
Puppeteer를 Lambda에서 돌려보자!
5 시간 동안 삽질해가면서 얻어낸 결과를 정리해보려고 한다.
이제 Lambda를 약간이나마 사용할 줄도 알고 Puppeteer도 해봤으니 Lambda에서 Puppeteer를 돌리는거야 쉽쉽이지~ 하면서 도전을 했지만..

어림도 없었다. Runtime Syntex Error부터 크롬이 4시간 째 켜지지 않고.. 정말 2020년 최고의 다이나믹 한 삽질같다.
이 글은 AWS의 Lambda와 Puppeteer, Serverless 프레임워크를 사용한다! 다만 깊은 내용은 다루지 않으므로 사용해 본 적이 없다면
Puppeteer
Serverless
먼저 읽어보자
헤 복잡한거는 귀찮아
처음에는 이 글(How to use Puppeteer in a Netlify (AWS Lambda) function)을 찾았었으나.. Netlify? 그게 뭔데요. 저는 넷플릭스밖에 몰라요ㅎ

Netlity는 GitHub, GitLab 등과 계정 연동 및 쉬운 호스팅을 제공하며,
CDN, Continuous Deployment(지속적 배포), One-Click HTTPS 제공 등 고성능 사이트 / 웹 응용 프로그램을 제작하는데 필요한 쉽고 빠른 다양한 서비스들을 제공합니다.
뭐 그렇다고 한다ㅎ 손쉽게 정적 웹사이트를 배포할 수 있도록 해준다는뎅.. 나는 아직 해본 적이 없으니! 저 글은 열어만 두고 해보지는 않았었다.
@serverless-chrome/lambda
필요한 serverless, chrome, lambda가 다 들어가있는 패키지가 있다고..? 이걸 쓰면 한번에 되겠지ㅎ
하는 마음으로 Serverless Chrome on AWS Lambda, the guide that works in 2019 and beyond를 따라했었다.
그런데 ㅎ 정말 구글링하고 온갖 이슈의 해결법을 찾다가 해결이 안되었는데 아래와 같은 이슈들을 발견했다.
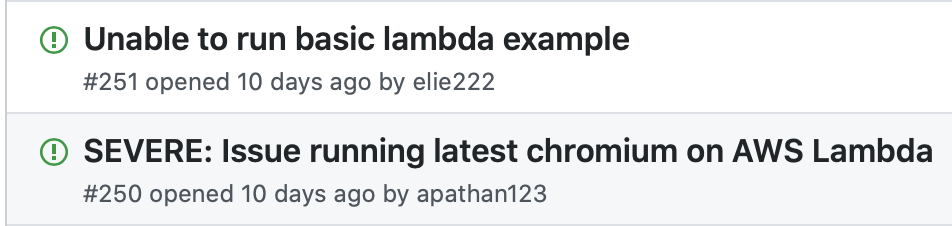
나 같은 경우에는
{
"errorType": "Error",
"errorMessage": "Unable to start Chrome. If you have the DEBUG env variable set,there will be more in the logs.",
"trace": [
"Error: Unable to start Chrome. If you have the DEBUG env variable set,there will be more in the logs.",
" at /var/task/node_modules/@serverless-chrome/lambda/dist/bundle.cjs.js:456:13",
" at Generator.throw (<anonymous>)",
" at step (/var/task/node_modules/@serverless-chrome/lambda/dist/bundle.cjs.js:370:30)",
" at /var/task/node_modules/@serverless-chrome/lambda/dist/bundle.cjs.js:382:13",
" at process._tickCallback (internal/process/next_tick.js:68:7)"
]
}라는 오류가 떴다.. 좀 더 자세히 살펴보면
2020-02-13T15:57:32.458Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO @serverless-chrome/lambda: Launcher Chrome running with pid 24 on port 9222.
2020-02-13T15:57:32.458Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO @serverless-chrome/lambda: Waiting for Chrome 0
...
