
Puppeteer로 크롤링 하기!
Puppeteer란?
사람들이 손쉽게 사용할 수 있는 크롤링 라이브러리로는 Selenium이 유명하다. 나도 여러 번 사용해 왔었고 간편한 방법으로 간단하게 크롤링을 할 수 있는 것은 맞으나.. 나는 Python이 익숙치 않아서 불편했었다. 그러던 중에 모두의 친구 구글이 해냈다.
Puppeteer는 Google Chrome 팀에서 공개한 Node.js 라이브러리로 Node.js를 이용해서 Headless Chrome를 조작할 수 있다!
Puppeteer는 2가지 버전이 존재한다.
puppeteer는 최신 버전의 Chromium을 포함한 패키지로 그냥 받아서 사용하면 된다. 한 마디로 올인원 패키지다
puppeteer-core는 Chromium을 포함하지 않는 패키지로 로컬에 우리가 받아놓은 크롬을 사용할 수 있다.
설치 방법은 다음과 같다.
npm i puppeteernpm i puppeteer-core학교 글 크롤링 하기!
금세 증발해 버리는 우리의 흥미를 돋우기 위해 예제를 만들면서 실습해 보자.
시도때도 없이 올라오는 공지 글을 보다 쉽게(?) 확인하기 위해 학교 공지 글을 크롤링 해보자!
중앙대 다빈치 SW 교육원에는 주기적으로 여러 프로그램 안내가 올라온다. 여기에 올라오는 글을 크롤링 하는 것이 우리의 목표다.
우리는 3줄 이상 읽지 않는 사람들이므로 간단하게 제목과 날짜, 신청 인원 등과 글의 링크만 크롤링 해보도록 하자!
프로젝트 설정
프로젝트 폴더를 만들어 준 후에 npm init을 해주자.
y/n과 같이 뭔가를 묻는다면 그냥 엔터를 계속 눌러 주자.
이후 우리는 puppeteer를 사용할 것이므로 npm install puppeteer --save를 해주자!
그럼 우리 프로젝트 디렉토리에 있는 package.json 파일은 대략 아래와 같을 것이다.
{
"name": "이름!!",
"version": "1.0.0",
"description": "",
"main": "여러분이 만든 파일",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^2.1.1"
}
}
이제 우리는 const puppeteer = require('puppeteer');를 통해 puppeteer를 사용할 수 있다! 조금 더 자세하게 알고싶다면 여기를 참고하자.
puppeteer 기본
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.naver.com');
await browser.close();
})();기본적인 사용 형태는 다음과 같다.
puppeteer.launch()를 통해 브라우저를 열고
browser.newPage()를 통해 새로운 창을 연다.
그리고 해당 페이지를 goto(dest)를 통해 이동할 수 있다.
그리고 browser.close()를 통해 브라우저를 닫음으로써 종료할 수 있다!
하지만 이를 실행해보면 아무런 일이 일어나지 않는 것을 알 수 있다. 그 이유는 headless 모드가 true로 설정되어 있으며 브라우저는 네이버로 이동한 후 아무런 일도 하지 않기 때문이다.
우리의 작업 과정을 편하게 확인하기 위해 headless 모드를 false로 바꾸어 주자.
const browser = await puppeteer.launch({
headless : false
});그럼 창이 뜨고 네이버로 이동한 후 바로 사라지는 것을 볼 수 있다.
바로 사라지지 않게 하기 위해서 딜레이를 줘보자.
브라우저를 닫기 전에 아래 코드를 추가해 보자.
await page.waitFor(10000);
단위가 ms 이므로 10초 후에 브라우저가 닫힐 것이다.
창을 열어보면 뭔가 네이버가 이상하게 잘려있는 것을 볼 수 있다.
