객체지향적 설계
- 객체지향 프로그래밍 기반의 설계
- 응집도, 결합도 => 이를 응용한 코드
- SOLID 원칙
C++ 문법에 대해서 잘 아는 것도 물론 중요하지만,
"객체 지향적으로" 코드를 구현할 줄 아는 것도 상당히 중요하다.
그 이유는:
1) 대부분의 라이브러리 및 오픈소스는
객체 지향적 으로 설계되어 있어,
객체지향에 대해 이해할수록 더 깊이 있는 학습이 가능하다
2) 좋은 설계로 구현된 코드는 개발 시간 자체를 단축할 수 있다
3) 좋은 설계로 구현된 코드는 기능 변경(사양 변경)에
유연하게 대응할 수 있다
응집도
'좋은 코드를 판단하는 기준 중 하나'
"구현한 클래스 내의 각 모듈들이
얼마나 밀접하게 연관되어 있는가"
결론적으로는 응집도가 높은 게 좋다
클래스 내에 관련없는 모듈(기능)들이 존재하게 되면,
변경이 자주 발생하고, 확장하기도 쉽지 않아진다
이 '관련성' 에 대해서 감을 잡기가 어려울 수 있는데,
실제 사례로 '피자배달'을 통해 생각해보면:
- 응집도가 낮은 경우
응집도가 낮은 경우는 곧
= 서로 관련 없는 기능들이 하나의 클래스로 묶여 있는 경우인데
이는 단일 목적을 가진 팀과 각기 다른 목적을 가진 팀으로 비유할 수 있다
피자배달로 따져보자면,
아래 기능들이 한 클래스(피자배달 클래스)에 포함되어 있을 시
"응집도가 낮다" 고 볼 수 있다. 각 기능들이 따로 노는 느낌을 주기 때문에.
- 피자 배달
- 웹사이트 디자인
- 회사 마케팅
- 창고 관리
회사의 부서를 생각하면 될 것 같다
- 응집도가 높은 경우
응집도가 높은 경우 = 서로 관련 있는 기능들만 하나의 클래스로 되어있는 경우
- 배달 경로 확인
- 주문 고객 대응
- 배달 예상 시간 측정
응집도 예시
아래 기능을 제공하는 코드가 있을 때:
- 특정 문자열을 받아 메시지를 출력
- 두 수의 합을 반환
- 특정 문자열을 받고 역으로 출력
여기에 추가적으로 다음 기능을 추가한다면:
- 두 수의 곱을 반환
- 특정 문자열을 받아 메시지를 출력하기 전 대문자로 변환
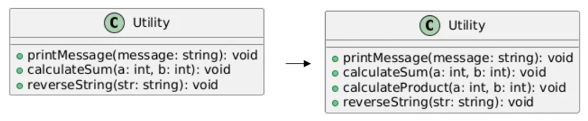
1) 응집도가 낮은 경우
객체지향 OOP 를 처음 접하는 경우
종종 모든 기능을 클래스 하나로 다 묶어버리려는 실수를 할 수 있는데
이는 다음 이유들 때문에 '좋은 설계' 로 보기 어렵다
- 목적이 다른 기능이 섞여있음
- 하나의 클래스에 모든 기능이 집중되어 유지보수가 곤란
#include <iostream>
#include <string>
#include <algorithm> // for transform
using namespace std;
class Utility {
public:
void printMessage(const string& message) {
string upperMessage = message;
transform(upperMessage.begin(), upperMessage.end(), upperMessage.begin(), ::toupper);
// transform 함수:
// upperMessage의 begin부터 end, 모든 문자열을
// toupper, 대문자로 변경
cout << "Message: " << upperMessage << endl;
}
void calculateSum(int a, int b) {
cout << "Sum: " << (a + b) << endl;
}
void calculateProduct(int a, int b) {
cout << "Product: " << (a * b) << endl;
}
void reverseString(const string& str) {
string reversed = string(str.rbegin(), str.rend());
// 역순 반복자로 문자열 뒤집기
cout << "Reversed: " << reversed << endl;
}
};
int main() {
Utility util;
util.printMessage("Hello");
util.calculateSum(5, 10);
util.calculateProduct(5, 10);
util.reverseString("world");
return 0;
}이렇게 '하나의' 클래스로 묶여있는 걸 수정하다보면
언제 어떻게 코드가 망가졌을 때
클래스 하나가 전부 쓸 수 없게 되는 사태를 초래할 수 있는 것.
