자원 관리하기
컴퓨터에서 자원이란 = "메모리"를 의미한다
이 메모리를 어떻게 관리해야 하는가?
- 메모리 누수와 자원 관리의 중요성
- 동적 메모리의 할당 및 해제를 적절히 수행하여
메모리를 효율적으로 관리 - 스마트 포인터와 같은 C++ 자원 관리 도구를 화용하여
안정적인 코드를 작성 - 언리얼 엔진에서 자원을 관리하는 과정
예시로 '옷장'을 생각했을 떄,
옷장의 공간은 물리적으로 한정 되있고,
옷을 계속 넣게 되면 결국 공간이 가득차
더이상 옷을 넣을 수 없게 되는 순간이 온다.
억지로 더 넣으려고 하면 기존의 옷이 쏟아지기 마련.
컴퓨터 메모리도 이와 비슷하게,
메모리는 한정된 자원이므로 효율적으로 활용하기 위한 고민이 필요하다.
메모리는 크게 스택 메모리 / 힙 메모리 로 나뉜다.
스택 메모리
일반 변수들은 대부분 "스택 메모리 공간" 에 들어간다.
이 스택 메모리 의 가장 큰 특징은:
변수의 생존 주기가 끝나면
선언 시 할당되었던 메모리가 자동으로 회수된다.
=> 사용자가 직접 메모리를 해제해 줄 필요가 없다.

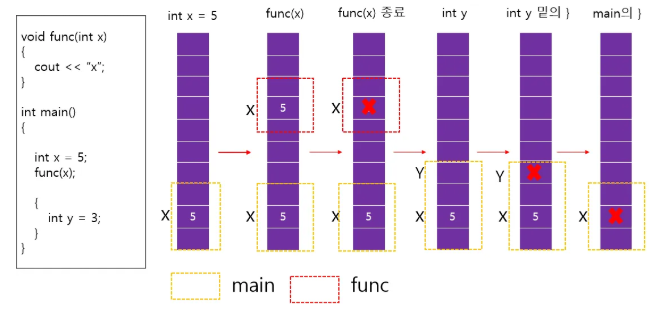
위 그림을 통해 가볍게 생각하면,
{} 를 따라 메모리의 할당과 제거가 행해진다고 보면 된다.
func(x)의 메모리가 { 시작할 때 잡혀서~
} 닫힐 때 메모리도 제거되고
아래 마찬가지로 { 열릴 때 y 메모리 공간이 생겼다가
} 닫힐 때 같이 제거된다.
간단하게 생각하면 힙 메모리에 해당하는 경우 외에는
대부분 "스택 메모리" 라고 생각하면 된다. (함수 안의 인자나 변수 등등)
예시들)
#include <iostream>
using namespace std;
void func1() {
int a = 10; // 지역 변수 'a', stack 메모리에서 관리됨
cout << "func1: a = " << a << endl;
} // func1()이 종료되면 'a'는 소멸됨
int main() {
func1(); // func1() 호출
// 'a'는 func1() 호출 중에만 존재하고, 함수 종료 후 소멸됨
return 0;
}#include <iostream>
using namespace std;
void func3() {
for (int i = 0; i < 3; ++i) { // 반복문 안에서 지역 변수 'i'가 매번 새로 생성됨
int temp = i * 10; // 반복문 안에서만 유효한 'temp'
cout << "Iteration " << i << ": temp = " << temp << endl;
} // 반복문 끝날 때마다 'temp'는 소멸됨
}
int main() {
func3(); // func3 호출
return 0;
}#include <iostream>
using namespace std;
void func2() {
int b = 20; // 지역 변수 'b', stack 메모리에서 관리됨
cout << "func2: b = " << b << endl;
}
void func1() {
int a = 10; // 지역 변수 'a', stack 메모리에서 관리됨
cout << "func1: a = " << a << endl;
func2(); // func2() 호출
} // func1() 종료 시 'a'는 소멸되고, func2() 종료 후 'b'도 소멸됨
int main() {
func1(); // func1() 호출
return 0;
}힙 메모리
"스택 메모리"는 방금까지 나온
메모리를 자동으로 회수해 주는 게 장점이지만,
'단점'들도 몇가지 있는데:
-
일반적으로 할당 가능한 크기가 제한적:
(힙 메모리는 무한대로 크다는 게 아니라)
가능한 메모리 크기가 스택 < 힙(heap) -
변수의 스코프(scope, 생존영역, 범위) 를 벗어나면
자동으로 해제되기 때문에 = 장점이자 단점
메모리를 더 길거나 유연하게 관리하기 어렵다
그래서 이런 단점들을 보완하기 위해 힙 메모리 = 동적 메모리를 쓰는데
1) 동적 할당 시 new 연산자를 사용하고, 해제 시 delete 를 사용
2) 스택 메모리와 달리 자동으로 해제되지 않기 때문에
**"메모리 누수"의 위험이 있다
3) 동적 할당된 객체(또는 변수)의 생존 주기는
delete로 해제할 때까지 유지된다.

new 연산자는 "주소값" 을 반환한다!!
=> 포인터 로 받아야 한다
ex) int* ptr = new int(10);
예시들)
#include <iostream>
using namespace std;
void func1() {
int* ptr = new int(10); // 힙 메모리에 정수 10 할당
cout << "Value: " << *ptr << endl;
delete ptr; // 메모리 해제
}
int main() {
func1();
return 0;
}#include <iostream>
using namespace std;
void createDynamicArray() {
int size;
cout << "Enter the size of the array: ";
cin >> size; // 배열 크기를 사용자로부터 입력받음
if (size > 0) {
int* arr = new int[size]; // 입력받은 크기만큼 동적 배열 생성
for (int i = 0; i < size; ++i) {
arr[i] = i * 2; // 배열 초기화
cout << "arr[" << i << "] = " << arr[i] << endl;
}
delete[] arr; // 동적으로 할당한 배열 메모리 해제
} else {
cout << "Invalid size!" << endl;
}
}
int main() {
createDynamicArray();
return 0;
}배열 예시를 보면 알 수 있지만
동적 할당 선언할 때 타입도 알 수 있도록 명시가 된다.
ex) int* arr = new int[5] delete[] arr
또한 이렇게 사용자 입력이 필요한 코드에서
힙 메모리의 장점이 드러나는 게:
스택 메모리의 경우는 실행 전에 크기가 결정되지만,
힙 메모리는 코드를 실행하고 size 를 받아서 그때 새롭게 힙 메모리에 할당할 수 있다는
그런 이점이 있다.
