우리는 예측 모델을 구축하기 위한 다양한 머신러닝 작업에 직면합니다. 그러나 좋은 모델을 구축하는 것만으로는 충분하지 않습니다. 모델의 성능을 확인하고 새로운 데이터에 일반화할 수 있는 능력을 점검해야 합니다. 이 때문에 교차 검증이 필요한 것입니다. 이 블로그 포스트에서는 교차 검증 개념에 대해 더 자세히 알아보고, 파이썬과 scikit-learn을 사용하여 이를 어떻게 구현하는지 알아보겠습니다.
교차 검증이란 무엇인가요?
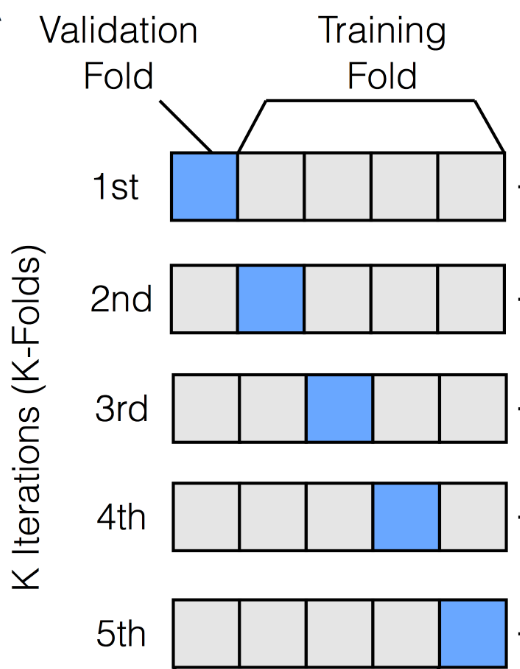
교차 검증은 모델의 성능과 새로운 데이터에 일반화하는 능력을 평가하기 위한 강력한 기법입니다. 이는 과적합을 방지하고 모델의 정확성에 대해 더 신뢰할 수 있는 측정치를 제공하는 데 사용됩니다. 교차 검증의 아이디어는 간단하지만 강력합니다. 데이터셋을 여러 하위 집합(폴드)으로 나눈 후, 모델은 다양한 하위 집합에서 훈련을 받고 나머지 하위 집합에서 평가를 받습니다.
K-폴드 교차 검증
가장 흔히 사용되는 교차 검증 기법 중 하나는 K-폴드 교차 검증입니다. 이 방법은 데이터셋을 'K'개의 폴드로 나눕니다. 이 폴드들은 대략적으로 동일한 크기를 가집니다. 모델은 'K'번 훈련하며, 각 폴드를 검증 세트로, 나머지 폴드를 훈련 세트로 사용합니다. 각 반복에서의 성능 점수는 평균화되어 전체 성능 지표를 제공합니다.
이제 파이썬과 scikit-learn을 사용하여 K-폴드 교차 검증을 어떻게 구현하는지 살펴보겠습니다.
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
# 데이터 로딩 및 전처리
data = pd.read_csv('data.csv')
X = data[['Feature1', 'Feature2', 'Feature3']]
y = data['Target']
scaler = StandardScaler()
X_stand = scaler.fit_transform(X)
# 모델 초기화
my_model = KNeighborsRegressor(n_neighbors=3)
# K-폴드 교차 검증 수행
cv = KFold(n_splits=5, shuffle=True)
r_square = cross_val_score(my_model, X_stand, y, cv=cv, scoring='r2')결과 해석하기
위 스니펫은 k-최근접 이웃 회귀 모델(KNeighborsRegressor)을 사용합니다. 그리고 5개의 폴드로 구성된 K-폴드 교차 검증을 수행합니다. 또한 데이터를 무작위로 섞어 폴드를 분할합니다(shuffle=True). 평가 지표로는 결정 계수(r2) 점수를 선택합니다.
결과인 r_square는 R-squared 점수들의 배열을 담고 있습니다. 각 점수는 모델이 다른 폴드에서 어떻게 수행하는지를 나타냅니다. 이 점수들을 분석함으로써, 모델의 일관성과 데이터 하위 집합 간의 변동성에 대한 통찰력을 얻을 수 있습니다.
결론
교차 검증은 데이터셋이 유한한 경우, 특히 모델 평가에 필수적인 도구입니다. 이를 통해 다양한 테스트 세트를 사용하여 모델의 성능에 대한 확신을 얻고, 새로운 데이터에 잘 일반화하는 모델을 보장할 수 있습니다. 특히, K-폴드 교차 검증은 여러 테스트 세트를 사용하여 모델의 정확성을 견고하게 추정합니다.
이 블로그 포스트에서는 교차 검증의 기본 개념을 다루고, 파이썬과 scikit-learn을 사용하여 교차 검증을 어떻게 구현하는지 설명하였습니다. 이제 여러분은 모델을 자신있게 평가하고, 모델 개발 중에 더 나은 결정을 내릴 수 있습니다.

잘 봤습니다. 좋은 글 감사합니다.