2020-02-13T15:57:32.961Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO
@serverless-chrome/lambda: Waiting for Chrome 10
2020-02-13T15:57:37.475Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO @serverless-chrome/lambda: Error trying to spawn chrome: { Error: connect ECONNREFUSED 127.0.0.1:9222
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1107:14)
errno: 'ECONNREFUSED',
code: 'ECONNREFUSED',
syscall: 'connect',
address: '127.0.0.1',
port: 9222 }
2020-02-13T15:57:37.476Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO @serverless-chrome/lambda: stdout log:
2020-02-13T15:57:37.476Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 INFO @serverless-chrome/lambda: stderr log: /var/task/node_modules/@serverless-chrome/lambda/dist/headless-chromium: error while loading shared libraries: libnss3.so: cannot open shared object file: No such file or directory
2020-02-13T15:57:37.476Z 1d60f638-cd43-49b5-92eb-c8a0d617fec3 ERROR Error occured in serverless-plugin-chrome wrapper when trying to ensure Chrome for handler() handler. { flags:
[ '--window-size=1280,1696',
'--hide-scrollbars',
'--ignore-certificate-errors' ] } Error: Unable to start Chrome. If you have the DEBUG env variable set,there will be more in the logs.대략 이런 오류였다ㅠ
그러던 중 다음 이슈(Should we need to update the supported version from node8.10 to node.10x)를 발견했다.
AWS는 이제 Node8.x를 지원 안하는데..?
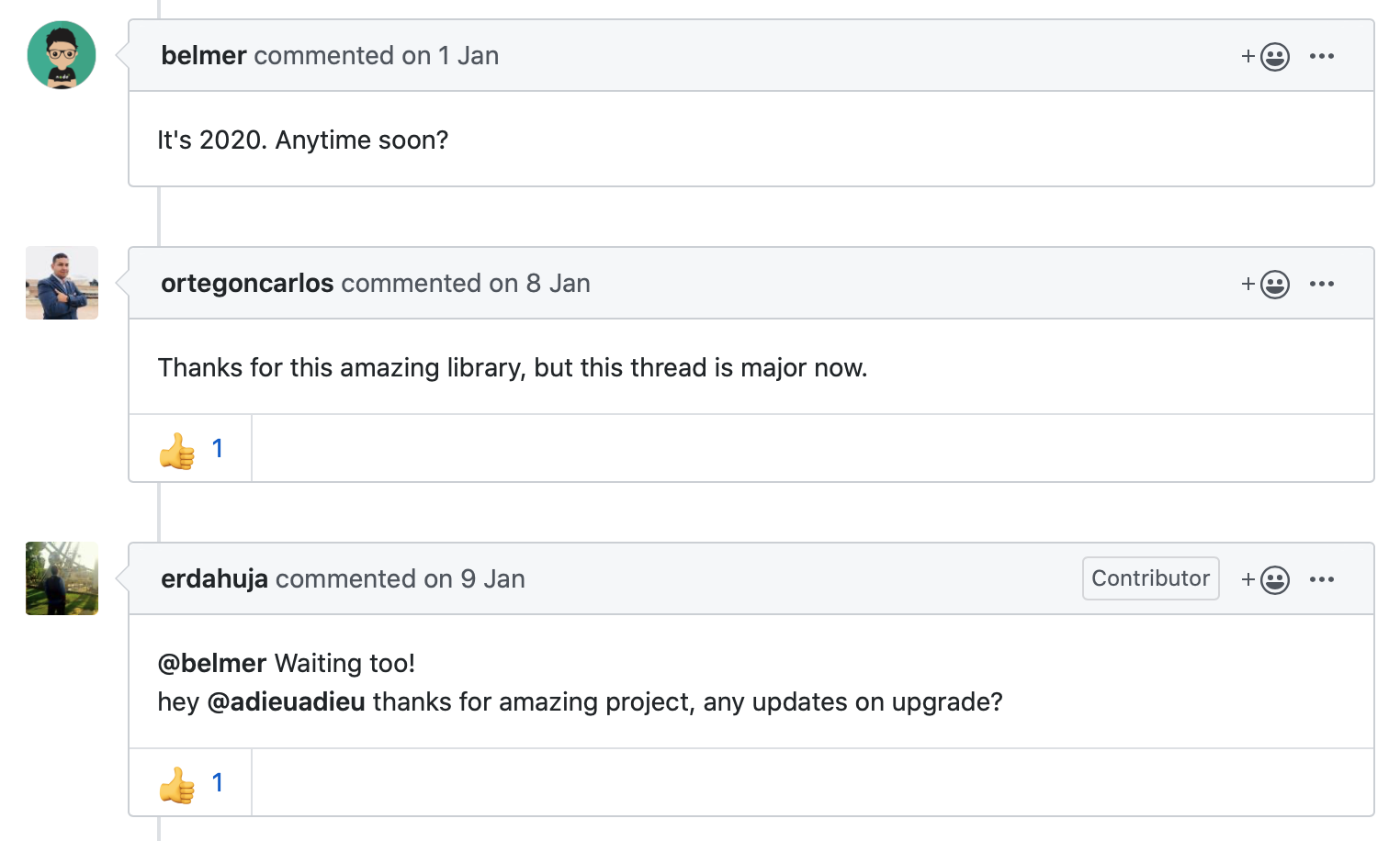
ㅎ
해당 패키지가 업데이트 되기 전에는 잘 안되는 것 같다ㅎㅎㅎ
그럼 다른 패키지를 쓰자!(chrome-aws-lambda)
그래서 다시 이 글(How to use Puppeteer in a Netlify (AWS Lambda) function)로 돌아왔다.
적당히 쏙쏙 필요한 내용만 뽑아서 쓰면 되겠지~
우리가 실습할 내용은 무엇이냐..!하면 velog의 각 블로그는 https://velog.io/@{id}와 같은 구조를 가진다.
즉 이렇게 사용자 ID를 입력 받으면 해당 블로그에 올라온 글 제목들을 크롤링 해보려 한당ㅎ
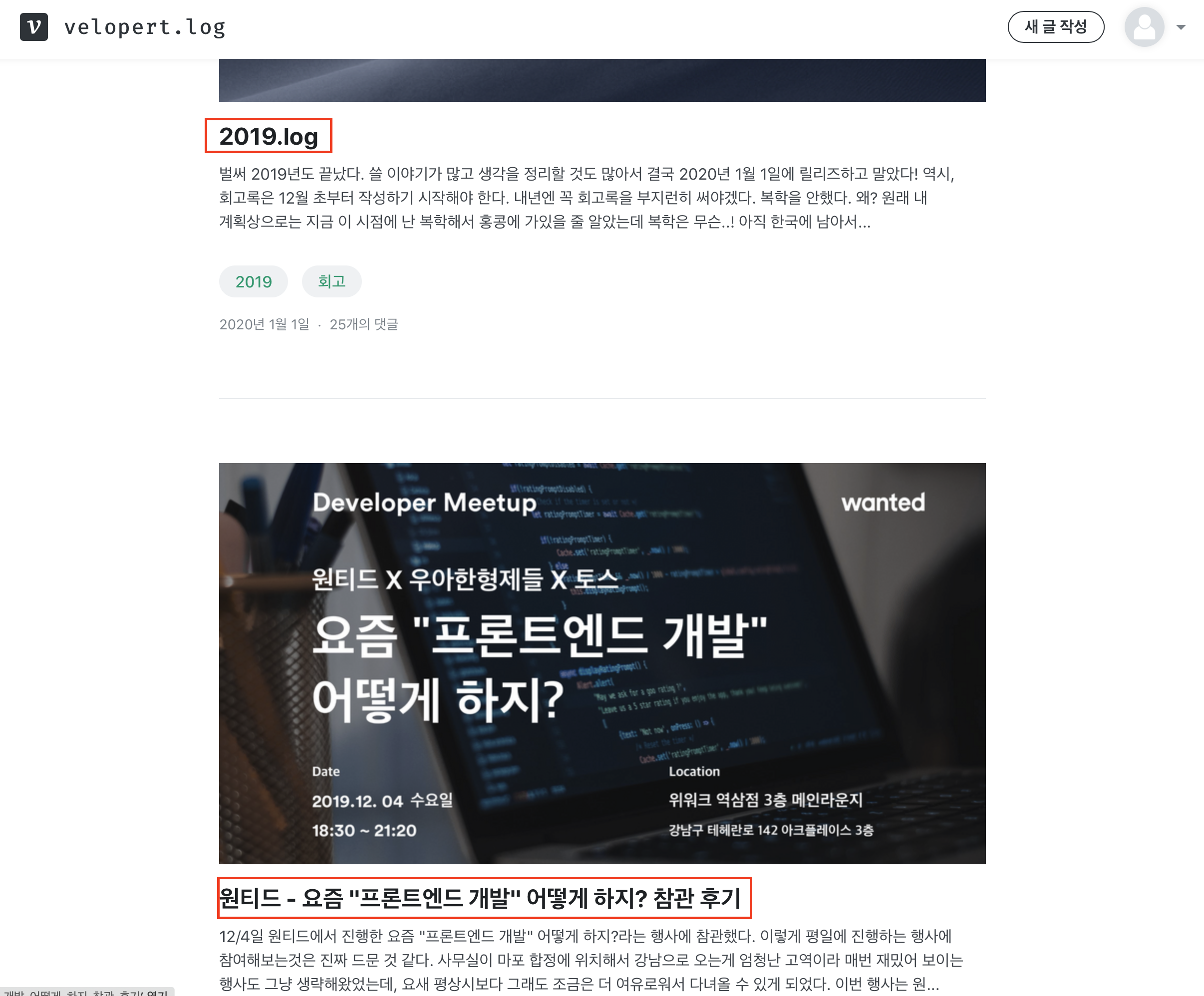
요런 제목들을 가져와보자~
프로젝트 설정
$ sls create -t aws-nodejs -p puppeteerWithLambda
$ cd puppeteerWithLambda우선 Serverless 프로젝트를 만들어주자. 아직 사용해 본 적이 없다면 이 글을 한번 읽어보고 사용해보자ㅎ 정말 편하다
이후에 필요한 패키지를 설치해주자!
$ npm install chrome-aws-lambda
$ npm install puppeteer-core chrome-aws-lambda --save-prod
$ npm install puppeteer --save-dev자 그리고 깔끔하게 작업하기 위해서 프로젝트 구조를 조금 바꾸어주자.
src 폴더를 하나 만들고 handler.js를 지운다. 그리고 src 폴더 내에 index.js 파일을 하나 만들어 주자.
다음과 같은 구조로 만들면 된다.
크롤링 함수 작성하기
이후 index.js 파일을 열어주자
const chromium = require('chrome-aws-lambda');
