일단 범위는 현재 연재중인 웹툰 한정으로 정했다.
내가 스크래핑 할 정보는
1. 웹툰명
2. 작가명
3. 각 웹툰별 썸네일 이미지 주소
이렇게 세가지였다.
이에 가장 적절한 페이지는 연도별 웹툰 탭의 2021년도 웹툰이었다
- 스크래핑 해 올 링크: https://comic.naver.com/webtoon/period.nhn
- 크롤링 할 데이터 : 웹툰 제목 / 작가명 / 웹툰별 썸네일 이미지
- 사용한 라이브러리: 파이썬 flask, bs4, pyMongo
- DB : MongoDB
그럼 크롤링 할 라이브러리를 설치해보자
먼저 나는 pycharm을 사용하였다. MongoDB 설치를 완료했다는 전제 하에 설명할 것이므로 설치하고 따라가도록 하자.
프로젝트 생성 후
File -> setting -> python Interpreter -
-> flask, pymongo, bs4 라이브러리를 설치해주자.
import requests
from bs4 import BeautifulSoup
import re
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta_plus_week4
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://comic.naver.com/webtoon/period.nhn?period=2021&view=image', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')그럼 이렇게 초기 import를 해야할 것이다. 경로를 local로 설정한 뒤 db 주소를 client. 저장할 폴더명 으로 변경하면 된다. 헤더에는 파싱에 필요한 코드가 기재되고
data = request.get('https://comic.naver.com/webtoon/period.nhn?period=2021&view=image', headers=headers)이 부분에 우리가 필요한 웹사이트의 링크를 넣어주었다.
최종적으로 완성된 코드이다.
import requests
from bs4 import BeautifulSoup
import re