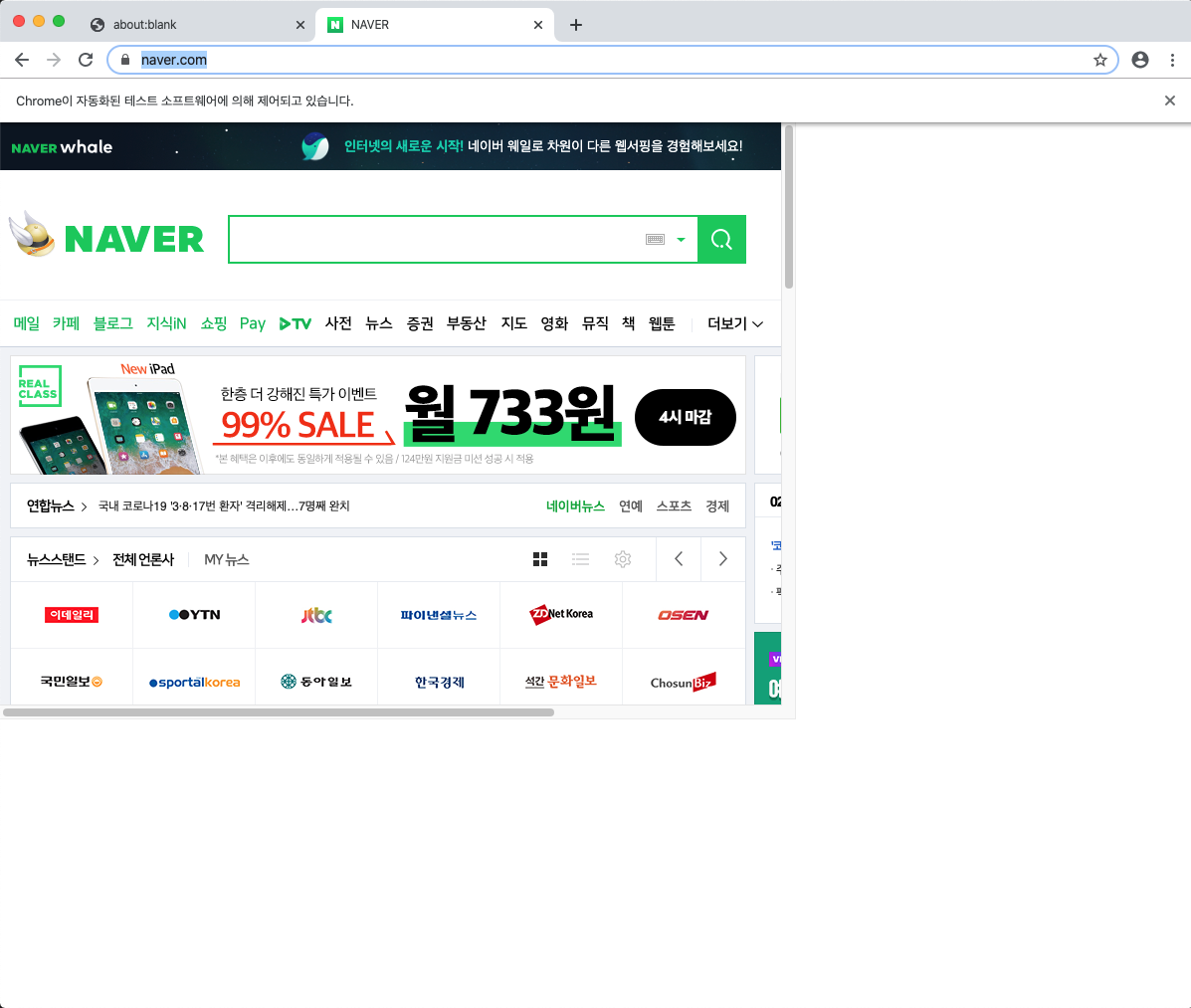
그 이유는 page의 defaultViewPort의 기본 값이 800x600이기 때문이다.
