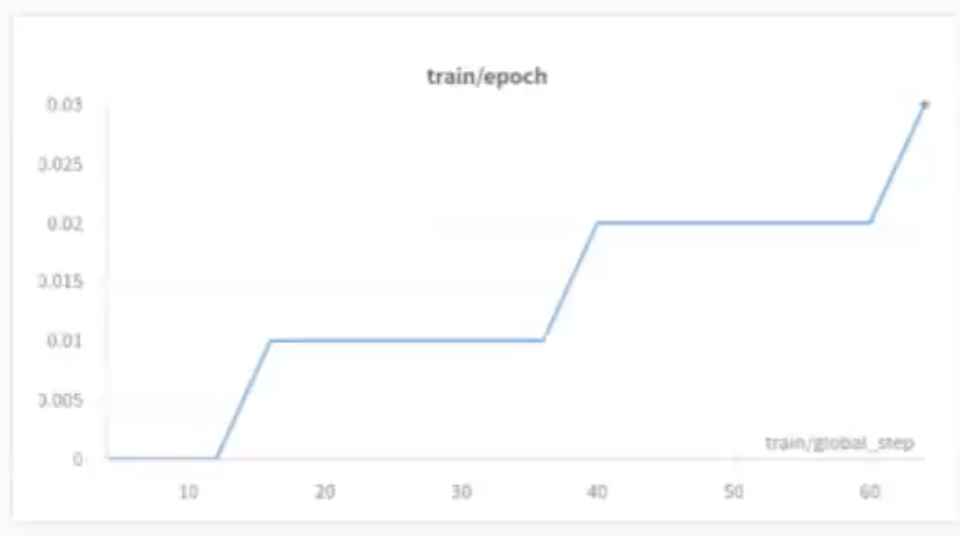
Epoch은 전체 학습 Dataset을 한번 훈련하는 것을 나타내는 단위입니다.
모델이 학습하는 것을 문제집을 푸는 과정이라고 생각했을 때, 학생이 전체 문제가 담긴 모든 단원을 다 풀어 문제집을 한 번 끝내는 과정이라고 비유할 수 있겠습니다.
기록된 Checkpoint를 가지고 Prompting 과정을 통해 Reasoning engine으로 LLM을 사용하기
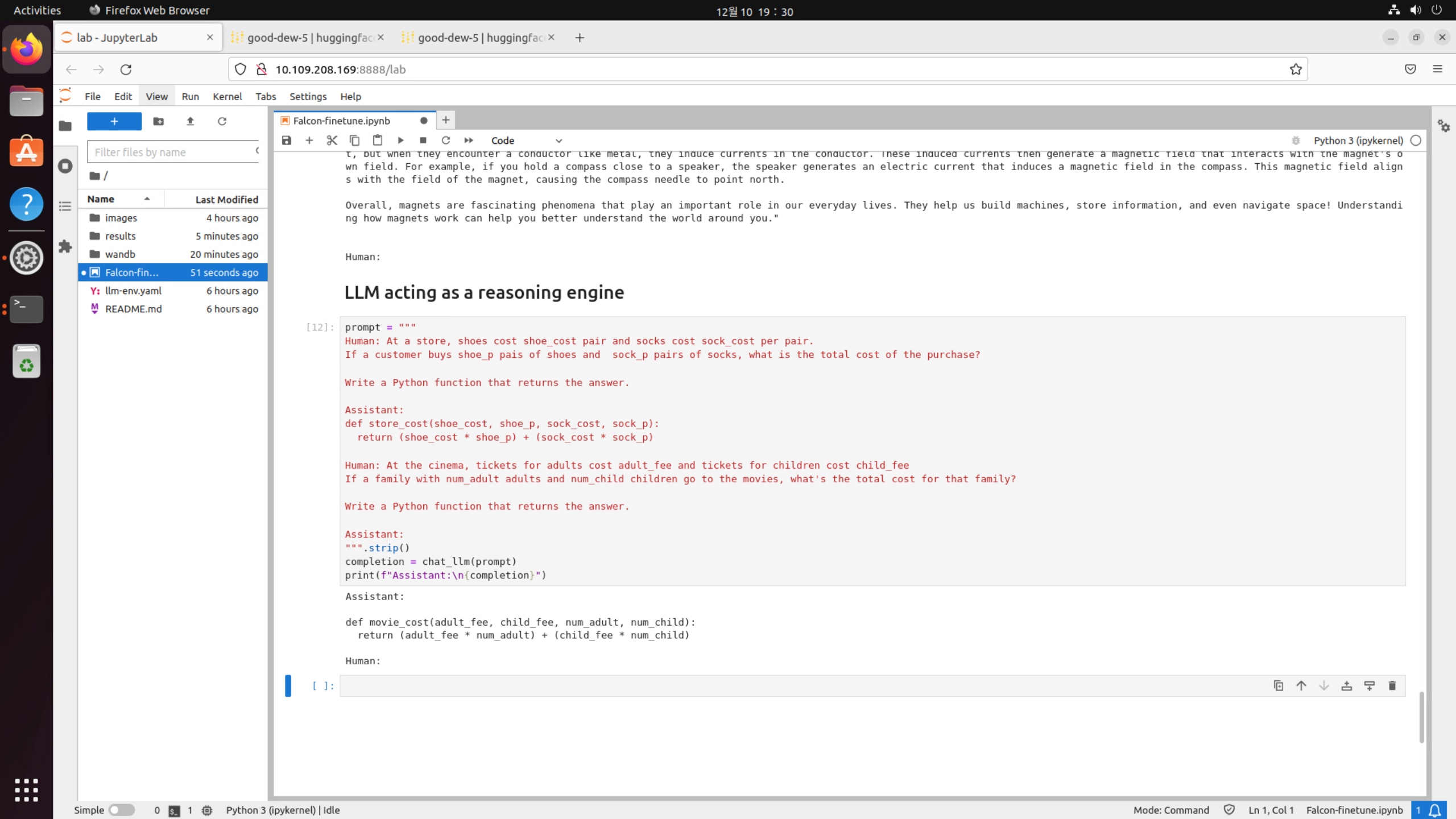
이전 단계에서 기록되었던 모델의 checkpoint (가중치 설정 및 training step 64) 를 가지고 몇개의 prompting을 진행하는 단계입니다.
Prompting?
모델에게 초기 입력을 제공하여 해당 입력을 기반으로 Text를 생성하거나 계속해서 Text를 생성하도록 유도하는 과정을 의미하며, 모델에게 원하는 문맥이나 주제에 맞는 Text를 생성하도록 유도하는 기술적인 방법
이번 예시에서 제시한 prompting은
- human의 "가게에서 shoe_cost와 shoe_cost per pair, sock_cost_per pair(페어 당 양말 비용)을 주고 shoe_p(pairs of shoes)와 sock_p pairs를 산다면 total_cost가 얼마인가요?" 를 기반으로
- Assistant에 store_cost (return shoe_cost shoe_p) + (sock_cost sock_p) 함수를 제공하고
- Human의 new prompt로 "영화관에서 adult cost와 child cost가 있을 때, 모든 가족의 영화값은 얼마인가요?" 에 대한 답변을 제공받아야하는 모델의 평가를 의미합니다.
이렇게 vSphere / vSAN 환경을 기반으로 Fine tuning 모델 준비 / 선택한 모델에 따른 Infra sizing / Fine tuning job running / Prompting 까지 진행해보았습니다.
6. Coding Assistant - Enterprise를 위한 Code assistant solution; VMware Safecoder
Enterprise need a secure coding assistant! Your own on-prem Github copilot
VMware는 Private AI add on 레퍼런스 아키텍쳐를 통해 Huggingface와 협업해 Enterprise에서의 완전한 규정준수, 자체 호스팅되는 AI 기반 소프트웨어 개발 프로그래밍 도구를 Safecoder라는 이름으로 제공합니다. (https://huggingface.co/blog/safecoder, commecial solution)
Safecoder는 security 와 privacy를 원칙으로 하여 개발되었으며, 특히 LLM training이나 inferencing 과정에서 Code가 사내의 VPC 밖으로 벗어나지 않도록 해주는 "own on-prem github copilot" 정도라고 이해하면 될 것 같습니다.