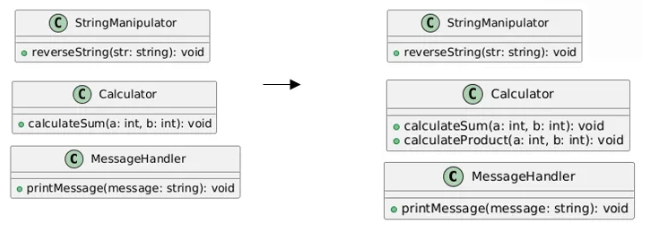
2) 응집도가 높은 경우
응집도를 높이기 위해서
클래스를 목적에 따라 나누어 구현해 준다
이를 통해 몇 가지 장점을 얻을 수 있는데
- 기능 변경이 필요할 때 해당 클래스만 수정하면 된다
- 관련 클래스끼리 정보를 공유해서 코드구조가 명확해진다
응집도가 낮은 경우:
응집도가 높은 경우:
#include <iostream>
#include <string>
#include <algorithm> // for transform
using namespace std;
class MessageHandler {
public:
void printMessage(const string& message) {
string upperMessage = message;
transform(upperMessage.begin(), upperMessage.end(), upperMessage.begin(), ::toupper);
cout << "Message: " << upperMessage << endl;
}
};
class Calculator {
public:
void calculateSum(int a, int b) {
cout << "Sum: " << (a + b) << endl;
}
void calculateProduct(int a, int b) {
cout << "Product: " << (a * b) << endl;
}
};
class StringManipulator {
public:
void reverseString(const string& str) {
string reversed = string(str.rbegin(), str.rend());
cout << "Reversed: " << reversed << endl;
}
};
int main() {
MessageHandler messageHandler;
messageHandler.printMessage("Hello");
Calculator calculator;
calculator.calculateSum(5, 10);
calculator.calculateProduct(5, 10);
StringManipulator stringManipulator;
stringManipulator.reverseString("world");
return 0;
}이렇게 클래스를 분리해 두는게
뭔가 문제가 생겼을 때 서로 영향도 적고
어디서 문제가 생겼는지 명확하게 볼 수 있으며
기능별로 잘 나눠져 있기 때문에 기억하고 활용하기도 쉽다
== "좋은 코드"
결합도
"결합도" = 각 모듈 또는 클래스 간의 "의존성"
예를 들어)
함수 A->B->C->D 이런 식으로 호출하게 되는 구조라면
이 ABCD 함수들은 의존성이 높은 것이며,
이 중 어느 하나가 수정될 시 전체 구조가 영향을 받는다.