너무 보기 불편하니 크게 크게 설정해주자!
await page.setViewport({
width: 1920,
height: 1080
});
위 문장을 실행하면 페이지가 보여지는 크기를 바꿀 수 있다.
이 때 setViewPort()는 페이지의 크기를 바꿔버리는데 몇몇 사이트는 이에 맞게 동작하지 않을 수 있으므로 사이트에 이동하기 전에 페이지 크기를 설정해주는 것이 좋다.
본격적인 크롤링 들어가기에 앞서서
지금까지 한 건 그냥 브라우저 띄우는 것에 불과하다. 그럼 본격적인 크롤링을 해보자~
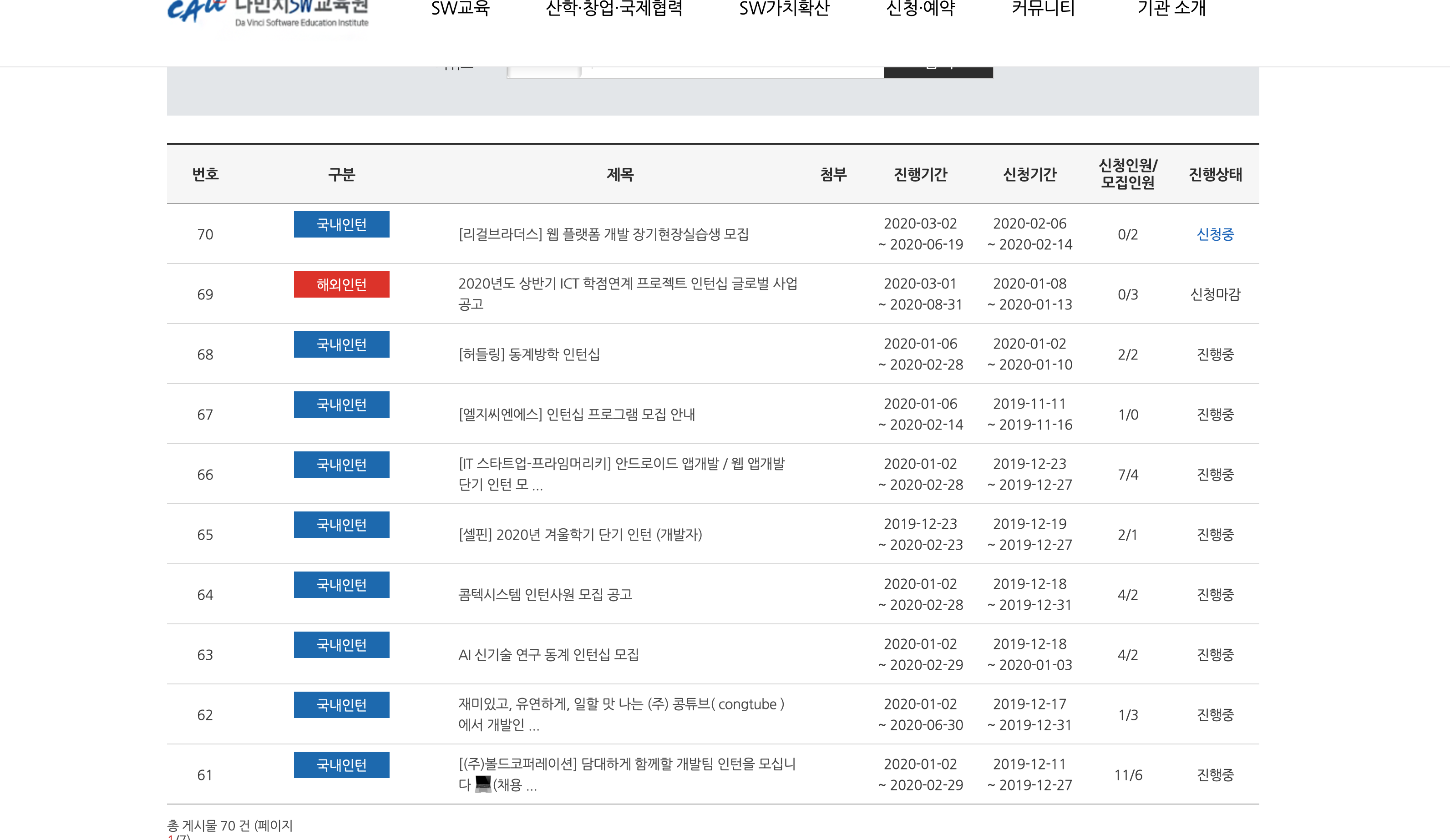
해당 사이트에서 우린 저 글들 중에서 내용과 눌렀을 때 이동하는 링크를 가져와야 한다.