다만 계속 "주의해야 할 점이":
메모리 해제를 꼭 해줘야 한다는 점
Dangling Pointer
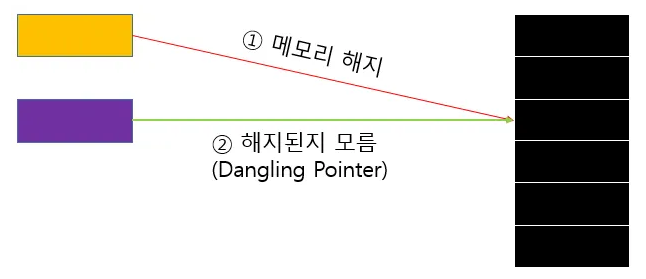
C++ 에서 자주 사용하는 유용한 기능인 "포인터"는,
앞서 활용한 방법처럼 메모리를 동적으로 할당했다가 해지할 경우,
메모리가 해제되었는지 어떤 상태인지를 자동으로 파악할 수가 없다.
그래서 이미 사라진 메모리의 주소를 계속 가지고 있는 포인터를 사용하는 것은
매우 위험한데, 이런 포인터를 Dangling Pointer 라고 부른다.
#include <iostream>
using namespace std;
void func5() {
int* ptr = new int(40); // 힙 메모리에 정수 40 할당
int* ptr2 = ptr;
cout << "ptr adress = " << ptr << endl;
cout << "ptr2 adress = " << ptr2 << endl;
cout << *ptr << endl;
delete ptr;
cout << *ptr2 << endl; // ptr 을 복사했기 때문에 빈 메모리를 보고있음
}
int main() {
func5();
return 0;
}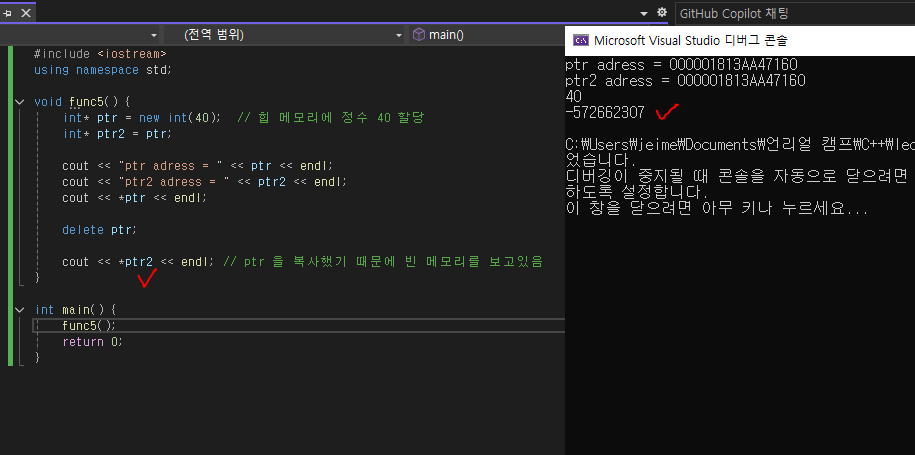
해제된 주소의 값을 read, 읽기만 했기 때문에 정상출력은 되지만
write 하는 제어 단계까지 가게되면 문제가 생긴다!
#include <iostream>
using namespace std;
void func4() {
int* ptr = new int(30); // 힙 메모리에 정수 30 할당
cout << "Value: " << *ptr << endl;
delete ptr; // 첫 번째 해제
// delete ptr; // 두 번째 해제 (코드 활성화 시 문제 발생)
}
int main() {
func4();
return 0;
}Memory Leak(메모리 누수)
위에서도 언급했지만,
동적으로 할당한 메모리들을 사용 후에
delete 등을 통해 해제해 주지 않으면,
계속해서 메모리가 누적되어 쌓이게 된다.
이런 상황이 계속 이어지다 보면,
프로그램이 점점 더 많은 메모리를 차지하게 되면서
사용할 수 있는 메모리가 부족해 지게 된다.
=> 이 현상을 메모리 누수(Memory Leak) 라고 부른다.
스마트 포인터
이렇게 힙 메모리 와 동적 할당은 다양한 장점들이 있지만,
dangling pointer 의 발생문제를 줄일 필요가 있기 때문에,
C++에서는 이를 자동으로 관리하기 위한 "스마트 포인터" 를 제공한다.
이 스마트 포인터 의 핵심 원리는:
new/delete를 "사용하지 않는" 자동 메모리 관리!
기본적인 delete 호출을 통한 메모리 관리 방식 대신,
각 스마트 포인터의 목적에 맞게 자동으로 메모리 관리를 도와준다.
-
unique_ptr은 객체에 대한 단일 소유권을 관리한다. // unique = 고유
: 객체의 소유권을 명확히 하며,
소유권 이전을 통해 효율적인 자원관리가 가능.
move를 통해 소유권을 이전할 수 있다.
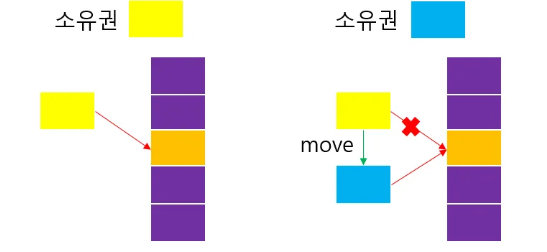
-
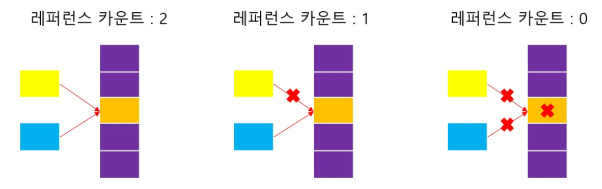
shared_ptr은 레퍼런스 카운트를 관리한다.
: "레퍼런스 카운트" 란 = "현재 객체를 참조하는 포인터의 개수"를 세는 것.
레퍼런스 카운트는 내부에서 알아서 관리되며,
이 레퍼런스 카운트가 -> 0이 되면 자동으로 메모리가 해제된다.
-
weak_ptr은 객체의 소유권을 공유하지 않는다.