즉, "결합도는 낮을수록 좋다"
결합도 예시
'자동차-엔진 관계' 를 코드로 구현한다고 생각했을 때,
- 자동차는 초기에 엔진이 장착되어 있고
- 자동차 시동이 걸리면 엔진이 동작한다고 출력되는데
엔진의 종류가 다양해지면서
자동차도 여러 종류의 엔진을 지원해야 한다
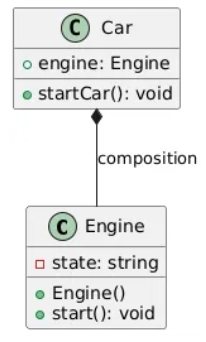
1) 결합도가 높은 경우
자동차 클래스가 디젤 엔진 클래스를 직접 포함하게 되면서
아래와 같은 문제가 발생함:
- 새로운 전기 엔진을 추가하려면
자동차 클래스도 수정이 필요함 - 변경이 잦은 경우 수정 범위가 커지고 유지보수가 곤란
#include <iostream>
#include <string>
using namespace std;
// 기존 Engine 클래스
class Engine {
public:
string state;
Engine() : state("off") {}
void start() {
state = "on";
cout << "Engine started" << endl;
}
};
class Car {
public:
Engine engine; // 엔진을 직접 포함하고있는 상태
void startCar() {
if (engine.state == "off") {
engine.start();
cout << "Car started" << endl;
}
}
};여기서 엔진이 추가되면 ==>
#include <iostream>
#include <string>
using namespace std;
// 기존 Engine 클래스
class Engine {
public:
string state;
Engine() : state("off") {}
void start() {
state = "on";
cout << "Engine started" << endl;
}
};
// 새로운 ElectricEngine 클래스 (기존 Engine과는 별도)
class ElectricEngine {
public:
string state;
ElectricEngine() : state("off") {}
void start() {
state = "on";
cout << "Electric Engine running silently" << endl;
}
};
// 기존 Car 클래스 수정
class Car {
public:
Engine engine; // Car 클래스는 여전히 Engine 클래스에 강하게 의존
void startCar() {
if (engine.state == "off") {
engine.start();
cout << "Car started" << endl;
}
}
};이러면 자유롭게 엔진을 변경해야 되는 상황과 다르게
Engine engine 으로 강하게 의존하고 결합된 상태이기 때문에
ElectricEngine 으로 대체하려면 코드를 갈아엎어야 되는 어려운 상황이 나온다
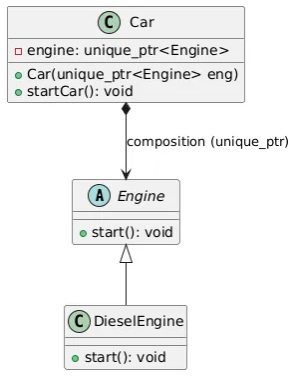
2) 결합도가 낮은 경우
결합도를 낮추기 위해서
자동차 클래스가 특정 엔진 클래스를 직접 포함하여 갖고 있지 않고
"인터페이스" => "추상화" 를 활용하는 방법을 쓸 수 있다.
이렇게 하면 다음과 같은 장점이 생기는데
- 자동차 클래스는 엔진 "인터페이스"에만 의존하므로,
새로운 엔진 종류를 추가해도 자동차 클래스 코드를 수정할 필요가 없다 - 확장성이 높아지면서 다양한 엔진을 유연하게 지원 가능
#include <iostream>
#include <memory>
#include <string>
using namespace std;
class Engine {
public:
virtual void start() = 0; // 순수 가상 함수
virtual ~Engine() = default; // 가상 소멸자
};
class DieselEngine : public Engine { // 엔진 파생 클래스
public:
void start() { // 순수가상함수 재정의
cout << "Diesel Engine started" << endl;
}
};
class Car {
private:
unique_ptr<Engine> engine; // 인터페이스에 의존하여 결합도 감소
// 인터페이스 추상화 클래스를 unique_ptr 고유 스마트 포인터로 참조
public:
Car(unique_ptr<Engine> eng) : engine(move(eng)) {}
void startCar() {
engine->start();
cout << "Car started" << endl;
}
};
int main() {
auto engine = make_unique<DieselEngine>(); // 유니크 포인터 선언
Car myCar(move(engine));
myCar.startCar();
return 0;
}기능 추가 후==>
#include <iostream>
#include <memory>
using namespace std;
// 공통 인터페이스 정의
class Engine {
public:
virtual void start() = 0;
virtual ~Engine() = default;
};
// DieselEngine 구현
class DieselEngine : public Engine {
public:
void start() {
cout << "Diesel Engine started" << endl;
}
};
// 새로운 ElectricEngine 구현
// 상속 파생 클래스 추가
class ElectricEngine : public Engine {
public:
void start() {
cout << "Electric Engine started silently" << endl;
}
};
// Car 클래스는 Engine 인터페이스에만 의존
class Car {
private:
unique_ptr<Engine> engine;
public:
Car(unique_ptr<Engine> eng) : engine(move(eng)) {}
// 유니크 포인터 소유권을 move() 함수로 받는다
void startCar() {
engine->start();
cout << "Car started" << endl;
}
};
int main() {
// DieselEngine을 사용하는 경우
auto dieselEngine = make_unique<DieselEngine>();
Car dieselCar(move(dieselEngine));
// move() 함수는 유니크 포인터 소유권 이전 해주는 함수
// 위에서는 디젤엔진 넣어주고 아래서는 전기엔진 넣어주는 느낌
dieselCar.startCar();
// ElectricEngine을 사용하는 경우
// 그때그때 유니크 포인터만 만들어주면 그만
auto electricEngine = make_unique<ElectricEngine>();
Car electricCar(move(electricEngine));
electricCar.startCar();
return 0;
}SOLID 원칙
계속해서 어떻게 해야 진정한 OOP(객체지향 프로그래밍) 가 가능한가?