puppeteer에서는 이를 위해 $, $eval, $$, $$eval이란 메소드를 지원한다.
$가 1개인지 2개인지는 한개를 찾느냐, 모두를 찾냐의 차이다.
document.querySelector와 document.querySelectorAll을 생각해보면 좋을 것 같다.
eval의 유무는 아래 코드에서 직접 살펴보자.
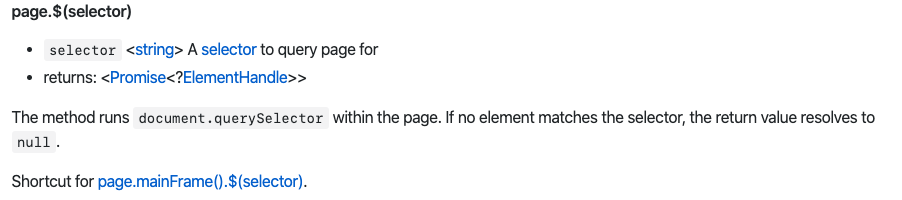
공식 홈페이지를 찾아보면 인자로 Selector 즉, 선택자를 받는다는 것을 알 수 있다.
프론트에서 css를 만져본 경험이 있는 사람이라면 무엇인지 알고 있겠지만 처음 들어보거나 생소하다면 여기를 참고해보자.
