C++ Functions
함수 는 "호출" 되었을 때만 실행되는 "코드블럭" 으로
파라미터(매개변수)를 함수로 전달할 수도 있다.
특정 액션을 구현하기 위해 사용되며,
코드의 재사용 과도 연관이 있다.
함수 생성
C++에는 기본적으로 main() (코드실행에 쓰임) 등의 함수가 내장되어 있지만,
직접 자기만의 함수를 만들 수도 있다.
함수를 직접 생성,정의 하기 위해선 아래와 같이 () 와 함께 함수이름을 지정해주면 된다
void 함수이름() {
// 실행할 코드
}여기서
void는,
"리턴값을 가지지 않는다" 라는 의미인데, 이는 나중에 배울 예정
이렇게 정의한 함수는 당연히 '바로 실행' 되는 게 아니고,
'나중에 쓰이기 위해 저장된다'
함수를 호출하기 위해선, () 까지 세트로 생각해서 그대로 적어주면 된다
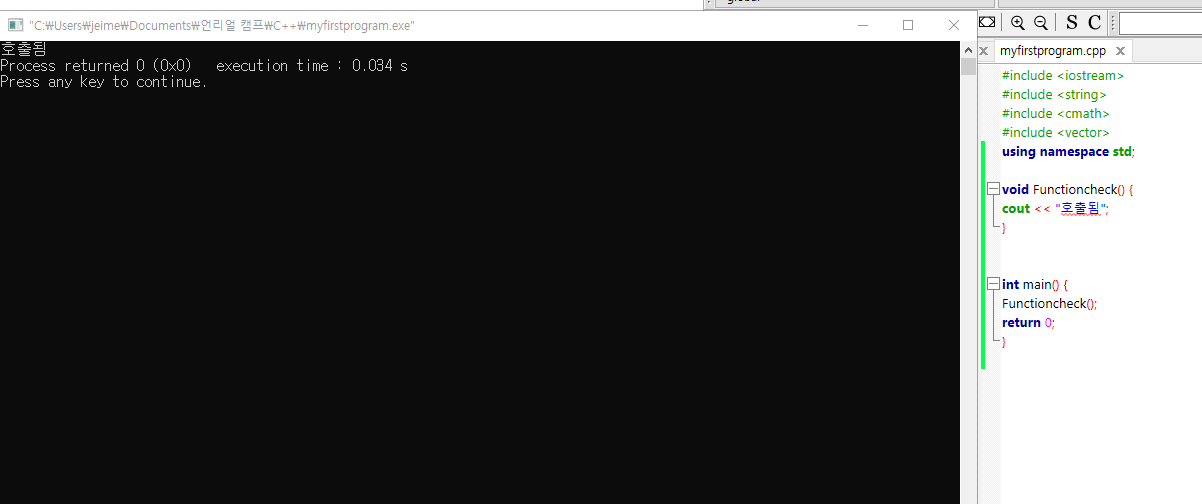
void Functioncheck() {
cout << "호출됨";
}
int main() {
Functioncheck(); // 여러번 호출도 가능
return 0;
}
선언과 정의
C++ 에서 함수는 두 파트로 구성되는데
- 선언 : 리턴값, 함수의 이름, 파라미터 등
- 정의 : 함수의 몸체(body) = 실행될 코드
void myFunction() { // 선언 부분
// 정의 부분
}다만 이 함수의 '선언' 과 '정의' 부분을 따로 분리할 수 있는데,
코드를 최적화하기 위해 이렇게 나눠주기도 한다.
보통이라면 무언가를 선언 및 정의해주기 전에 호출부터 해버리면 에러가 나겠지만
우선 "선언" 부터 해주고 "정의"를 나중에 해주는 형식
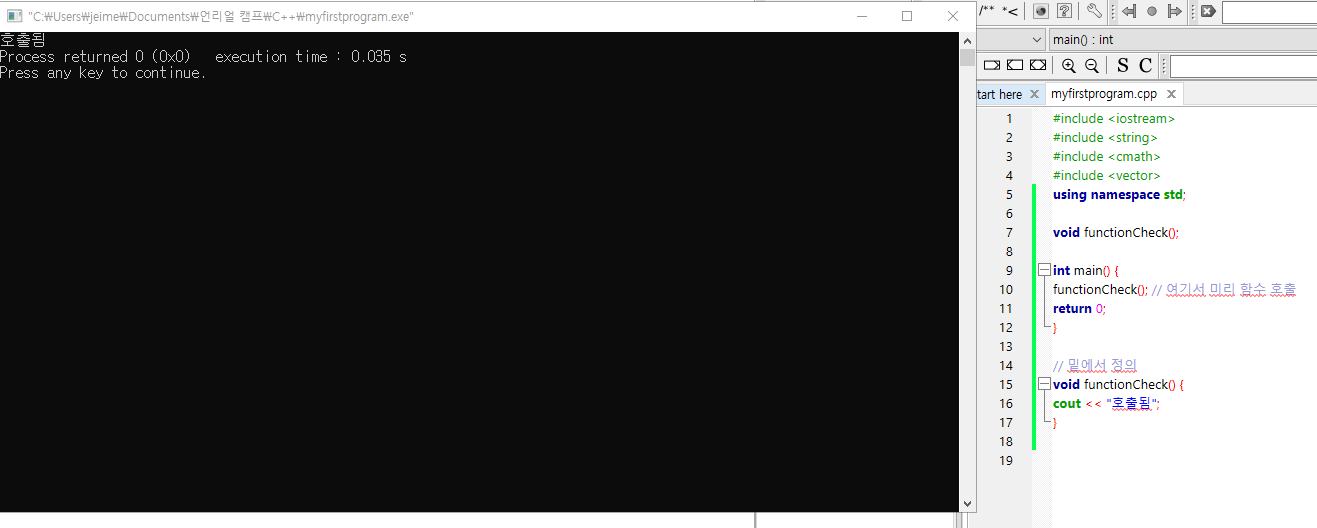
void functionCheck();
int main() {
functionCheck(); // 여기서 미리 함수 호출
return 0;
}
// 밑에서 정의
void functionCheck() {
cout << "호출됨";
}
선언과정의라는 개념에 헷갈릴 수 있기 때문에 주의가 필요
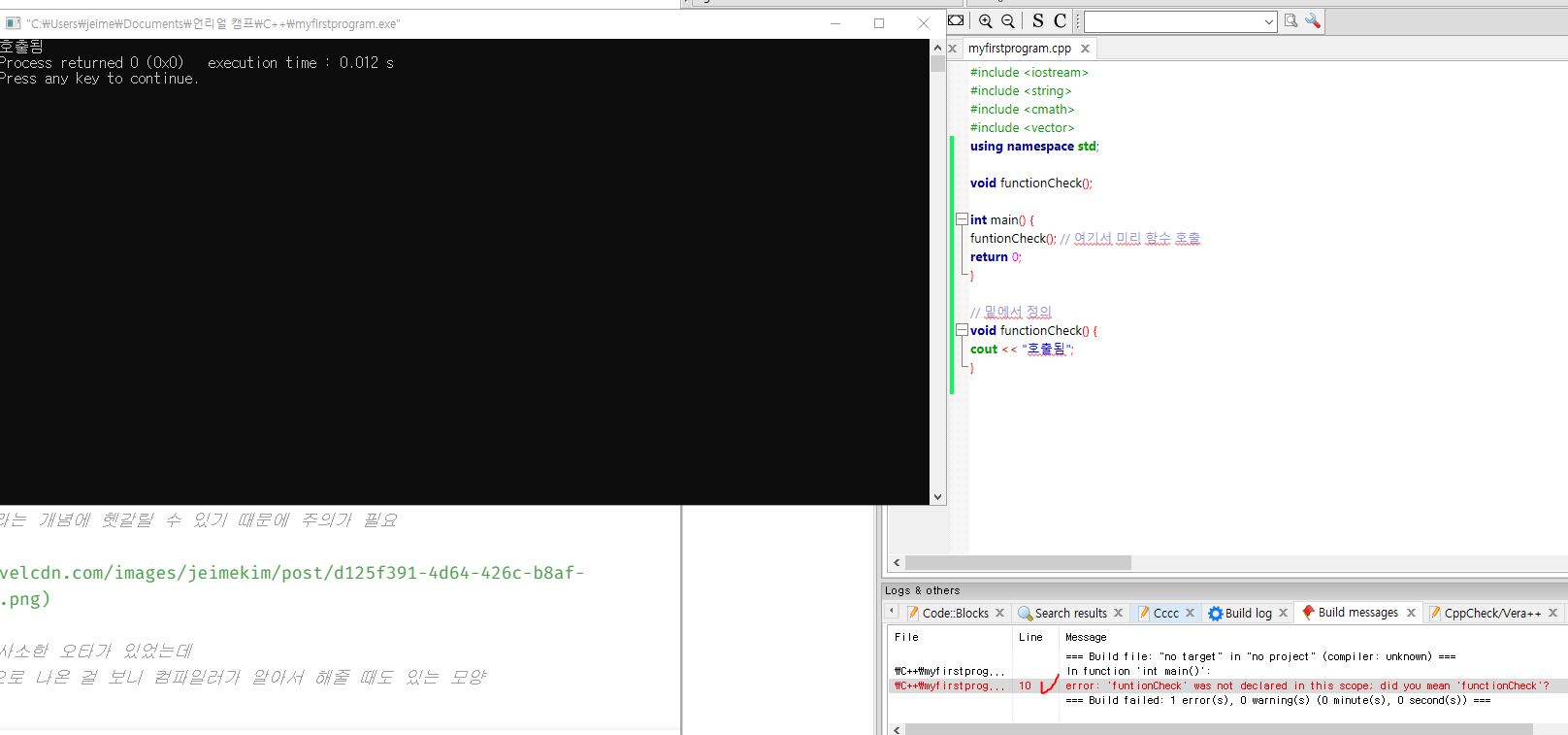
위 예시 스샷 전에 사소한 오타가 있었는데
그래도 출력은 정상적으로 나온 걸 보니 컴파일러가 알아서 해줄 때도 있는 모양
함수 파라미터
매개변수(parameters) 와 인수(arguments)
파라미터를 통해 함수에게 정보를 전달해줄수 있는데,
이 때 파라미터 는 함수 안에서 "변수처럼 작용한다"
파라미터는 함수 이름에 이어지는 () 안에 들어가며,
콤마로 구분만 해주면 개수에 딱히 제한은 없다
void 함수이름(파라미터1, 파라미터2, 파라미터3) {
// 실행코드
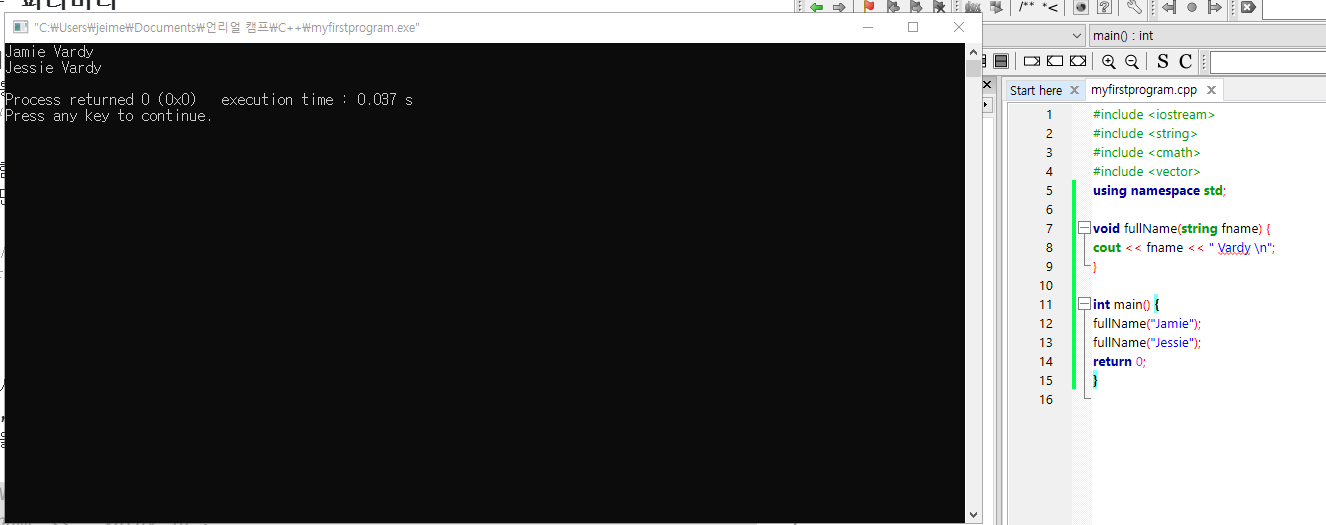
}아래 예시에서는 매개변수로 string 타입의 이름들을 주게 되며,
함수를 선언,정의 할 때 미리 파라미터로 문자열 타입의 변수를 쓸 것임을 명시하고,
파라미터로 들어온 이름을 준비된 성씨와 함께 같이 출력하는 구조이다.
