0. 들어가며
프로젝트를 진행하며 회원가입, 로그인 페이지를 맡았다.
회원가입과 로그인을 할 때 요건에 맞는 정보를 수집해야 하는데, 이 때 이메일이나 패스워드같은 복잡한 문자가 조건에 부합하는지에 대해 검사하는 기능이 필요하다.
정규표현식 패턴을 적용하면 이 기능을 빠르게 구현할 수 있다.
그래서 정규표현식을 바로 적용하려 해보니, 이것도 하나의 로직이라 대략적이고 정확한 이해가 수반되어야 제대로 활용할 수 있을 것으로 생각되었다.
그래서 생활코딩 강의를 통해 정규표현식을 공부하고, 해당 내용을 본 포스팅에 기록해두려고 한다.
목차
- 들어가며
- 정의
- 정규표현식 패턴
1) 기본 패턴
2) 위치와 이스케이핑
3) 모든 문자
4) 특정 문자
5) 서브 패턴
6) 수량자
7) 경계
8) 전방/후방 탐색- 정규표현식을 위한 도구
- 자바스크립트와 정규표현식
1) 패턴 만들기
2) RegExp 객체의 정규표현식
3) String 객체의 정규표현식
4) 옵션
5) 사례 1: 캡쳐
6) 사례 2: 치환- 참고자료
* 본 포스팅에서 정규표현식의 문법은 '문법'이라고 지칭하고, 일반 문자는 '소스문자'라고 지칭한다.
* 본 포스팅에서는 정규표현식을 위한 도구까지 작성하며, 자바스크립트와 정규표현식 및 참고자료는 다음 포스팅을 통해 기록한다.1. 정의
정규표현식(Regular Expression)
: 문자열을 처리하는 방법 중의 하나로 특정한 조건의 문자를 검색하거나 치환하는 과정을 매우 간편하게 처리 할 수 있도록 하는 수단이다.
2. 정규표현식 패턴
어떤 텍스트의 존재 여부를 알아내거나, 어떤 텍스트를 특정 언어로 변화하는 작업을 하기위해서는 내가 처리하고자 하는 문자를 정규표현식의 문법에 맞게 찾아낼 수 있어야 한다. 이번 장에서는 그 문법에 해당하는 패턴에 대해 알아보자.
1) 기본 패턴
- 정규표현식은 대소문자를 구분한다. 만약 대소문자를 구분하고 싶지 않은 경우, 정규표현식의 내용을 바꾸거나 정규표현식의 설정을 바꾸어 사용해야 한다.
- 정규표현식은 띄어쓰기 칸의 개수를 구분한다.
2) 위치와 이스케이핑
위치
찾고자 하는 문자열의 위치를 지정하는 방법을 살펴보자.
특수기호
^(Caret, 캐럿)
소스 상에서 시작에 위치한 대상을 지목할 때 사용된다.
특수기호
$(Dollar, 달러)
소스 상에서 마지막에 위치한 대상을 지목할 때 사용된다.
예제 )
Source:
who is who
Case 1:
Regular Expression: ^who
First match: 'who' is who
All matches: 'who' is who
Case 2:
Regular Expression: who$
First match: who is 'who'
All matches: who is 'who'즉 who 앞에 캐럿 ^ 이 붙으면 'who로 시작하는 텍스트'를 의미하고,
who 뒤에 달러 $ 가 붙으면 'who로 끝나는 텍스트'를 의미한다.
이제 캐럿과 달러 문자가 소스에 포함되어 있을 때, 어떻게 정규표현식이 작동하는지에 대해 알아보자.
이스케이프, escape
특수기호
\(Back slash, 역슬래시)
기호 뒤에 따라오는 문자를 정규표현식에서 의미가 있는 문법이 아닌 단순한 소스 문자로 인식하게끔 한다.