다만 개념을 몰라도 크롤링을 할 수는 있다. 다만 중간에 문제가 생겼을 때 선택자 개념을 모르면 해결하기 어려울 수 있으니 기본적인 것이라도 살펴보고 하는 것을 추천한다.
그럼 선택자를 모르는데 어떻게 크롤링을 할 수 있느냐! 하면 바로 크롬의 개발자 도구를 사용하면 된다.
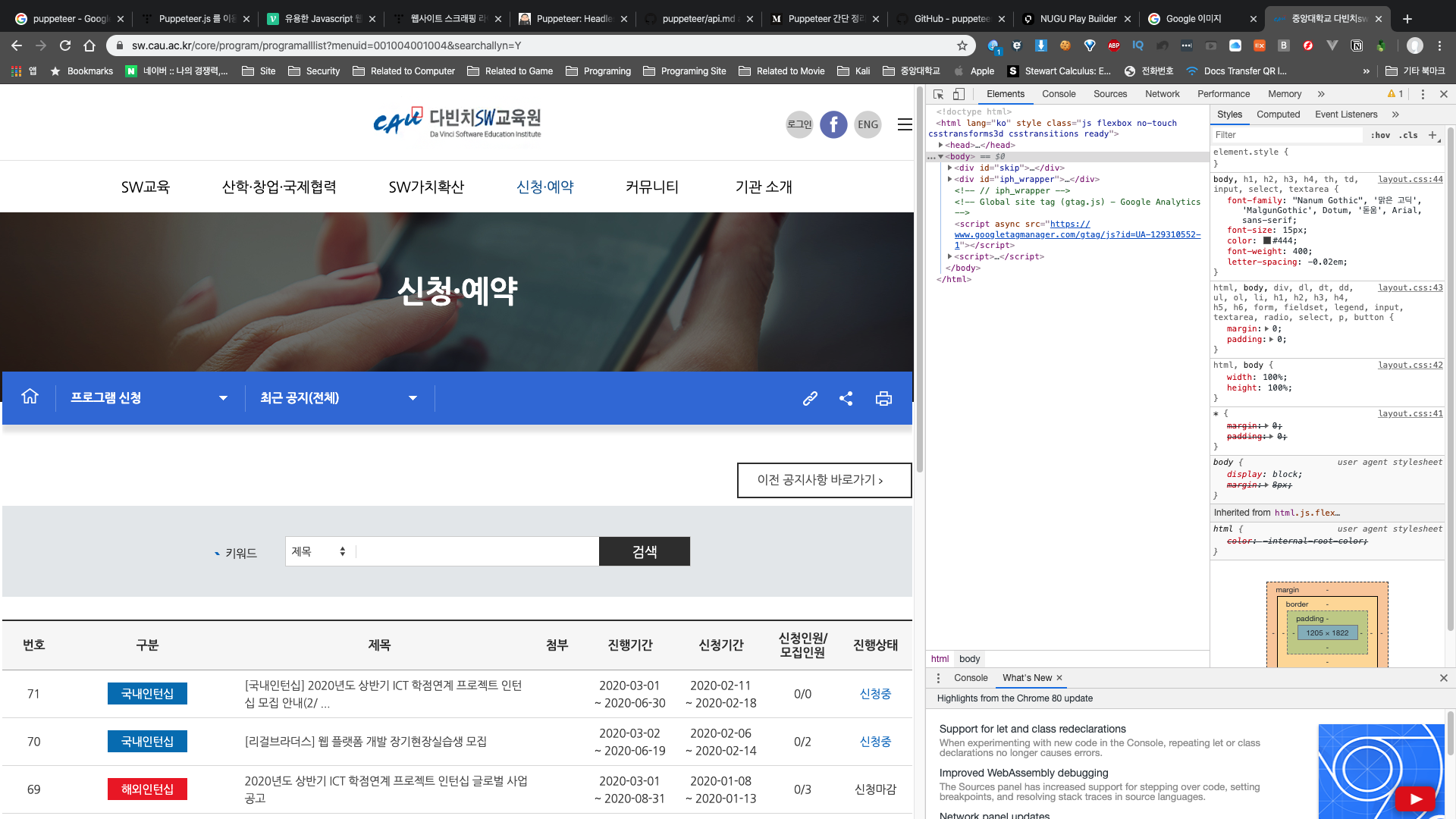
F12를 눌러 개발자 도구를 키고
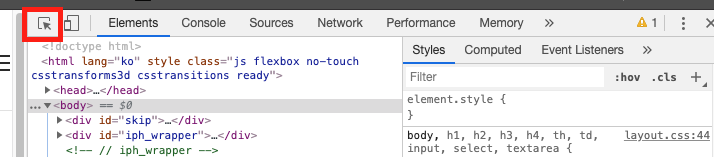
저기 마우스가 떠있는 아이콘을 클릭한다.
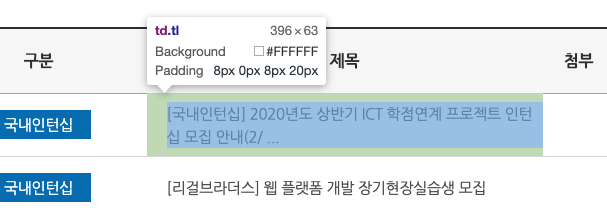
그럼 다음처럼 웹 페이지 요소를 선택할 수 있게 되는데 이를 누르면 HTML 파일에서 해당 요소를 나타내는 부분으로 이동한다.