사전에 사내에 컨테이너 형식으로 준비되어 있는 Code completion inference container (Starcoder)를 기반으로 vscode plugin으로 code assistant를 사용하는 과정을 소개하겠습니다.
Prerequisites: Inference VM
- Infra: (12vCPU / 30GB / GPU 1 * NVIDIA A200 40GB PCIe 로 진행)
- Huggingface Account API Token
Code assistant inference 컨테이너 배포
준비된 vSphere 환경의 Ubuntu VM에 Starcoder container를 배포합니다.
sudo docker run --gpus 0 -v /home/octo/hf_text_gen:/data -e HUGGING_FACE_HUB_TOKEN=<API 토큰> --network host ghcr.io/huggingface/text-generation-inference:0.8 --model-id bigcode/starcoder --max-concurrent-requests 400 --max-input-length 4000 --max-total-tokens 4512 -p 8081각 Variables 의미
--gpus 0: VM에 available된 첫번째 GPU를 utilization 하도록 설정한다는 옵션입니다. 만약 2개의 GPU가 VM에 assign되어 있다면, training을 위한 activity 또는 다른 model을 이용하는 code-assistant 프로그램 등 다른 목적에 따른 GPU들을 각각 utilization 할 수 있도록 설정할 수 있습니다.--max-input-length 4000: 이전 training 단계의 token들을 이 서버에서 Maximum input length로 최대 몇 개 까지 handle할 수 있는지를 결정하는 매개변수입니다. 보통 약 3글자가 하나의 token으로 계산되므로 최대 token 4000은 입력 설정을 최대 12000자 (safecoder에서는 code 글자..) 정도로 한다는 것을 의미합니다.-p 8081: docker listening port 8080--network host: 이 container 의 port를 VM network에 expose하고 이 inference container를 VM외부에서도 accesible할 수 있도록 지정해줍니다.
VScode plugin과 연동해 code generation해보기
VScode에 배포되어 있는 llm-vscode extension configuration을 이용해 VMware code autocomplete도 이용할 수 있습니다. 예를 들면 ctrl+z를 누르면 generate code를 auto recommendation 해주는 것처럼 말이죠.
이용 방법은 아래와 같습니다.
1. Hugging face 검색 > llm-vscode 플러그인 install

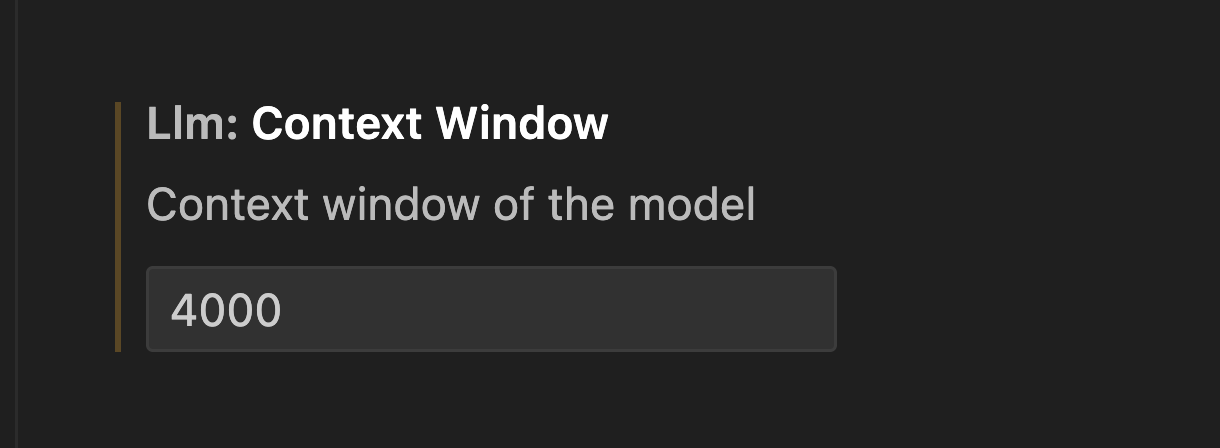
2. Context window설정
Context window를 4000으로 설정합니다. Context window는 code 추천을 위해 서버로 전송되는 문자 수를 의미합니다. (참고로 4000은 default값입니다.)
