[개발일지 2022.4.8] 파이썬 데이터관련 필수 라이브러리(2)
1.학습한 내용
1)Pandas 마무리
지난 시간에 이어서 Pandas 의 수업을 추가로 진행하였다.
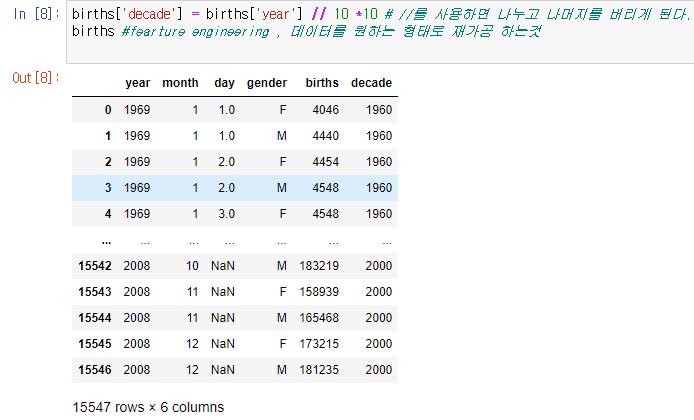
pd.read_csv 명령어를 이용해서 웹에서 미국출생률 데이터를 가져온다.

이후 몇년대인지를 알기위해서 decade 항목을 추가한다.
이때 //의 의미는 나누기가 아닌 나누고 소수점을 버리는 코드이다.
위의 정보들을 이용하여서 그래프를 그리려면 다른 라이브러리 matplotlib 이 필요하다. 따라서 이를 import 한다.
import matplotlib.pyplot as plt
#그래프를 그리기 위한 라이브러리 matplotlib그 후 그래프를 그리는 코드를 사용한다.
births.pivot_table('births',index='year',columns='gender',aggfunc='sum').plot()이때 y값은 births , x값은 year 로, 그려지는 분류는 gender, 표시되는 값은 해당 수치들의 합을 뜻한다.
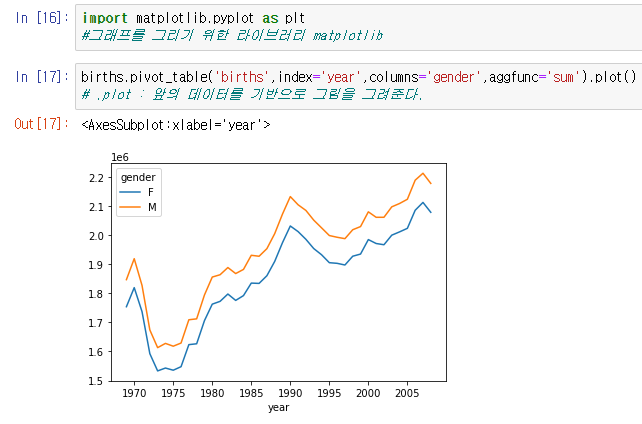
위와 같은 그래프가 그려진다.
2)Matplotlib 데이터 시각화
이전의 pandas 실습에서도 사용했듯이
Matplotlib 라이브러리를 사용하면 데이터를 시각화가 가능해진다.
우선 라이브러리를 불러온다.
import matplotlib.pyplot as pltmatplotlib.pyplot 을 앞으로 plt라 부른다.
또한 Numpy 명령어를 사용할 예정이기때문에 numpy 라이브러리도 불러온다.
