데이터베이스와 ERD에 대해 공부했다.
데이터베이스는 데이터를 장기적으로 저장하고 보존하는 시스템으로, 정보를 잘 활용할 수 있기 위해서 만들어졌다.
관계형 DB와 비관계형 DB로 나뉜다.
관계형 DB (RDBMS, Relational DataBase Management System)
MySQL, Postgres, Oracle DB이 관계형 데이터베이스다.
정보들이 서로 상호 관련성을 가진 상태로 표현되고 저장된다.
이 DB에서 모든 데이터는 table로 표현되기 때문에, 각 테이블은 column과 row로 구성된다.
table 형식으로 모인 정보를 정규화해서 서로 관련있는 것끼리 분류해서 저장한 것이 바로 데이터베이스다.
column: 테이블의 각 항목
row: 각 항목들의 실제 값, 각 row는 숫자로 구성된 Primary key를 가진다.(꼭 인덱스를 부여받는 것 같다.) 이 PK를 통해 해당 로우를 찾거나 인용한다.
three rules
데이터베이스는 세 가지 규칙에 의해 구성된다.
- 1차 정규형: 원자값
column은 각 1개씩 원자값을 가진다.
이 원자값을 지키려면 중복되는 정보가 많아진다.
이런 중복 정보를 줄이기 위해 table을 나누고, 각 table에 연결되는 구간(정보)을 만들어서 서로 연결된 정보를 쉽게 찾을 수 있게 한다.
- 2차 정규형: 기본키(Primary Key)
모든 property는 PK에 종속된다.
만약 PK가 복합키(FK 2개 이상)로 구성되었을 때, 그 테이블에 하나라도 복합키에 의존하지 않는 row가이있으면, 이를 다른 테이블로 나누어야 한다.
(그러나 PK가 고유 키일 때는 나눌 필요가 없다.)
- 3차 정규형: 종속 불가
PK를 제외하고 서로 종속할 수 없다. 만약 PK를 제외하고 서로 종속되어 있으면, 다시 또 테이블을 쪼개서 정보를 분리해야 한다.
테이블을 나누고 연결하는 이유
- 중복된 데이터 혹은 잘못된 데이터를 저장하지 않기 위해
- 정보를 불러올 때 디스크를 더 효율적으로 사용하기 위해
table connection
테이블들은 Foreign Key로 연결한다.
- one to one
- one to many
- many to many
일대일 관계에서는 한 테이블의 row 1개와 다른 테이블의 row 1개가 매칭된다.
일대다 관계에서는 한 테이블의 row 1개와 다른 테이블의 row 여러 개가 매칭된다.
다대다 관계에서는 한 테이블의 row 여러 개와 다른 테이블의 row 여러 개가 매칭된다.
(다대다 관계에서는 중간 테이블을 만들어서, 나올 수 있는 조합을 모두 입력해둔다.)
주의!) one to one
일대일 관계에서는 꼭 필요한 경우가 아니라면 table을 나누지 않아도 됌. (통신낭비를 방지가 위해)
그러나 일대일 관계더라도 정보가 너무 많아지는 경우라면, 필수 정보와 부가 정보를 나눠서 저장하는 것이 통신을 더 아끼는 방법이다.
Transaction & ACID
(ACID: Atomicity 원자성, Consistency 일관성, isolation 고립성, Durability 지속성)
Transaction 트랜잭션
- Transaction은 일련의 작업들을 하나의 작업처럼 취급해서, 전부 성공하거나 전부 실패하는 것이다.
- ACID를 제공함으로서 트랜잭션 기능을 제공한다.
- 모든 트랜잭션은 로그로 남고, 시스템 장애가 발생하기 전으로 되돌릴 수 있다.
- 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
ACID
- Atomicity:
트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력.
예)
자금 이체의 경우, 돈을 빼오는 작업이 성공과 돈을 넣는 작업이 모두 실행되어야 한다.
따라서 원자성을 지켜서 중간 단계까지 실행되고 실패하는 일이 없도록 한다.
- Consistency:
트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 DB로 유지하는 것.
예) 무결성 제약에 '모든 계좌는 잔고가 있어야 함' 조항이 있다면, 이를 위반하는 트랜잭션은 중단된다.
- Isolation:
트랜잭션을 수행할 때, 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것.