void fullName(string fname) {
cout << fname << " Vardy \n";
}
int main() {
fullName("Jamie");
fullName("Jessie");
return 0;
}
파라미터가 함수로 전달되고 나면 이를
인수라고 부르게 되며,
따라서 위에서 나온 예시로 보면
fname은파라미터이고, "Jamie" 와 "Jessie" 는인수라고 보면 된다다르게 말하자면,
파라미터는 함수를 정의할 때 미리 만들어주는 "변수" 이고,
인수는 함수를 호출하면서 파라미터로 들어가는 "값 또는 데이터"
파라미터란, "함수 안의 변수로, 데이터를 받는다"
Default Parameters
함수의 파라미터를 지정하면서 "기본값" 을 설정해줄 수도 있는데
이를 통해 인수 없이 함수를 호출하더라도, 기본값이 쓰이게 된다
기본값 설정에는 = 를 활용
void myFunction(string country = "한국") {
cout << country << "\n";
}
int main() {
myFunction("일본");
myFunction("중국");
myFunction();
myFunction("러시아");
return 0;
}
이렇게 기본값을 포함한 파라미터를
"optional parameter", 선택적 매개변수라고 부른다.
Multiple Parameters
위에서 나왔듯이 함수에는 여러 개의 파라미터를 줄 수가 있다.
void myFunction(string name, int age) {
cout << name << ":" << age << " years old. \n";
}
int main() {
myFunction("Kuma", 4);
myFunction("Rance", 7);
return 0;
}
이렇게 여러개의 파라미터를 사용할 때는,
반드시 같은 수의 인수를 받아줘야 하고, 순서도 맞춰줘야 한다
라는 점에 주의.
Return Keyword
함수 과정에서 계속 나온 void 키워드는,
"이 함수가 값을 반환하지 않는다" 라는 의미를 나타내는데
만약 함수가 리턴값을 가지도록 하고 싶다면,
void 말고 "데이터 타입" 을 통해 함수를 선언 및 정의 해주면서,
함수 안에서 return 키워드로 리턴값을 적어주면 된다.
int myFunction(int x) {
return x*3;
}
int main() {
cout << myFunction(5);
return 0;
}
거듭제곱으로 실험해보고 싶었으나 불가한 이유가 있는 듯 하다
오류 메시지 상으로는 "pow()/sqrt() 함수를 호출하기엔 x가 int 가 아니기 때문에 불가" 하다고.
아래 예시와 같이 함수의 리턴값을 변수에 저장도 가능
int myFunction(int x, int y) {
return x + y;
}
int main() {
int z = myFunction(5, 3);
cout << z;
return 0;
}int doubleGame(int x) {
return x * 2;
}