: 다른 스마트 포인터와 다르게
"레퍼런스 카운트를 증가시키지 않는 약한 참조"를 걸어주는데,
2번의 shared_ptr 는 유용하지만 "순환참조"가 발생할 수 있기 때문.
순환 참조
= 두 개 이상의 객체가 서로를 shared_ptr로 가리켜 참조하는 상황
메모리 누수를 유발할 수 있음
서로 순환하고 있는 shared_ptr중
하나를 weak_ptr로 대체하면
순환 고리가 끊어지게 되므로 순환참조 가 발생하지 않는다!
좀 더 간단하게 표현하자면:
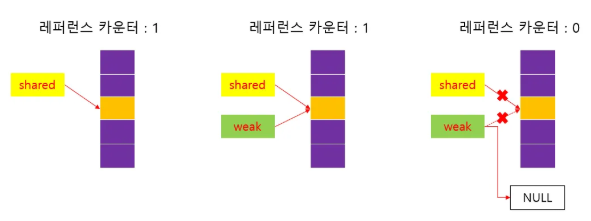
shared_ptr 은 관찰과 소유를 하는 반면,
weak_ptr 은 관찰만 한다.
같은 곳을 참조하던 shared_ptr 이 사라지게 되면,
weak_ptr 은 자동으로 참조가 해제되며 null을 가리키게 된다.
unique_ptr
객체의 소유권을 관리하는 스마트 포인터 로,
= '단 하나'의 포인터만 객체를 소유할 수 있다
객체 : 포인터 -> 1대1 대응
1) "소유권" 의 개념만 있기 때문에
복사 혹은 대입이 불가능하다. = 이걸 시도하는 순간 컴파일 에러 발생
#include <iostream>
#include <memory> // unique_ptr 사용
using namespace std;
int main() {
// unique_ptr 생성
unique_ptr<int> ptr1 = make_unique<int>(10);
// unique_ptr이 관리하는 값 출력
cout << "ptr1의 값: " << *ptr1 << endl;
// unique_ptr은 복사가 불가능
// unique_ptr<int> ptr2 = ptr1; // 컴파일 에러 발생!
// 범위를 벗어나면 메모리 자동 해제
return 0;
}일단 <memory> 라이브러리가 필요하다
unique_ptr 이 vs 에서 청록색인 점이나,
라이브러리 추가가 필요한 점이나 일종의 '클래스' 라고 볼 수 있을 듯
make_unique가 멤버함수 느낌?
unique_ptr 이라고 데이터타입 처럼 명시를 해주고
<int> 로 포인터 타입 정해주고 ptr1 포인터 이름,
make_unique<int> 로 좀전에 (new int) 만들었듯이 동적 할당
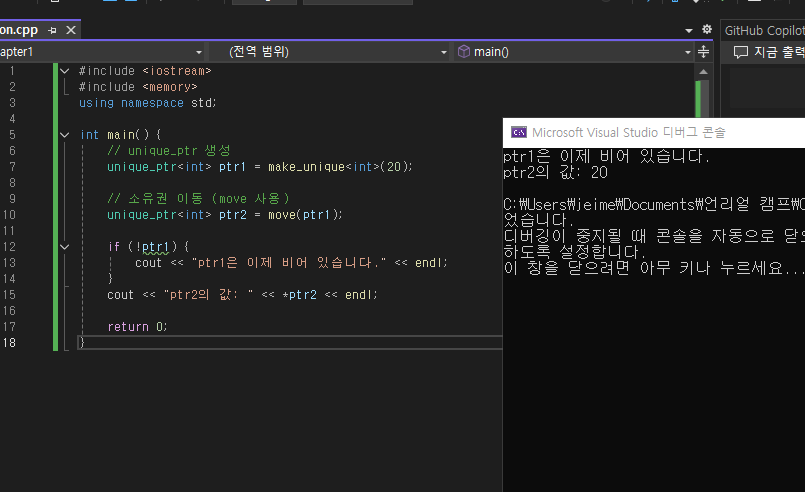
2) 복사 불가, move 를 통해 소유권 이전만 가능
int main() {
// unique_ptr 생성
unique_ptr<int> ptr1 = make_unique<int>(20);
// 소유권 이동 (move 사용)
unique_ptr<int> ptr2 = move(ptr1);
if (!ptr1) {
cout << "ptr1은 이제 비어 있습니다." << endl;
}
cout << "ptr2의 값: " << *ptr2 << endl;
return 0;
}
move :
소유권을 이전받을 포인터를 지정해주고 unique_ptr<int> ptr2
move() 함수와 함께 넘길 포인터 지정 move(ptr1)
예시)
class MyClass {
public:
MyClass(int val) : value(val) {
cout << "MyClass 생성: " << value << endl;
}
~MyClass() {
cout << "MyClass 소멸: " << value << endl;
}
void display() const {
cout << "값: " << value << endl;
}
private:
int value;
};
int main() {
// unique_ptr로 MyClass 객체 관리
unique_ptr<MyClass> myObject = make_unique<MyClass>(42);
// MyClass 멤버 함수 호출
myObject->display();
// 소유권 이동
unique_ptr<MyClass> newOwner = move(myObject);
if (!myObject) {
cout << "myObject는 이제 비어 있습니다." << endl;
}
newOwner->display();
// 범위를 벗어나면 newOwner가 관리하는 메모리 자동 해제
return 0;
}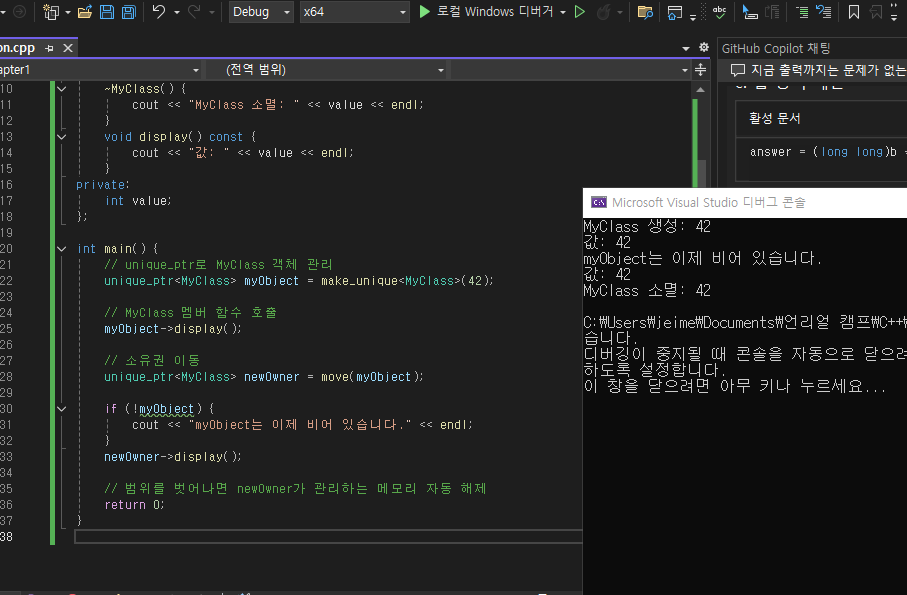
소멸까지 정확하게 나오는 모습.
void display() const 부분은
= 이 display 함수가 객체의 멤버변수를 수정하지 않겠다는 명시적 부분.
