STL 기초
- STL의 구성 요소를 이해하고 효율적인 코드를 작성
- 컨테이너와 알고리즘을 활용해 생산성을 높이는 방식을 학습
STL , Standard Template Library 는
C++ 표준 라이브러리의 일부로,
컨테이너 알고리즘 반복자 등의
템플릿 기반 구성 요소를 포함한다.
이 "STL" 을 활용하면,
다양한 자료구조와 알고리즘을 "직접 구현하지 않고도"
사용할 수 있다
Standard Template Library,
표준 | 템플릿 | 라이브러리 인데
표준이란 = C++ 에서 기본적으로 제공한다는 뜻이고
템플릿 = 데이터에 의존하지 않고
사용할 수 있는 라이브러리 라는 뜻이다.
3가지로 이루어져 있으며:
- 컨테이너 = 데이터를 담는 것
- 알고리즘 = 여러가지 동작
- 반복자 = 컨테이너와 알고리즘에 대해 세부사항을 몰라도 동일한 문법으로 사용할 수 있게
도와주는 존재
컨테이너
컨테이너 = "데이터를 '담는' 자료구조"
데이터를 담는 방식이나 제공하는 함수에 따라
다양한 컨테이너를 제공한다.
-
모든 컨테이너는 "템플릿"으로 구현되어 있어서,
다양한 타입의 데이터를 저장할 수 있다. -
모든 컨테이너는 내부적으로 메모리 관리를 해준다.
따라서 사용할 때 메모리 해제를 따로 고려할 필요가 없다. -
대부분의 컨테이너는
반복자를 제공하며
때문에 내부 구성을 모르더라도
동일한 방식으로 컨테이너 내부를 순회할 수 있다.
벡터
지금까지도 자주 사용해온 벡터 는
= 배열과 매우 유사한 컨테이너로
대표적인 특징은 다음과 같다.
-
"템플릿 클래스로 구현되어" 특정 타입에 종속되지 않는다
-
삽입되는 원소 개수에 따라
내부 배열의 크기가 자동으로 조정된다
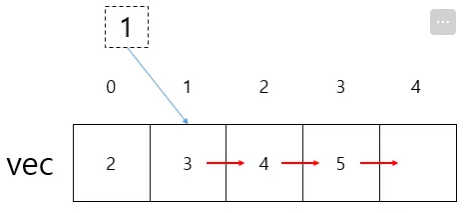
ex) push_back(emplace_back) / pop_back -
임의 접근이 가능하다 = 인덱스를 통한 접근이 가능하다
ex) arr[2] 처럼 vec[2] 가 가능 -
삽입/삭제 는 맨 뒤에 하는 게 좋다
배열 중간에 삽입/삭제 도 물론 가능하지만
배열을 복사하는 과정이 필요해서 비효율적
성능 이슈와도 직결한다
- 벡터의 선언
타입만 명시해서 선언하는 방법과
초기값까지 같이 선언하는 방법이 있다.
vector<int> vec : int를 요소로 갖는 벡터 vec
vector<int> vec2(5,10) : 크기가 5이고, int 10 을 요소로 갖는 vec2

vector<int> vec3 = {1,2,3,4,5} :
초기화 리스트를 사용한 선언으로,
특정 값으로 벡터를 초기화 해줄 때 자주 사용된다.
(원소의 개수가 적을 때 주로 씀)
vector<int> vec4(vec3) : vec3 을 복사해 온 vec4
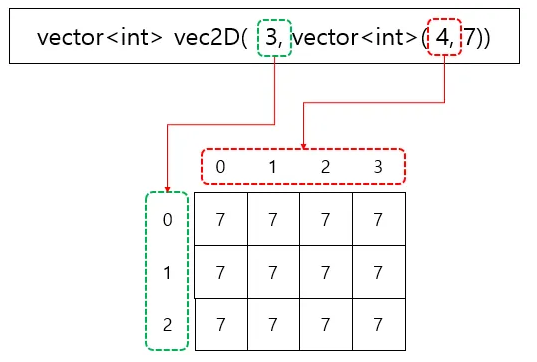
vector<vector<int>> vec2D(3, vector<int>(4, 7)) :
조금 복잡한 내용이지만
이건 다차원 배열로, 예시로 준 코드의 해석은
모든 원소가 7인 3*4 행렬
- 벡터의 동작
벡터의 메서드(멤버함수) 중 자주 사용하는 것들 :
1) push_back
벡터의 맨 끝에 원소를 추가해준다.