int main() {
for (int i = 1; i <= 5; i++) {
cout << "Double of " << i << " is " << doubleGame(i) << endl;
}
return 0;
}
Pass By Reference
"참조 기능의 활용" 으로서,
방금 같이 '평범한' 변수와 파라미터를 사용하는 게 아니라
함수에게 "참조값"을 전달할 수도 있는데
인수의 값을 바꿔줄 필요가 있을 때 유용하다
void swapNums(int &x, int &y) { // 인수1이 x 값이 되고 인수2가 y값이 되고
int z = x; // z값에 x
x = y; // x값에 y
y = z; // y값에 z
}
int main() {
int firstNum = 17;
int secondNum = 23;
cout << "값 교환 전: " << "\n";
cout << firstNum << " | " << secondNum << "\n"
// 여기서 함수를 호출 함으로서 값이 교환됨
swapNums(firstNum, secondNum); // 이 두 값을 '참조'해서 활용
cout << "값 교환 후: " << "\n";
cout << firstNum << " | " << secondNum << "\n";
return 0;
} // 이를 통해 인수로 들어간 변수의 값을 수정하는 것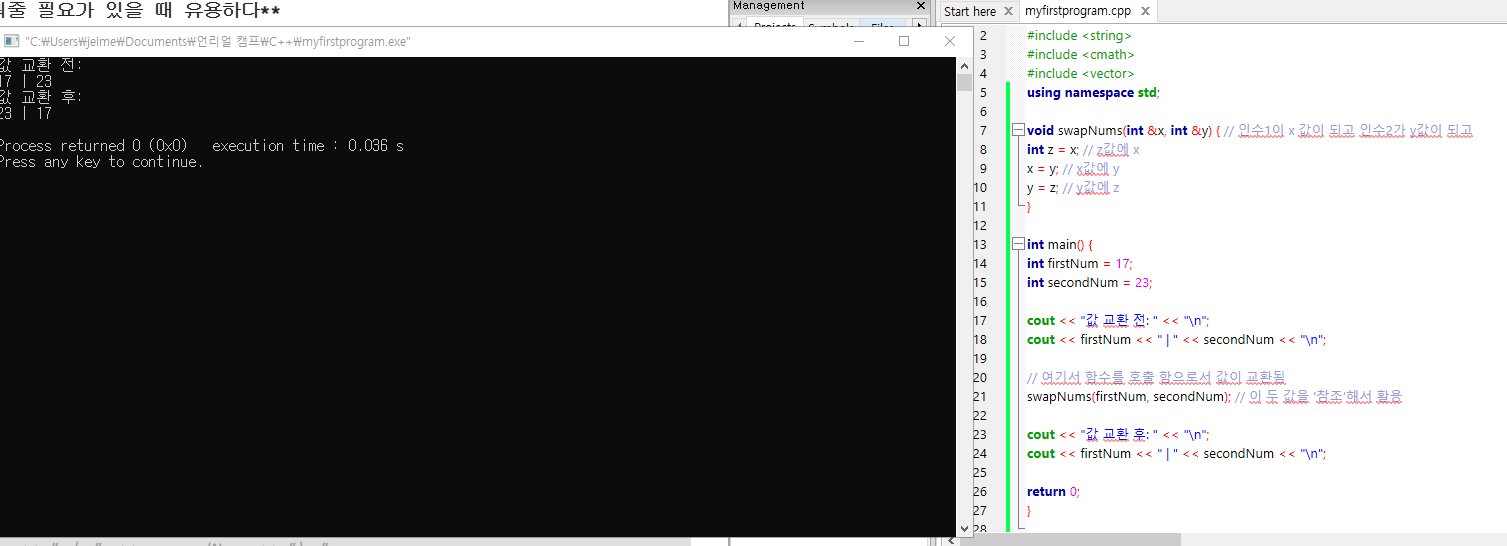
배열의 경우
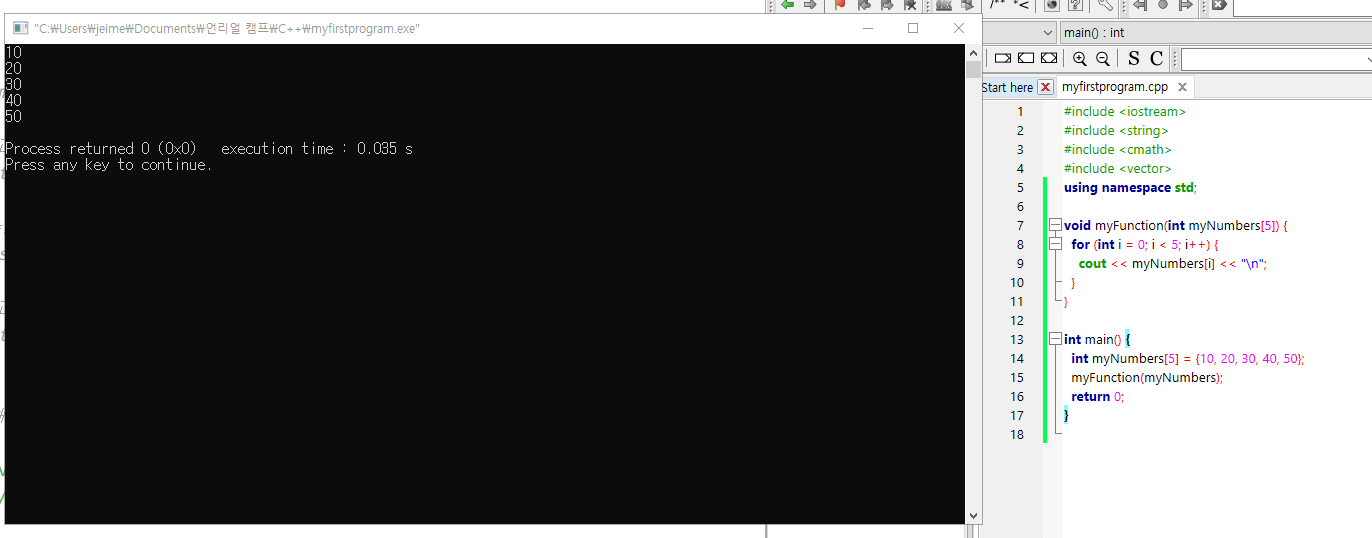
매개변수에 5짜리 배열을 지정해주고
요소 하나씩 출력하게 만든 다음,
메인함수에서 배열 값을 할당해주고
만든 함수를 호출해 하나씩 출력하게 만든 모습중요한 건,
함수를 호출할 때는
배열의 이름만 넣어주면 되지만myFunction(myNumbers);
함수를 만들때 파라미터에 배열 정의는 제대로 해줄 필요가 있다는 점
myFunction(int myNumbers[5]) {
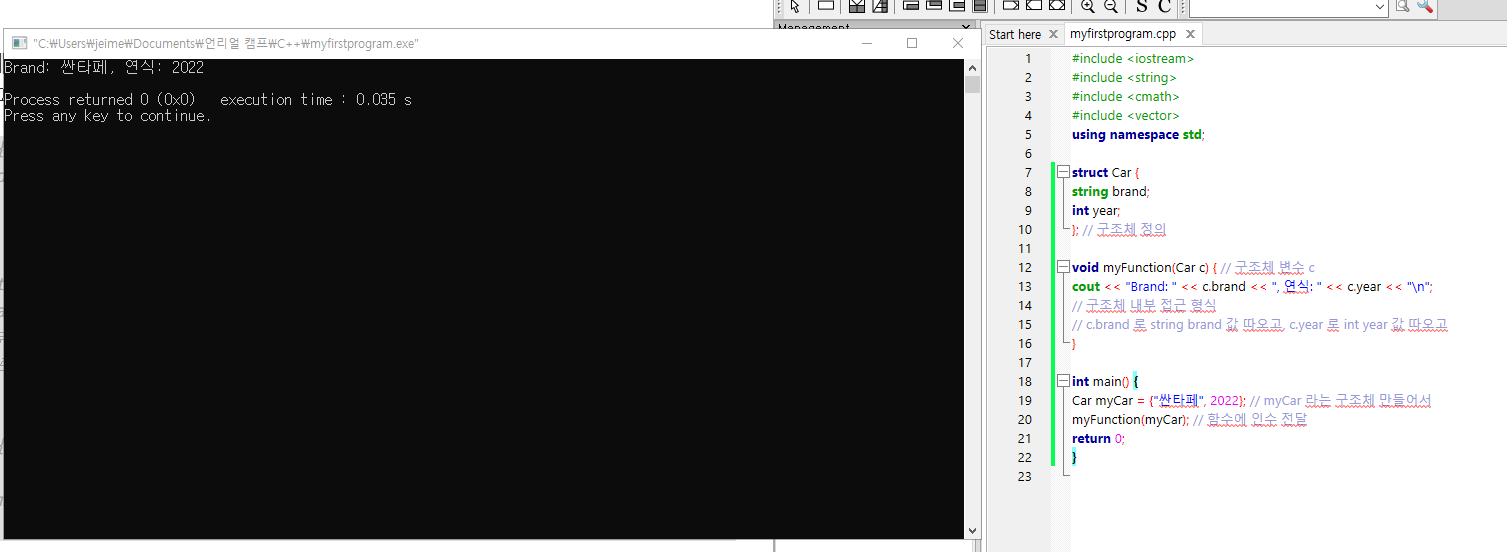
구조체의 경우
함수 안에서 그룹화된 데이터를 쓰고 싶을 때 유용.
struct Car {
string brand;
int year;
}; // 구조체 정의
void myFunction(Car c) { // 구조체 변수 c
cout << "Brand: " << c.brand << ", 연식: " << c.year << "\n";
// 구조체 내부 접근 형식
// c.brand 로 string brand 값 따오고, c.year 로 int year 값 따오고
}
int main() {
Car myCar = {"싼타페", 2022}; // myCar 라는 구조체 만들어서
myFunction(myCar); // 함수에 인수 전달
return 0;
}
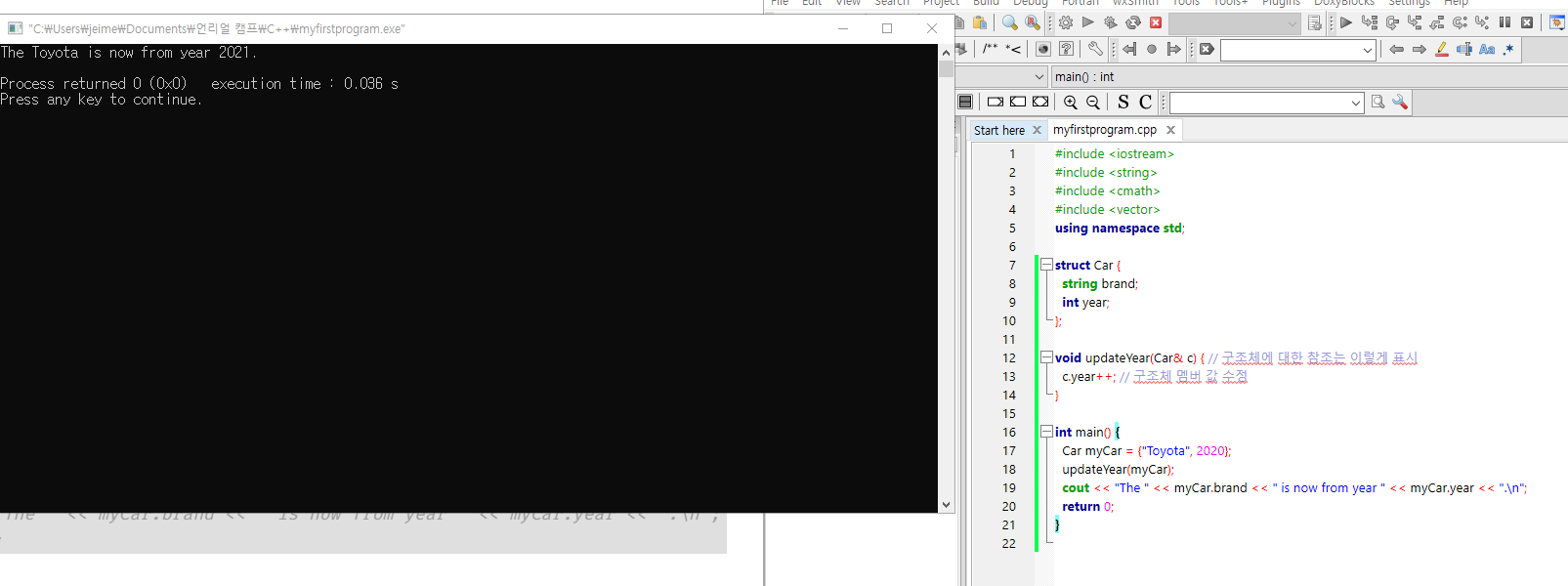
여기서도 & 를 통해 "참조" 의 활용이 가능한데
이를 통해 함수로 오리지널 데이터, 원래 값을 수정할 수 있다.