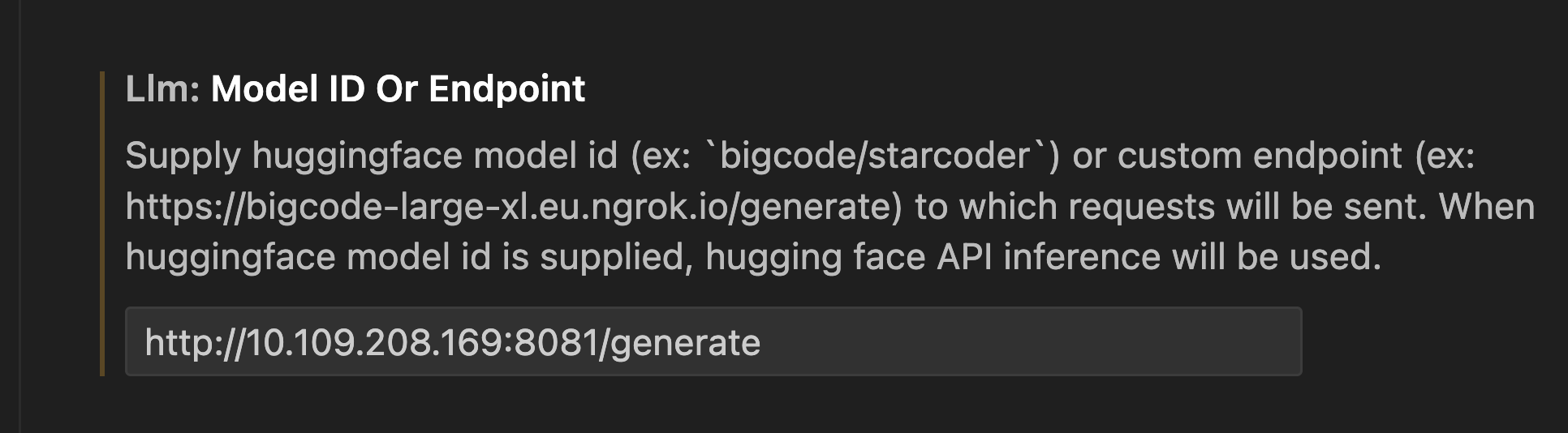
3. Model ID / Endpoint 입력
LLM Inferencing server IP:Port/generate를 입력합니다.
만약 safecoder의 code 추천 서버가 아니라, 기업에 자체적으로 제작된 code generation inferencing container가 존재하면 그 inferencing container의 정보를 입력할 수 있습니다.
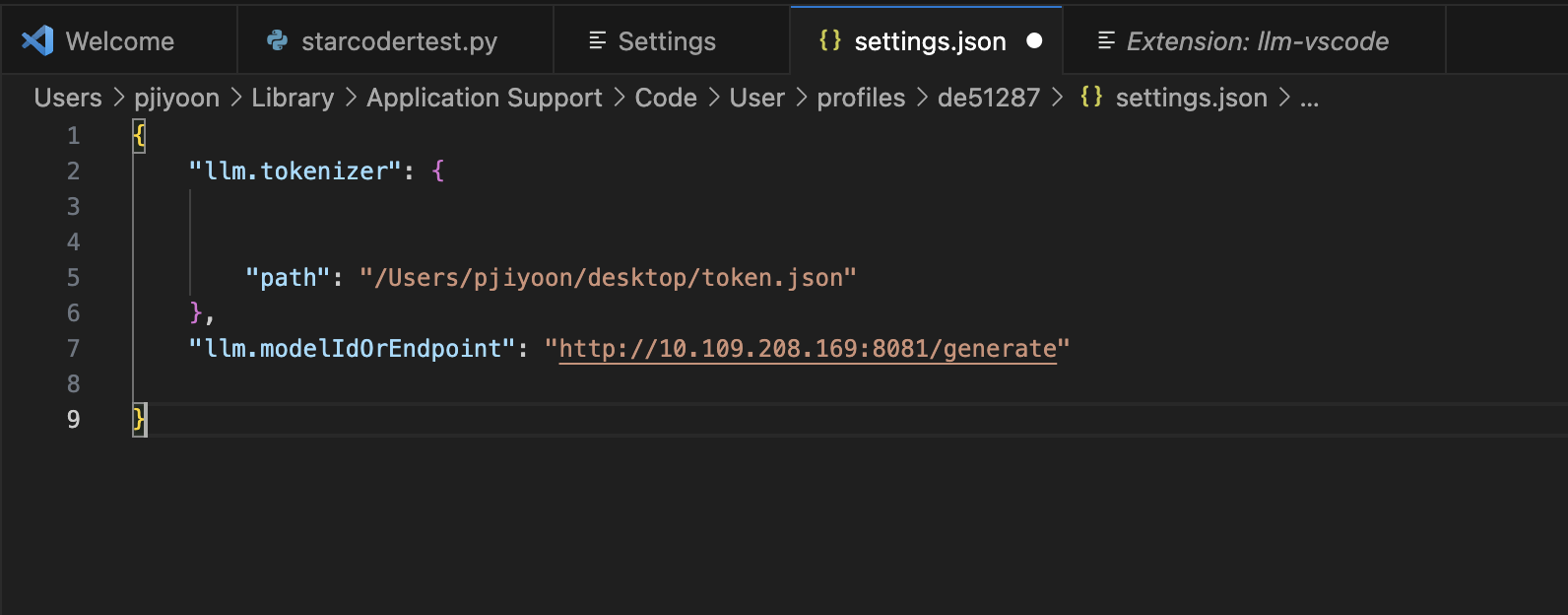
4. llm.tokenizer에 경로 입력
Huggingface의 token을 settings.json > "llm.tokenizer" 항목으로 아래와 같이 경로에 입력해줍니다.
Result; Code 추천받기
간단한 예시로 vsphere automation sdk python 코드를 추천받아 봤습니다.
"#" 뒤에 내가 원하는 작업을 영어로 입력하면 약간의 시간이 지나 starcoder가 아래에 코드를 추천해줍니다.
End of Labs
마치며..
내가 NVIDIA Solution Engineer인지 VMware Solution Engineer인지, Data Scientist인지 Kubernetes DevOps인지.. End-to-end로 공부해 본 아주 귀한 경험이었습니다.