원소의 개수에 따라 벡터 크기는 자동으로 증가하기 때문에
"메모리 관리에 대해 신경쓸 필요 없다"
2) pop_back
벡터 맨 끝의 원소를 제거해준다.
맨 끝의 원소가 제거됨과 동시에 벡터 크기도 자동으로 줄어든다
(자동 메모리 관리)
3) size
현재 벡터의 크기(길이)(원소 개수) 를 확인할 수 있다
이 .size() 를 활용해 반복문을 자주 쓴다
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec = {10, 20, 30};
cout << "Size of vector: " << vec.size() << endl;
vec.push_back(40);
cout << "Size after push_back: " << vec.size() << endl;
vec.pop_back();
cout << "Size after pop_back: " << vec.size() << endl;
return 0;
}
// 출력:
// Size of vector: 3
// Size after push_back: 4
// Size after pop_back: 34) erase
특정 위치 혹은 구간에 있는 원소를 제거하는 함수로
이렇게 중간에 있는 원소를 삭제하게 되면
나머지 원소들을 다 옮겨줘야 하기 때문에
"시간 복잡도" 가 커질 수 있어서 되도록 사용은 지양할 것.
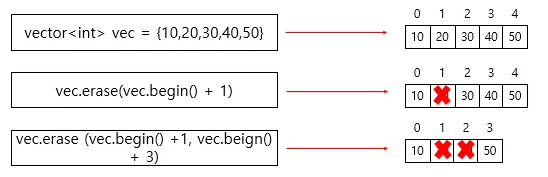
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec = {10, 20, 30, 40, 50};
// 두 번째 요소 제거 (index 1)
vec.erase(vec.begin() + 1);
cout << "Vector after erasing second element: ";
for (int num : vec) {
cout << num << " ";
}
cout << endl;
// 범위 요소 제거 (index 1~2)
vec.erase(vec.begin() + 1, vec.begin() + 3);
// 범위를 하나 건너까지 잡는 게 포인트
// .end() 가 마지막원소 다음자리이듯이
// 이 범위도 범위 end 부분은 건드리지 않고 그 전까지 건드림
cout << "Vector after erasing range: ";
for (int num : vec) {
cout << num << " ";
}
return 0;
}
// 출력:
// Vector after erasing second element: 10 30 40 50
// Vector after erasing range: 10 50맵
핸드폰에서 연락처를 찾을 때
이름 등을 검색해서 번호를 찾듯이,
'특정 키' 를 사용하여 값을 검색하는 기능을 제공하는 컨테이너를
맵 이라고 부른다.
배열은 정수형 인덱스를 활용해서 특정 위치의 값을 빠르게 찾아주지만,
맵은 키 를 활용해서 값과 쌍으로 저장해두고 검색한다.
맵의 주요 특성은:
1) 키-값 쌍은 pair<const key, Value> 형태로 저장된다
2) 키값을 기준으로 "내부 데이터가 자동으로 정렬된다"
3) 중복 키값은 허용되지 않는다
맵의 선언
맵을 선언하는 방식에는 여러가지가 있는데,
맵의 주요 특성을 이해함으로써 적절한 선언 방식을 고르는데 참고할 수 있다.
맵을 선언할 때는
키-값 쌍을 저장하기 위해
"키 타입" 과 "값 타입" 두 가지를 지정할 필요가 있다
이 두 타입은 동일해도, 서로 달라도 무방하며
키 타입은 비교 연산이 가능한 종류여야 한다
키-값이 같은 경우:
#include <iostream>
#include <map>
using namespace std;
// 문자열 키와 문자열 값을 저장하는 map 예제
int main() {
map<string, string> countryMap;
// 요소 추가
countryMap["KR"] = "Korea";
countryMap["US"] = "United States";
countryMap["JP"] = "Japan";
// 요소 출력
for (const auto& pair : countryMap) {
cout << "Country Code: " << pair.first << ", Country Name: " << pair.second << endl;
}
return 0;
}
/*
출력 결과:
Country Code: JP, Country Name: Japan
Country Code: KR, Country Name: Korea
Country Code: US, Country Name: United States
*/키-값이 다른 경우:
#include <iostream>
#include <map>
using namespace std;
// 정수 키와 문자열 값을 저장하는 map 예제
int main() {
map<int, string> studentMap;
// 요소 추가
studentMap[101] = "Alice";
studentMap[102] = "Bob";
studentMap[103] = "Charlie";
// 요소 출력
for (const auto& pair : studentMap) {
cout << "ID: " << pair.first << ", Name: " << pair.second << endl;
}
return 0;
}
/*
출력 결과:
ID: 101, Name: Alice
ID: 102, Name: Bob
ID: 103, Name: Charlie
*/맵의 동작
"맵에서 제공되는 함수들"에 대해서,
- 우선 맵은 키 값 순서대로 오름차순 정렬된다.
