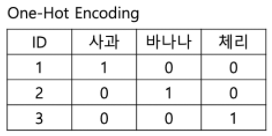
One-hot encoding이란
학습 시킬 때는 모든 데이터를 숫자로 넣어줘야 한다.
명목형 데이터의 경우엔 어떻게 처리해야할까?
예를 들자면 지역의 경우
- 0: 오렌지, 1: 사과, 2: 바나나
3가지의 과일이 해당타입의 숫자로 배열되어있다.
Ex) [0, 1, 2, 2, 2, 1, 1, 0]
기계학습이나 딥러닝의 학습과정에서 0,1,2의 데이터가 들어간다면 서로 상관이 없지만 숫자로 표현 되어 있기 때문에 영향을 미칠 수 있다.
1 + 1 = 2 라는 수식이
사과 + 사과 = 바나나
라는 결과를 초래할 수 있기 때문
때문에 이를 방지하기 위해 별도에 3개의 column을 만들고 해당 타입의 columns에만 1 나머지 column에는 0 을 대입해주는 pre-processing을 거쳐야 하고, 이것을 one-hot encoding 이라 한다.
즉, 아래와 같이 바뀐다.

One-hot encoding 방법
1. TensorFlow
to_categorical()
# import module
from tensorflow.keras.utils import to_categorical# label = 5
label_onehot = to_categorical(label, num_classes = 10) # class의 수를 알아야 사용가능
label_onehot> array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)2. pandas
pd.get_dummies()
# import module
import pandas as pd
# 예시 데이터 생성
data = {
'과일' : ['오렌지', '사과', '바나나', '바나나', '바나나', '사과', '사과', '오렌지']
}
# DataFrame변환
df = pd.DataFrame(data)
df
pd.get_dummies(df)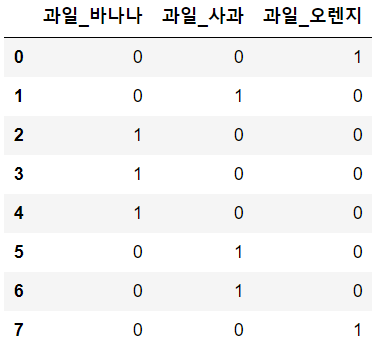
하나의 df로 보자면
pd.concat([pd.DataFrame(df), pd.get_dummies(df['과일'])], axis=1)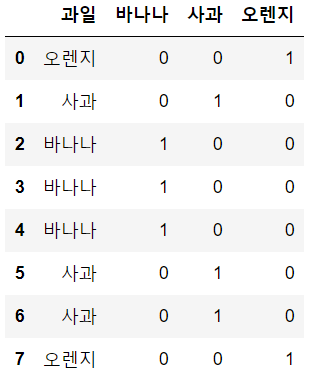

살어리 살어리랏다 청산에 살어리랏다.