지금은 display 함수에서 멤버변수 value 의 값에 어떠한 조정을 하진 않지만
저렇게 const 로 명시해 두면 value=10 같이 나중에 넣어줘도 에러뜨면서 통하지 않는다.
shared_ptr
객체 하나를 여러 개 포인터로 참조하는
말그대로 "공유 포인터"
레퍼런스 카운터 가 내부적으로 관리를 해주기 때문에
참조중인 포인터 수가 0 이 되면 자동으로 메모리 해제.
use_count() 메서드(멤버함수)로 참조중인 포인터 수를 확인할 수 있고
reset() 함수로 소유 중인 객체를 해제하거나 다른 객체로 변경도 가능!
1) 복사/대입 을 통해 여러 개의 포인터가 객체 하나를 공유할 수 있다
#include <iostream>
#include <memory> // shared_ptr 사용
using namespace std;
int main() {
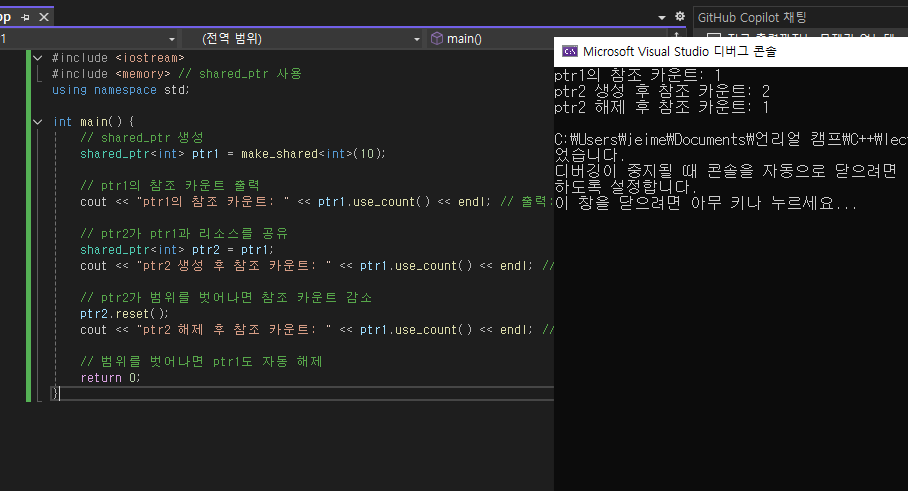
// shared_ptr 생성
shared_ptr<int> ptr1 = make_shared<int>(10);
// ptr1의 참조 카운트 출력
cout << "ptr1의 참조 카운트: " << ptr1.use_count() << endl; // 출력: 1
// ptr2가 ptr1과 리소스를 공유
shared_ptr<int> ptr2 = ptr1;
cout << "ptr2 생성 후 참조 카운트: " << ptr1.use_count() << endl; // 출력: 2
// ptr2가 범위를 벗어나면 참조 카운트 감소
ptr2.reset();
cout << "ptr2 해제 후 참조 카운트: " << ptr1.use_count() << endl; // 출력: 1
// 범위를 벗어나면 ptr1도 자동 해제
return 0;
}
unique_ptr 과 유사한 방식으로 선언, 정의.
역할이 다르지 매커니즘은 비슷한 모습
복사해서 다른 포인터에 넣어주면 카운트가 오르고,
참조 중인 포인터에 .reset() 함수 호출해주면 참조 해제.
예시)
class MyClass {
public:
MyClass(int val) : value(val) {
cout << "MyClass 생성: " << value << endl; // 출력: MyClass 생성: 42
}
~MyClass() {
cout << "MyClass 소멸: " << value << endl; // 출력: MyClass 소멸: 42
}
void display() const {
cout << "값: " << value << endl; // 출력: 값: 42
}
private:
int value;
};
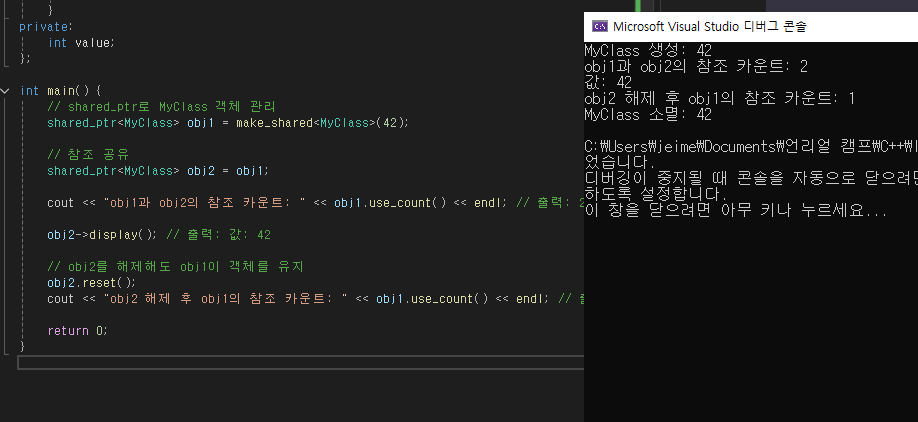
int main() {
// shared_ptr로 MyClass 객체 관리
shared_ptr<MyClass> obj1 = make_shared<MyClass>(42);
// 참조 공유
shared_ptr<MyClass> obj2 = obj1;
cout << "obj1과 obj2의 참조 카운트: " << obj1.use_count() << endl; // 출력: 2
obj2->display(); // 출력: 값: 42
// obj2를 해제해도 obj1이 객체를 유지
obj2.reset();
cout << "obj2 해제 후 obj1의 참조 카운트: " << obj1.use_count() << endl; // 출력: 1
return 0;
}
weak_ptr (약한 참조)
weak_ptr 은 위의 shared_ptr에서 쓰는 레퍼런스 카운트를 증가시키지 않는다.