스스로 고민을 해보는 것도 좋지만
이미 고수들이 잘 닦아놓은 걸 토대로 가져다 써도 문제가 없다
그런 의미에서 배우는 것이 SOLID 원칙
이 SOLID 원칙의 목적은 크게 2가지:
1) 유지보수성 및 확장성 향상 = 재사용성 향상
2) 변경 유연성
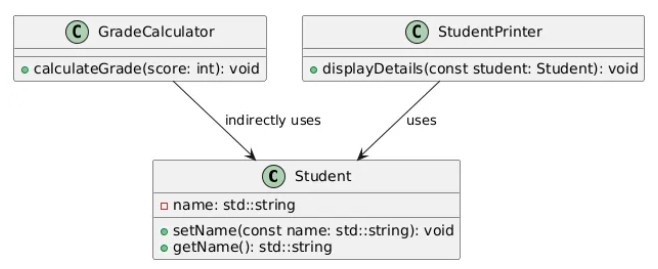
단일 책임 원칙 (SRP)
"각 클래스는 하나의 책임(=역할)만 가져야 한다"
클래스 별로 역할을 확실하게 나눠서
수정이 필요한 경우 필요한 해당 클래스만 딱딱 수정
예를 들어)
- 학생의 이름을 저장
- 학생 이름을 출력
- 학생의 점수를 받아 성적 계산
이때 "단일 책임 원칙"에 따르지 않고 구현한다면
Student 클래스 하나에 모든 메서드를 우겨넣을 수 있다

하지만 이때 Student 클래스는 학생 정보만 정확히 가지고 있는 게 최선이고,
나머지 기능은 별도의 클래스로 분리해주는 게 가장 좋다!
#include <iostream>
#include <string>
// 학생 정보 관리 클래스
class Student {
public:
void setName(const std::string& name) {
this->name = name;
}
std::string getName() const {
return name;
}
private:
std::string name;
};
// 성적 계산 클래스
class GradeCalculator {
public:
void calculateGrade(int score) {
if (score >= 90) {
std::cout << "Grade: A" << std::endl;
} else if (score >= 80) {
std::cout << "Grade: B" << std::endl;
} else {
std::cout << "Grade: C" << std::endl;
}
}
};
// 출력 클래스 // 각각 책임(역할) 이 하나씩
class StudentPrinter {
public:
void displayDetails(const Student& student) {
std::cout << "Student Name: " << student.getName() << std::endl;
}
};개방 폐쇄 원칙 (OCP)
"확장에는 열려있어야 하고, 수정에는 닫혀있어야 한다" 라는 개념.
기존 코드를 최소한으로 변경하면서 새로운 기능을 추가할 수 있도록,
그렇게 설계되어야 한다는 얘기.
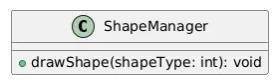
ex) 도형에 해당되는 번호를 받아 해당 도형을 그려주는 클래스
아래와 같이 ShapeManager 클래스 하나가
모든 도형을 다 관리하게 되면..
