1.학습한 내용
1)Preprocessing 전처리
-데이터를 분석하기 용이하게 고치는 모든작업.
-데이터 사이언스 전 과정에서 알고리즘 자체를 수행하는것보다 전처리 과정에서 더 많은 시간을 소비한다.(전체 프로젝트의 8~90%)
-알고리즘이나 파라메터가 잘못된 경우에는 지속적인 실험으로 문제를 찾아서 개선해 나갈 수 있지만, 데이터 자체가 잘못된 경우에는 실험 결과가 개선되지 않음.
데이터의 경우 다음과 같은 문제점들이 있을 수 있다.
결측치: 중요한 데이터가 빠져있다.
데이터오류: 잘못된 데이터가 입력되어있다.
이상치 : 값의 범위가 일반적인 범위에서 벗어나 있다.
데이터형식: 데이터 형식이 분석하기에 적합하지 않다.
범주형 데이터: 범주형으로 표현되어야 하는 데이터가 다른형태로 되어있다.( 1 or 0 인 데이터로 나뉘는 데이터, 범주형 데이터 Categorical 을 범주형 데이터로 설정하지 않으면 숫자로 인지하여 계산을 한다.)
이를 해결하기 위해서 사용되는 대표적인 데이터 전처리 기법
-Scaling 스케일링
-sampling 샘플링
-Dimensionality Reduction
-Categorical Variable to Numeric Variable
전처리를 위하여 필요한 라이브러리들을 호출한다.
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as pltabalone_columns = list()
for l in open('data/abalone_attributes.txt'):
abalone_columns.append(l.strip())
data = pd.read_csv('data/abalone.txt',header=None, names=abalone_columns)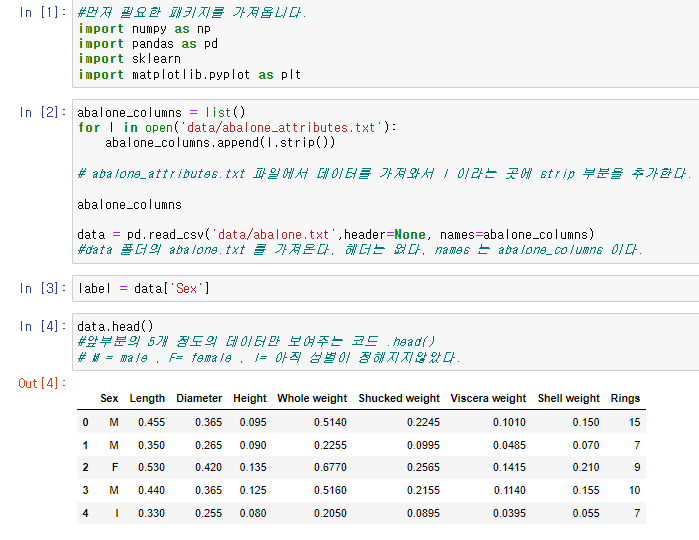
그리고 위에서 얘기한대로 데이터를 고치는 방법중 삭제하는 방법으로는 del 코드를 사용할수있다.
예를들어 데이터표에서 sex라는 항을 지우려면
del data['Sex']를 입력한뒤 출력하면
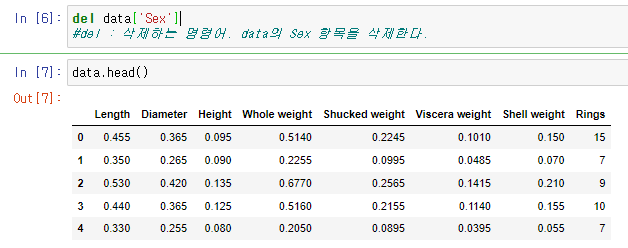
그 전의 표에서 sex라는 줄이 사라진것을 확인할수있다.