그래서 없는 메모리를 참조하지 않도록
lock() 함수를 통해 shared_ptr 이 현재 유효한 지
먼저 확인을 해주는 과정이 필요.
1) weak_ptr을 쓰기 전에 유효성부터 확인
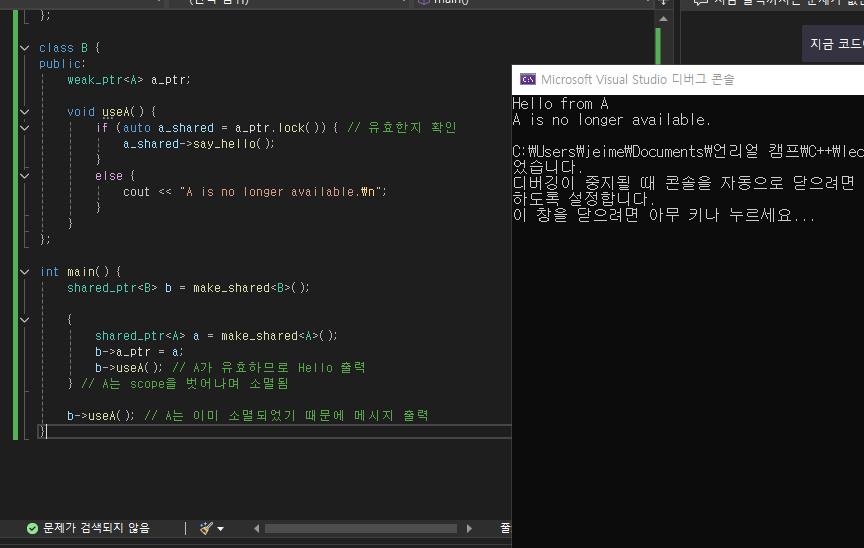
#include <iostream>
#include <memory>
using namespace std;
class A {
public:
void say_hello() {
cout << "Hello from A\n";
}
};
class B {
public:
weak_ptr<A> a_ptr; // weak ptr 작성
void useA() {
if (auto a_shared = a_ptr.lock()) {
// lock() 으로 유효한지 확인 후에 코드 실행
a_shared->say_hello();
} else {
cout << "A is no longer available.\n";
}
}
};
int main() {
shared_ptr<B> b = make_shared<B>(); //
{
shared_ptr<A> a = make_shared<A>();
b->a_ptr = a;
b->useA(); // A가 유효하므로 Hello 출력
} // A는 scope을 벗어나며 소멸됨
b->useA(); // A는 이미 소멸되었기 때문에 메시지 출력
}
살짝 복잡한 짜임새를 가졌다.
일단 앞서 말했듯 lock() 으로 유효성부터 확인하고 사용할 수 있도록
if 문을 배치.
is valid 개념
if (auto a_shared = a_ptr.lock()) :
a_ptr.lock() 의 결과 null 이 아니라면 => 코드가 실행된다.
(!null 과 같은 의미)
우선 A 클래스의 약한 참조 a_ptr 을 가진 B 클래스의 공유 포인터 b 를 선언.
=> {} 안에서 A 클래스 공유 포인터 a 를 선언해주고
=> b 주소에 있는 약한 참조 a_ptr 이 a 를 가리키게 지정.
=> {} 안에선 b 를 통해(->) useA 를 호출해도 동작
=> {} 를 벗어나면서 공유 포인터 a 가 소멸
=> 밖에서 b 를 통해(->) useA 를 호출하려 해도 a 가 소멸되서 불가능
=> A 가 더이상 유효하지 않다는 메시지 출력
2) shared_ptr 로 서로를 가리키다 보면 순환참조가 발생할 수 있다
#include <iostream>
#include <memory>
using namespace std;
class B; // Forward declaration
class A {
public:
shared_ptr<B> b_ptr;
~A() { cout << "A destroyed\n"; }
};
class B {
public:
shared_ptr<A> a_ptr;
~B() { cout << "B destroyed\n"; }
};
int main() {
auto a = make_shared<A>();
auto b = make_shared<B>();
a->b_ptr = b;
b->a_ptr = a;
// main 함수가 끝나도 A와 B는 서로 참조 중이라 메모리 해제가 안 됨
return 0;
}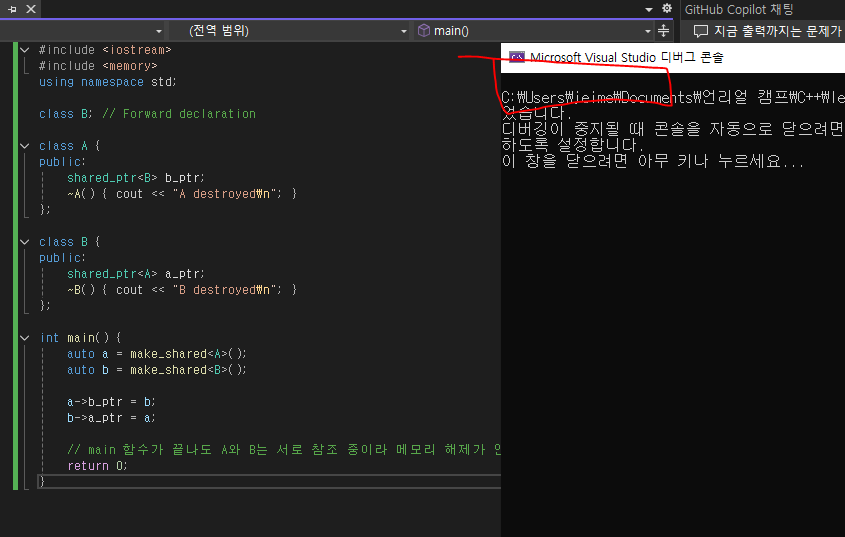
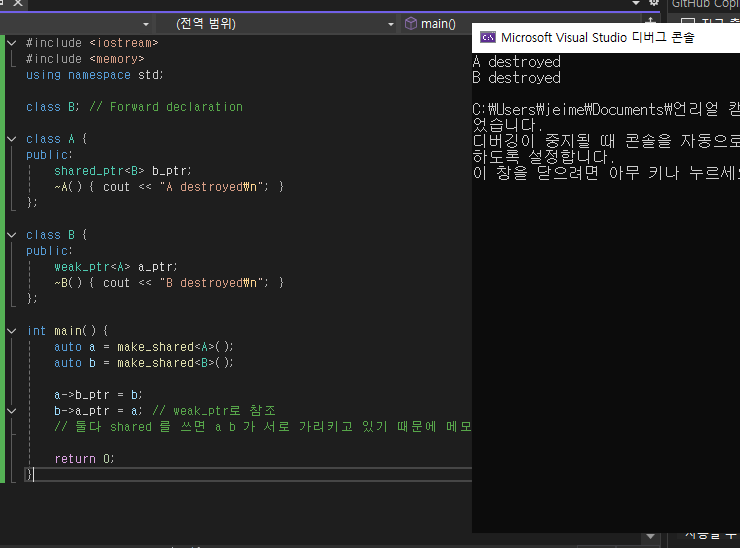
소멸자가 호출되지 않아 터미널에 아무것도 나오지 않는 모습