struct Car {
string brand;
int year;
};
void updateYear(Car& c) { // 구조체에 대한 참조는 이렇게 표시
c.year++; // 구조체 멤버 값 수정
}
int main() {
Car myCar = {"Toyota", 2020};
updateYear(myCar);
cout << "The " << myCar.brand << " is now from year " << myCar.year << ".\n";
return 0;
}
실생활 예제
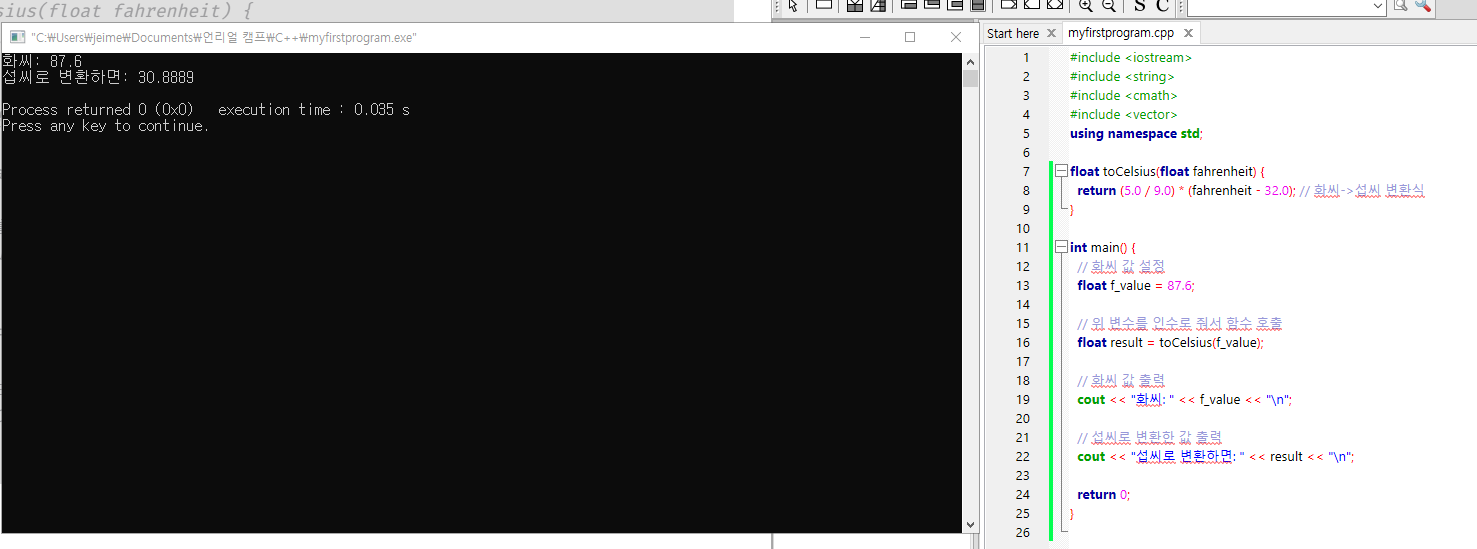
- 화씨 => 섭씨 변환
// Function to convert Fahrenheit to Celsius
float toCelsius(float fahrenheit) {
return (5.0 / 9.0) * (fahrenheit - 32.0); // 화씨->섭씨 변환식
}
int main() {
// 화씨 값 설정
float f_value = 98.8;
// 위 변수를 인수로 줘서 함수 호출
float result = toCelsius(f_value);
// 화씨 값 출력
cout << "Fahrenheit: " << f_value << "\n";
// 섭씨로 변환한 값 출력
cout << "Convert Fahrenheit to Celsius: " << result << "\n";
return 0;
}
Function Overloading
함수 오버로딩 이란,
각자의 파라미터의 데이터타입이나 개수가 다른 한,
같은 이름을 가진 함수가 여러 개 존재할 수 있도록 하는 C++ 의 기능이다.
int myFunction(int x)
float myFunction(float x)
double myFunction(double x, double y)
각자 파라미터 형태가 다르기 때문에 모두 존재 성립이 기능이 없다고 가정하고,
각각 다른 데이터타입의 숫자 2개를 더해주는 함수가 있다고 해보자
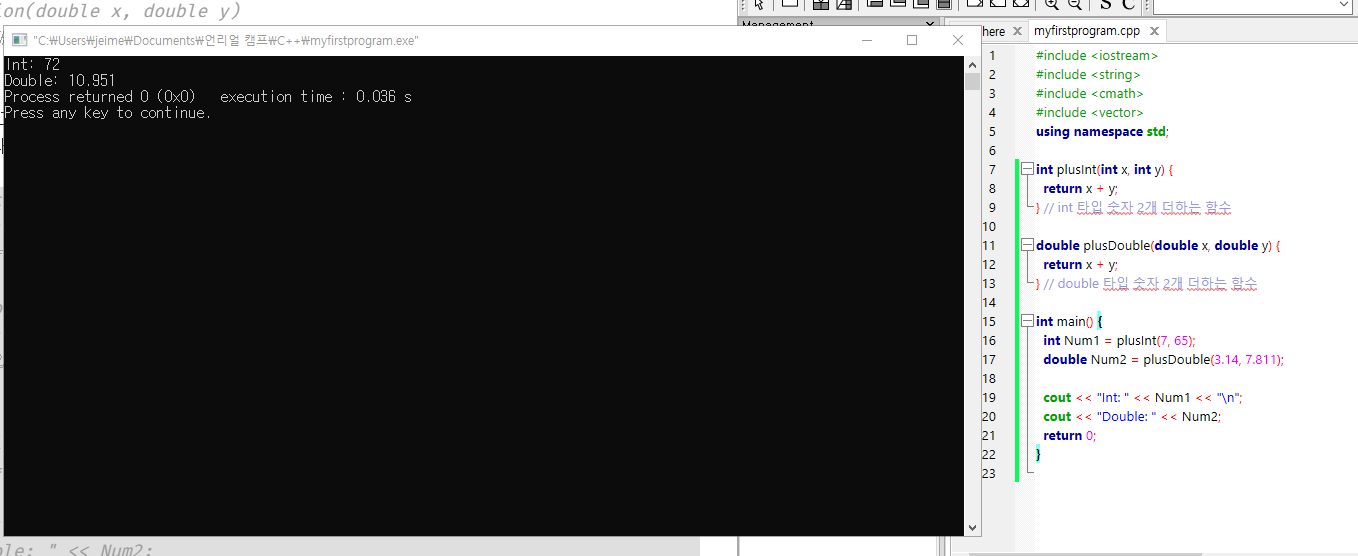
int plusInt(int x, int y) {
return x + y;
} // int 타입 숫자 2개 더하는 함수
double plusDouble(double x, double y) {
return x + y;
} // double 타입 숫자 2개 더하는 함수
int main() {
int Num1 = plusInt(7, 65);
double Num2 = plusDouble(3.14, 7.811);
cout << "Int: " << Num1 << "\n";
cout << "Double: " << Num2;
return 0;
}
이 과정의 문제점은 : 기능로직 자체는 같은데 이름이 다른 함수 2개를 만들어줘야 한다는 점
그래서 이것보다도 과정을 좀더 최적화해서,
"함수 오버로딩" 을 활용해 파라미터가 다른 같은 이름의 함수를 작성해주면
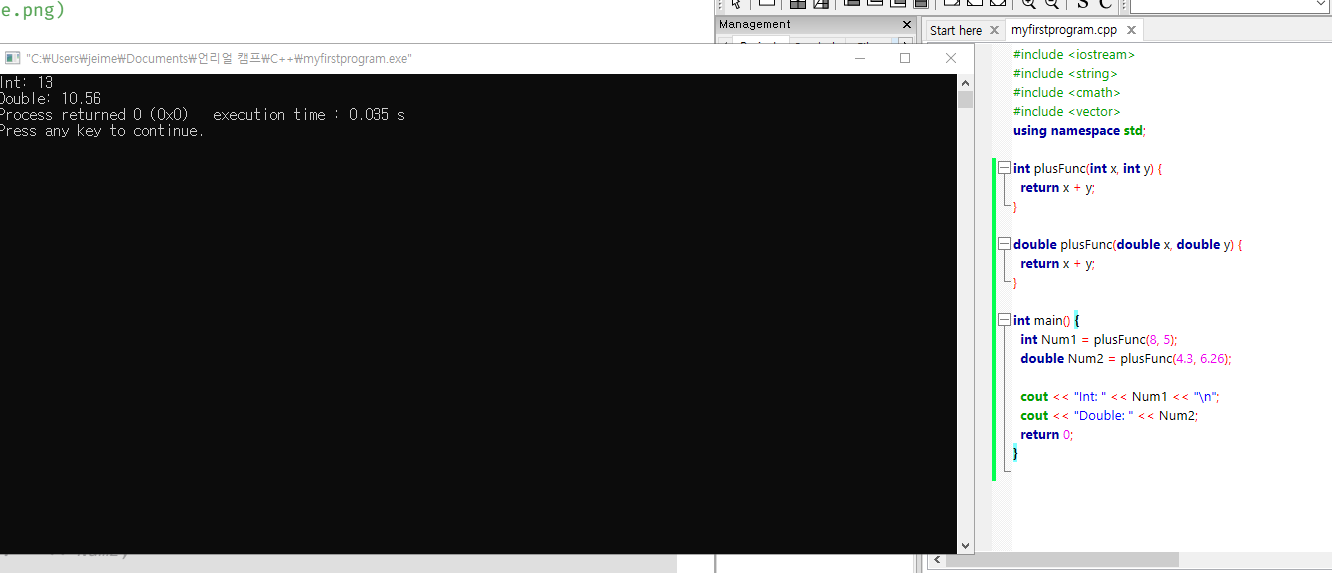
int plusFunc(int x, int y) {
return x + y;
}
double plusFunc(double x, double y) {
return x + y;
}
int main() {
int Num1 = plusFunc(8, 5);
double Num2 = plusFunc(4.3, 6.26); // 그냥 같은 이름 호출하면 된다
cout << "Int: " << Num1 << "\n";
cout << "Double: " << Num2;
return 0;
}
여기서 아래와 같이
파라미터 개수를 다르게 해서 활용하면
int plusFunc(int x, int y) {
return x + y;
}
int plusFunc(int x, int y, int z) {
return x + y + z;
}
int main() {
int result1 = plusFunc(3, 7);
int result2 = plusFunc(1, 2, 3);
cout << "Sum of 2 numbers: " << result1 << "\n";
cout << "Sum of 3 numbers: " << result2;
return 0;
}인수가 2개 들어오건 3개 들어오건 '같은 이름의' 함수를 호출할 수 있게 되는 것
Variable Scope
함수를 배웠으니 이제 알아야할 것은,
"변수"는 함수의 '안'과 '밖'에서 다르게 작용한다는 것이다.