이후
데이터의 정보를 한눈에 확인하는 describe 명령어, 전체데이터의 형태를 확인하는 info 명령어를 사용하게 되면
data.describe()
data.info()
사진과 같이 표의 데이터의 갯수, mean : 평균 ,std : 표준편차, min:최소값 max :최대값 같은 정보를 describe 를 통해 알수있고, column, dtype 등을 infor 를 통해 알수있다.
2)Scaling
변수의 크기가 너무 작거나 너무 큰 경우 결과에 미치는 영향력이 일정하지 않을 수 있음-> 변수의 크기를 일정하게 맞추어 주는 작업을 Scaling 이라고 함.
(단위를 맞추어 주는 작업)
2-1) min-max scaling
값의 범위가 0~1 사이로 변경된다.
특정 값들이 전체에 미치는 영향을 줄여서 모든 값들이 단위 크기와 상관없이 중요한 영향력을 가질수 있게 하기 위함.

data = (data - np.min(data))/(np.max(data)-np.min(data))위의 수식을 코드로 만든것이다.
이를 입력하면
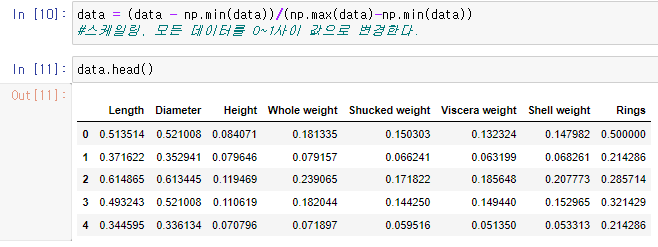
사진과 같이 데이터의 범위가 0~1사이로 scaling 된것을 확인할수있다.
하지만, 이러한 코드들 또한 이미 만들어져서 라이브러리로 존재하기 때문에, 이를 활용하게 된다면
from sklearn.preprocessing import MinMaxScaler
mMscaler = MinMaxScaler()이를 통해서 민맥스스케일러를 활성화 하고.
mMscaled_data = mMscaler.fit_transform(data);이때, fit 코드와 transform 의 코드가 따로있지만, fit은 데이터를 적용만 시키기 때문에, transform 을 통해서 변환을 하기때문에, 항상 함께 쓰인다.
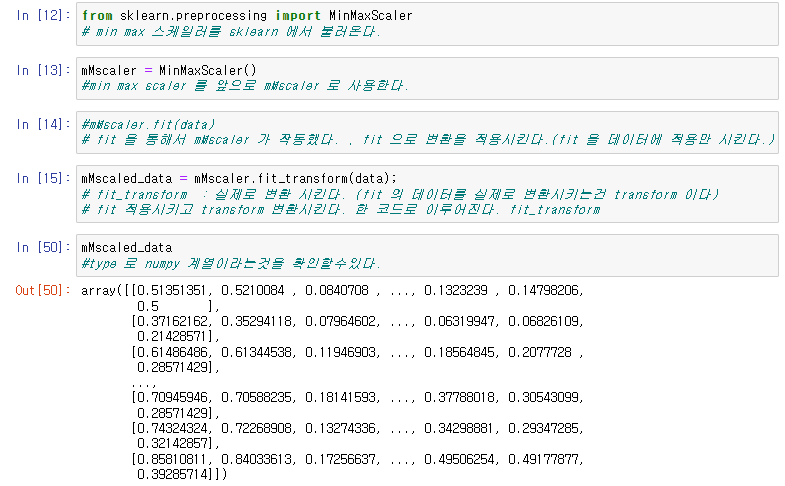
이러한 라이브러리를 이용하여 위의 코드와 동일한 결과가 나오는것을 확인할수있다.
2-2) Standard Scaling
-z-score 라고 부르는 데이터를 통계적으로 표준정규분포화 시켜 스케일링 하는 방식이다.
-데이터의 평균이 0
표준편차가 1이 되도록 스케일링 한다.