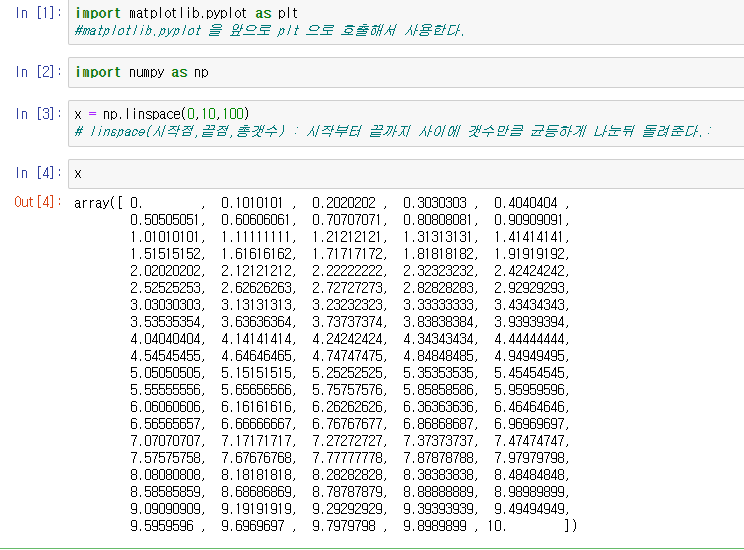
import numpy as np그 후 기능중 하나인 linspace를 사용해본다.
x = np.linspace(0,10,100)linspace(시작점,끝점,총갯수) : 시작부터 끝까지 사이에 갯수만큼 균등하게 나눈뒤 돌려준다.
이후 numpy 를 사용하여
np.sin(x)
sin값을 구할수도 있으며
matplotlib 라이브러리를 사용하면
plt.plot(x, np.sin(x))
plt.plot(x, np.cos(x))
그래프를 그릴수도있다.
또한 이를 한 코드에 동시에 입력을 하게되면
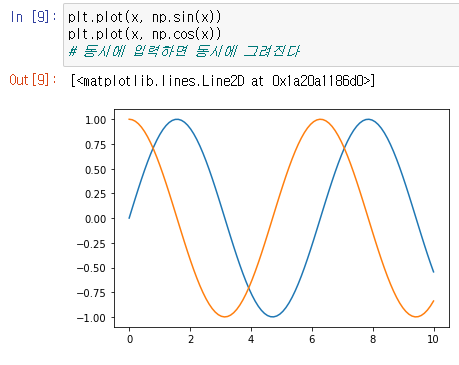
한 화면에 두개의 그래프가 동시에 나타난다.
이후 figure 코드를 이용하게되면
fig=plt.figure()
# figure의 뜻: matplotlib 에 그림판을 하나 준비한다.
plt.plot(x, np.sin(x),'-')
# (x축,y축,선의 타입) 으로 설정할수있다.
plt.plot(x, np.cos(x), '--')
# - : 선으로 이루어진 그래프, --: dash선으로 이루어진 그래프
fig.savefig('my_figure.png')
# 이 코드를 실행한 폴더에 my_figure.png 라는 이름의 이미지 파일이 만들어졌다.를 통해서 이미지 파일을 만들어 낼수도있고.
IPython.display 라이브러리의 Image 기능을 통해서
해당 이미지 파일을 불러낼수도있다.
fig.canvas.get_supported_filetypes()위의 코드를 통하여서 지원하는 파일들의 유형들을 확인할수도 있다.

그래프를 한 그림안에 넣는것이 아니라 나누어서 두가지 이상의 그래프를 그릴려고 할때는 plot안의 plot, subplot 을 사용하게된다.
plt.subplot(2,1,1)
plt.plot(x,np.sin(x))
plt.subplot(2,1,2)
plt.plot(x,np.cos(x))위의 코드는 한화면에 2개를 표현할때 1번째로 표현하는것은 sin(x), 두번째로 표현하는것은 cos(x) 라는 코드이다.
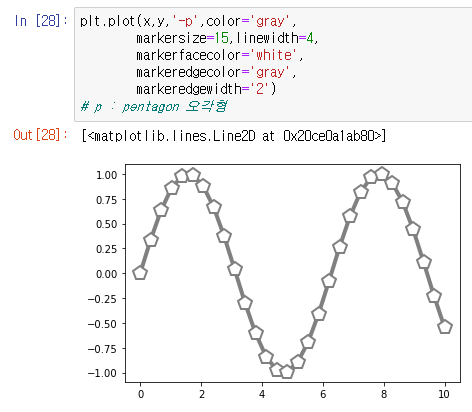
plot 을 사용하다보면 여러가지 정보를 지정할수있는데, 예를 들어 색,선의 형태 등이 있다.