C++ 에선, 변수는 만들어진 그 범위 안에서만 작동하고, 이를 스코프(scope) 라고 한다.
함수 안에서 만들어진 변수는
그 함수의 local scope 에 소속되며,
해당 함수를 벗어나면 작동하지 않는다.
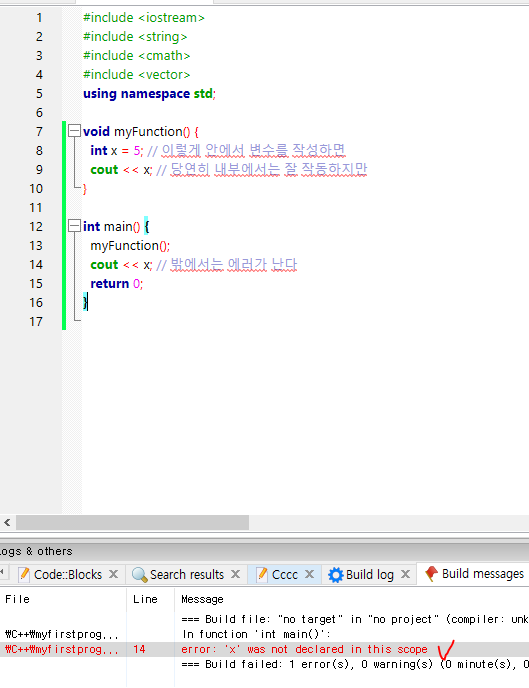
자주 나오는 로컬/글로벌 개념
void myFunction() {
int x = 5; // 이렇게 안에서 변수를 작성하면
cout << x; // 당연히 내부에서는 잘 작동하지만
}
int main() {
myFunction();
cout << x; // 밖에서는 에러가 난다
return 0;
}
반면 함수 밖에서 생성된 변수는, 글로벌 변수 라고 불리며
global scope에 소속되며
이 글로벌 변수는 프로그램 어디서든 사용 가능하다
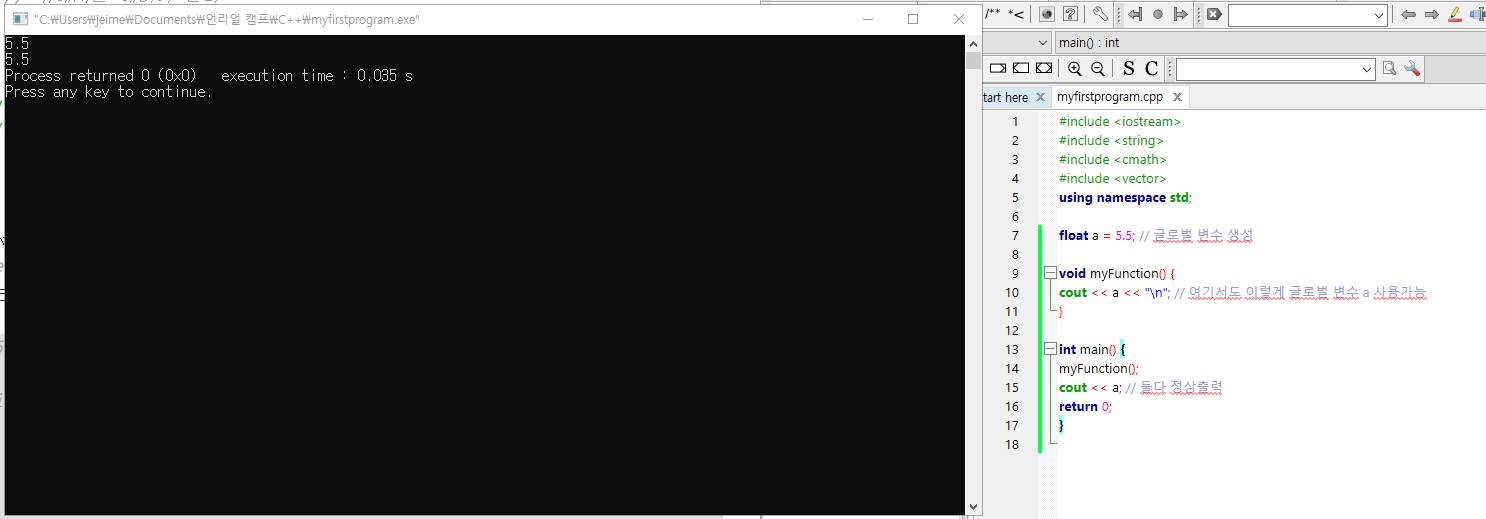
float a = 5.5; // 글로벌 변수 생성
void myFunction() {
cout << a << "\n"; // 여기서도 이렇게 글로벌 변수 a 사용가능
}
int main() {
myFunction();
cout << a; // 둘다 정상출력
return 0;
}
이 개념에서 유의할 부분은,
이름이 같은 변수라도 함수 내/외부, 로컬/글로벌 이 다르게 작동할 수 있다는 점이다.
아래와 같은 경우 변수 이름이 x로 같지만,
함수 내부의 로컬 변수 x 와 함수 외부의 글로벌 변수 x로
두 개의 별개 변수로 취급된다.
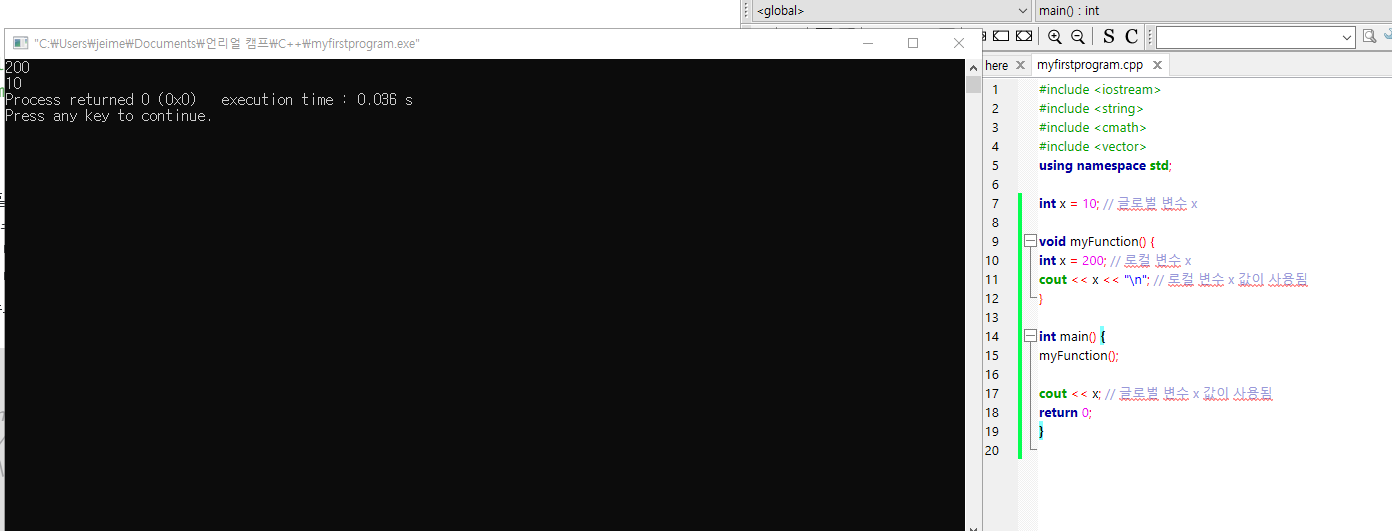
int x = 10; // 글로벌 변수 x
void myFunction() {
int x = 200; // 로컬 변수 x
cout << x << "\n"; // 로컬 변수 x 값이 사용됨
}
int main() {
myFunction();
cout << x; // 글로벌 변수 x 값이 사용됨
return 0;
}
하지만, 혹시 모를 에러와
혼란 방지를 위해 위와 같이 같은 이름의 변수를 사용하는 건 최대한 지양해야 한다.