직접 별도로 정렬 과정을 거치지 않더라도
삽입/삭제에 따라 알아서 내부적으로 정렬된다
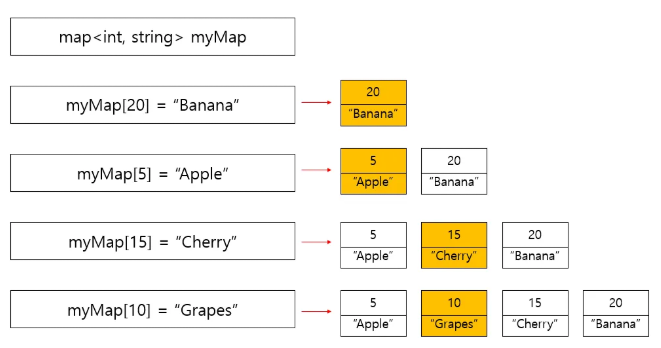
insert()
make_pair()를 이용해서pair객체를 생성한 뒤
insert함수를 사용할 수 있다
또는{}[]를 활용해서 값을 추가할 수도 있다
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, string> myMap;
// make_pair()를 사용하여 insert()
myMap.insert(make_pair(1, "Apple"));
myMap.insert(make_pair(2, "Banana"));
myMap.insert(make_pair(3, "Cherry"));
// make_pair() 괄호 안에 걸로 pair 를 make 해서
// insert 맵에 삽입하겠다
// 출력
for (const auto& pair : myMap) {
cout << "Key: " << pair.first << ", Value: " << pair.second << endl;
}
return 0;
}
/*
출력 결과:
Key: 1, Value: Apple
Key: 2, Value: Banana
Key: 3, Value: Cherry
*/// {}를 사용하여 insert()
myMap.insert({4, "Dog"});
myMap.insert({5, "Elephant"});
myMap.insert({6, "Frog"}); // {키, 값}
// [] 연산자로 값 추가
myMap[7] = "Giraffe";
myMap[8] = "Horse";
myMap[9] = "Iguana"; // 맵이름[키] = 값find()
find 메서드를 통해 특정 "키"가 맵에 존재하는지 확인 가능
find()는 키가 존재하면 해당 키의 iterator를 반환하고
존재하지 않으면.end()를 반환한다.벡터에서 알고리즘 헤더 차용해 find 하던것과 유사
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, string> myMap = {
{1, "Apple"},
{2, "Banana"},
{3, "Cherry"}
};
int key = 2;
auto it = myMap.find(key); // 키 2를 찾기
if (it != myMap.end()) { // 키가 존재하면,
// 키가 존재하지 않을 시 .end() 가 반환되기 때문
cout << "Found! Key: " << it->first << ", Value: " << it->second << endl;
} else {
cout << "Key " << key << " not found!" << endl;
}
return 0;
}
/*
출력 결과:
Found! Key: 2, Value: Banana
*/size()
맵의 키-값 쌍의 개수를 반환한다
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, string> myMap;
// 요소 추가
myMap[1] = "Apple";
myMap[2] = "Banana";
myMap[3] = "Cherry";
// 현재 크기 출력
cout << "Map size: " << myMap.size() << endl;
return 0;
}
/*
출력 결과:
Map size: 3
*/벡터 길이 구할 떄와 같다
erase(key)
맵 안 특정 key 를 가진 요소만 삭제한다
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, string> myMap = {
{1, "Apple"},
{2, "Banana"},
{3, "Cherry"}
};
cout << "Before erase, size: " << myMap.size() << endl;
// 특정 키 삭제
myMap.erase(2);
cout << "After erase(2), size: " << myMap.size() << endl;
// 남은 요소 출력
for (const auto& pair : myMap) {
cout << "Key: " << pair.first << ", Value: " << pair.second << endl;
}
return 0;
}
/*
출력 결과:
Before erase, size: 3
After erase(2), size: 2
Key: 1, Value: Apple
Key: 3, Value: Cherry
*/- 존재하지 않는 키를 삭제할 경우에는)
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, string> myMap = {
{10, "Dog"},
{20, "Cat"},
{30, "Rabbit"}
};
// 존재하지 않는 키 삭제 시도
int removed = myMap.erase(40);
if (removed == 0) { // 반환값이 0인 모
cout << "Key 40 not found. No deletion performed." << endl;
}
return 0;
}
/*
출력 결과:
Key 40 not found. No deletion performed.