예제 )
Source:
$12$ \-\ $25$
Case 1:
Regular Expression: ^$
First match: $12$ \-\ $25$
All matches: $12$ \-\ $25$ (아무것도 매치되지 않음)
Case 2:
Regular Expression: \$ (escape로 인해 달러가 문법이 아닌 소스 문자로 인식됌)
First match: '$'12$ \-\ $25$
All matches: '$'12'$' \-\ '$'25'$'
Case 3:
Regular Expression: ^\$
First match: '$'12$ \-\ $25$
All matches: '$'12$ \-\ $25$
Case 4:
Regular Expression: \$$
First match: $12$ \-\ $25'$'
All matches: $12$ \-\ $25'$'
Case 5:
Regular Expression: \$$
First match: $12$ '\'-\ $25$
All matches: $12$ '\'-'\' $25$3) 모든 문자
특수기호
.(Point, 점)
모든 문자를 인식한다.
예제 1 )
Source:
Regular expressions are powerful!!!
Case 1:
Regular Expression: .
First match: 'R'egular expressions are powerful!!!
All matches: 'Regular expressions are powerful!!!'
Case 2:
Regular Expression: ...... (6개의 문자를 인식한다)
First match: 'Regula'r expressions are powerful!!!
All matches: 'Regula''r expr''ession''s are ''powerf'ul!!!' (6개씩 인식, 마지막 'ul!!!'은 5개라서 인식 불가)예제 2 )
Source:
O.K.
Case 1:
Regular Expression: .
First match: 'O'.K.
All matches: 'O.K.'
Case 2:
Regular Expression: \. (점을 문법이 아닌 소스문자로서 인식)
First match: O'.'K.
All matches: O'.'K'.'
Case 3:
Regular Expression: \..\. ('\.' '.' '\.' 이라서 두개의 점 사이에 어떤 문자가 오던 정규표현식이 인식)
First match: O'.K.'
All matches: O'.K.'4) 특정 문자
문자 후보군
원하는 문자의 후보군을 지정하는 방법에 대해 알아보자.
특수기호
[](Square brackets, 대괄호)
대괄호 내에 있는 문자 중 1개라도 소스문자에 있다면, 정규표현식이 그 소스문자를 인식한다.
대괄호와 대괄호 내의 문자 모두가 '한 개'의 문자로 취급된다는 점을 주의하자.
예제 )
Source:
How do you do?
Case 1:
Regular Expression: [oyu] (문자 1개)
First match: H'o'w do you do?
All matches: H'o'w d'o' 'you' d'o'?
Case 2:
Regular Expression: [dH]. (문자 2개)
First match: 'Ho'w do you do?
All matches: 'Ho'w 'do' you 'do'?
Case 3:
Regular Expression: [owy][yow]
First match: H'ow' do you do?
All matches: H'ow' do 'yo'u do?Range
특수기호
[-](Dash, 대시)
어디서부터 어디까지인지 range를 나타냄
예제 )
Source:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
Case 1:
Regular Expression: [C-K]
First match: AB'C'DEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
All matches: AB'CDEFGHIJK'LMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
Case 2:
Regular Expression: [CDEFGHIJK]
First match: AB'C'DEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
All matches: AB'CDEFGHIJK'LMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
Case 3:
Regular Expression: [a-d]
First match: ABCDEFGHIJKLMNOPQRSTUVWXYZ
'a'bcdefghijklmnopqrstuvwxyz 0123456789
All matches: ABCDEFGHIJKLMNOPQRSTUVWXYZ
'abcd'efghijklmnopqrstuvwxyz 0123456789
Case 4:
Regular Expression: [2-6]
First match: ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 01'2'3456789
All matches: ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 01'23456'789
Case 5:
Regular Expression: [C-Ka-d2-6]
First match: AB'C'DEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
All matches: AB'CDEFGHIJK'LMNOPQRSTUVWXYZ
'abcd'efghijklmnopqrstuvwxyz 01'23456'789Not이라는 의미에서의 ^
특수기호
[-]와^
대괄호 내에 캐럿을 시작으로 문자가 있다면, 그 문자를 제외한 나머지만 정규표현식이 인식한다.