3) 순환참조를 weak_ptr로 끊어준 예시)
#include <iostream>
#include <memory>
using namespace std;
class B; // Forward declaration
class A {
public:
shared_ptr<B> b_ptr;
~A() { cout << "A destroyed\n"; }
};
class B {
public:
weak_ptr<A> a_ptr;
~B() { cout << "B destroyed\n"; }
};
int main() {
auto a = make_shared<A>();
auto b = make_shared<B>();
a->b_ptr = b;
b->a_ptr = a; // weak_ptr로 참조
// 둘다 shared 를 쓰면 a b 가 서로 가리키고 있기 때문에 메모리 해제 X
return 0;
}
※ Forward declaration 은 "전방 선언" 이란 개념으로,
함수, 구조체, 열거자, 공용자, 외부(extern) 변수, 클래스 등을
자세한 내용 구현에 앞서 선언부터 해주는 걸 말한다.
이는 서로를 호출하는 함수, 외부(extern) 변수, PImple기법 등에서 사용된다.
위 예시의 경우 클래스 A와 B가 서로와 관련된 내용을 담고 있기 때문에
B 클래스를 이름만이라도 앞서 선언해줄 필요가 있다.
A 클래스만 완성된 시점에서 보면, 존재하지 않는 B 클래스 내용을 다루고 있는 셈.
클래스에 대해 학습할 때 선언부와 / 구현부를 나누어 주던 것도
이 "전방 선언" 개념에 속한다.
얕은 복사 / 깊은 복사
복사의 방식에는 이렇게 위 두가지 방식이 있는데,
일반적으로 "포인터" 나 동적 할당된 자원들을 관리하는 객체는
메모리 안정성을 위해 '깊은 복사'를 사용하는 것이 바람직하다.
1. 얕은 복사(Shallow Copy)
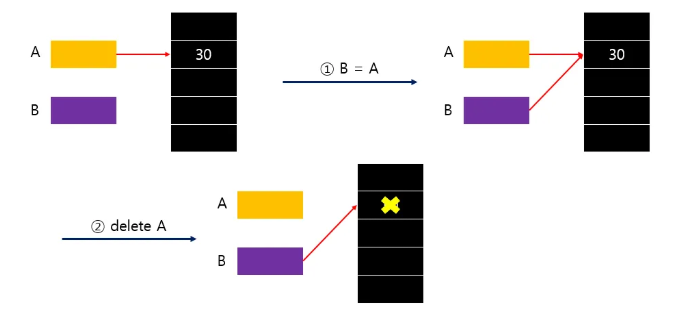
클래스 내의 포인터 멤버를 복사할 때,
포인터가 가리키고 있는 데이터가 아닌,
포인터가 저장하고 있는 주소값 만 복사하는 것
=> 즉, 원본과 복사본이 동일하게 동적할당된 메모리를 포인팅하게 되면서,
원본의 동적 메모리가 해제되면 복사본은 아무것도 없는 곳을 가리키는,
아까 봤던 "dangling pointer" 가 된다
#include <iostream>
using namespace std;
int main() {
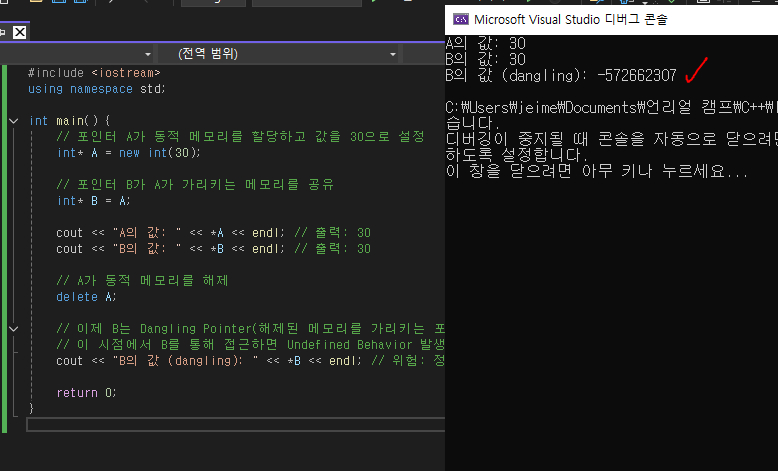
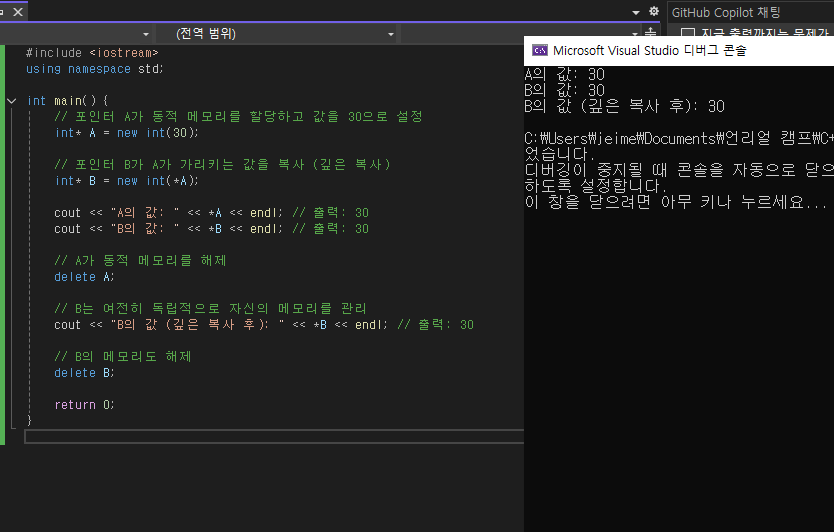
// 포인터 A가 동적 메모리를 할당하고 값을 30으로 설정
int* A = new int(30);
// 포인터 B가 A가 가리키는 메모리를 공유
int* B = A;
cout << "A의 값: " << *A << endl; // 출력: 30
cout << "B의 값: " << *B << endl; // 출력: 30
// A가 동적 메모리를 해제
delete A;
// 이제 B는 Dangling Pointer(해제된 메모리를 가리키는 포인터)
// 이 시점에서 B를 통해 접근하면 Undefined Behavior 발생
cout << "B의 값 (dangling): " << *B << endl; // 위험: 정의되지 않은 동작
return 0;
}
2. 깊은 복사(Deep Copy)
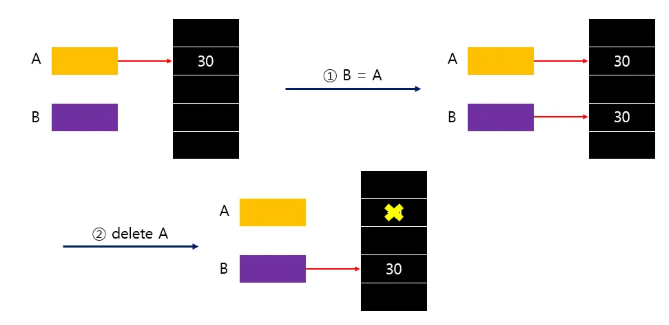