*/clear
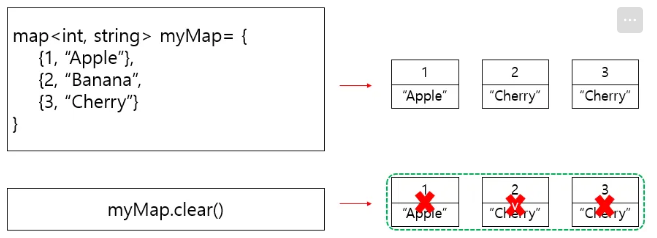
맵에 있는 모든 원소를 삭제한다
(맵 말고도 대부분의 컨테이너에 존재하는 함수)
알고리즘
STL 은 다양한 컨테이너와 독립적으로 동작하는 범용 알고리즘을 제공하는데,
ex) 특정 원소 값을 찾거나, 정렬 기능 등을
표준 라이브러리에서 바로 사용할 수 있다
추가로,
특정 컨테이너의 내부 구현을 몰라도
동일한 방식으로 알고리즘을 적용할 수 있다는 게 나이스한 점.
이것이 가능한 이유는 "반복자" 덕분인데
반복자(iterator)는 컨테이너의 요소를 "추상화"하여
일관된 방식으로 접근할 수 있도록 도와준다.
- sort
컨테이너 내부의 데이터를 정렬하는 함수로,
기본 타입, int 나 double 등의 경우는
사용자 정렬 함수가 없다면 오름차순으로 정렬되며
직접 사용자 정렬 함수를 정의할 수도 있다.사용자 정렬 함수는
인자를 1개 받는 경우 / 2개 받는 경우 가 나뉘어져 있지만
여기선 2개인 경우만
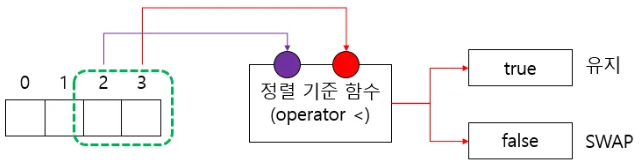
사용자 정렬 함수 comp(a, b) 를 구현하기 위해 알아둬야 하는 것은:
1) 현재 컨테이너에서 첫 번째 인자 a 가 앞에 있는 원소를 의미한다
2) comp(a, b) 가 true 이면 a 와 b 의 순서는 유지되고,
false라면 순서를 바꾼다
기본 타입 벡터를 정렬하는 예시)
#include <iostream>
#include <vector>
#include <algorithm> // sort 함수 포함
using namespace std;
int main() {
vector<int> vec = {5, 2, 9, 1, 5, 6};
// 오름차순 정렬
sort(vec.begin(), vec.end());
// 결과 출력
for (int num : vec) {
cout << num << " ";
}
return 0;
}#include <iostream>
#include <vector>
#include <algorithm> // sort 함수 포함
using namespace std;
bool compare(int a, int b) {
return a > b; // 내림차순
} // 기준을 정해주는 사용자 정렬 함수
int main() {
vector<int> vec = {5, 2, 9, 1, 5, 6};
// 내림차순 정렬
sort(vec.begin(), vec.end(), compare); // 사용자 정렬 함수 반영
// 결과 출력
for (int num : vec) {
cout << num << " ";
}
return 0;
}기본 타입 배열의 경우)
#include <iostream>
#include <algorithm> // sort 함수 포함
using namespace std;
int main() {
int arr[] = {5, 2, 9, 1, 5, 6};
int size = sizeof(arr) / sizeof(arr[0]);
// 오름차순 정렬
sort(arr, arr + size); // 반복자처럼 활용됨
// 결과 출력
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
return 0;
}#include <iostream>
#include <algorithm> // sort 함수 포함
using namespace std;
bool compare(int a, int b) {
return a > b; // 내림차순
}
int main() {
int arr[] = {5, 2, 9, 1, 5, 6};
int size = sizeof(arr) / sizeof(arr[0]);
// 내림차순 정렬
sort(arr, arr + size, compare);
// 결과 출력
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
return 0;
}클래스 타입 벡터의 경우)
#include <iostream>
#include <vector>
#include <algorithm> // sort 함수 포함
using namespace std;
class Person {
private:
string name;
int age;
public:
// 생성자
Person(string name, int age) : name(name), age(age) {}
// Getter 함수
string getName() const { return name; }
int getAge() const { return age; }