예제 )
Source:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
Case 1:
Regular Expression: [^CDghi45]
First match: 'A'BCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
All matches: 'AB'CD'EFGHIJKLMNOPQRSTUVWXYZ'
'abcdef'ghi'jklmnopqrstuvwxyz 0123'45'6789'
Case 2:
Regular Expression: [^W-Z]
First match: 'A'BCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz 0123456789
All matches: 'ABCDEFGHIJKLMNOPQRSTUV'WXYZ
'abcdefghijklmnopqrstuvwxyz 0123456789'5) 서브 패턴
특수기호
()(Parentheses, 소괄호)와|(Vertical bar or Pipe 수직선)
소괄호 내에 수직선으로 나뉜 여러 문자가 있을 경우, 정규표현식은 각 문자를 인식한다.
예제 )
Source:
Monday Tuesday Friday
Case 1:
Regular Expression: (on|ues|rida)
First match: M'on'day Tuesday Friday
All matches: M'on'day T'ues'day F'rida'y
Case 2:
Regular Expression: (Mon|Tues|Fri)day
First match: 'Monday' Tuesday Friday
All matches: 'Monday' 'Tuesday' 'Friday'
Case 3:
Regular Expression: ..(id|esd|nd)ay
First match: 'Monday' Tuesday Friday
All matches: 'Monday' 'Tuesday' 'Friday'6) 수량자 (Quantifiers)
어떠한 패턴이 얼마나 등장하는가에 대한 수량을 인식하는 정규표현식이다.
*, +, ? 와 같은 기본수량자로는 수량의 범위를 지정할 수 있고,
{}와 같은 심화수량자로는 수량의 정확한 숫자까지 지정할 수 있다.
기본수량자와 알파벳
특수기호
*(Asterisk, 별표)
별표 앞의 문자가 0개부터 여러개까지 있을 수 있다.
특수기호
+(Plus sign, 더하기표)
더하기표 앞의 문자가 1개부터 여러개까지 있을 수 있다.
특수기호
?(Question mark, 물음표)
물음표 앞의 문자가 없거나 1개일 수 있다.
예제 )
Source:
aabc abc bc
Case 1:
Regular Expression: a*b
First match: 'aab'c abc bc
All matches: 'aab'c 'ab'c 'b'c
Case 2:
Regular Expression: a+b
First match: 'aab'c abc bc
All matches: 'aab'c 'ab'c bc
Case 3:
Regular Expression: a?b
First match: a'ab'c abc bc
All matches: a'ab'c 'ab'c 'b'c기본수량자와 특수기호
예제 1 ) *
Source:
-@- *** -- "*" -- *** -@-
Case 1:
Regular Expression: .* (모든텍스트라는 뜻이 된다)
First match: '-@- *** -- "*" -- *** -@-'
All matches: '-@- *** -- "*" -- *** -@-'
Case 2:
Regular Expression: -A*- (두 개의 대시 사이에 A가 0개부터 여러개일 수 있다는 뜻)
First match: -@- *** '--' "*" -- *** -@-
All matches: -@- *** '--' "*" '--' *** -@-
Case 3:
Regular Expression: [-@]* (- 혹은 @ 문자가 0개부터 여러개일 수 있다는 뜻)
First match: '-@-' *** -- "*" -- *** -@-
All matches: '-@-' *** '--' "*" '--' *** '-@-'예제 2 ) +
Source:
-@@@- * ** - - "*" -- * ** -@@@-
Case 1:
Regular Expression: \*+ (별표가 1개부터 여러개일 수 있다는 뜻)
First match: -@@@- '*' ** - - "*" -- * ** -@@@-
All matches: -@@@- '*' '**' - - "'*'" -- '*' '**' -@@@-
Case 2:
Regular Expression: -@+- (두 개의 대시 사이에 골뱅이가 1개부터 여러개일 수 있다는 뜻)
First match: '-@@@-' * ** - - "*" -- * ** -@@@-
All matches: '-@@@-' * ** - - "*" -- * ** '-@@@-'
Case 3:
Regular Expression: [^ ]+ (띄어쓰기를 부정하기 때문에, 띄어쓰기를 제외한 모든 문자를 1개 이상부터 인식)
First match: '-@@@-' * ** - - "*" -- * ** -@@@-
All matches: '-@@@-' '*' '**' '-' '-' '"*"' '--' '*' '**' '-@@@-'예제 3 ) ?