고립성은 가장 유연성 있는 제약 조건이기 때문에, 관련 문서를 참조해서 꼼꼼히 읽어보자.
예)
은행 관리자가 이체 작업을 하는 도중, 쿼리를 실행하더라도 특정 계좌 간 이체하는 양 측을 볼 수 없다.
- Durability:
성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것.
시스템 문제나 DB 일관성 체크를 하더라도 성공적으로 수행된 트랜잭션은 계속 유지되어야 한다.
관계형(SQL) vs 비관계형(NoSQL)
SQL과 NoSQL은 모두 DataBase Manegement System이다.
SQL은 관계형이기 때문에 Relational DataBase Manegement System(RDBMS)이라고 한다.
NoSQL은 비관계형 타입의 데이터를 저장할 때 주로 사용되는 시스템으로 MongoDB, Redis, Cassandra 등이 있다.
관계형 DB는 데이터를 저장하기 전 어디에 어떻게 저장할 것인지(테이블)를 정의해야하는 반면,
비관계형 DB는 데이터를 저장하기 전에 정의할 필요가 없다.
보다 크게 관계형과 비관계형 DBMS의 장단점을 나누자면 다음과 같다.
SQL
특징:
- 정형화된 데이터 및 완전성이 중요한 데이터를 저장하는 데 유리하다. (예_ 전자상거래 정보, 은행계좌 정보, 거래 정보)
장점:
- 데이터를 더 효율적이고 체계적으로 저장, 관리할 수 있다.
- 저장할 테이터의 구조(table schema)를 정의함으로써 데이터의 완정성이 보장된다.
- 트랜잭션 기능.
단점:
- 테이블 구조 변화에 덜 유연하다.
- 확장이 쉽지 않다.
테이블 구조가 미리 정의되어 있기 때문에, 확장을 위해서는 서버 성능 scale up이 필요함. 서버 확장만으로는 분산 저장이 쉽지 않음.
NoSQL
특징:
- 비정형화된 데이터 및 완전성이 덜 중요한 데이터를 저장하는 데 유리하다. (예_ 로그 데이터)
장점:
- 데이터 구조를 미리 정의하지 않아도 된다.
- 데이터 구조 변화에 유연하다.
- 확장이 쉽다. (서버 확장만 필요)
- 방대한 양의 데이터 저장에 유리하다.
단점:
- 데이터 완전성이 덜 보장된다.
- 트랜잭션이 불안정하거나 불가하다.
ERD (Entity Relationship Diagram)
ERD는 개체-관계로 구조화된 데이터를 모델링해서 그 관계를 도출하는 산출물이다.
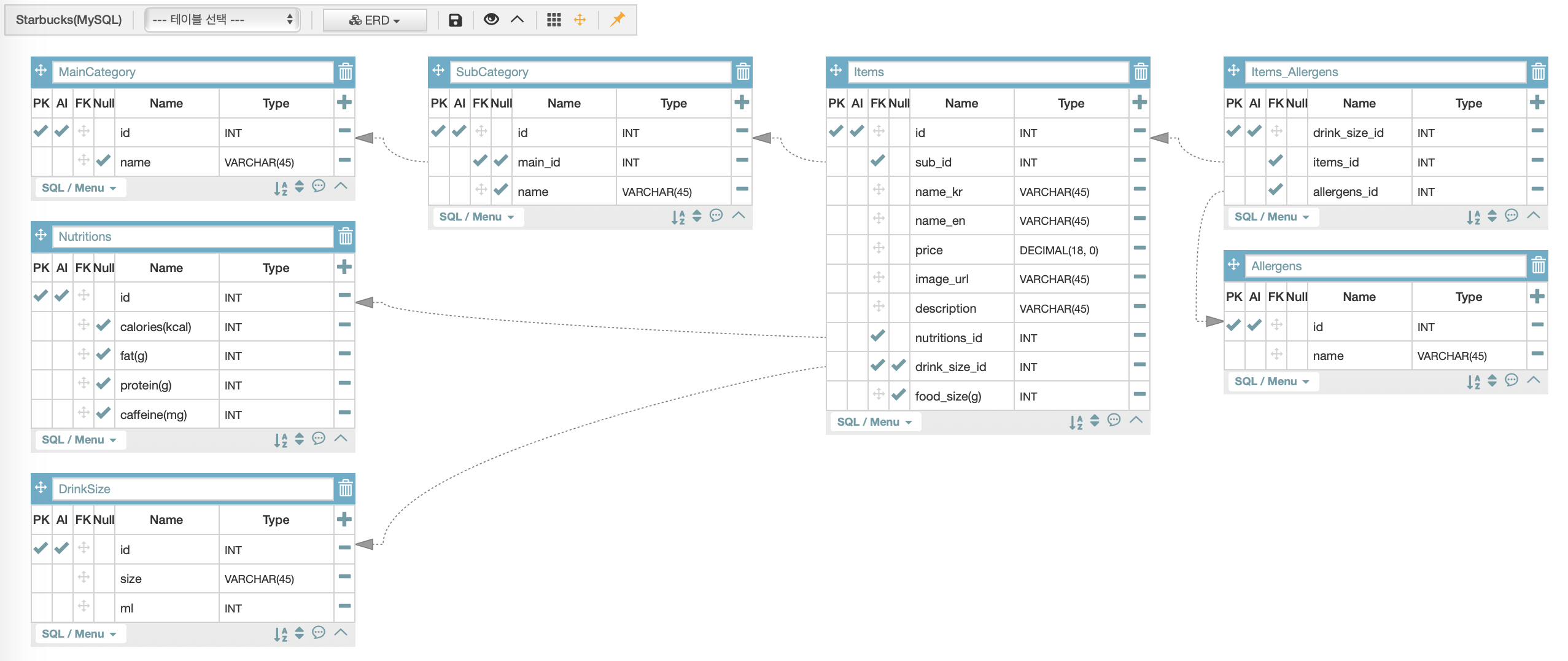
말이 조금 복잡한데, 아래 그림과 같이 정리한다.
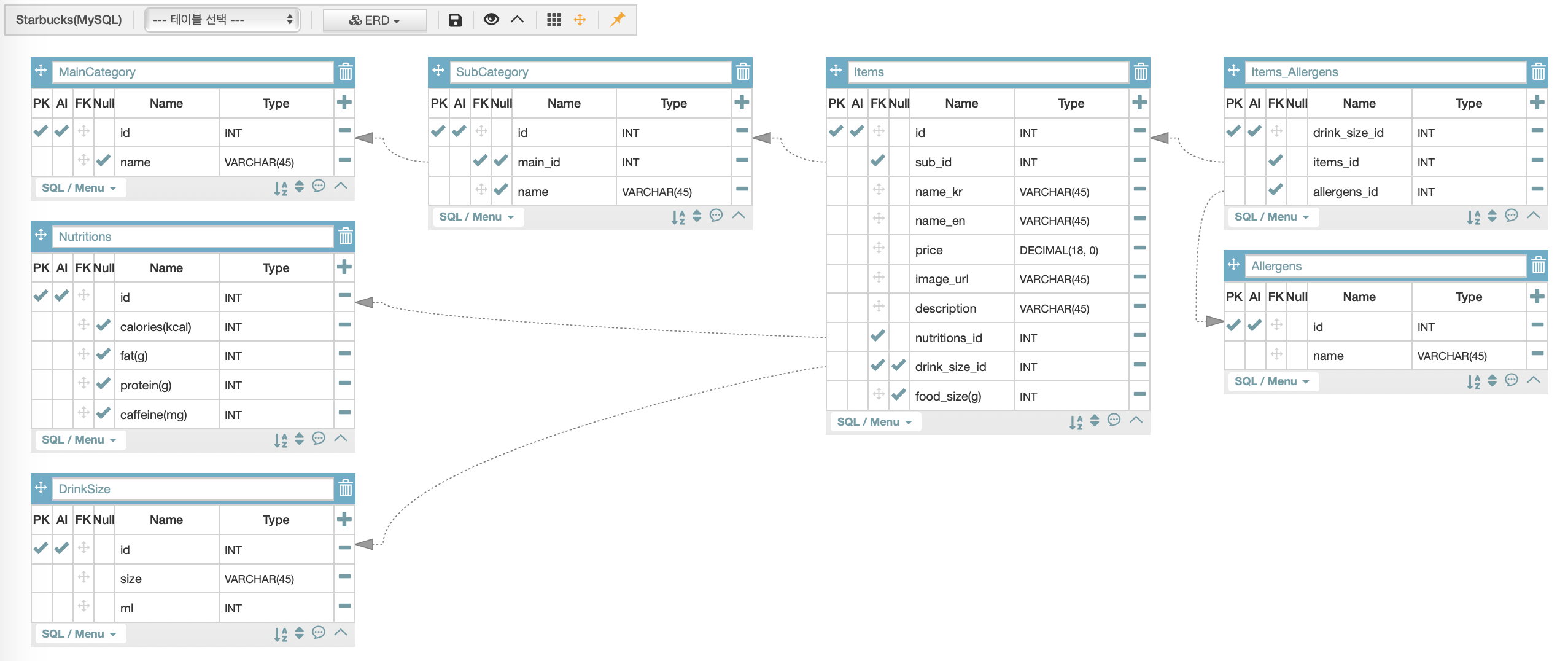
ERD 작성 특징
-
위 시트를 보면 '각 테이블은 고유의 id column에 PK'를 가진다.