따라서 이동한 요소의 부모나 자식에서 우리가 원하는 부분을 찾아서
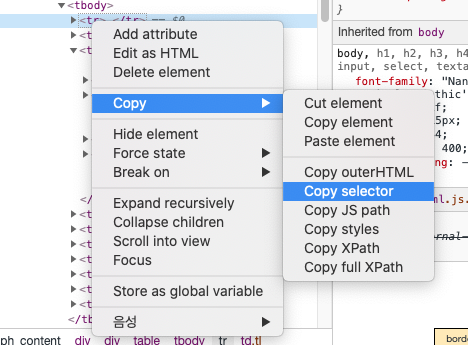
우클릭 후 Copy selector를 눌러준다!
이후 아래와 같이 코드를 작성한다.
let data = await page.$(
"#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td.tl");
let evalData = await page.evaluate(element => {
return element.textContent;
}, data);
console.log(evalData);$ 뒤에 오는 선택자는 원하는 선택자를 찾아서 적당히 넣어주자!
대략적으로 코드를 설명하자면 $()을 통해 해당 요소를 찾고 evaluate()요소를 통해 해당 요소의 원하는 값을 얻어낸다.
위 코드는 아래처럼 바꿀 수도 있다.
let data = await page.$eval(
"#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td.tl", element => {
return element.textContent;
});
console.log(data);즉 $()과 $eval()의 차이는 evaluate()을 내장하고 있느냐의 차이다.
원하는 데이터를 얻어보자
자 데이터를 추출하는 방법은 알아냈으니 정말 우리가 원하는 데이터를 얻어내보자!
우선 우리가 필요로 하는 데이터는 아래와 같은 구조를 하고 있다.
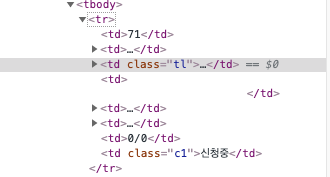
여러 태그 안에 들어있는 것을 확인할 수 있다.
간편하게 하기 위해서 제목, 진행 기간, 신청 기간, 신청인원/모집인원, 진행 상태만 가져와보자.
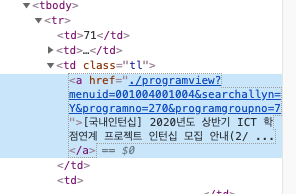
제목의 경우 다음처럼 3번째 태그 안 <a> 태그에 들어있다.
따라서 다음과 같은 코드로 추출 할 수 있다.
let data = {};
let temp = await page.$("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(3) > a");
data.name = await page.evaluate((data) => {
return data.textContent;
}, temp);
data.link = await page.evaluate((data) => {
return data.href;
}, temp);
$을 통해 해당 요소를 선택한 후 eval()을 통해 원하는 데이터를 추출하면 된다.

진행 기간, 신청 기간, 신청인원/모집인원, 진행 상태의 경우 모두 <td>태그 안에 들어있는 것을 확인할 수 있다.
따라서 다음과 같이 추출할 수 있다. let data = {};
let temp = await page.$("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(3) > a");
data.name = await page.evaluate((data) => {
return data.textContent;
}, temp);
data.link = await page.evaluate((data) => {
return data.href;
}, temp);
data.programPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(5)", (data) => data.textContent);
data.applyingPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(6)", (data) => data.textContent);
data.count = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(7)", (data) => data.textContent);
data.state = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(1) > td:nth-child(8)", (data) => data.textContent); 그럼 다음과 같은 데이터를 얻을 수 있다.
{ name: '[국내인턴십] 2020년도 상반기 ICT 학점연계 프로젝트 인턴십 모집 안내(2/ ...',
link:
'https://sw.cau.ac.kr/core/program/programview?menuid=001004001004&searchallyn=Y&programno=270&programgroupno=7',
programPeriod: '2020-03-01 ~ 2020-06-30',
applyingPeriod: '2020-02-11 ~ 2020-02-18',
count: '0/0',
state: '신청중' } 하지만 우리가 모아야 하는 데이터는 여러 줄이므로 아래와 같이 함수를 만들어 준다!