이때 색을 바꾸려면 코드안에 color를 넣게 되는데.
그림과 같이 여러가지 수단으로 color 를 지정해줄수 있다.
또한 선의 형태도 설정할수있는데.
solid 혹은 - 의 경우에는 실선을
dashed 혹은 -- 의 경우에는 파선을
dashdot 혹은 -. 의경우에는 실선과 파선을
dotted 혹은 : 의 경우에는 점선을
표현할수있다.
지금까지의 plot들은 임의의 x축기준과 y축 기준으로 그래프가 그려지게 되었는데,
이를 xlim, ylim을 사용하여 x축범위와 y축범위를 지정해줄수 있다.
또한 낮은 숫자에서 높은숫자로 가는 그래프를 높은숫자에서 낮은숫자로 가는 그래프로 뒤집어서 그래프를 그릴수도있다.
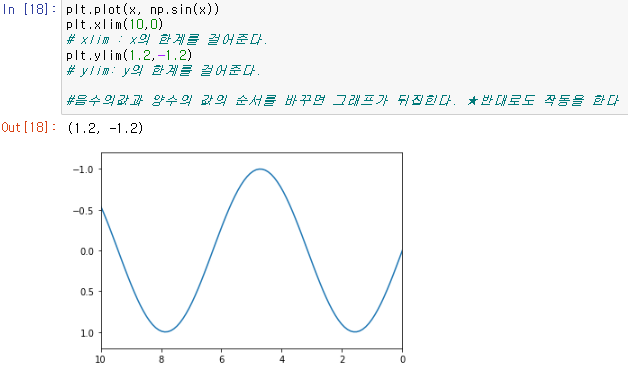
또한 이 기준을 임의로 설정하는것이 아니라 정해진 값들로 지정하는것 또한 가능한데.
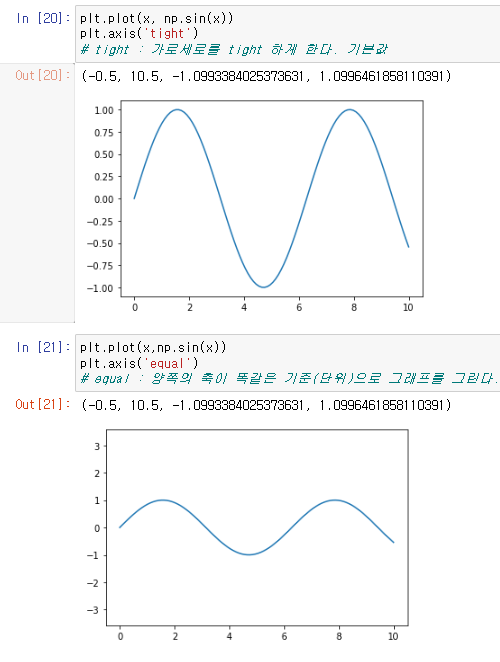
기본값과 같은 tight, 그리고 x축기준과 y축기준이 같도록 설정하는 equal 등이 있다.
그래프의 이름, x축과 y축 이름등을 설정할수 있는데.
그래프의 이름은 plt.title()
x축의 이름은 plt.xlabel()
y축의 이름은 plt.ylabel()
로 표현할수있다.
또한 그래프 자체에 label을 붙이게 되면 이를 legend() 코드를 사용하는것으로 그래프의 이름도 표현이 가능하다.