어떠한 도형이 추가될 때마다 drawShape 함수의 코드가 수정되면서
클래스가 계속해서 영향을 받는다.
class ShapeManager {
public:
void drawShape(int shapeType) {
if (shapeType == 1) {
// 원 그리기
} else if (shapeType == 2) {
// 사각형 그리기
}
}
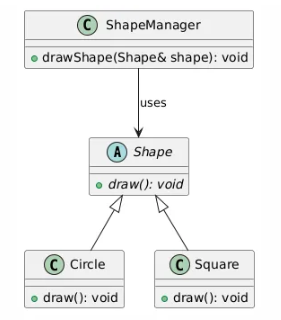
};더 적절한 구현 방법은,
적당한 인터페이스, 여기선 Shape 기본 클래스를 만들어서
그 객체의 참조자를 파라미터로 받는 것.
그리고 각 도형을 Shape 기본 클래스를 상속 받은 파생 클래스로 제작
class Shape {
public:
virtual void draw() = 0; // 순수 가상 함수
};
class Circle : public Shape {
public:
void draw() {
// 원 그리기로 재정의
}
};
class Square : public Shape {
public:
void draw() {
// 사각형 그리기로 재정의
}
};
class ShapeManager {
public:
void drawShape(Shape& shape) { // 인터페이스 참조를 받아서
shape.draw(); // 다형성 활용
}
};리스 코프 치환 원칙 (LSP)
자식 클래스는 부모 클래스에서 기대하고 있는 행동을 보여줘야 하며
객체지향에서 "다형성"을 활용할 떄,
부모 클래스를 사용하는 코드가 자식 클래스로 대체되더라도
문제없이 동작해야만 한다.
=> 이를 위해 파생 클래스는 기본 클래스의 동작을 일관되게 유지할 필요가 있다.
인터페이스에서 순수가상함수를 작성했으면
파생 클래스에서 반드시 해당 순수가상함수를 재정의해줘야 하는 느낌과 유사
ex)
- 모든 도형은 넓이를 계산할 수 있어야한다
- Rectangle 클래스를 상속받는 Square 클래스 구현
원칙을 잘못 적용할 경우:
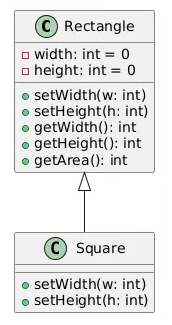
이 경우 Square 는 정사각형이기 때문에
높이와 너비를 따로 설정할 필요가 없어서
=> 부모 클래스에서 원하는 행동을 보장할 수 없게 된다.
#include <iostream>
class Rectangle {
public:
virtual void setWidth(int w) { width = w; }
virtual void setHeight(int h) { height = h; }
int getWidth() const { return width; }
int getHeight() const { return height; }
int getArea() const { return width * height; }
private:
int width = 0;
int height = 0;
};
class Square : public Rectangle {
public:
void setWidth(int w) override {
Rectangle::setWidth(w);
Rectangle::setHeight(w); // 정사각형은 너비와 높이가 같아야 함
}
void setHeight(int h) override {
Rectangle::setHeight(h);
Rectangle::setWidth(h); // 정사각형은 너비와 높이가 같아야 함
}
};
void testRectangle(Rectangle& rect) {
rect.setWidth(5);
rect.setHeight(10); // square의 경우 여기서 10*10 이 되버림
std::cout << "Expected area: 50, Actual area: " << rect.getArea() << std::endl;
}
int main() {
Rectangle rect;
testRectangle(rect); // Expected area: 50
Square square;
testRectangle(square); // Expected area: 50, Actual area: 100 (문제 발생)
return 0;
}Rectangle 과 Square 의 속성이 잘 맞지 않아
상속한 것 자체가 잘못되었다고 볼 수 있다.
이러한 차이를 메꾸기 위해 LSP 원칙을 잘 적용하면:
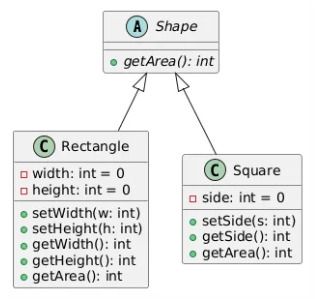
똑같이 추상화를 통해
Shape 인터페이스를 두 클래스가 상속받게 만들고,
getArea() 가 가상함수가 되면서 도형별로 넓이 구하는 방식을 맞게 구현해주면 그만.