클래스의 포인터 멤버가 가리키고 있는 동적 데이터를
"따로" 새로 할당된 메모리 영역에 복제하는 것으로
원본과 복사본이 서로 다른 독립적인 메모리이기 때문에
어느 하나가 해제되더라도 서로에겐 영향이 없다.
다만 우리가 지금 배우고 있는 건
"동적 메모리 할당 활용" 이기 때문에
이렇게 깊은 복사를 사용했다면 제대로 복사본도 delete 해줄 필요가 있다
#include <iostream>
using namespace std;
int main() {
// 포인터 A가 동적 메모리를 할당하고 값을 30으로 설정
int* A = new int(30);
// 포인터 B가 A가 가리키는 값을 복사 (깊은 복사)
int* B = new int(*A);
// new int 하는 순간 새로운(new) int 를 위한 공간이 할당됨
cout << "A의 값: " << *A << endl; // 출력: 30
cout << "B의 값: " << *B << endl; // 출력: 30
// A가 동적 메모리를 해제
delete A;
// B는 다른 공간이라 영향 X
cout << "B의 값 (깊은 복사 후): " << *B << endl; // 출력: 30
// 제대로 B의 메모리도 해제
delete B;
return 0;
}
언리얼 엔진의 메모리 관리
"언리얼 엔진"에서는
객체들의 메모리 관리를 자동화하기 위해
"가비지 컬렉션 시스템" 을 사용한다.
'로봇 청소기' 처럼,
주기적으로 작동해서 어떠한 객체가
아직 사용중인지, 더이상 사용하지 않는지(garbage) 를 확인해서
자동으로 사용되지 않는 메모리를 처리해준다.
1. 가비지 컬렉션은 "마크 앤 스윕" 알고리즘 방식으로 동작한다
이 "마크 앤 스윕" 알고리즘이 주기적으로 실행되서
더 이상 프로그램에서 사용하지 않는다고 판단되는 UObject 들을
식별해서 메모리에서 제거한다:
아직 사용중인, 필요한 객체에는 표시(mark)를 하고,
표시되지 않은 객체들은 쓰레기(garbage)로 간주해서 치우는(sweep) 방식.
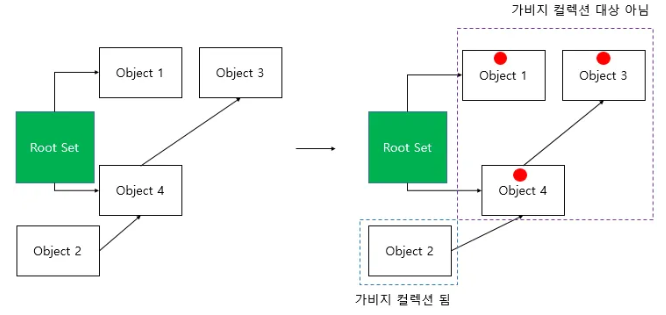
1) "루트셋(root set)" 에서 시작
- 먼저 루트셋에 포함된 객체들을 식별하는데,
이 객체들은 항상 살아있다 는 상태로 간주되는 특별한 친구들.
ex) 게임 엔진 자체, 플레이어 컨트롤러 등
청소할 때 절대 버리면 안되는 물건들
2) 마킹 단계, 도달 가능성 분석
- 루트셋 객체에서 시작해서
타고타고 직간접적으로 참조하는 UObject 들에 마킹을 한다.
사용중 딱지 붙이는 느낌.
3) 스윕 단계, 메모리 회수
- 마킹이 완료되면,
마킹되지 않은 객체들이 점유하고 있던 메모리를 회수한다.
이 과정에서 해당 객체들의 소멸자가 호출되며 메모리가 반환됨.당연히, '소멸자 호출' 이란 말에서 알 수 있지만
코드 자체를 없애는 게 아니라 만들어진 클래스의 소멸자를 불러서
메모리에서 해제해 주는 것.
나중에 필요할 때 다시 부르라는 식으로.
2. UObject 에는 가비지 콜렉션 동작을 제어하는
다양한 플래그(Flag)가 존재.
이 플래그들이 가비지 콜렉션 동작에 중요한 정보를 제공하는데,
GUObjectArray 라는 전역(global) 배열에 저장되어 있는
각 객체들의 정보의 일부로서 관리된다.
-
RF_RootSet:
이 플래그가 설정된, 이 딱지가 붙은 객체는
루트셋의 일부로 판정된다.