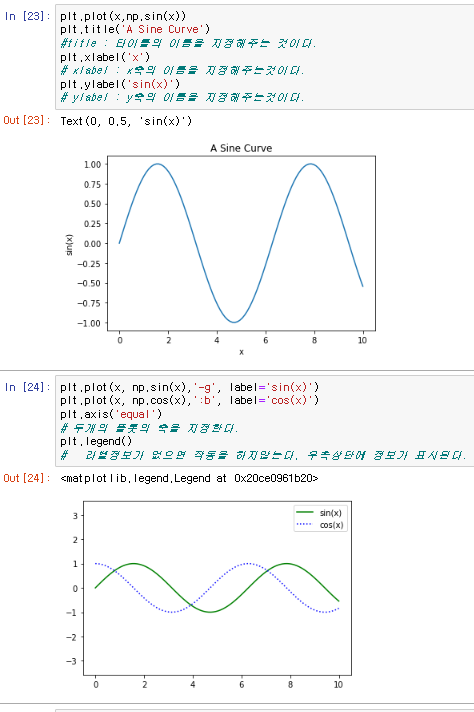
또한 데이터가 그래프에서 존재하는 위치를 확인할때 선으로는 명확하게 구별이 되지않으므로 해당 지점에
'o' 'x' '+' 'v' 등 다양한 marker 를 사용하는것으로 가능 하다.
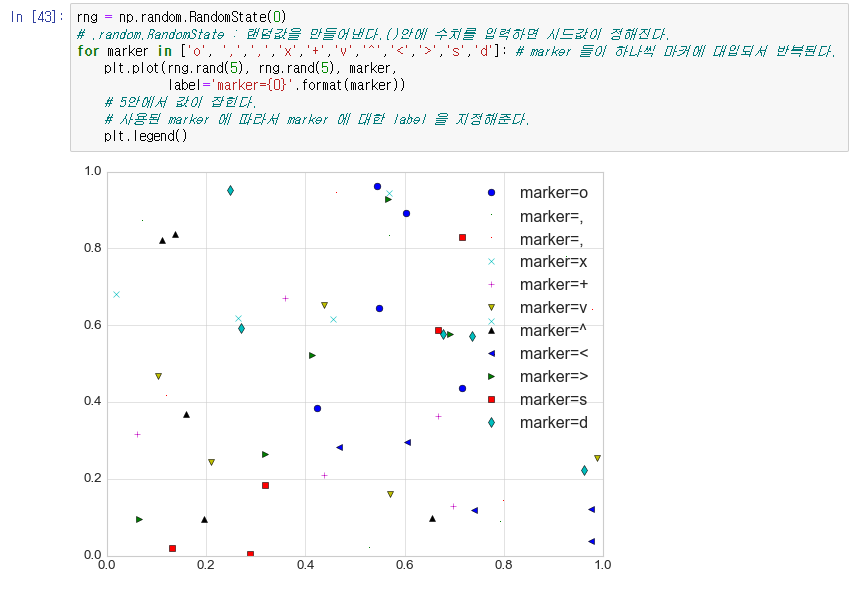
위에 배운것들을 종합하여서
데이터의 위치에 마커, 마커의 모양, 마커의 크기, 마커들 사이를 이어주는 선, 그 선의 길이 등을 설정할수 있다.
이제 지정된 데이터 값들이 아닌 랜덤한 값을 가져와서 그래프를 찍어보는것을 할것인데, 이는 Numpy의 RandomState를 이용하게 된다.
x값이 랜덤, y값이 랜덤이고 컬러도 랜덤이고,
찍히는 마크의 사이즈도 랜덤일때 점을 찍는다, 단 같은지점에 점이 찍히면 구별이 되지않을수 있으므로 점에는 투명도를 부여한다.
rng = np.random.RandomState(0)
x = rng.randn(100)
y = rng.randn(100)
color = rng.rand(100)
sizes = 1000 * rng.rand(100)
plt.scatter(x,y, c=color, s=sizes, alpha=0.3, cmap='viridis')그리고 마지막으로 해당 그래프에서 사용한 색상의 표를 불러온다.
