인공지능에 대해서 들어본 사람들은 머신러닝(Machine Learning)과 딥러닝(Deep Learning)이 있다는 것을 알 수 있을 것이다.
관계를 간단하게 설명하자면, 인공지능(Artificial Intelligence)의 하위 개념으로 머신러닝이 있고, 머신러닝의 하위 개념으로 딥러닝이 있다.
강화학습(Reinforcement Learning)은 Machine Learning의 한 분야이다. 또한, 지도 학습(Supervised Learning) 또는 비지도 학습(Unsupervised Learning), 자기지도 학습(Self-supervised Learning)처럼 강화학습도 데이터 학습 방법의 한 종류이다.
강화학습의 가장 대표적인 예로는 '구글(Google)'에서 발표한 '알파고(AlphaGo)'가 있다.
강화학습은 환경과의 상호작용을 통해 스스로 데이터를 만들고 이를 이용해 환경의 바람직한 변화를 일으키는 행동이 무엇인지를 스스로 학습하게 된다. 최근에는 딥러닝과 결합한 강화학습(Deep Reinforcement Learning)이 주목을 받고 있다.
강화학습(Reinforcement Learning)
강화학습은 에이전트(agent), 환경(environment), 상태(state), action(행동), 그리고 보상(reward) 의 다섯가지 요소로 구성된다. 여기서 에이전트는 의사 결정자이며, 환경은 시스템이다. 강화학습은 시간 변수가 존재하며 이는 일반적으로 불연속적(discrete)이다.
학습이 진행되는 동안 에이전트는 상태를 관측하여 일정한 정책하에 불연속적인 값으로 된 행동을 선택하여 이를 환경에 인가해 환경을 변화시키게 된다. 선택된 행동에 따라 즉시 또는 정해진 시간 간격마다(간헐적으로) 보상을 환경으로부터 제공받게 된다.
강화학습의 목표는 최종적인 누적 보상을 최대화하는 최적의 행동을 찾는 것이다.
강화학습의 프로세스(Process)
강화학습의 전체적인 프로세스는 다음과 같은 도식으로 나타낼 수 있다.
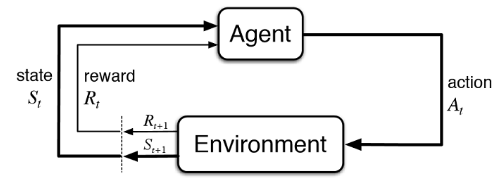
[출처:https://stevebong.tistory.com/4]
하나씩 설명하면 다음과 같다.
1. 에이전트는 환경의 상태()를 측정한다.
2. 현재 상태에서 에이전트의 규칙(정책)에 따라 최적 행동()를 선택한다.
3. 선택한 행동에 의해 환경의 상태는 다음 상태()로 전환된다.
4. 다음 상태()를 바탕으로 에이전트는 새로운 행동()을 선택한다.
5. 환경으로부터 주어지는 즉각적인 보상()을 사용해 장기적인 성과를 계산해서 에이전트의 정책을 즉시 또는 주기적으로 계산한다.
강화학습에서 이러한 프로세스가 반복되며, 에이전트는 매 time-step마다 에이전트는 환경의 상태를 측정하여 적절한 행동을 취하면 다음 상태로 전환된다. 행동에 따라 즉각적 혹은 주기적으로 보상을 얻게 된다.
이러한 프로세스를 수학적으로 모델링한 것이 마르코프 결정 프로세스(Markov Decision Process) 이다.
Markov Decision Process
MDP는 상태(), 상태천이 확률밀도함수(), 행동() 그리고 보상함수() 로 이루어진 이산시간 확률 프로세스(discrete-time stochastic process) 이다. MDP는 순차적으로 행동을 결정해야하는 문제를 풀기 위한 수학 모델이다.
이 때, 상태(state)와 행동(action) 은 이산공간 랜덤 변수(discrete-time variable) 이다.
상태천이 확률밀도함수는 상태()에서 행동()를 수행했을 때 다음 상태()로 갈 확률밀도함수 이며, 이다. 상태천이 확률밀도함수의 표기법에서 볼 수 있듯이 다음 상태로 갈 확률은 현재 상태()에만 영향을 받는 것 을 볼 수 있다. 이는 곧 마르코프 시퀀스에 해당하게 되는 것이다.
보상함수() 는 상태()에서 에이전트가 행동()를 선택했을 때 즉시 얻게 되는 보상으로 정의하며, 랜덤변수(random variable)이다.
강화학습의 5가지 요소에 포함되는 상태와 보상은 환경에서 주어지는 정보이다.
