머신러닝 모델을 평가하는 데는 다양한 지표가 사용됩니다. 이번 포스팅에서는 분류 모델을 평가하는 데 사용되는 주요 지표들에 대해 알아보겠습니다.
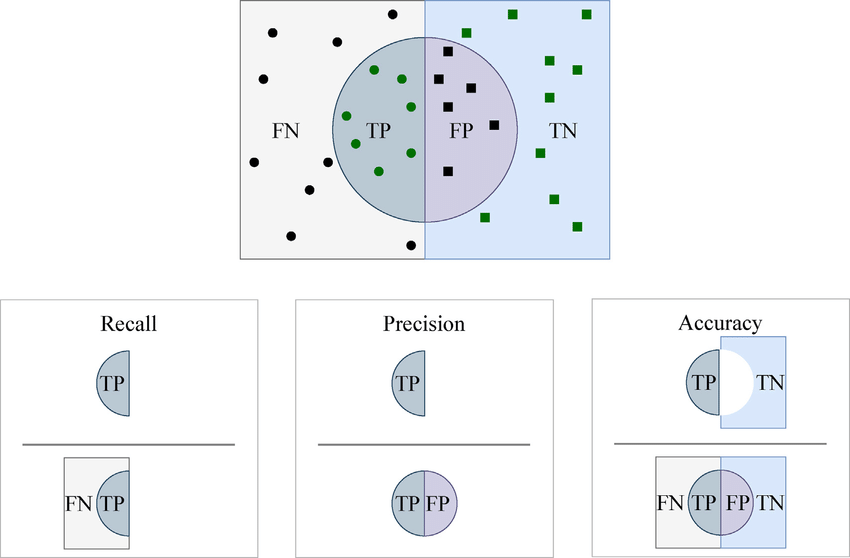
1. 정확도(Accuracy)
정확도는 가장 직관적인 성능 측정 지표입니다. 정확하게 예측된 관측치의 비율을 나타냅니다.
2. 정밀도(Precision)
정밀도는 예측된 긍정 관측치 중 실제로 긍정인 관측치의 비율입니다. 이는 분류기의 정확성을 측정하는 지표로, 정밀도가 낮으면 거짓 긍정(false positive)이 많다는 것을 의미합니다.
3. 재현율(Recall, 또는 민감도(Sensitivity))
재현율은 실제 긍정 클래스의 모든 관측치 중에서 긍정으로 정확하게 예측된 관측치의 비율입니다. 이는 분류기의 완전성을 측정하는 지표로, 재현율이 낮으면 거짓 부정(false negative)이 많다는 것을 의미합니다.
4. F1 점수(F1 Score)
F1 점수는 정밀도와 재현율의 가중 평균입니다. 따라서 이 점수는 거짓 긍정과 거짓 부정 모두를 고려합니다. 클래스 분포가 불균형한 문제에 적합합니다.
5. ROC(Receiver Operating Characteristic) 곡선 아래 영역 (AUC-ROC)
ROC 곡선은 진짜 긍정 비율에 대한 거짓 긍정 비율의 그래프입니다. 이는 민감도와 특이성 간의 트레이드오프를 보여줍니다(민감도가 증가하면 특이성이 감소합니다). 곡선이 ROC 공간의 45도 대각선에 가까워질수록 테스트의 정확도가 떨어집니다. ROC 곡선 아래의 영역은 모델 성능을 정량화하며, 1은 완벽한 테스트를, 0.5는 가치 없는 테스트를 나타냅니다.
6. 혼동 행렬(Confusion Matrix)
혼동 행렬은 분류 모델의 성능을 설명하는 데 종종 사용되는 표입니다. 이는 진짜 긍정, 진짜 부정, 거짓 긍정(제1종 오류), 거짓 부정(제2종 오류)에 대한 정보를 포함합니다.
각 지표는 모델의 성능에 대해 다른 관점을 제공하며, 어떤 지표를 평가에 사용할지 선택할 때는 작업의 특정 상황과 목표를 고려하는 것이 중요합니다.