Source:
--XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@-
Case 1:
Regular Expression: -X?XX?X
First match: -'-XX'-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@-
All matches: -'-XX'-@'-XX'-@@'-XX'-@@@'-XX'-@@@@'-XX'-@@-@@-
Case 2:
Regular Expression: -@?@?@?-
First match: '--'XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@-
All matches: '--'XX'-@-'XX'-@@-'XX'-@@@-'XX-@@@@-XX'-@@-'@@-심화수량자와 알파벳
특수기호
{}(Curly brakets, 중괄호)
중괄호 앞의 소스문자를 중괄호 내의 숫자만큼 인식한다.
예제 )
Source:
One ring to bring them all and in the darkness bind them
Case 1:
Regular Expression: .{5} (어떤 문자든 5개를 인식)
First match: 'One r'ing to bring them all and in the darkness bind them
All matches: 'One r''ing t'o bri''ng th''em al''l and'' in t''he da''rknes''s bin''d the'm
Case 2:
Regular Expression: [els]{1,3} (e 혹은 l 혹은 s가 1개부터 3개까지 있을 때 인식)
First match: On'e' ring to bring them all and in the darkness bind them
All matches: On'e' ring to bring th'e'm a'll' and in th'e' darkn'ess' bind th'e'm
Case 3:
Regular Expression: [a-z]{3,} (a부터 z까지 3개 이상일 때 인식)
First match: One 'ring' to bring them all and in the darkness bind them
All matches: One 'ring' to 'bring' 'them' 'all' 'and' in 'the' 'darkness' 'bind' 'them'기본수량자와 심화수량자
심화수량자 {}를 사용하면, 기본수량자에서 *, +, ?로 구분되었던 기능을 간편히 구현할 수 있다.
예제 )
Source:
AA ABA ABBA ABBBA
Case 1:
Regular Expression: AB*A (두 개의 A 사이에 B가 0개부터 여러개 있을 수 있다는 뜻)
First match: 'AA' ABA ABBA ABBBA
All matches: 'AA' 'ABA' 'ABBA' 'ABBBA'
Case 2:
Regular Expression: AB{0,}A (두 개의 A 사이에 B가 0개부터 여러개 있을 수 있다는 뜻, 즉 AB*A와 같은 뜻)
First match: 'AA' ABA ABBA ABBBA
All matches: 'AA' 'ABA' 'ABBA' 'ABBBA'
Case 3:
Regular Expression: AB+A (두 개의 A 사이에 B가 1개부터 여러개 있을 수 있다는 뜻)
First match: AA 'ABA' ABBA ABBBA
All matches: AA 'ABA' 'ABBA' 'ABBBA'
Case 4:
Regular Expression: AB{1,}A (AB+A와 같은 뜻)
First match: AA 'ABA' ABBA ABBBA
All matches: AA 'ABA' 'ABBA' 'ABBBA'
Case 5:
Regular Expression: AB?A (두 개의 A 사이에 B가 0개이거나 1개일 수 있다는 뜻)
First match: 'AA' ABA ABBA ABBBA
All matches: 'AA' 'ABA' ABBA ABBBA
Case 6:
Regular Expression: AB{0,1}A (AB?A와 같은 뜻)
First match: 'AA' ABA ABBA ABBBA
All matches: 'AA' 'ABA' ABBA ABBBA복합수량자
특수기호
*와?