module.exports.handler = async (event, context) => {
const browser = await chromium.puppeteer.launch({
executablePath: await chromium.executablePath,
args: chromium.args,
defaultViewport: chromium.defaultViewport,
headless: chromium.headless,
});
const page = await browser.newPage();
await browser.close();
//// setTimeout(() => chrome.instance.kill(), 0);
return {
statusCode: 200,
body: JSON.stringify({
message: "Hello World!"
})
}
}puppeteer를 사용하기 위한 기본적인 코드 구조는 다음과 같다. browser를 부르는 코드를 제외하고는 크게 다르지 않다.
여기서 주목할 점은 setTimeout(() => chrome.instance.kill(), 0); 코드 부분이다.
이 글을 읽고 나중에 추가한 부분인데 일부 운영체제(맥이나 리눅스 등등) 에서는 크롬 프로세스가 꺼지기 전에 node를 kill 해버려 크롬 프로세스가 남아있는 경우가 있다.
나같은 경우에도 로컬에서 작업을 하다 경험했고 만약 그렇다면 이 곳을 참고해서 해결하자.
다만 위 부분이 주석처리 된 이유는 이전 @serverless-chrome/lambda를 사용할 때는 위 코드가 동작 되었으나 패키지를 바꾸면서 어떤 방향으로 수정해야할 지 감이 안와 주석처리 해놓았다.
만약 어느 순간부터 크롬이 시작이 안된다면 위에서 남긴 링크를 참고해서 해결하자.
자 본격적인 크롤링 코드를 넣어보자. 우선 가고자하는 url을 얻어내야 한다.
let targetUrl = "https://velog.io/@";
try {
let id = event.pathParameters.id;
targetUrl = targetUrl + id;
} catch (e) {
targetUrl = targetUrl + "velopert";
}특별한 설명은 없어도 될 것 같다. 쿼리를 통해 날라오는 id를 pathParameters로부터 얻어내면 된다.