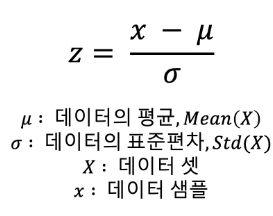
이 또한 MinMaxscaler 와 같이 이미 라이브러리가 존재한다.
from sklearn.preprocessing import StandardScaler
sdscaler = StandardScaler()그리고 코드의 형태 또한 비슷한데, 이를 사용하면.
sdscaled_data = sdscaler.fit_transform(data)
평균이 0, 표준편차가 1이 되도록 스케일링이 된것을 볼수 있다.
3)Sampling 샘플링
샘플링을 하는 이유는 클래스 불균형 문제를 해결하기 위함
클래스 불균형 문제란
분류를 목적으로 하는 데이터 셋에 클래스 라벨의 비율이 균형적으로 맞지 않고 한쪽으로 치우치게 되어 각 클래스의 데이터를 학습하기 어려워지는 경우
샘플링의 두가지 방법
-적은 클래스의 수를 증가시키는 OverSampling
-많은 클래스의 수를 감소 시키는 UnderSampling
이 있다.
우선 내 컴퓨터의 경우에는 imblearn 이 설치가 되어있지 않았기 때문에 이를 install 을 진행하였다.
!pip install imblearn
그후 오버샘플링과 언더샘플링을 활성화한다.
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
ros = RandomOverSampler()
rus = RandomUnderSampler()이때 기준이 되는 샘플의 shape를 먼저 확인한다.
data.shape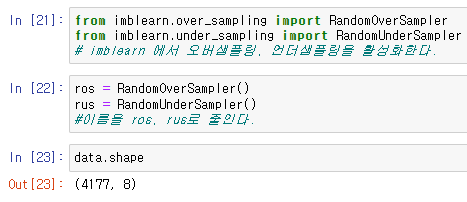
위의 결과를 통해 기본이 되는 data의 shape는
(4177,8) 임을 알수있다.
3-1) 오버샘플링 OverSampling
샘플들의 수를 증가시키는 것으로
oversampled_data, oversampled_label = ros.fit_resample(data,label)
oversampled_data = pd.DataFrame(oversampled_data,columns= data.columns)resample 을 통하여 oversampling 을 진행하면
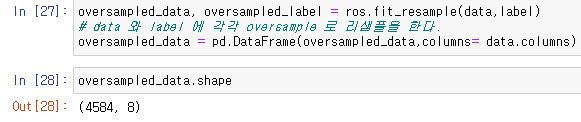
(4177,8) 이었던 데이터의 형태가 (4584,8) 로 늘어난것을 확인할수있다.
3-2) 언더샘플링 UnderSampling
샘플들의 수를 감소시키는 것으로
undersampled_data,undersampled_label = rus.fit_resample(data,label)
(4177,8) 이었던 데이터의 형태가 (3921,8) 로 줄어든것을 확인할수있다.
3-3) SMOTE (Synthetic Minority Oversampling Technique)
임의의 Over,Under 샘플링은 데이터 중복으로 인한 과적합 문제, 데이터 손실의 문제가 있어서 그런 문제를 최대한 해결할수 있는 SMOTE알고리즘이 제시되었다.
SMOTE 알고리즘은 수가 적은 클래스의 점을 하나 선택해 k개의 가까운 데이터 샘플을 찾고 그 사이에 새로운 점을 생성하는 방식
SMOTE의 장점은 데이터 손실이 없고 과적합을 완화 시킬수있음.