// const로 값변경 방지
};
// 다중 기준 정렬 함수 (나이 오름차순 → 이름 오름차순)
bool compareByAgeAndName(const Person& a, const Person& b) {
// 상수로 Person 객체 참조
if (a.getAge() == b.getAge()) { // 나이가 같다면
return a.getName() < b.getName(); // 이름 오름차순
}
return a.getAge() < b.getAge(); // 나이 오름차순
}
int main() {
vector<Person> people = {
Person("Alice", 30),
Person("Bob", 25),
Person("Charlie", 35),
Person("Alice", 25)
};
// 나이 → 이름 순으로 정렬
sort(people.begin(), people.end(), compareByAgeAndName);
// 결과 출력
for (const Person& person : people) {
cout << person.getName() << " (" << person.getAge() << ")" << endl;
}
return 0;
}클래스 같이 직접 만들어낸 타입의 경우에는,
C++ 에서 자동으로 인식해서 정렬할 수가 없기 때문에
비교 해주는 (compare) 함수를 반드시 직접 정의해주고
sort에 사용해 줘야 한다.
- find
find 는 아까도 봤지만,
컨테이너 내부에서 특정 원소를 찾아 해당 원소의 "반복자"를 반환하는 함수로
find(first, last, 찾을 값)의 형태로 사용한다find도 STL 템플릿->알고리즘 에서 제공하는 함수로,
데이터 타입, 컨테이너 종류에 구애받지 않고 작동한다.
find 함수의 세부 동작은 아래와 같다:
1) find(first, last) 가 탐색 대상(범위)
2) 원소를 찾은 경우 해당 원소의 "반복자"를 반환
3) 못 찾았다면 last에 해당하는 반복자를 반환 (주로 .end())
#include <iostream>
#include <vector>
#include <algorithm> // find 함수 포함
using namespace std;
int main() {
vector<int> vec = {10, 20, 30, 40, 50};
// 특정 값 30을 찾음
auto it = find(vec.begin(), vec.end(), 30);
if (it != vec.end()) {
cout << "값 30이 벡터에서 발견됨, 위치: " << (it - vec.begin()) << endl;
} else {
cout << "값 30이 벡터에 없음" << endl;
}
return 0;
}#include <iostream>
#include <algorithm> // find 함수 포함
using namespace std;
int main() {
int arr[] = {1, 2, 3, 4, 5};
int size = sizeof(arr) / sizeof(arr[0]);
// 특정 값 4를 찾음
auto it = find(arr, arr + size, 4);
if (it != arr + size) {
cout << "값 4가 배열에서 발견됨, 위치: " << (it - arr) << endl;
} else {
cout << "값 4가 배열에 없음" << endl;
}
return 0;
}#include <iostream>
#include <algorithm> // find 함수 포함
#include <string>
using namespace std;
int main() {
string str = "hello world";
// 문자 'o' 찾기
auto it = find(str.begin(), str.end(), 'o');
if (it != str.end()) {
cout << "문자 'o'가 문자열에서 발견됨, 위치: " << (it - str.begin()) << endl;
} else {
cout << "문자 'o'가 문자열에 없음" << endl;
}
return 0;
}반복자
컨테이너와 알고리즘에 대해 알아보면서,
컨테이너의 내부 구조는 서로 다르더라도
대부분 알고리즘을 동일한 코드를 활용해 사용할 수 있다는 점에 주목되는데,
즉, 컨테이너 구현 방식에 의존하지 않고도
"내부 구현을 몰라도" 알고리즘을 활용하는데 전혀 문제가 없다는 얘기.
이는 계속해서 등장한 반복자 를 기반으로 알고리즘이 동작하기 때문이다.