다만 우리가 AWS 상에서 테스트를 할 때 쿼리를 넘겨주지 않는 경우를 제외하고는 url을 통해서 해당 API를 호출할 수는 없다.
{"message":"Missing Authentication Token"}라는 메시지가 뜨며 아무런 일도 일어나지 않을 것이다.
만약 뒤에 쿼리 없이도 호출이 되게 만들고싶다면 이후 아래에서 설정할 serverless.yml에서
- http:
path: /start/
method: GET
- http:
path: /start/{id}
method: GET와 같은 형식으로 작성하면 된다!
자 브라우저도 키는데 성공했으니 이제 데이터를 모아보자 velog에서 각 글의 제목은 h2 태그로 지정되어 있으므로
await page.goto(targetUrl);
await page.waitForSelector("h2");
const message = await page.$$eval("h2", data => {
return data.map(element => element.textContent);
});를 통해 글을 얻어내고
return {
statusCode: 200,
body: JSON.stringify({
message: ` Data is Here : ${message}`
})
}를 통해 데이터를 쏴주자!
전체 코드는 여기서 확인하자
Serverless 설정하기
자 함수를 다 만들었으니 이제 serverless.yml을 설정해보자!
service: puppeteerwithlambda
provider:
name: aws
runtime: nodejs12.x
memorySize: 512
timeout: 30
region: ap-northeast-2
functions:
start:
handler: src/index.handler
events:
- http:
path: /start/{id}
method: get다음과 같이 설정해주면 된다.
특별히 주목할 점은 함수 파일은 src/index.js 파일을 사용하고 해당 모듈 안에 있는 handler 함수를 호출할 것이다.
함수를 실행하는 방법으론 http의 GET 메소드를 사용할 것이며 쿼리로 id를 받는다는 것이다.
배포 전에 로컬에서 테스트하기
로컬 테스트 또한 기존과 동일하다
$ sls invoke local --function start
{
"statusCode": 200,
"body": "{\"message\":\" Data is Here : 2019.log,원티드 - 요즘 \\\"프론트엔드 개발\\\" 어떻게 하지? 참관 후기,CRA로 만든 프로젝트에 Storybook 적용 / 유용한 팁 / 강의를 마치면서..,Rollup을 사용하여 디자인 시스템 번들 후, npm 라이브러리로 배포하기,Storybook을 활용하여 본격적으로 디자인 시스템 구축하기,Storybook 프로젝트에서 TypeScript로 컴포넌트의 props 문서화 편하게 하기,Storybook을 다양한 Addon과 함께 활용해보면서 사용법 정복하기,TypeScript와 Storybook을 사용한 리액트 디자인 시스템 구축하기 ,TypeScript 환경에서 Redux를 프로처럼 사용하기,TypeScript 환경에서 리액트 Context API 제대로 활용하기,타입스크립트로 리액트 Hooks 사용하기 (useState, useReducer, useRef),리액트 컴포넌트 타입스크립트로 작성하기,타입스크립트 기초 연습,리액트 프로젝트에서 타입스크립트 사용하기,리액트를 다루는 기술 개정판 출간 - 무엇이 달라졌을까?,GDG FRONT-ENDGAME 컨퍼런스 참가 및 발표 후기,react-testing-library 의 비동기작업을 위한 테스트,react-testing-library 를 사용하여 TDD 개발 흐름으로 투두리스트 만들기,react-testing-library 를 사용한 리액트 컴포넌트 테스트,Enzyme 을 사용한 리액트 컴포넌트 테스트\"}"
}잘 동작하는 것을 확인할 수 있다ㅎ
만약 로컬에서 GET에 파라미터를 전달하고싶다면
$ sls invoke local --function start --data '{ "pathParameters": {"id":"jeffyoun"}}'
{
"statusCode": 200,
"body": "{\"message\":\" Data is Here : Serverless 프레임워크 사용해서 배포하기,Puppeteer로 학교 공지 글 크롤링 하기!,NUGU 스피커와 AWS Lambda 사용하기\"}"
}위와 같은 방법을 사용하자!