=> 설정된 시점부터 알고리즘 대상 외 판정
AddToRoot()함수를 통해 설정할 수 있으며,
해제는RemoveFromRoot()함수를 통해 해제 가능. -
RF_BeginDestroyed:
해당 객체의BeginDestroy()함수가 호출되었음을 나타내며,
이 BeginDestroy 함수는 = 그 객체가 실제로 메모리에서 치워지기 전에
필요한 정리 작업을 수행해주는 함수 -
RF_FinishDestroyed:
객체의FinishDestroy()함수,
객체 소멸의 마지막 단계가 시작되었음을 나타내 준다.
이 함수가 완료되면 메모리가 완전히 해제됨.
아래 2개는 우리가 직접 설정해주는 건 아니다.
언리얼 엔진의 리플렉션 시스템
리플렉션(Reflection) :
프로그램이 실행 중에 스스로 구조와 상태를 검사하고
그걸 수정할 수 있는 능력
C++ 에는 이런 기능이 내장되어 있진 않지만
UE 에서는 자체적으로 이 리플렉션 시스템을 구축하고 있다.
- 그럼 이게 왜 필요하냐
리플렉션은 UObject 를 위한 운영체제 OS 개념으로,
엔진 내부에서 동작하는 여러 모듈
ex) 가비지 컬렉터, 스크립트 시스템 등은
모두UObject를 기반으로 하는데,
그 반면에 개발자가 직접 정의한 타입들의 경우에는
엔진 자체적으로는 이해할 수 있는 방법이 없기 때문에
이 문제를 해결하기 위해서 엔진에게
우리가 만든 타입들의 정보를 공유해줘야 한다.
== 이게 "리플렉션"
블루프린트에서 노드들을 배치하고 이어줘서 로직을 만들거나
에디터 디테일에서 값을 수정하는 등
=> 이게 C++ 코드를 직접 수정하는 대신
언리얼 엔진에서 리플렉션 받은 내용을 엔진에서 편하게 수정하는 것.
리플렉션의 핵심은
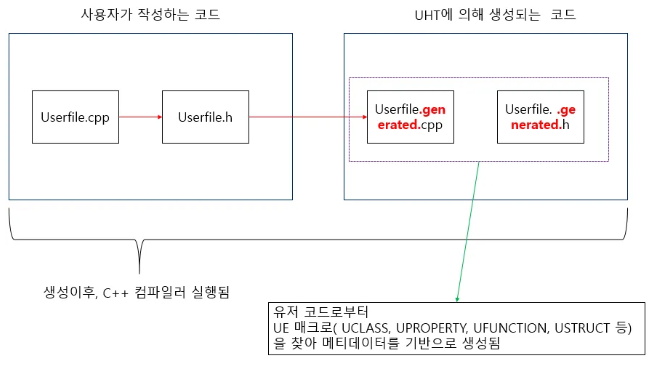
"UHT 코드 생성기"
이 UHT 는 컴파일러가 수행되기 전에 먼저 동작하는데
C++ 코드 안에서 메타 데이터를 얻어서 내부적으로 소스 코드를 생성해주고,
이게 완료되고 나면 C++ 컴파일러가 실행된다.
몇가지 핵심 리플렉션 매크로들)
-
UCLASS() :
C++ 클래스를 UObject 기반의 리플렉션 시스템에 등록
일반적으로 클래스 정의 앞에 배치 -
UPROPERTY() :
멤버 변수를 리플렉션 시스템에 노출
멤버 변수 선언 앞에 배치 -
UFUNCTION() :
멤버 함수를 리플렉션 시스템에 노출
멤버 함수 선언 앞 -
USTRUCT() :
C++ 구조체를 리플렉션 시스템에 등록
구조체 정의 앞 -
GENERATED_BODY() :
UHT가 생성하는 리플렉션 및 엔진 지원 코드를 위한 삽입 지점
클래스/구조체 본문 첫 줄
이 리플렉션 매크로들을 사용해서
C++ 코드에 표시를 해줘야
=> 언리얼 엔진에서 이해하도록 변환이 되는 방식
- 구조체와 클래스 예시:
// FMyStructData.h (or within another .h)
#pragma once
#include "CoreMinimal.h"
#include "UObject/ObjectMacros.h"
#include "MyStructData.generated.h"
USTRUCT(BlueprintType)
// 블루프린트에서 이 구조체를 타입으로 사용할 수 있도록 합니다.
// 이 UHT 매크로의 () 안에 들어가는 건 "플래그" 로,
// 이런식으로 어떻게 쓸 수 있다, 어떤 것이다 지정해주는 것
struct FMyStructData
{
GENERATED_BODY() // UHT가 필요한 코드를 생성하도록 합니다.
public:
UPROPERTY(EditAnywhere, BlueprintReadWrite, Category = "MyStructData")
int32 SampleInt;
UPROPERTY(EditAnywhere, BlueprintReadWrite, Category = "MyStructData")
FString SampleString;
FMyStructData() : SampleInt(0), SampleString(TEXT("Default")) {}
};UCLASS(Blueprintable, BlueprintType)
// 블루프린트에서 생성 가능하고 타입으로 사용 가능하도록 합니다.
class YOURPROJECT_API UMyReflectedObject : public UObject
// UObject를 상속받습니다.
{
GENERATED_BODY() // UHT가 필요한 코드를 생성하도록 합니다.
public:
......
UMyReflectedObject(); // 생성자
};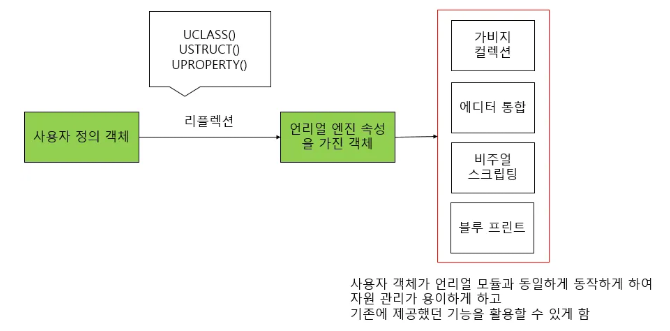
코드에서 작성된 개체가,
언리얼 모듈과 동일하게 동작하게 만들어 줌으로써
자원 관리를 용이하게 하고
엔진에서 제공되는 기능들을 활용할 수 있게 해 준다!