또한, 글로벌 변수는 프로그램 내 어디서든 액세스해서 수정할 수 있는 만큼,
취급에 주의가 필요하다.
int x = 5;
void myFunction() {
cout << ++x << "\n"; // Increment the value of x by 1 and print it
}
int main() {
myFunction();
cout << x; // Print the global variable x
return 0;
}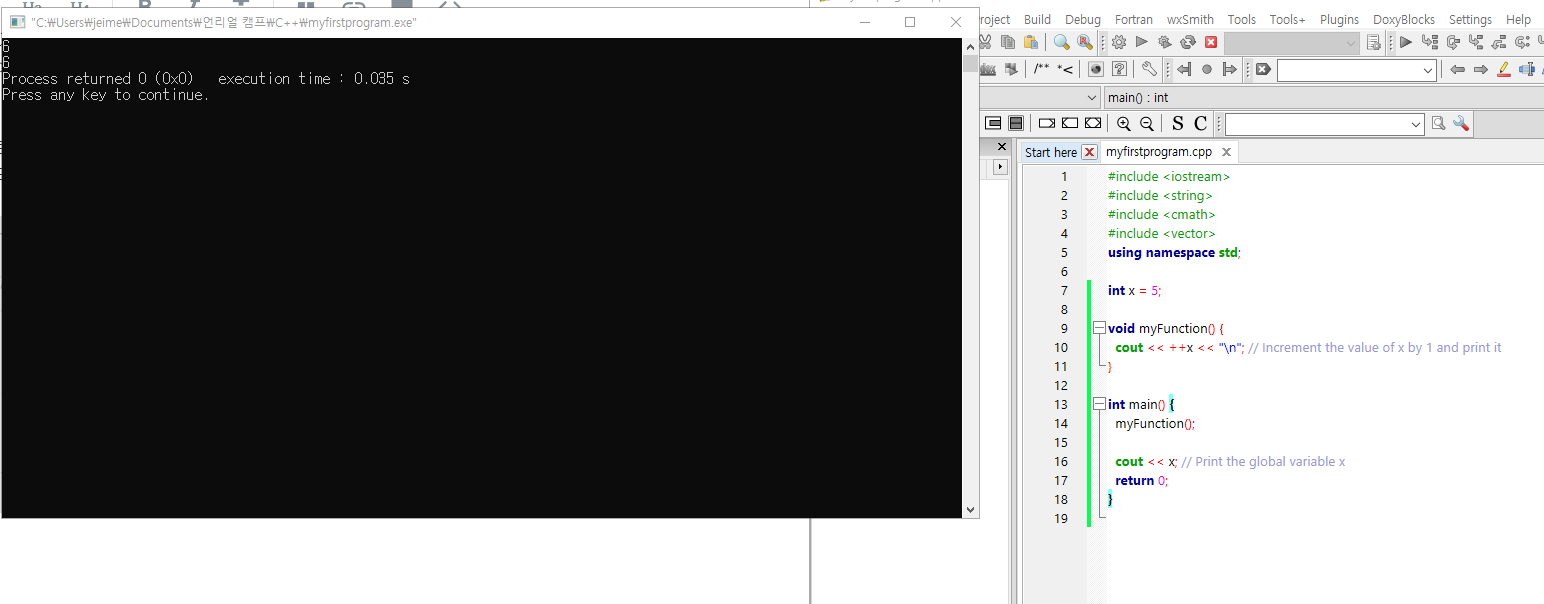
함수 안에서 글로벌 변수 x의 값이 수정되었기 때문에
함수 밖에서 출력해도 이미 수정된 값이 나온다.
※ 요약하자면,
코드를 더 쉽고 유지보수 가능하게 만들기 위해
가능한 알기쉽고 적절한 이름을 가진 로컬 변수를 애용하라는 얘기다.
혹시 기존 C++ 프로그램이나 다른 사람과 협업할 때
글로벌 변수를 발견하면, 이 scope 개념을 통해
코드가 어떻게 작동하는지 확인하는 것도 중요하다.
Recursion
(recursion) 재귀 라는 기능은,
함수가 스스로를 호출하도록 하는 일종의 테크닉이다.
이 기술은 복잡한 문제를 보다 쉽게 해결할 수 있는 간단한 문제들로
'세분화'할 수 있게 해준다.
예시)
단순히 숫자 2개를 더하는 것은 쉽지만
일정 범위의 숫자를 더하는 것은 더 복잡하기 마련.
이때 재귀 를 활용해서 범위를 더하는 것을
세분화해 2개 숫자를 더하는 방식으로 나누어서 적용할 수 있다
int sum(int k) {
if (k > 0) {
return k + sum(k - 1); // 인수 + 이전 함수 결과
} else {
return 0;
}
}
int main() {
int result = sum(10);
cout << result;
return 0;
}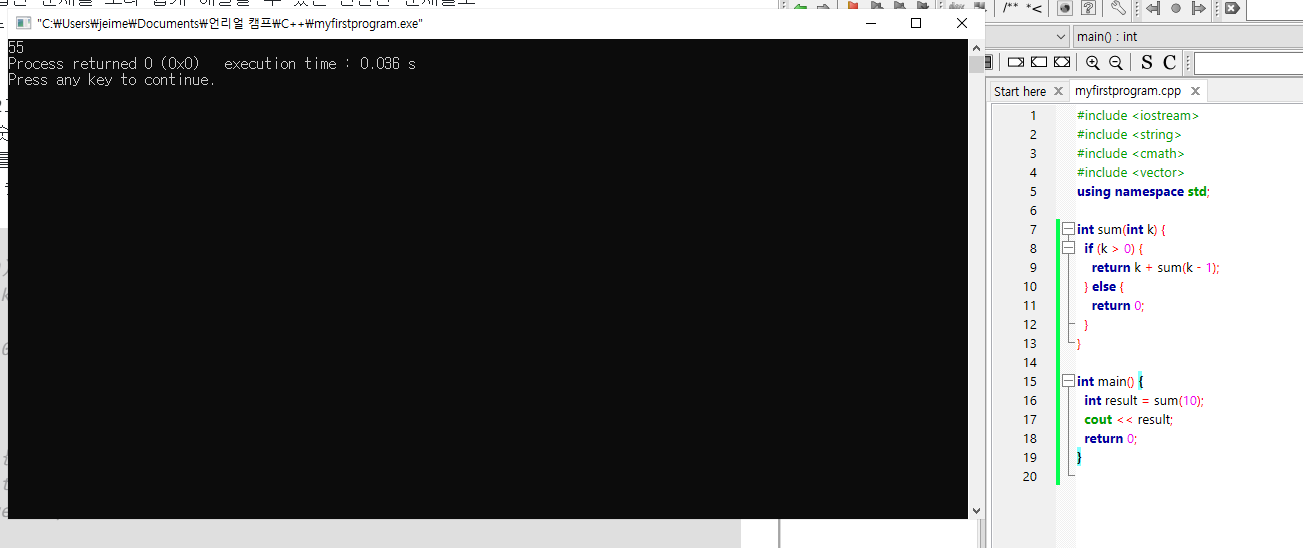
sum() 함수를 호출하게 되면 :
이 파라미터 k 가 1 씩 작아지면서 재귀 기능을 통해 sum() 을 다시 호출한다
10 + sum(9)
10 + ( 9 + sum(8) )
10 + ( 9 + ( 8 + sum(7) ) )
...
10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 + sum(0)
10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 + 0
비슷한 예로)
'팩토리얼' 을 구하는 방법도 있다
#include <iostream>
using namespace std;
int factorial(int n) {
if (n > 1) {
return n * factorial(n - 1);
// 5 * factorial(4)
// 5 * 4 * factorial(3)
// ...
// 5 * 4 * 3 * 2 * factorial(1) = 1
} else {
return 1;
}
}
int main() {
cout << "Factorial of 5 is " << factorial(5);
return 0;
}Lambda Functions
람다 함수 는 내가 쓰고 있는 코드에 바로 다이렉트로 넣을 수 있는
"익명적인, anonymous" 함수로,
별도로 이름을 붙이거나 선언할 필요가 없는,
빠른 기능이 필요할 때 유효한 함수다.