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta_plus_week4
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://comic.naver.com/webtoon/period.nhn?period=2021&view=image', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#content > div.list_area.daily_img > ul > li')
for tr in trs:
a_tag = tr.select_one('dl > dt > a ')
b_tag = tr.select_one('dl > dd.desc')
c_tag = tr.select_one(' a > img')
if a_tag is not None:
if b_tag is not None:
if c_tag is not None:
title = a_tag.text
title = title.replace("전체보기", "")
title = title.replace("평점", "")
author = b_tag.text
img = c_tag["src"]
doc = {'title': title,
'author': author,
'img': img
}
db.webtoon.insert_one(doc)
print(title,author,img)`
코드 설명
1. trs
변수 전체 카드 중
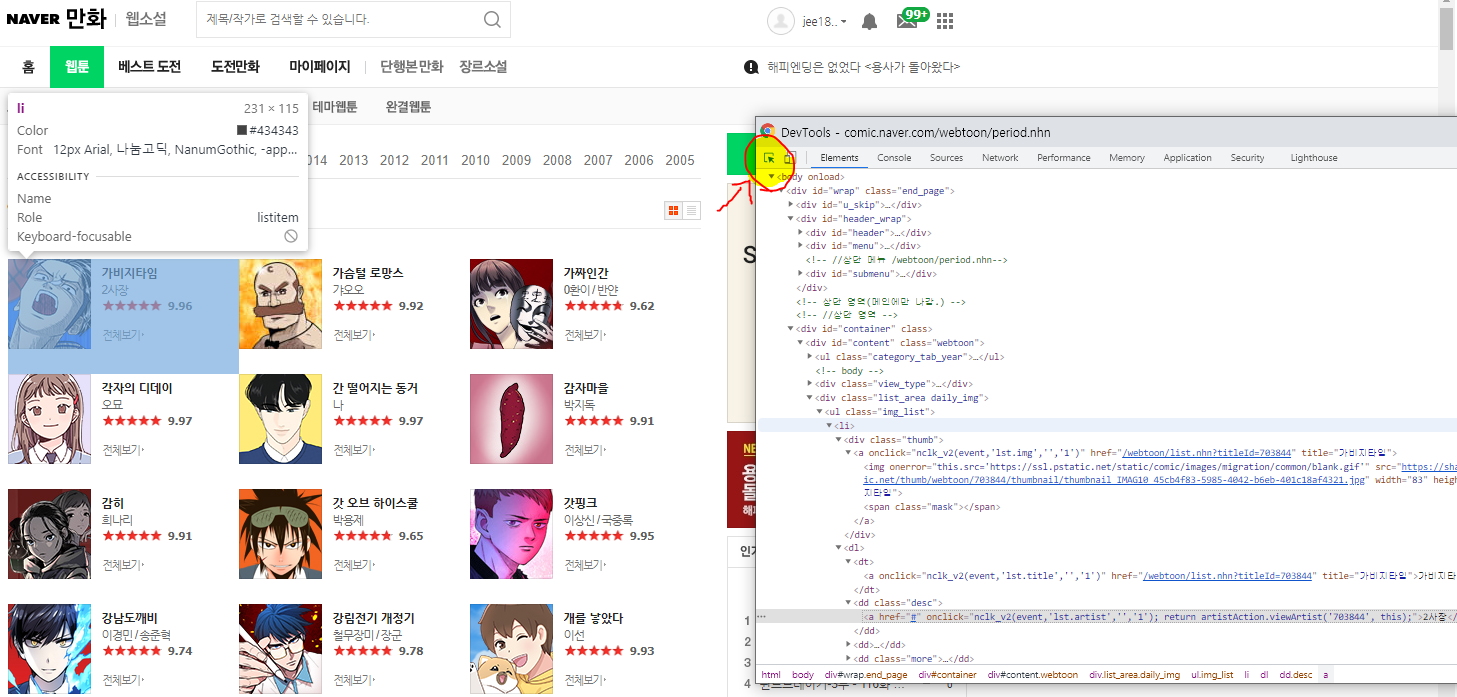
해당 영역에 해당하는 코드의 검사창 왼쪽 상단 화살표 를 클릭 후
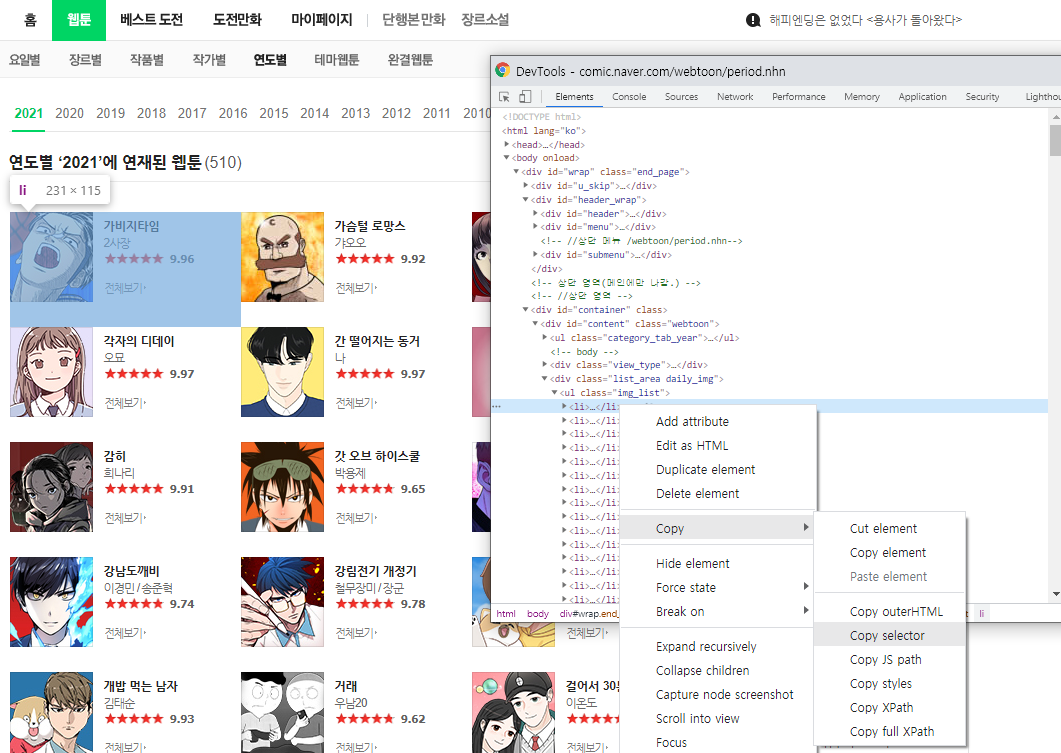
오른쪽 마우스 → copy → copy selector 을 한 다음
코드에 붙여넣기를 해주면
#content > div.list_area.daily_img > ul > li:nth-child(1)
이렇게 나올 것이다. 여기서 변동되는 정보인
nth-child(1) 전으로
#content > div.list_area.daily_img > ul > li 영역만
trs 변수 안에 넣어준다.