plt.colorbar()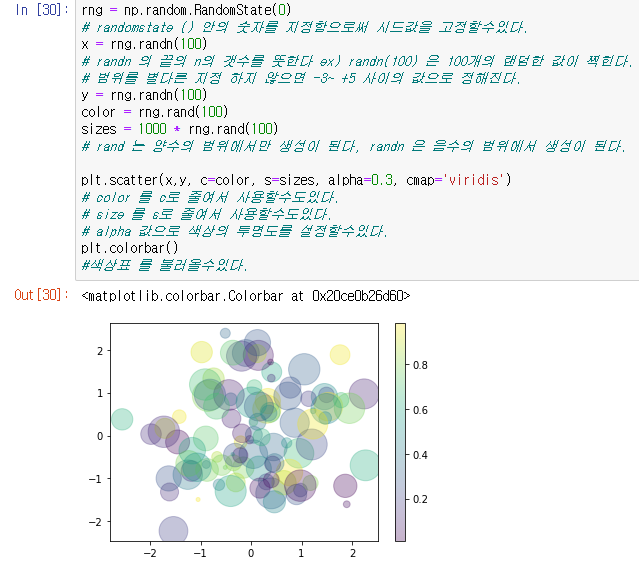
이를 활용하여 실습하게되면
이전에 orange에서 사용했던 iris 값을 예시로 들면
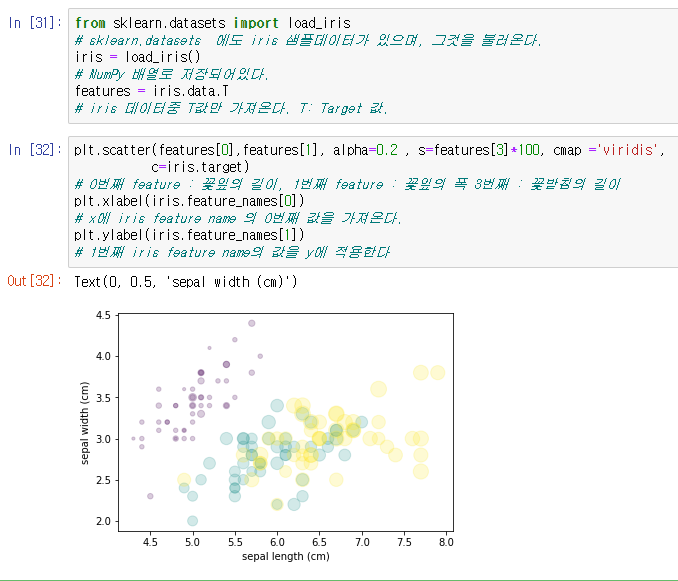
붓꽃의 종류에 따라서 색을 다르게하여 종류별로 구별이 되고,
꽃받침의 길이에 따라서 점의 점의 크기가 달라지게되고,
투명도를 설정함으로써 진할수록 해당 지점에 데이터가 많다는것을 보기쉽게 확인할수있게된다.
또한 데이터들에는 오차범위가 존재할수 있는데,
이 오차범위에 대한것을 그래프에 errorbar 로 표현이 가능하다.

위의 그림의 경우 점의 위치가 데이터이고 점에 그어진 선이 오차로써 나올수도있는 위치들의 범위를 표현해준다.
검은점에 검은선을 긋는것으로 보기가 힘들어진것을
그래프의 style 자체를 설정하는 style 으로 그래프의 표 자체를 보기 쉽게 정리해주고 선의 색깔 등을 조절하게되면
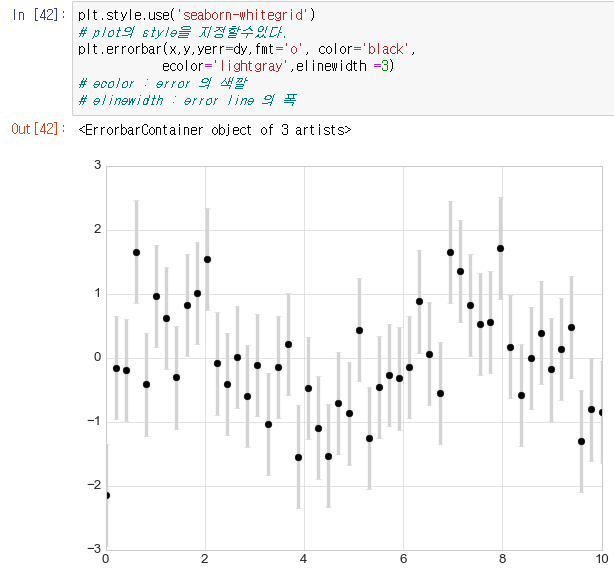
그림과 같이 칸마다 선이 그어져있는 곳에서 데이터의 위치와 선들을 볼수있게된다.