#include <iostream>
class Shape {
public:
virtual int getArea() const = 0; // 넓이를 계산하는 순수 가상 함수
// 공통적인 넓이 구하는 함수만 인터페이스로 분리
};
class Rectangle : public Shape {
public:
void setWidth(int w) { width = w; }
void setHeight(int h) { height = h; }
int getWidth() const { return width; }
int getHeight() const { return height; }
int getArea() const override { return width * height; }
private:
int width = 0;
int height = 0;
};
class Square : public Shape {
public:
void setSide(int s) { side = s; } // 정사각형이니까 편하게 한 변만 구현
int getSide() const { return side; }
int getArea() const override { return side * side; }
private:
int side = 0;
};
void testShape(Shape& shape) {
std::cout << "Area: " << shape.getArea() << std::endl;
}
int main() {
Rectangle rect;
rect.setWidth(5);
rect.setHeight(10);
testShape(rect); // Area: 50
Square square;
square.setSide(7);
testShape(square); // Area: 49
return 0;
}인터페이스 분리 원칙 (ISP)
"클라이언트는 자신이 사용하지 않는 메서드에 의존해서는 안된다"
즉, 하나의 거대한 인터페이스보다는
역할별로 세분화된 인터페이스를 만들어서
필요한 기능만 맞게 구현하도록 설계해야 한다.
클래스는 자기한테 필요없는 기능까지 가지고 있을 이유가 없다.
ex)
- 프린트, 스캔
잘못 적용한 경우)
프린터 기능과 스캔 기능을 클래스 하나로 묶어서 작성하게 되면
이를 상속받는 클래스들은 필요에 관계없이 두 기능 모두를 구현할 필요가 생긴다
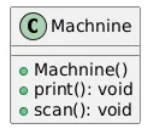
class Machnine {
private:
public:
Machnine() {}
void print() {
//세부 기능 구현
}
void scan() {
//세부 기능 구현
}
};이를 제대로 적용하려면)
프린터, 스캔, 팩스 등 기능을 따로 별도 클래스로 구현해서
필요한 기능 클래스만 쓱쓱 가져다 쓸 수 있도록 구현하면 된다
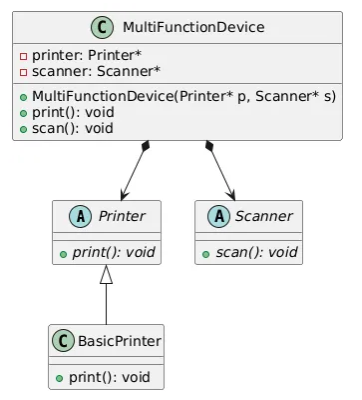
class Printer {
public:
virtual void print() = 0; // 프린트 기능 순수가상함수
};
class Scanner {
public:
virtual void scan() = 0; // 스캔 기능
};
class BasicPrinter : public Printer {
public:
void print() override { // 프린트 기능만 필요->재정의
// 문서 출력
}
};
class MultiFunctionDevice {//
private:
Printer* printer;
Scanner* scanner; // 멀티 기능 필요
// 프린터 인터페이스와 스캐너 인터페이스를 둘 다 가져온것
// 상속을 더블로 할수는 없으니까? 이런 방식으로 해결하는 걸지도
public:
MultiFunctionDevice(Printer* p, Scanner* s) : printer(p), scanner(s) {}
void print() {
if (printer) printer->print(); // 인터페이스에 의존
// 여기서 구현하는 게 아니라
}
void scan() {
if (scanner) scanner->scan(); // 필요한 만큼 재정의
}
};의존 역전 원칙 (DIP)
고수준 모듈(인터페이스) 는 저수준모듈(구체적인 구현 클래스들)에 의존하지 않고,
"둘 다 추상화에 의존해야 한다."