MDP문제는 누적 보상을 최대로 하기 위한 최적의 정책(각 상태에서 어떤 행동을 취할 것인가)을 구하는 것 이다. 즉, 를 구하는 것이다. 이 식에서 행동 도 랜덤 변수이므로, 상태 에서 여러개의 행동을 선택할 수 있고, 이를 확률적 정책 이라고 한다.
MDP의 프로세스는 다음과 같다.
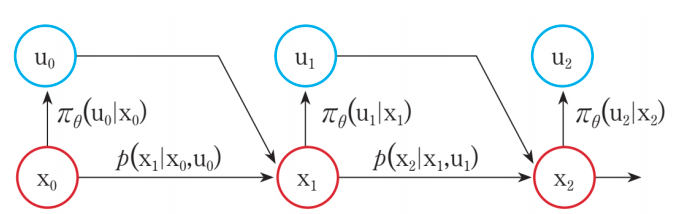
상태 에서 정책 에 의해서 행동 가 확률적으로 선택되면 상태천이 확률변수 에 의해 다음 상태 로 이동하게 된다. MDP는 보상이 즉시 주어지므로, 환경에 의해서 보상 이 주어지게 된다. 이 과정에서 행동이 선택될 때, 정책이 확정적이라면, 로 구해질 수 있다. 즉, 상태 값에 따라서 행동이 정해지게 되는 것이다(가능한 행동이 한 개). 반면에, 위의 예처럼 행동이 확률적으로 선택된다면, 현재 상태에서 행동이 확정적으로 정해지는 것이 아닌, 모든 행동이 가능해 지는 것이다. 따라서, 동일한 상태 값일 때에도 다른 행동을 할 수 있는 것이다. 이처럼 특정 상태에서 행동이 확정적으로 선택되냐 확률적으로 선택되냐에 따라서 확정적 MDP, 확률적 MDP 로 나뉘게 된다.
이와 같은 과정이 반복되면서 상태변수, 행동, 보상의 순서대로 전개되며, 이 시퀀스를 에피소드(episode) 라고 정의한다.
궤적(trajectory) 은 상태변수와 행동의 연속적인 시퀀스()며, 에피소드와 달리 보상은 포함되지 않는다.
이전에 MDP의 개념에 대해서 설명할 때, 누적 보상을 최대로 하기 위한 최적의 정책을 찾는 것이라고 설명하였다. 그렇다면 미래의 누적 보상은 어떻게 구해지는 것일까?
이를 설명하기 위해서 반환값(discounted return) 에 대해서 설명하면 다음과 같다.
반환값이란 시간 스텝 이후 미래에 얻을 수 있는 보상의 총합 을 말하며, 로 계산되며, 는 감가율을 나타낸다. 감가율이 작을 수록 에이전트가 먼 미래에 받을 보상보다 가까운 미래에 받을 보상에 더 큰 가중치를 둔다는 뜻이며, 반환값이 무한대로 발산하는 것을 막는 수학적 장치 역할도 하게 된다.
감가율이 작을수록 가까운 미래에 더 큰 가중치가 둔다는게 1에 가까운 값보다 0에 가까운 값이 더 가파른 그래프를 형성해서 그런 것 같음. 또한, 무한대로 발산하는 것을 막는다는 것은 면 이므로, 반환값은 보다 작아지게 된다. 가 수렴하므로, 반환값도 수렴하게 된다.
가치함수
가치함수에는 상태가치함수(State-value function)과 행동가치함수(Action-value function)이 있다. 상태가치(State-value)는 어떤 상태변수 에서 정책 에 따라 행동 의 행동이 가해졌을 때 기대할 수 있는 반환값의 기댓값 이다. 이산시간 일 때,
로 계산할 수 있다.
상태가치는 상태변수 에서 정책 로 기대할 수 있는 미래보상의 총합이다.
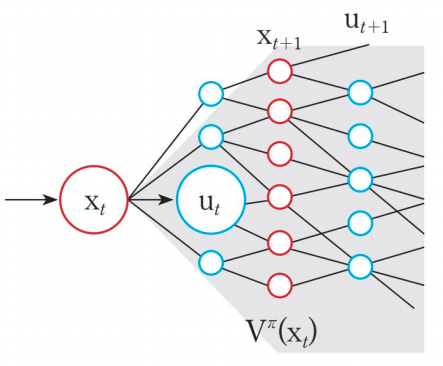
행동가치는 어떤 상태변수 에서 행동 를 선택하고 그로부터 정책 에 의해서 행동이 가해졌을 때 기대할 수 있는 반환값의 기대값 이다. 마찬가지로 이산시간 일 때,
이다. 즉, 행동가치는 상태변수 와 행동 에서 시작한 모든 가능한 궤적의 미래보상 총합의 기댓값인 것이다.