3)Scikit Learn
머신 러닝을 위해 사용되는 대표적인 라이브러리
간단한 머신러닝 모델을 생성할수있다.
scikit-learn 라이브러리
머신러닝을 구현한 오픈소스 라이브러리중 가장 유명한 라이브러리중 하나인다.
일관되고 간결한 API가 강점이고 문서화가 잘 되어있다.
알고리즘은 Python class 로 구현되고 데이터셋은 Numpy 배열, Pandas DataFrame, SciPy 희소 행렬을 사용할수있다.
scikit-learn 데이터 표현 방식
특징 행렬(Feature Matrix)
특징들에 따른 표로 되어있다
우선 scikit-learn 의 라이브리를 불러온다.
import sklearn
from sklearn.datasets import load iris
iris_dataset = load_iris()
print(f'iris_dataset key:{iris_dataset.keys()}')라이브러리를 불러오고, 그 라이브러리에서 iris의 데이터를 불러와서 해당 데이터를 iris_dataset 에 입력을 한뒤.
데이터가 제대로 입력되었는지 확인하기 위해서
dataset의 key값이 무엇인지 출력한다.

이로인해 키값으로는 data ,target , frame, targe_names, DESCR , feature_names , filename 이 있다는 것을 알수있게 된다.
이들의 값을 print 하는것으로 확인할수 있지만.
이중에서 DESCR , Describe, 데이터셋에 대한 설명값을 로드하게되면
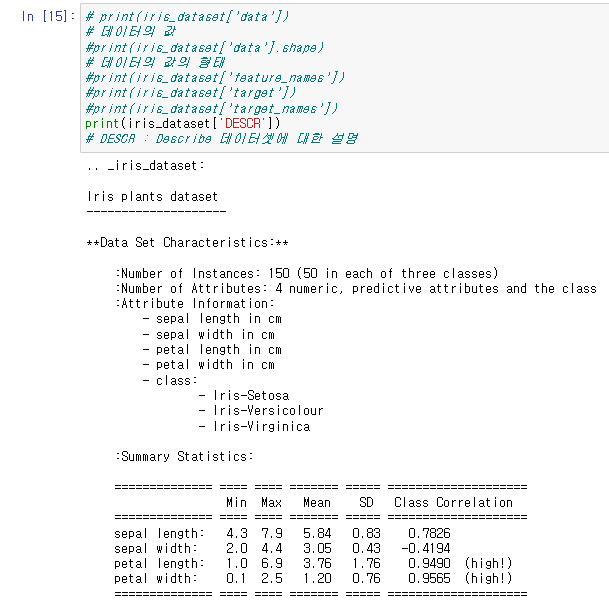

그림과 같이 데이터셋에 대한 내용을 설명해주는 장문의 글이 출력된다.
데이터 분류
이제 데이터들을 이용해서 machine learning을 하고자 한다.
이때 machine learning 에 필요한 데이터가 orange를 사용해보는 과정에서
학습용 input 데이터, 학습용 label 데이터,
테스트용 input 데이터, 테스트용 label 데이터가 필요한 것을 알수있었다.
따라서 이를 위해서 큰 데이터셋을 용도에 따라서 분류하는 명령어가 필요하다.
이를 위해서
from sklearn.model_selection import train_test_splittrain_test_split 라이브러리를 가져온다.