간단하게 말하자면,
구체적인 구현에 의존하는 것이 아니라
인터페이스나 추상 클래스 같은 추상화 계층을 통해
결합도를 낮추는 것이 좋은 설계라는 뜻
ex)
- 컴퓨터에 키보드 모니터 가 있고
- 키보드는 입력을 받을 수 있으며 모니터는 출력이 가능
잘못 적용)
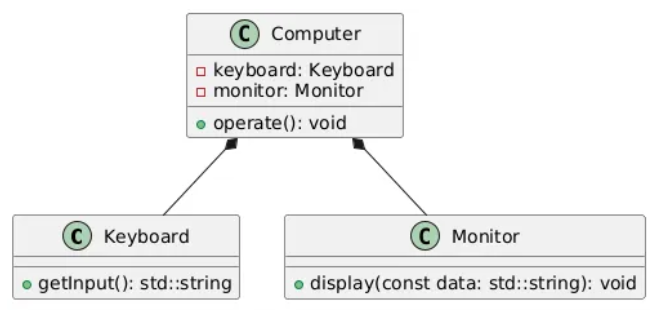
Computer 클래스가 Keyboard, Monitor 클래스와 강하게 결합되면서
키보드 나 모니터 의 종류가 늘어나게 되면 변경량이 불어나게 된다
#include<string>
class Keyboard {
public:
std::string getInput() {
return "입력 데이터";
}
};
class Monitor {
public:
void display(const std::string& data) {
// 출력
}
};
class Computer {
Keyboard keyboard;
Monitor monitor; // 직접적으로 객체를 보유, 강하게 의존
// 키보드-모니터 바꾸려면 새로 작성해야 한다
public:
void operate() {
std::string input = keyboard.getInput();
monitor.display(input);
}
};이를 보완하려면)
키보드와 모니터를 인터페이스화 해서 (종류가 추가될 수 있기 때문에)
결합도를 낮춰준다
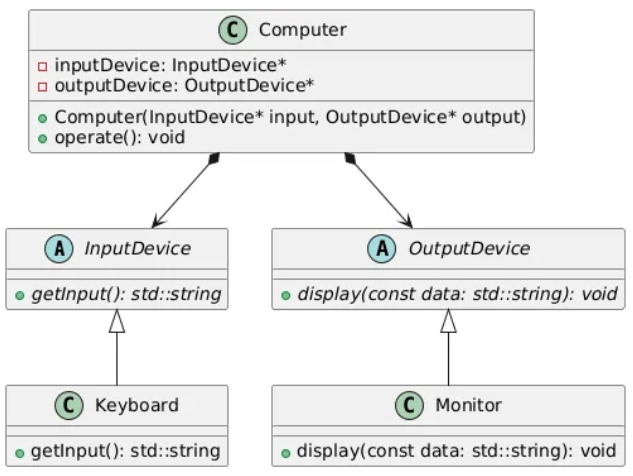
#include<string>
class InputDevice {
public:
virtual std::string getInput() = 0;
};
class OutputDevice {
public:
virtual void display(const std::string& data) = 0;
};
class Keyboard : public InputDevice {
public:
std::string getInput() override {
return "키보드 입력 데이터";
}
};
class Monitor : public OutputDevice {
public:
void display(const std::string& data) override {
// 화면에 출력
}
};
class Computer {
private:
InputDevice* inputDevice;
OutputDevice* outputDevice; // 포인터로 참조
// 입력장치, 출력장치 인터페이스를 실제 구현한 클래스들에 모두 대응한다
// Animal* animal 하던 거 생각
public:
Computer(InputDevice* input, OutputDevice* output)
: inputDevice(input), outputDevice(output) {}
void operate() {
std::string data = inputDevice->getInput();
outputDevice->display(data);
}
};요약하자면,
각 클래스가 각자 명확하고 단일된 목표 기능이 있고
추상 클래스, "인터페이스"를 십분 활용해 유지보수성 과 확장성을 잡는 것
"개방 폐쇄 원칙 (OCP)" 만 우선 잘 명심해두면
상당히 도움이 된다.
확장에는 열려있고, 수정에는 닫혀있을 것.
기존 코드를 최소한으로 변경하면서 새로운 기능을 추가할 수 있게 만들 것