배포하기
sls deploy를 살포시 입력해주자
$ sls deploy
Serverless: Packaging service...
Serverless: Excluding development dependencies...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
........
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service puppeteerwithlambda.zip file to S3 (42.44 MB)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
.................................
Serverless: Stack update finished...
Service Information
service: puppeteerwithlambda
stage: dev
region: ap-northeast-2
stack: puppeteerwithlambda-dev
resources: 12
api keys:
None
endpoints:
GET - https://sdk7ye4l7g.execute-api.ap-northeast-2.amazonaws.com/dev/start/{id}
functions:
start: puppeteerwithlambda-dev-start
layers:
None
Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.이 때 용량에 주의하자. 너무 작으면 모듈이 포함이 안된 것이고 너무 크다면 필요없는 모듈들까지 포함되어서 Lambda에 올라가는 것이다!
주어진 endPoint로 접속을 해보자.
$ curl -X GET https://sdk7ye4l7g.execute-api.ap-northeast-2.amazonaws.com/dev/start/jeffyoun
{"message":" Data is Here : Serverless 프레임워크 사용해서 배포하기,Puppeteer로 학교 공지 글 크롤링 하기!,NUGU 스피커와 AWS Lambda 사용하기"}
$ curl -X GET https://sdk7ye4l7g.execute-api.ap-northeast-2.amazonaws.com/dev/start/velopert
{"message":" Data is Here : 2019.log,원티드 - 요즘 \"프론트엔드 개발\" 어떻게 하지? 참관 후기,CRA로 만든 프로젝트에 Storybook 적용 / 유용한 팁 / 강의를 마치면서..,Rollup을 사용하여 디자인 시스템 번들 후, npm 라이브러리로 배포하기,Storybook을 활용하여 본격적으로 디자인 시스템 구축하기,Storybook 프로젝트에서 TypeScript로 컴포넌트의 props 문서화 편하게 하기,Storybook을 다양한 Addon과 함께 활용해보면서 사용법 정복하기,TypeScript와 Storybook을 사용한 리액트 디자인 시스템 구축하기 ,TypeScript 환경에서 Redux를 프로처럼 사용하기,TypeScript 환경에서 리액트 Context API 제대로 활용하기,타입스크립트로 리액트 Hooks 사용하기 (useState, useReducer, useRef),리액트 컴포넌트 타입스크립트로 작성하기,타입스크립트 기초 연습,리액트 프로젝트에서 타입스크립트 사용하기,리액트를 다루는 기술 개정판 출간 - 무엇이 달라졌을까?,GDG FRONT-ENDGAME 컨퍼런스 참가 및 발표 후기,react-testing-library 의 비동기작업을 위한 테스트,react-testing-library 를 사용하여 TDD 개발 흐름으로 투두리스트 만들기,react-testing-library 를 사용한 리액트 컴포넌트 테스트,Enzyme 을 사용한 리액트 컴포넌트 테스트"}잘 된다ㅎ
만약에
"errorType": "Runtime.ImportModuleError",
"errorMessage": "Error: Cannot find module 'puppeteer'\이런 에러가 뜬다면 serverless.yml 파일 끝에
package:
include:
- node_modules/puppeteer-core/**를 쓰고 다시 deploy 해보자
마무리
여기까지 AWS Lambda에 Puppeteer를 사용하기위한 삽질이었다ㅠ 나와 같은 삽질을 하고있는 사람들에게 도움이 되기를 바라고 만약 따라하다가 문제가 있거나 더욱 자세한 정보를 알고싶다면 아래 링크를 참고하자
serverless.yml get 파라미터 설정
Cannot find module 'puppeteer-core/lib/FrameManager'
chrome-aws-lambda GitHub
Serverless 모듈 포함 문제
chrome-aws-lambda 사용법
Puppeteer를 AWS Lambda에서 사용하기
Serverless Chrome on AWS Lambda, the guide that works in 2019 and beyond
Running puppeteer and headless chrome on AWS lambda with Serverless


포스팅 잘 보고 가요!!
힘내세요...ㅎ