이에 따라서 iris 데이터를 분류하려면
train_test_split(iris_dataset['data'], iris_dataset['target'], test_size=0.25,random_state=42)x축(input값)을 iris_dataset 의 data 값, y축(label값)을 iris_dataset의 target 값을 가지며, 이를 test용으로 25%를 가지도록(따라서 학습용은 75%) 분류하는 명령어를 입력하게된다.
이렇게 나뉘어진것을 확인하기 위해서
print(train_input.shape)
print(test_input.shape)
print(train_label.shape)
print(test_label.shape)의 코드를 입력하게 되면

iris 데이터의 갯수가 150개인데
이때 훈련용으로 나뉜 75% 로 112개, 테스트용으로 38개로 나뉜것을 확인할수있게 된다.
또한 테스트의 값은 하나이기때문에 테스트용 데이터들의 형태에는 2차원의 값이 없는것을 확인할수있다.
최근접 알고리즘
알고리즘에서 데이터를 입력할때 입력한 정보가 어떤 분류에 들어가는가를 확인하는 과정이 필요한데, 이 과정에서 데이터를 확인할때 해당 데이터와 가장 가까운 데이터의 영역의 값을 가지게 된다.
이때 기준점의 갯수가 많을수록 데이터의 신뢰도가 올라간다.
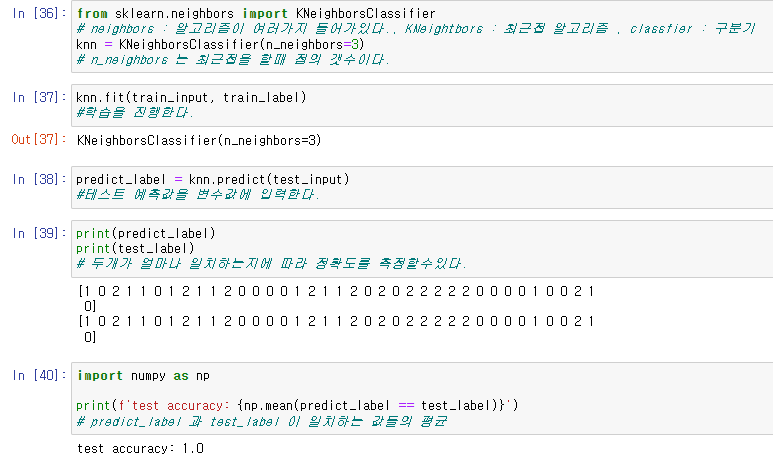
이 값은
test의 값과 예측값을 비교했을때 정확도가 100%가 나온다는것을 확인할수 있었다.
※정확도가 100% 인것은 무조건 좋은것이 아니라, 데이터가 과적합한것이기 때문에 조금이라도 다른 데이터를 입력하면 오차가 크게 나타날수 있는 위험이 있다.
2.학습내용 중 어려웠던 점
영어가 어렵다
이번 수업은 이전과 마찬가지로 라이브러리의 형식을 그대로 가져와서 사용하는것으로 빠르게 지나갔다.
이를 따라서 입력해보는 과정에서 대괄호 중괄호 괄호 가 필요에 따라서 바뀌어서 입력되는 것들이 어려웠다.
3.해결방법
빠르게 바꾸어서 입력하시는것을 글씨가 작은탓에 놓쳐서 오류가 난 다음에야 코드를 다시 들여다보는것으로 올바르게 고쳐서 입력하는것으로 해결했다.
4.학습소감
오늘의 강사님의 수업은 이러한 코드가 있다, 이 코드를 이렇게 사용하면 이런결과가 나온다. 의 식으로 결과를 볼수있었으며, 이를 따라 입력하는것으로 오류가 나면 강사님의 코드와 비교를 하는것으로 틀린점을 찾는 방식으로 고칠수 있었지만.
이는 모두 좋은 데이터를 가지고 정해진 틀에 맞춰서 입력하고 난것을 듣게 된것이기 때문에, 잘못된 데이터를 가지고 사용하게 되면 어떻게 되는지에 대해서는 개인적으로 찾아서 연습을 하는식으로 새로 배워나가야할것같다.