-
다른 테이블과 연결될 때는
=>'연결을 원하는 (하위)테이블'에 FK를 가진 column을 생성하고,
이를 '연결을 받는 (상위)테이블의 id'에 연결한다. -
다른 테이블과 연결되지 않은 column의 경우 => name, age 식으로 간단하게 이름 붙여주면 되고,
연결된 column의 경우 => main_category_id(main_category가 상위테이블명, _id는 디비에서 자동 추가되기 때문에 모델링 때만 구분을 위해 추가해주는 것) 식으로 이름 붙여주면 된다. -
VARCHAR(n)는 variation과 character의 줄임말로, n은 글자수를 나타내며 table 작성자가 정할 수 있다.
(이미지 주소를 만들 때 column 이름을 'image_url'으로 하고 varchar(200)정도로 구성하는 경우가 많다.) -
TINYINT는 boolean을 나타내는 타입으로 보통 'is_이름이름' 식으로 앞에 is를 붙여준다.
-
주문 사이트의 경우, products의 rows만 별도로 추출할 일이 많이 생긴다. 그렇기 때문에 대부분의 경우 products 테이블은 따로 구성하는 것이 좋다.
-
테이블명은 보통 camelCase로 작성하며, 줄임말을 쓰지 않는다. (img 같은 줄임말을 쓰지 않고 image라고 모두 쓴다.)
-
중간 테이블의 영문명은 through table이다.
ERD 구성 tips
-
중심이 되는 product table을 먼저 만들고, 그것으로부터 (화살표 및 다른 테이블이 )쭉 뻗어나가는 것이 좋다.
-
중간 테이블에서 앞 뒤의 PK를 조합한 숫자를 중간테이블의 PK로 쓸 수도 있다. 그렇지만 이는 확인이 복잡하고 헷갈릴 여지가 많기 때문에, 중간테이블이더라도 그냥 고유의 ID PK를 주는 것이 편하다.
나는 이 DB tables를 생성하는 게 정말, 정말 재밌었다.
나는 어렸을 때부터 정리를 좋아해서
초등학생 때 교실의 서랍장을 보기 좋고 사용하기 편하게 항상 정리해 두었고,
집에서도 청소(청소기 밀기, 스팀하기 등)는 하지 않더라도 항상 물건들을 제 자리에 둔다.
(그렇게 해야 마음이 편안하고 기분이 좋다.)
공부할 때도 정보를 분류해서 따로 정리해두는 것을 좋아하고,
책장도 어떤 기준에 따라 나눠서 같은 분류끼리 두는 것을 좋아한다.
(이 기준은 다양하다. 지금까지는 '책 무게 -> 책 색상 -> 책 종류' 순으로 정리해왔다.)
그래서 그런지 ERD를 할 때도 어떤 기준을 두고 table을 어떻게 나누는 것이 좋은지에 대해 팀원들과 계속 대화하면서 그것을 눈으로 볼 수 있게 구축하는 것이 진짜 재밌었다.
게다가 이 ERD를 만드는 것은 위에서 설명한 규칙들을 지켜가면서 만들어야 하기 때문에, 무엇이 맞고 틀린지에 대해 계속 이야기를 나누고 실제 데이터를 넣었을 때 어떻게 구성되는 지에 대해 그려보는 게 많이 까다롭다. 그래서 더 흥미롭고 '어떻게든 정확하고 간지나는 ERD를 만들어서 사람들한테 자랑하고 싶다'는 마음이 생겼다.