*이 가진 범위 중 가장 작은 숫자를 인식하게 된다.
예제 )
Source:
One ring to bring them all and in the darkness bind them
Case 1:
Regular Expression: r.* (r로 시작하는 문자 뒤에 어떤 문자던 0개부터 여러개가 올 수 있다는 뜻)
First match: One 'ring to bring them all and in the darkness bind them'
All matches: One 'ring to bring them all and in the darkness bind them'
Case 2:
Regular Expression: r.*? (물음표로 인해 별표의 범위중 가장 작은 수량 0을 인식, 즉 r만 인식하게 됨)
First match: One 'r'ing to bring them all and in the darkness bind them
All matches: One 'r'ing to b'r'ing them all and in the da'r'kness bind them
Case 3:
Regular Expression: r.+ (r로 시작하는 문자 뒤에 어떤 문자던 1개부터 여러개가 올 수 있다는 뜻)
First match: One 'ring to bring them all and in the darkness bind them'
All matches: One 'ring to bring them all and in the darkness bind them'
Case 4:
Regular Expression: r.+? (물음표로 인해 더하기표의 범위중 가장 작은 수량 1을 인식, 즉 r과 어떤 문자 1개만 인식하게 됨)
First match: One 'ri'ng to bring them all and in the darkness bind them
All matches: One 'ri'ng to b'ri'ng them all and in the da'rk'ness bind them
Case 5:
Regular Expression: r.? (r로 시작하는 문자 뒤에 어떤 문자던 0개 혹은 1개가 올 수 있다는 뜻)
First match: One 'ri'ng to bring them all and in the darkness bind them
All matches: One 'ri'ng to b'ri'ng them all and in the da'rk'ness bind them
Case 6:
Regular Expression: r.?? (물음표로 인해 물음표의 범위중 가장 작은 수량 0을 인식, 즉 r만 인식하게 됨)
First match: One 'r'ing to bring them all and in the darkness bind them
All matches: One 'r'ing to b'r'ing them all and in the da'r'kness bind them수량자의 활용
Greedy Quantifiers (탐욕적인 수량자)
Lazy Quantifiers (게으른 수량자)
https://regexr.com/ 사이트를 통해 정규표현식을 테스트 해보았다.
아래와 같이 div 태그 사이에 .+을 입력하면 탐욕적인 수량자로서 기능하기 때문에 중간에 있는 </div><div>도 소스문자로서 인식된다.

반면 아래와 같이 div 태그 사이에 .+?을 입력하면 게으른 수량자로서 기능하기 때문에 중간에 있는 </div>에서 정규표현식 인식이 멈추게 된다.

7) 경계
Character Class (문자 그룹): [A-z0-9_] (alphanumeric plus "_")
\w
\w
문자 그룹과 동일하게 인식한다.