마찬가지의 방법으로
1. 제목
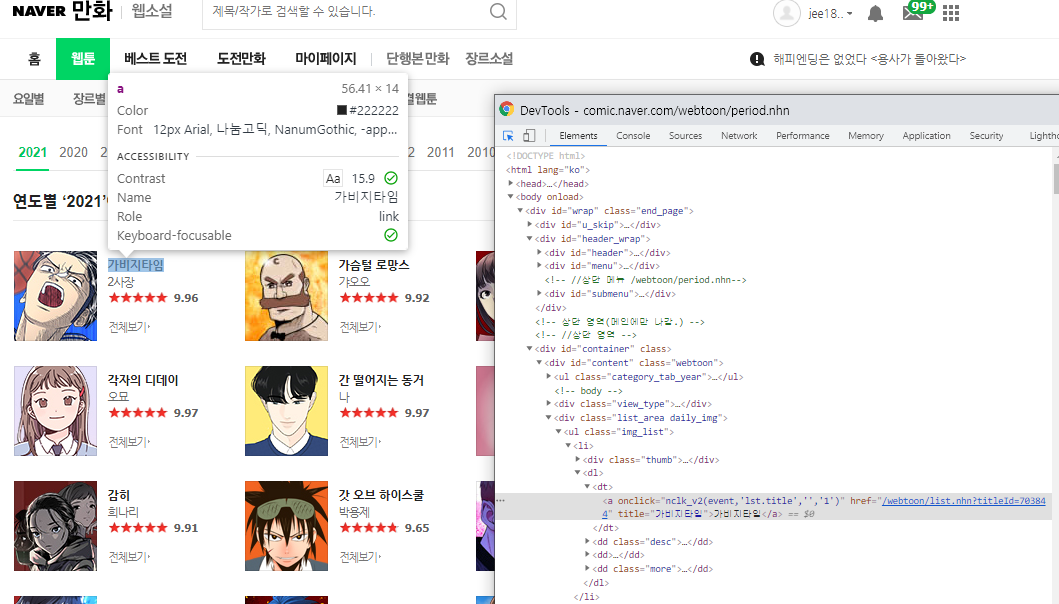
2. 작가명
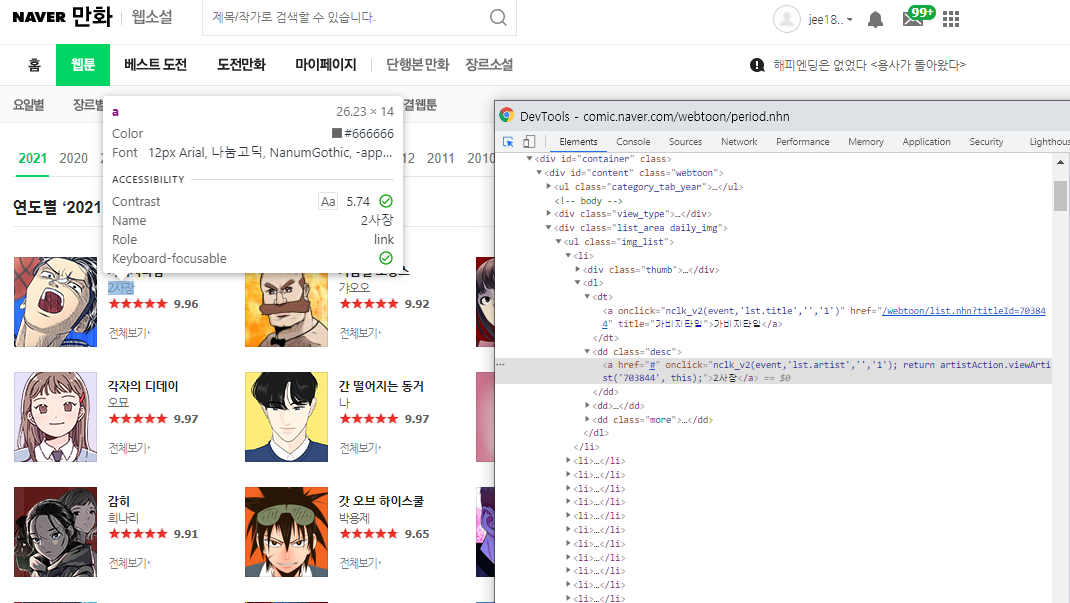
3. 썸네일 이미지
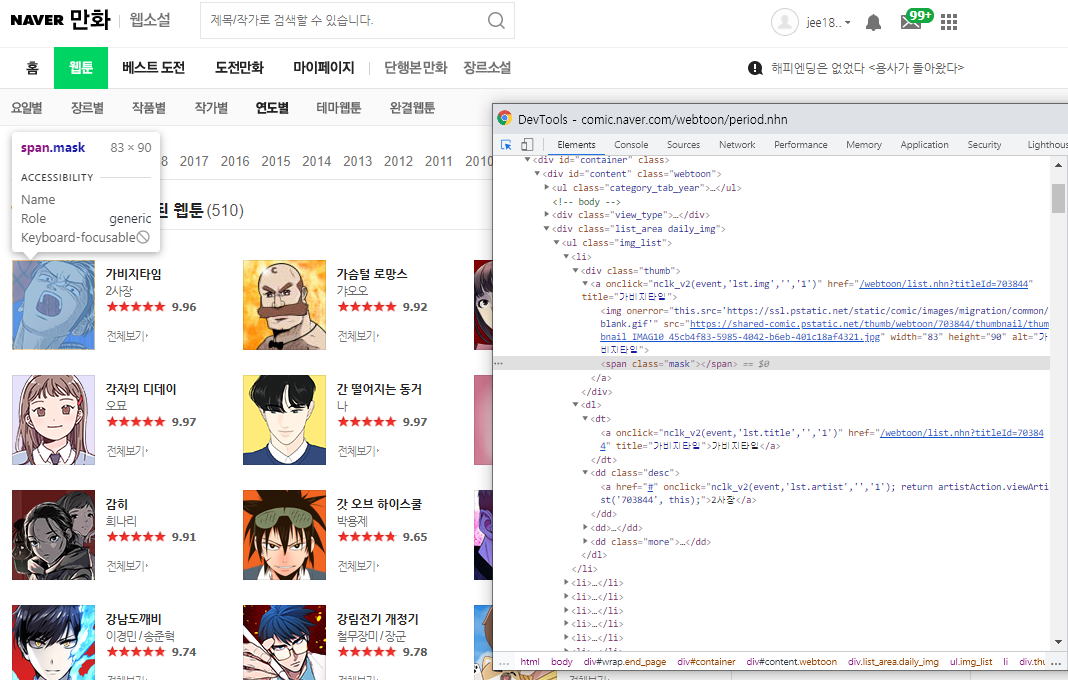
까지 각각 같은 방법으로 copy selecetor+ 붙여넣기 한 다음
에서 앞에서 기재한
#content > div.list_area.daily_img > ul > li
의 뒷부분인 각각
1. dl > dt > a
2. dl > dd.desc
3. a > img
을 각 tag 변수에 대입한다.
※ 공백 등의 경우로 None이 포함되어 있을 경우 실행 시 에러가 발생하므로 세가지 변수 모두 None 이 아닐 때의 if문을 추가해 주었다.
if a_tag is not None:
if b_tag is not None:
if c_tag is not None:※ 제목의 'title' 변수, 작가명의 'author' 의 경우
해당 url 에서

이렇게 되어있어 url속에서 찾고자하는 정보에 해당하는 text 형식만 추출해야하므로
title = a_tag.text
author = b_tag.text이렇게 처리해주었다.
※ '전체보기', '평점' 의 경우 제거 해야 하므로
title.replace("전체보기", "")
title = title.replace("평점", "")```으로 replace 를 사용하여 공백으로 처리하였다.
※ 이미지 주소의 경우

해당 html url 에서 앞부분 gif 주소를 제외하고 우리가 필요한 이미지는 .jpg 이미지이므로 'src' 영역만 따로 추출해주어야 한다.
따라서 img = c_tag["src"] 이렇게 src영역만 추출해주었다.
다 되었으면
doc = {'title': title,
'author': author,
'img': img
}
db.webtoon.insert_one(doc)
이렇게 DB에 컬렉션 명을 지정하여 삽입하여 주면 끝이다.
마치며
다음에는 selenium을 이용하여 동적 페이지에서의 스크래핑을 시도해보도록 해야겠다.