일종의 미니 함수
[capture] (parameters) { code };위와 같은 형태를 가지는데,
capture 에 대해서는 지금은 신경쓰지 말고 그냥 빈 괄호로 냅두면 된다
기본 람다 예시)
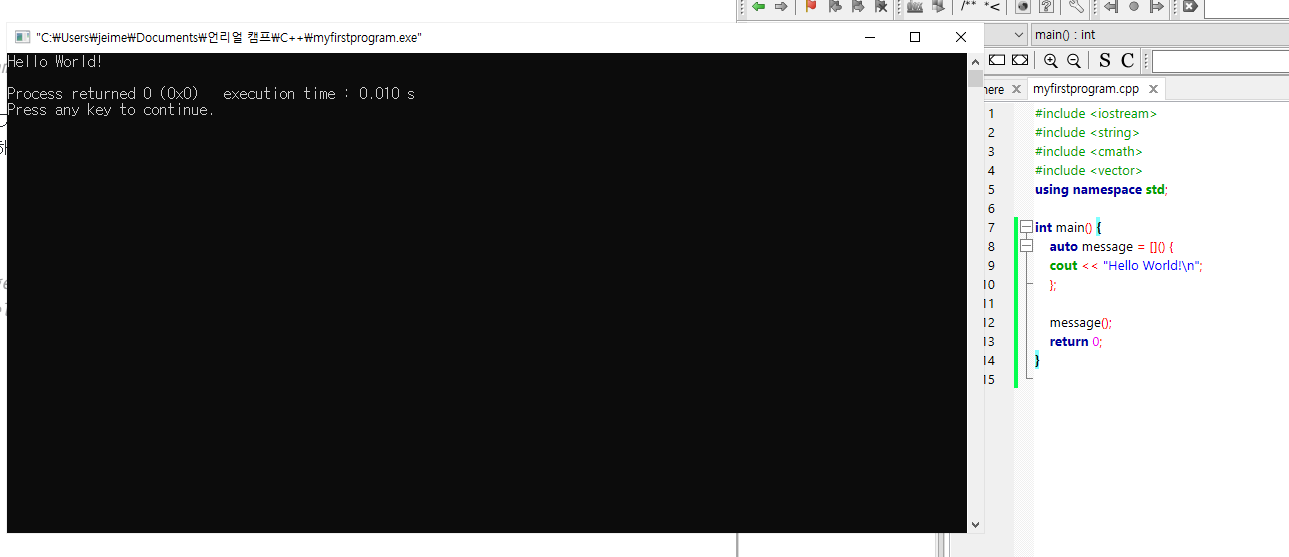
int main() {
auto message = []() {
cout << "Hello World!\n";
};
message();
return 0;
}
다른 일반적인 함수와 같이
람다 함수에 파라미터 값=인수 를 줄 수도 있다
#include <iostream>
using namespace std;
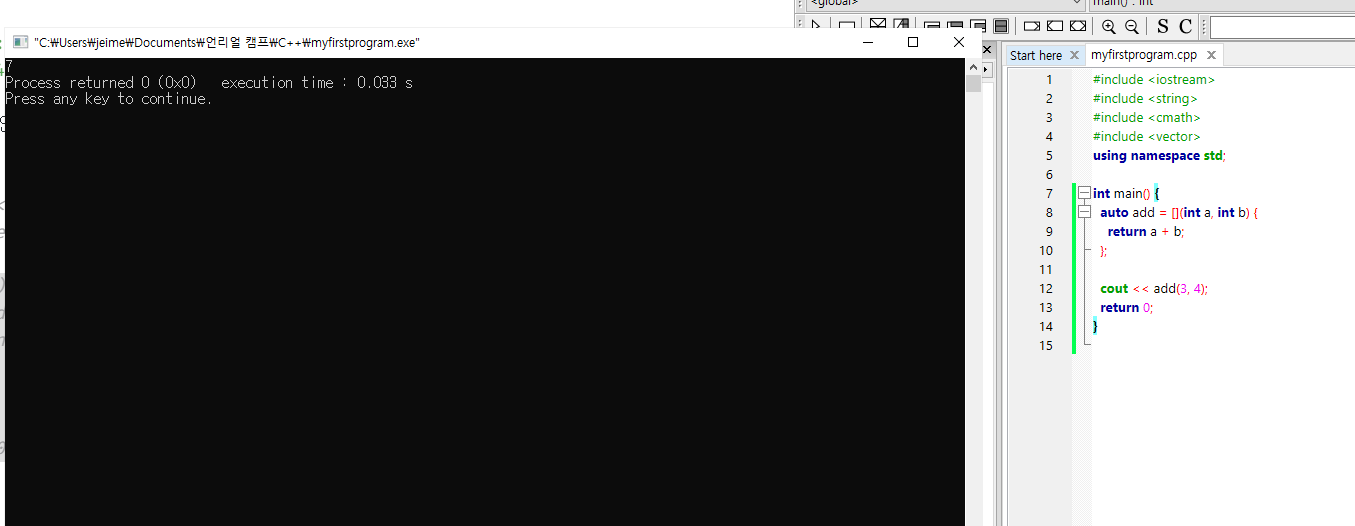
int main() {
auto add = [](int a, int b) {
return a + b;
};
cout << add(3, 4);
return 0;
}
람다를 함수에 전달하기
람다함수를 다른 함수에 인수 로서 전달할 수도 있는데,
이는 함수에게 데이터만 전달하는 게 아니라
"무엇을 할지" 전달하고 싶을 때 유용한 기능이다
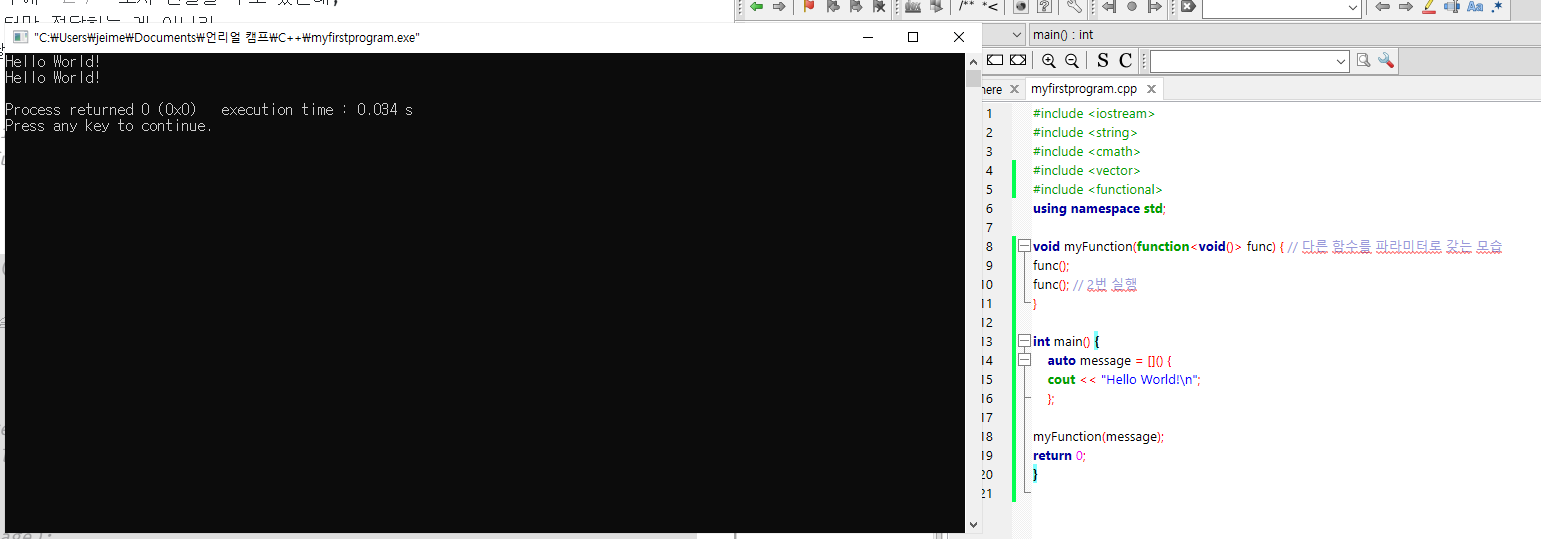
아래 예시를 보면, 다른 함수에 람다함수를 전달하면서, 2번 실행되게 만들어준다
#include <functional> // 이 라이브러리가 필요하다
// 싫다면 std::function 식으로
...
void myFunction(function<void()> func) { // 다른 함수를 파라미터로 갖는 모습
func();
func(); // 2번 실행
}
int main() {
auto message = []() {
cout << "Hello World!\n";
};
myFunction(message);
return 0;
}
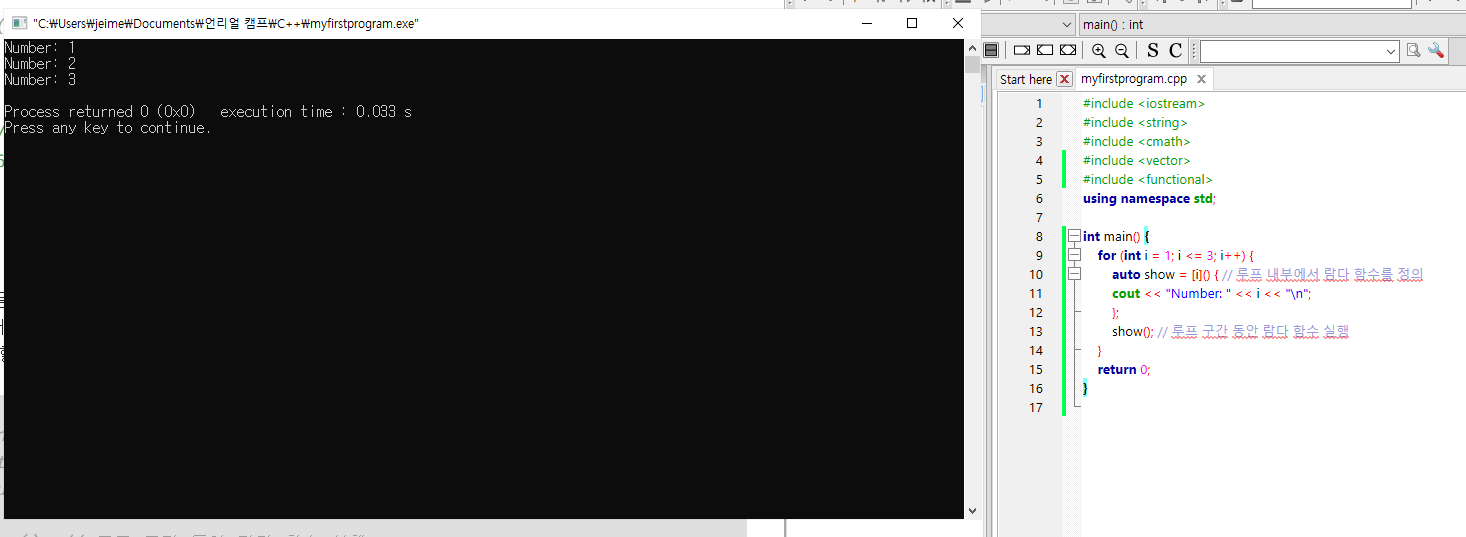
루프 활용
루프 내부에서 람다 함수를 정의하고 사용함으로써,
빠른 동작을 할수 있도록 만들 수 있다
int main() {
for (int i = 1; i <= 3; i++) {
auto show = [i]() { // 루프 내부에서 람다 함수를 정의
cout << "Number: " << i << "\n";
};
show(); // 루프 구간 동안 람다 함수 실행
}
return 0;
}
Capture Clause
[] 대괄호를 통해 람다 가 외부의 변수에 접근할 수 있게 되는데,
이를 capture clause 라고 부른다
아래 예시에서, 람다는 값(복사본) 을 기준으로 변수 x 를 "포착"한다
int main() {
int x = 10;
auto show = [x]() { // 외부 변수 x 에 접근
cout << x; // x 출력
};
show();
return 0;
}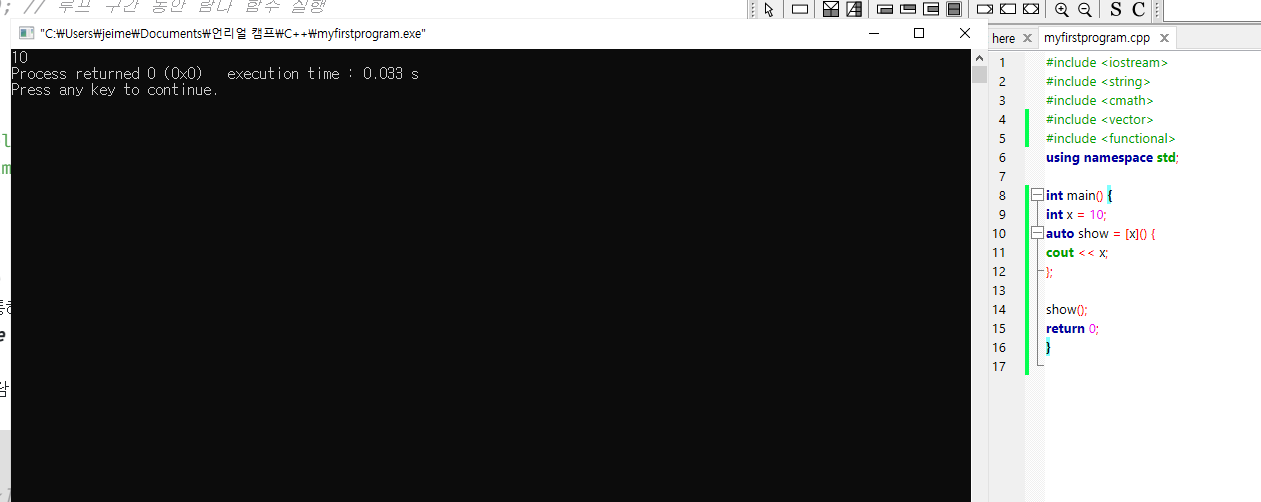
람다는 변수 "x" 의 복사본을 사용하며,
이는 람다 함수 이후에 x 의 값을 바꿔주더라도,
람다 내부에는 영향을 미치지 않는다는 것을 의미한다.