예제 )
Source:
A1 B2 c3 d_4 e:5 ffGG77--__--
Case 1:
Regular Expression: \w ([A-z0-9_] 범위 내의 문자를 모두 인식)
First match: 'A1' B2 c3 d_4 e:5 ffGG77--__--
All matches: 'A1' 'B2' 'c3' 'd_4' 'e':'5' 'ffGG77'--'__'--
Case 2:
Regular Expression: \w* (\w와 동일하게 인식)
First match: 'A1' B2 c3 d_4 e:5 ffGG77--__--
All matches: 'A1' 'B2' 'c3' 'd_4' 'e':'5' 'ffGG77'--'__'--
Case 3:
Regular Expression: [a-z]\w* (a부터 z 사이의 문자로 시작하고, [A-z0-9_] 범위 내의 문자가 0개 이상일 때를 인식)
First match: A1 B2 'c3' d_4 e:5 ffGG77--__--
All matches: A1 B2 'c3' 'd_4' 'e':5 'ffGG77'--__--
Case 4:
Regular Expression: \w{5} ([A-z0-9_] 범위 내의 문자를 5개 단위로 인식)
First match: A1 B2 c3 d_4 e:5 'ffGG7'7--__--
All matches: A1 B2 c3 d_4 e:5 'ffGG7'7--__--
Case 5:
Regular Expression: [A-z0-9_] (\w와 동일하게 인식)
First match: 'A1' B2 c3 d_4 e:5 ffGG77--__--
All matches: 'A1' 'B2' 'c3' 'd_4' 'e':'5' 'ffGG77'--'__'--\W
\W
\w와 정반대의 의미를 갖는다. (= not word)
예제 )
Source:
AS _34:AS11.23 @#$ %12^*
Case 1:
Regular Expression: \W ([A-z0-9_]에 포함되지 않는 모든 문자를 인식)
First match: AS' '_34:AS11.23 @#$ %12^*
All matches: AS' '_34':'AS11'.'23' @#$ %'12'^*'
Case 2:
Regular Expression: \w
First match: 'A'S _34:AS11.23 @#$ %12^*
All matches: 'AS' '_34':'AS11'.'23' @#$ %'12'^*
Case 3:
Regular Expression: [^A-z0-9_] (캐럿 ^ 으로 인해 \W와 동일하게 인식)