상태가치와 행동가치의 차이점은 상태 에서 행동 를 수행하기 전과 후의 차이이다. 상태가지는 에서 가능한 모든 행동의 궤적에 따라서 구해진 반환값의 기댓값이고, 행동가치는 에서 수행 한 후 가능한 모든 다음 상태 의 궤적에 따라 구해진 반환값의 기댓값인 것이다.
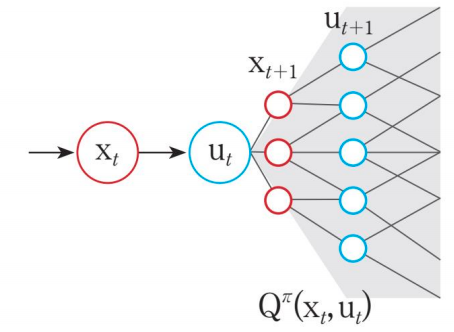
상태가치함수와 행동가치함수는 다음과 같은 관계를 가지고 있다. (유도는 생략)
상태가지는 상태변수 에서 선택 가능한 모든 행동 에 대한 행동가치의 평균값이다.
벨만 방정식
벨만 방정식을 내용위주로 설명하려 한다.
식의 우변에서 값 안에 존재하는 식을 보면, 현재 상태 에서 정책 를 따라 행동 를 행했을 때의 즉각 보상과 다음 상태 에서의 가치 함수 값에 감가율()를 곱한 값을 더한 식의 기댓값이다. 즉, 현재 상태 에서 가능한 모든 행동에 대한 의 기댓값인 것이다. 이처럼 벨만 방정식은 현재 상태변수의 가치와 다음 시간스텝에서의 상태변수의 가치의 관계를 나타낸 식이다. 이 때, 상태 가치 함수는 시간에 따라 변화하므로 와 은 다른 함수임을 기억해두어야한다.
이번에는 행동가치 함수로 이루어진 벨만 방정식이다.
이 식에서 우변을 보면, 행동에 따른 보상 와 다음 상태 에서 가능한 모든 행동에서의 가치 함수에 감가율을 적용한 값에 에서 가능한 모든 값에 대해 기댓값을 한번 더 적용해주었다.
강화학습은 최대 보상을 만드는 최적 정책을 찾는것이 최종 목적이기 때문에, 모든 정책 중에서 가치함수 값을 최대로 만드는 정책을 적용했을 때의 상태가치 함수와 행동가치 함수를 각각 최적 상태가치 함수, 최적 행동가치 함수라고 한다.
최적 상태가치 함수는 다음과 같다.
또한, 최적 행동가치 함수는 다음과 같다.
위의 최적 상태가치 함수와 행동가치 함수를 비교하면 다음과 같은 관계식을 얻을 수 있다.
상태 가치 함수는 행동가치 함수를 행동에 관해 평균값을 취한 것이므로, 위의 식을 이에 대입하면,
의 관계를 가지게 된다. 이 때, 상태가치를 최대로 만드는 정책이 최적 정책이므로, 최적 정책 는
이처럼, 최적 정책은 최적 가치 함수 뿐만 아니라 최적 정책으로도 표현할 수 있게 된다.
강화학습 종류
강화학습은 반복(iteration) 과정을 통해 최적 정책(optimal policy)를 산출한다. 또한, 강화학습의 방법론은 환경 모델을 추정하는가, 가치함수를 추정하는가, 정책을 ㅇ떤 방법을 통해 개선시킬 것인가에 따라 달라진다.
가치 기반(Value-based) 강화학습
가치함수를 추정해 최대의 보상을 계산함으로써 최적의 정책을 얻는다.
먼저, 행동 가치함수를 추정한 후에, 각 state에서 행동가치 함수를 최대화하는 행동을 선택해 최적 정책을 유도한다.
state, action이 이산 공간을 기반으로 하는 DQN(Deep Q Network)등이 대표적이다.
정책 그래디언트(Policy Gradient)
직접 정책을 유도하는 방법이다.
정책 파라미터 공간을 직접 탐색하여 최적의 정책을 찾는 것을 목적으로 하며, 일반적으로 정책은 신경망으로 모델링한다.
정책 그래디언트 방법에서는 보통 가치함수도 함께 추정하여 정책의 성과를 평가하는 액터-크리틱(actor-critic) 구조를 사용한다.
모델 기반(Model-based) 강화학습
환경 모델을 추정해 사용하는 방법이다.
간단하고 효율적이며, 경쟁력 있으며 로봇 제어, 드론 제어 분야에서 인기있는 방법론이다.
정책을 개선할 때는 환경 모델을 정의하는 방식에 따라 다양한 방법이 사용된다.