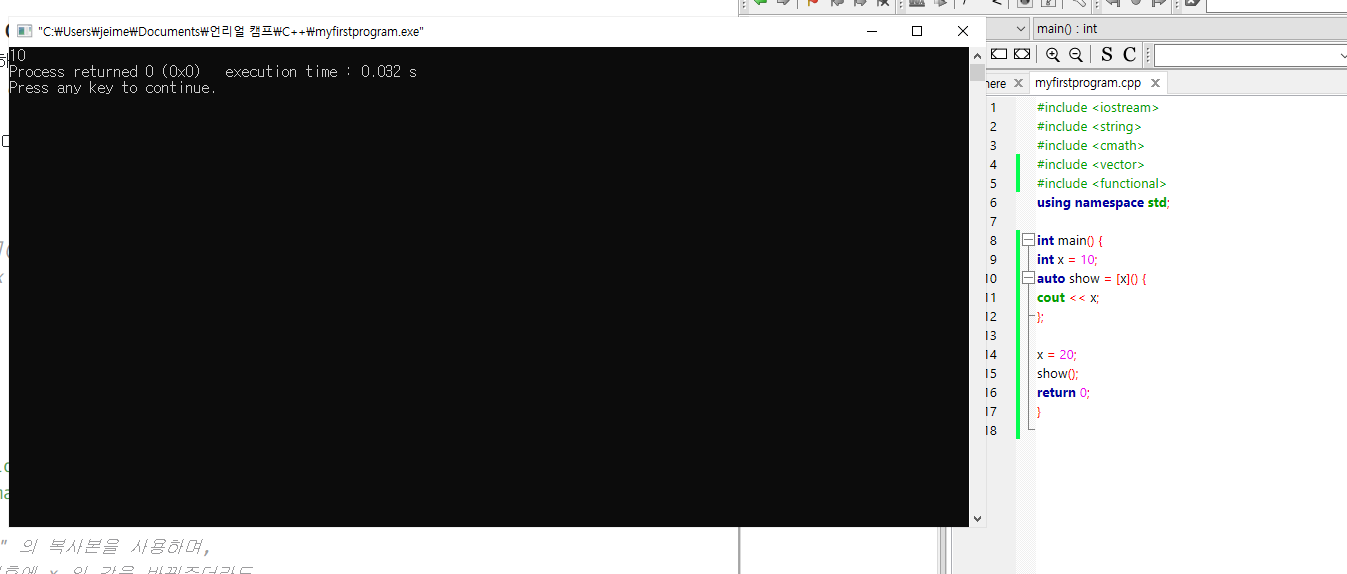
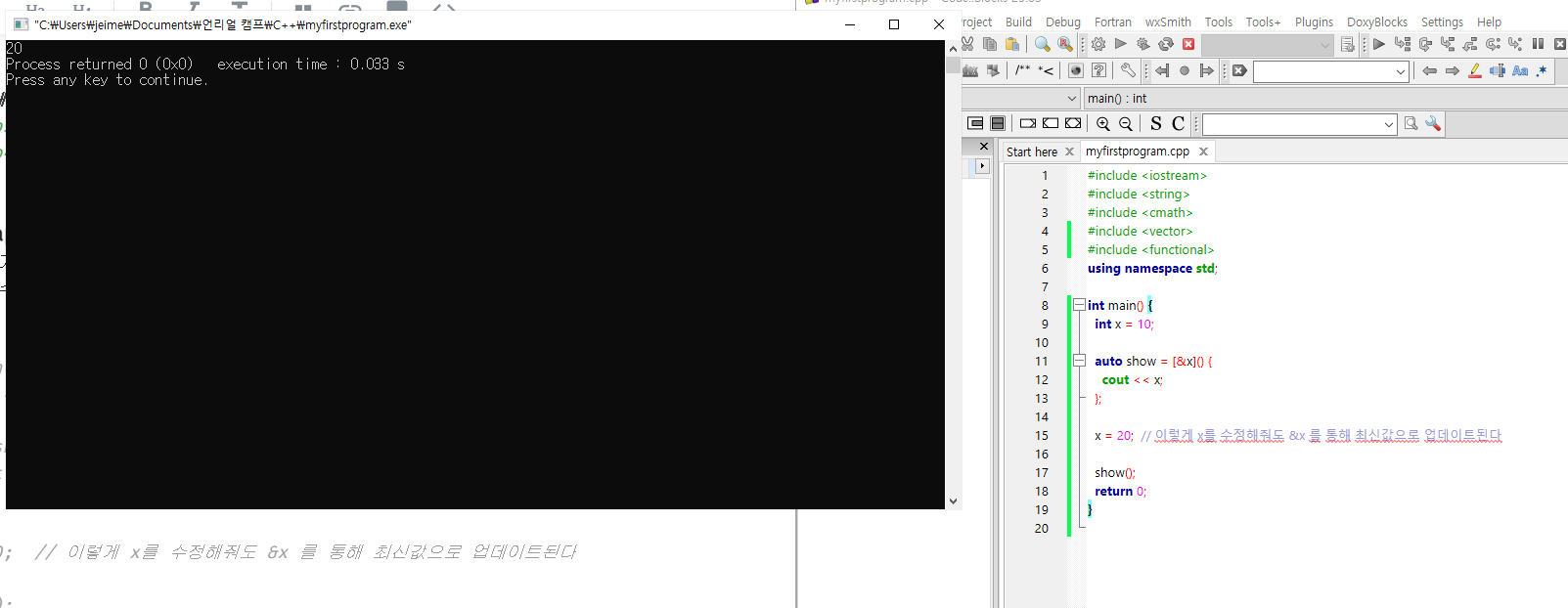
Capture by Reference
위와 다르게,
람다가 변수의 최신값(단순 복사본이 아닌) 을 사용하게 하고 싶다면
[&] 를 사용해 참조를 활용해주면 된다.
int main() {
int x = 10;
auto show = [&x]() {
cout << x;
};
x = 20; // 이렇게 x를 수정해줘도 &x 를 통해 최신값으로 업데이트된다
show();
return 0;
}
일반 함수 vs 람다 함수
두 함수 모두
"코드를 그룹화해서" "나중에 실행할 수 있도록"
한다는 점에선 같지만, 쓰임새가 약-간 다르다
1) 일반 함수를 써야 할 때:
- 여러 장소에서 재사용할 함수
- 함수에게 명료하고 의미있는 이름을 부여하고 싶을 때
- 로직이 길고 복잡할 때
2) 람다 함수를 써야 할 때:
- 함수를 한번만 쓸 것임
- 코드가 짧고 간단
- 다른 함수에게 빠른 함수를 전달하고 싶을 때
ex) 아래 예시는 같은 동작을 한다
int add(int a, int b) {
return a + b;
}auto add = [](int a, int b) {
return a + b;
};만약 다시 사용할 일이 없다면 람다 함수가 최적.
빠르기도 하고
코드 블럭 안에서나 다른 함수의 인수로서도 잘 동작하기 때문