First match: AS' '_34:AS11.23 @#$ %12^*
All matches: AS' '_34':'AS11'.'23' @#$ %'12'^*'\s \S
\s
공백만을 인식한다.
\S
\s와 반대되기 때문에 공백이 아닌 모든 것을 인식한다.
예제 )
(zvon.org의 캡쳐사진 대체)

\d \D
digit의 약자이다.
\d
숫자만을 인식한다. [0-9]와 동일하다.
\D
\d와 반대되기 때문에 숫자가 아닌 모든 것을 인식한다.
예제 )
(zvon.org의 캡쳐사진 대체)

\b
word boundary의 약자이다.
\b
\w와 \W 사이의 문자를 찾아낸다.
\b. == \b\w
.\b == \w\b
\b\w\b == 단어가 1개 character일 때 인식
\b\w+\b == 모든 단어를 인식
예제 1 )
(zvon.org의 캡쳐사진 대체)
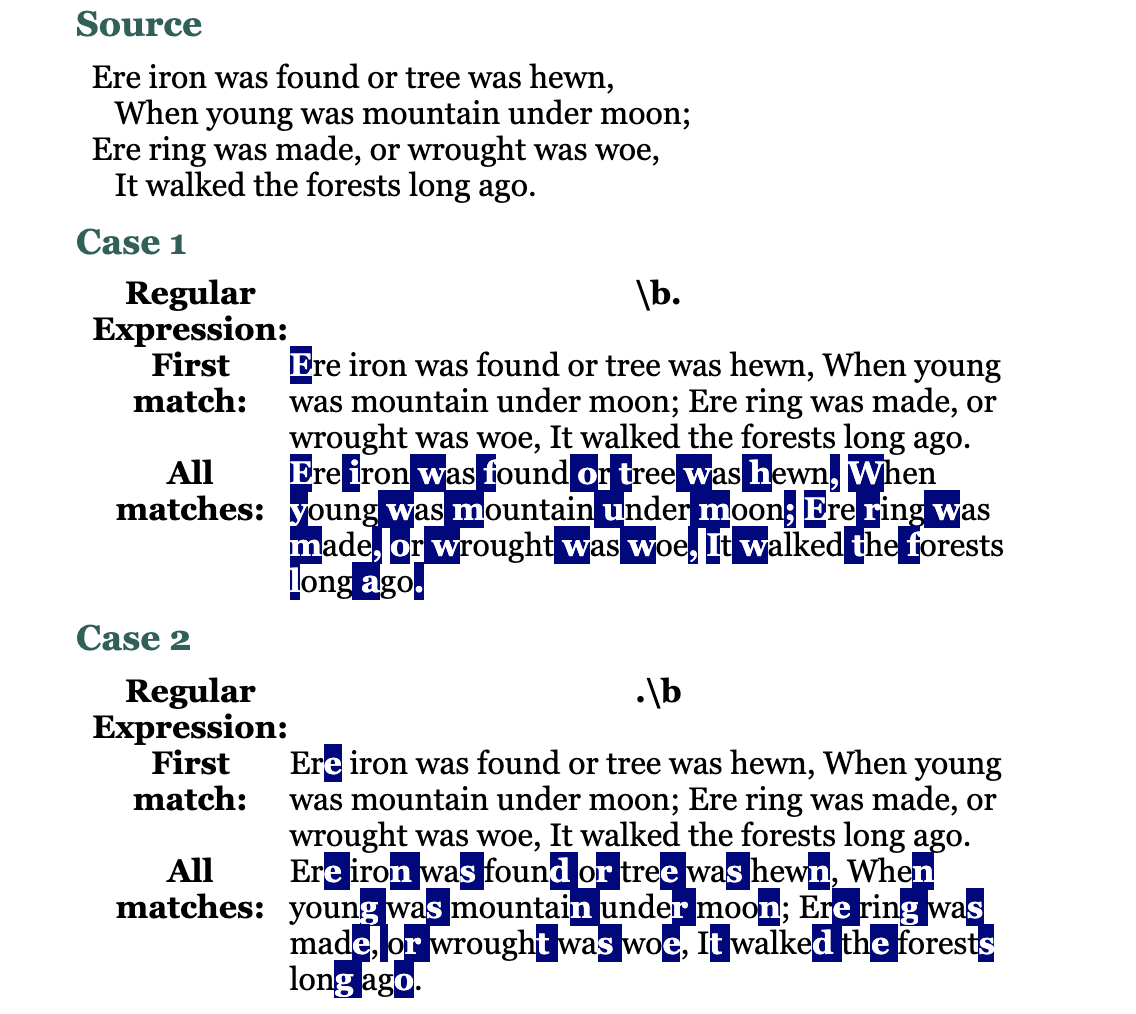
예제 2 )
Source:
cat concat
\cat
=> 'cat' con'cat'
\bcat
=> 'cat' concat
cat\b
=> 'cat' con'cat'
\b.
=> 'c'at' ''c'oncat\B
\B
\b와 정반대의 의미를 갖는다. (바운더리에 있지 않는 문자만 인식)
예제 1 )
(zvon.org의 캡쳐사진 대체)

예제 2 )



\A \Z
행에서 가장 앞쪽과 뒤쪽의 바운더리를 지정하는 패턴에 대해 알아보자.
\A는^과 비슷하다.
다만 multiline일 때\A는 가장 첫번째 단어만 인식하는 반면,^는 모든 문장의 첫번째 단어를 인식한다.
\Z는$와 비슷하다.
다만 multiline일 때\Z는 가장 마지막 단어만 인식하는 반면,$는 모든 문장의 마지막 단어를 인식한다.
예제 )
(zvon.org의 캡쳐사진 대체)

8) 전방/후방 탐색
(?=<pattern>)
(?=<pattern>)
어떤 문자가 나오기 전까지를 인식한다.
예제 1 )
(zvon.org의 캡쳐사진 대체)

3. 정규표현식을 위한 도구
-
regexr
http://www.regexr.com/
정규 표현식에 대한 도움말과 각종 사례들을 보여주는 서비스로 정규표현식을 라이브로 만들 수 있는 기능도 제공하고 있다. -
regexper
http://www.regexper.com/
정규 표현식을 시각화해서 보여주는 도구 -
regexone
http://regexone.com/
인터렉티브하게 정규 표현식을 공부 할 수 있는 사이트