반복자, iterator 는 컨테이너의 요소들에 대한
"일관된 접근 방법" 을 제공하기 때문에,
알고리즘이 특정 컨테이너에 내부 구현과 무관하게 동작할 수 있게 된다.
- 순방향 반복자
말그대로 앞에서부터 뒤로 순차적으로 순회하는 반복자.
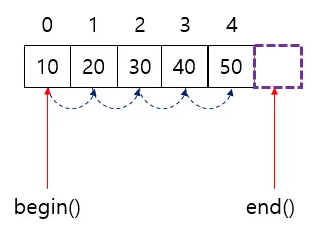
begin()은 컨테이너의 첫 번째 원소를 가리키는 반복자end()는 컨테이너의 마지막 원소 "다음 곳" 을 가리키는 반복자
왜 이렇게 end() 가 마지막 원소의 "다음 곳"을 가리키가 되었는가 하면:
1) 일관된 반복 구조를 유지할 수 있고
2) 탐색 실패를 쉽게 표현할 수 있기 때문
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 순방향 반복자를 사용해 짝수만 출력
for (auto it = numbers.begin(); it != numbers.end(); ++it) {
if (*it % 2 == 0) {
cout << *it << " ";
}
}
return 0;
}
// 출력: 2 4 6 8 10#include <map>
#include <iostream>
using namespace std;
int main() {
map<string, int> scores = {{"Alice", 90}, {"Bob", 85}, {"Charlie", 88}};
// 순방향 반복자를 사용해 맵의 키-값 쌍 출력
for (auto it = scores.begin(); it != scores.end(); ++it) {
cout << it->first << ": " << it->second << endl;
}
return 0;
}
// 출력:
// Alice: 90
// Bob: 85
// Charlie: 88#include <vector>
#include <string>
#include <algorithm>
#include <iostream>
using namespace std;
int main() {
vector<string> words = {"apple", "banana", "cherry", "date"};
string target = "cherry";
auto it = find(words.begin(), words.end(), target);
if (it != words.end()) {
cout << "Word \"" << target << "\" found at index " << distance(words.begin(), it) << endl;
// 두 인자 사이의 거리
// => 벡터 시작부터 해당 반복자까지의 거리 = 인덱스
} else {
cout << "Word \"" << target << "\" not found." << endl;
}
return 0;
}
// 출력: Word "cherry" found at index 2- 역방향 반복자
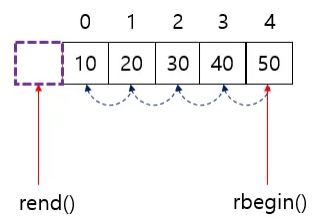
반대로 역방향 반복자는
컨테이너의 마지막 원소부터 첫 번쨰 원소까지 역순으로 순회하며
rbegin()은 컨테이너의 마지막 원소를 가리키고rend()는 컨테이너의 첫 번째 원소보다 "하나 이전 곳" 을 가리킨다
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int> numbers = {10, 15, 20, 25, 30};
// 역방향 반복자로 짝수만 출력
for (auto it = numbers.rbegin(); it != numbers.rend(); ++it) {
if (*it % 2 == 0) {
cout << *it << " ";
}
}
return 0;
}
// 출력: 30 20 10#include <map>
#include <iostream>
using namespace std;
int main() {
map<string, int> scores = {{"Alice", 90}, {"Bob", 85}, {"Charlie", 88}};
// 역방향 반복자로 값이 88 이상인 항목만 출력
for (auto it = scores.rbegin(); it != scores.rend(); ++it) {
if (it->second >= 88) {
cout << it->first << ": " << it->second << endl;
}
}
return 0;
}
// 출력:
// Charlie: 88
// Alice: 90#include <vector>
#include <string>
#include <algorithm>
#include <iostream>
using namespace std;
int main() {
vector<string> words = {"apple", "banana", "cherry", "date"};
string target = "banana";
auto it = find(words.rbegin(), words.rend(), target);
if (it != words.rend()) {
cout << "Word \"" << target << "\" found at reverse index "
<< distance(words.rbegin(), it) << " (from the back)" << endl;
cout << "Word \"" << target << "\" found at forward index "
<< distance(words.begin(), it.base()) - 1 << " (from the front)" << endl;
} else {
cout << "Word \"" << target << "\" not found." << endl;
}
return 0;
}
// 출력:
// Word "banana" found at reverse index 2 (from the back)
// Word "banana" found at forward index 1 (from the front)