한가지 아쉬운 점은 VMware Cloud Foundation위에 이 full stack을 빌드해보지 않은 것이 아쉽습니다. VMware Cloud Foundation은 Hybrid cloud의 모든 요소를 구축하는 통합 플랫폼인데 이번에 ESXi부터 Tanzu Kubernetes cluster, vSAN(Storage) 등 모든 component를 따로따로 설치하는 것을 보니, 어쩌면 VCF에 포함되어 있는 SDDC manager를 통해 한번에 설치하고 구성하는 것이 편리하겠다는 생각이 들었거든요.
특히나 best check point를 기록하고, 다음 배포에서 그 dependency를 가지고 모델을 배포해야하는 training 배포 같은 경우에도 VCF에 포함되어 있는 Aria Automation(인프라 자동화 배포 엔진) 의 workflow 기능을 이용해 수동 개입 없이 자동 배포되면 편하지 않을까 생각했습니다. 실제로 Data scientist들은 어떤 tool과 기능을 이용해 모델 조정에 따른 배포자동화를 하고 계신지 궁금해지기도 하는 등.. 아주 여러가지 방면에서 많~은 공부를 한 귀한 프로젝트였던건 아닌지!
다시 한번 이 많은 것들을 짧은 시간 안에 다 함께 배포해보고 테스트 해볼 기회를 준 동기님 박수 짝짝 드립니다.
End of docs

안녕하세요. 작성하신 포스팅 잘 보았습니다!
제가 현재 프로젝트 진행하면서 on-premise환경에 H100 GPU를 ESXi 8.0b에 vGPU MIG 방식으로 VM에 할당하여 운영하려고 테스트 중인데, GPU DLS 서버오 Client VM간에 오픈 해주어야 하는 포트가 443,80만 오픈 되어있으면 될까요?
예전에는 7070포트도 오픈을 했던 기억이 있어서 질문 드립니다.