async function getAll(page) {
let data = [];
const number = await page.$$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr", (data) => data.length);
// tr태그의 개수를 세어서 줄의 개수를 얻은 후에
for (let index = 0; index < number; index++) {
data.push(await getOne(page, index + 1));
// 각 줄의 정보를 얻어서 배열에 Push
}
return Promise.resolve(data);
}
async function getOne(page, index) {
let data = {};
let temp = await page.$("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(3) > a");
// nth-child(index)를 이용해 원하는 줄을 선택할 수 있도록 한다.
data.name = await page.evaluate((data) => {
return data.textContent;
}, temp);
data.link = await page.evaluate((data) => {
return data.href;
}, temp);
data.programPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(5)", (data) => data.textContent);
data.applyingPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(6)", (data) => data.textContent);
data.count = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(7)", (data) => data.textContent);
data.state = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(8)", (data) => data.textContent);
return Promise.resolve(data);
}페이지 전환
데이터를 다 얻었으니 다음 페이지로 넘어가야 한다. 페이지를 바꾸는 방법엔 여러가지가 있다.
page.click(Selector)를 이용해 페이지를 넘기는 버튼을 누르는 방법도 있고
https://sw.cau.ac.kr/core/program/programalllist?menuid=001004001004&searchallyn=Y¤tpage=2와 같이 만약 주소에 현재 페이지를 나타내는 인자가 존재한다면 이를 이용할 수도 있다.
후자가 성능 면에서 빠르므로 후자 방법을 이용해 보자.
let data = [];
for (let index = 1; index <= 3; index++) {
await page.goto('https://sw.cau.ac.kr/core/program/programalllist?menuid=001004001004&searchallyn=Y¤tpage=' + index);
data.push(await getAll(page));
}
console.log(data);for문을 돌면서 각 페이지를 크롤링하면 된다! 간단하다=ㅅ=
전체 코드는 다음과 같다.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.setViewport({
width: 1920,
height: 1080
});
let data = [];
for (let index = 1; index <= 3; index++) {
await page.goto('https://sw.cau.ac.kr/core/program/programalllist?menuid=001004001004&searchallyn=Y¤tpage=' + index);
data.push(await getAll(page));
}
console.log(data);
await page.waitFor(10000);
await browser.close();
})();
async function getAll(page) {
let data = [];
const number = await page.$$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr", (data) => data.length);
// tr태그의 개수를 세어서 줄의 개수를 얻은 후에
for (let index = 0; index < number; index++) {
data.push(await getOne(page, index + 1));
// 각 줄의 정보를 얻어서 배열에 Push
}
return Promise.resolve(data);
}
async function getOne(page, index) {
let data = {};
let temp = await page.$("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(3) > a");
// nth-child(index)를 이용해 원하는 줄을 선택할 수 있도록 한다.
data.name = await page.evaluate((data) => {
return data.textContent;
}, temp);
data.link = await page.evaluate((data) => {
return data.href;
}, temp);
data.programPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(5)", (data) => data.textContent);
data.applyingPeriod = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(6)", (data) => data.textContent);
data.count = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(7)", (data) => data.textContent);
data.state = await page.$eval("#iph_content > div > div.list_type_h1.web_view.mt3 > table > tbody > tr:nth-child(" + index + ") > td:nth-child(8)", (data) => data.textContent);
return Promise.resolve(data);
}마무리
간단하게 puppeteer를 다루어보았다. 위 실습은 간단한 실습이라 단순히 데이터를 가져오고 사이트로 이동하는 정도만 사용했지만 복잡한 사이트는 크롤링 하기 쉽지 않을 것이다.
그와 관련된 메소드로 page.click(Selector), page.waitFor(Time[ms]),page.waitForSelector(Selector), page.waitForNavigation() 등이 있을 것이다.
자세한 내용은 공식 API 문서를 참고하면 된다!



추천 누르고 갑니다~~^^