우선 기준이 되는 데이터를 불러온다.
from sklearn.datasets import make_classification
data ,label = make_classification(
n_samples=1000,
n_classes=3 ,
n_features=2,
n_repeated=0,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
weights=[0.05,0.15,0.8],
class_sep=1,
random_state=2022
)이를 먼저 확인하면

데이터가 이렇게 되어있고
이를 그래프를 그려서 시각화하여 확인하면
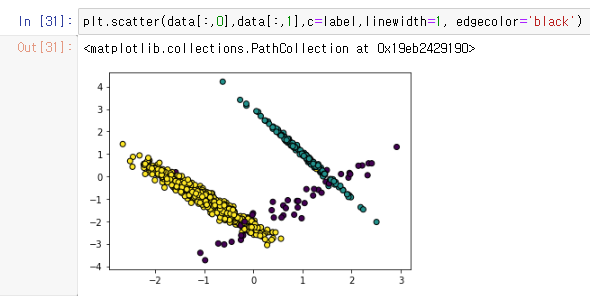
이제 이를 기준으로 데이터를 SMOTE 를 통하여 샘플링을 진행한다.
우선 라이브러리에서 SMOTE를 활성화한다.
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=5)그 후 smote의 명령어를 사용한다.
smoted_data, smoted_label = smote.fit_resample(data,label)이때, 결과값인 smoted_data 와 smoted_label 이 이전의 data와 label 과 어떻게 달라졌는지를 알려주기 위해서
두가지를 출력하는 명령어를 입력한다.
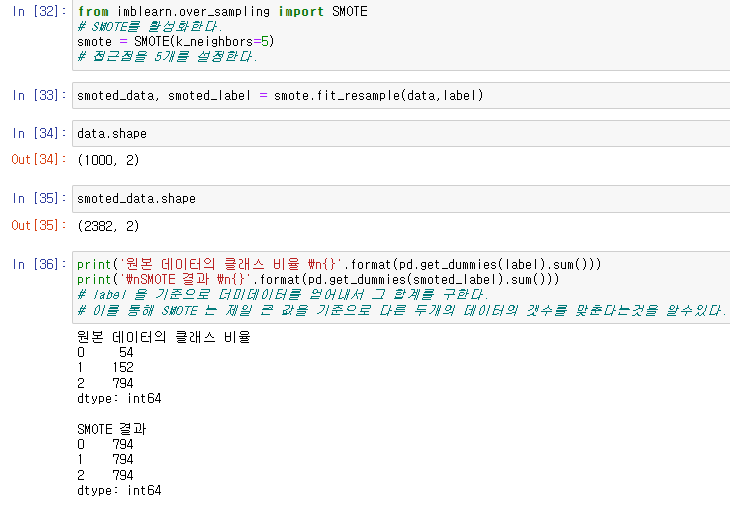
이 결과를 통해서 SMOTE 샘플링은 랜덤하게 데이터를 늘리거나 줄이는것이 아니라, 표본중 가장 수가 많은 데이터를 기준으로 다른 데이터들의 수를 맞추어서 늘린 다는것을 알수있다.
이를 시각적으로 확인하기 위해서 그래프를 그리게되면.
plt.scatter(smoted_data[:,0],smoted_data[:,1], c=smoted_label , linewidth=1,edgecolor='k')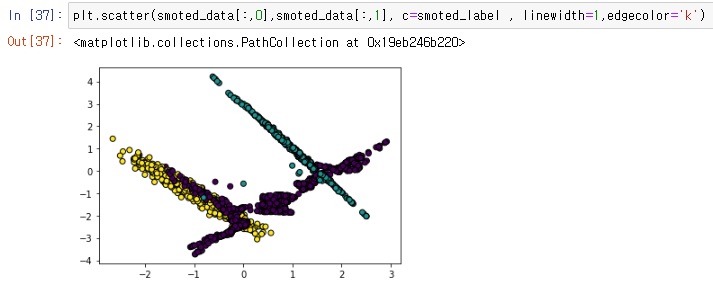
기존에 데이터의 수가 적어서 눈에 띄지 않았던 부분들이 짙어진것으로 데이터가 늘어난것을 확인할수있다.
4) Dimensionality Reduction (차원축소)
차원의 저주
차원의 저주는 저차원에서 일어나지 않았던현상들이 고차원에서 데이터를 분석하거나 다룰때 발생하는 현상.
차원의 저주가 발생하는 이유
- 고차원으로 올라갈 수록 공간의 크기가 증가
-공간의 크기가 증가할 경우, 데이터가 존재하지 않는 빈공간이 생김 - 이런 빈 공간들이 데이터를 해석할 때 문제를 일으킴.
따라서, 데이터의 차원이 불필요하게 큰 경우에는 필요 없는 변수를 제거하고 과적합을 방지하기 위해서 데이터 차원을 축소한다.
과적합의 이유 말고도 높은 차원의 데이터는 사람이 해석하기에도 어려움이 있어서 차원을 축소하는 작업을 하기도 한다.
예를 들어 그림의 경우가 있다.
우선 데이터셋을 하나 가져온다.
from sklearn.datasets import load_digits
digits = load_digits()이때 가져온 digits 데이터셋의 형태를 알기 위해
digits.data.shape를 입력한다.
그리고 기존의 데이터를 2차원으로 차원축소를 한뒤 보여주는 코드를 입력한다.
data = digits.data
label = digits.target
plt.imshow(data[0].reshape(8,8))
print('Label : {}'.format(label[0]))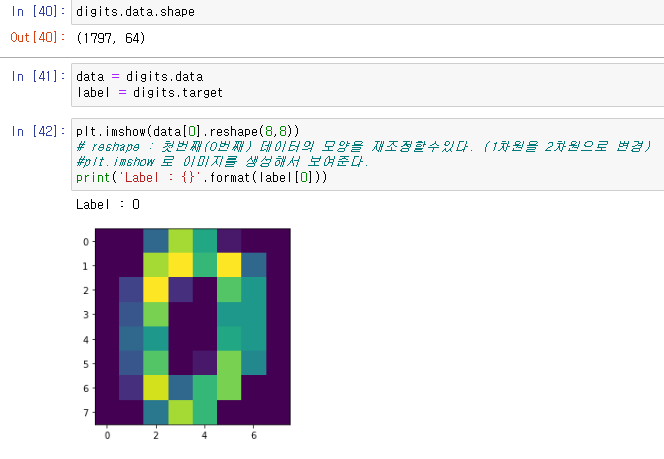
reshape 를 통하여 기존의 데이터값을 2차원으로 변경하여서 이미지를 보여주는것으로 이미지를 볼수있다.
4-1) 주 성분 분석(Principal Component Analysis ,PCA)
대표적인 차원 축소 기법으로 주 성분 분석(PCA)이 사용된다.
PCA는 여러 차원으로 이루어진 데이터를 가장 잘 표현하는 축으로 Projection 해서 차원을 축소하는 방식을 사용함.
데이터를 가장 잘 표현하는 축이란 데이터의 분산을 잘 표현하는 축임
주성분은 데이터 셋을 특이값 분해를 통해서.
얻어지는 고유한 벡터값.
주 성분 분석을 활성화한다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)이때 n_componets=2 는 데이터를 2차원으로 만든다는 의미이다.
이후 pca를 이용해서 새로운 데이터를 만든다.
new_data = pca.fit_transform(data)이 둘을 비교를 하면 64차원이었던 데이터를 2차원 데이터로 변환하였다는것을 알수있다.
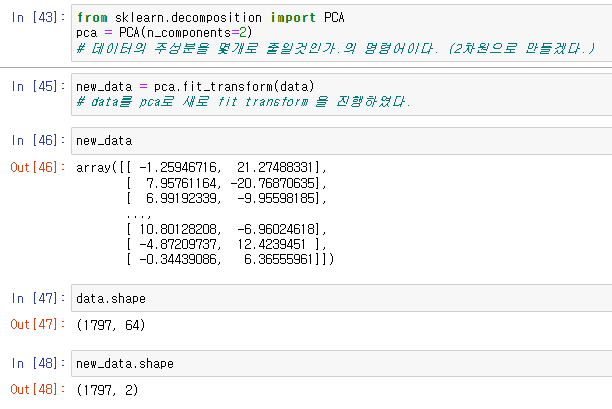
이를 통해서 64차원이어서 그래프에 표현할수 없었던 데이터를 2차원으로 바꿈으로써 그래프에 표현이 가능해졌다.
plt.scatter(new_data[:,0],new_data[:,1], c=label, linewidth=1 ,edgecolor='k')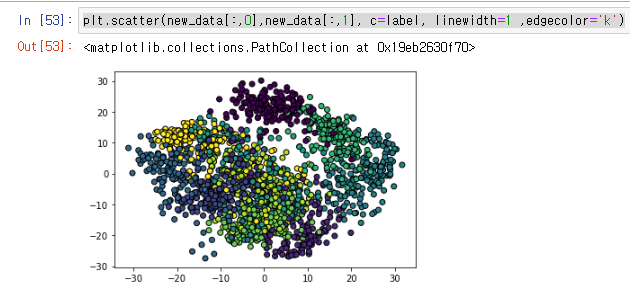
5) Categorical Variable to Numeric Variable
범주형 데이터란 차의 등급을 나타내는 소형,중형,대형과 같이 범주로 분류될수있는 변수를 의미한다.
범주형 데이터는 주료 데이터 상에서 문자열로 표시되는데 문자와 숫자가 매핑 되는 형태로 표현되기도 한다..
컴퓨터가 data를 활용하여 모델화하고 학습하기 위해서는 data를 모두 수치화 해야한다.
수치화방법으로는 label Encoding 과 One-hot Encoding 이 있다.
5-1) Label Encoding
label Encoding 은 n개의 범주형 데이터를 0~ n-1 의 연속적인 수치 데이터로 표현한다.
간단한 방법이지만 문제를 단순화 시킬수있다.
예시를 들기위해서 전복의 데이터를 불러온다.
data = pd.read_csv('data/abalone.txt',header=None, names=abalone_columns )
label = data['Sex']Label Encoding 라이브러리를 불러온다.
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
label_encoded_label = le.fit_transform(label)이 후에 기존의 데이터에 Label encoding을 한 코드의 전후를 비교하기위해 두 데이터 모두를 보여주는 명령어를 입력한다.
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)), label_encoded_label.reshape((-1, 1))], axis=1),
columns=['label', 'label_encoded'])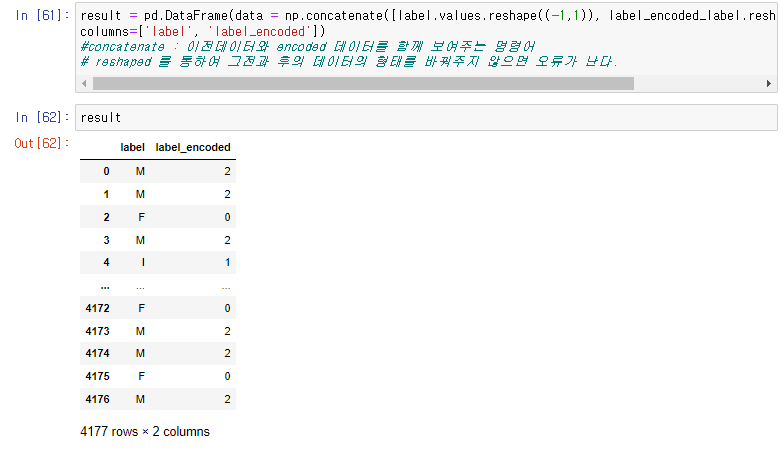
이때 reshape 를 통해서 형태를 바꿔주지 않으면 오류가 난다.
5-2) One-hot Encoding
one-hot encoding은 범주형 데이터를 n개의 비트벡터로 표현함.
고양이와 개 그리고 얼룩말을 표현하기 위해서는 3개의 비트가 필요 (종류 수만큼 차원이 확장)
one-hot encdoing 은 서로 다른 범주에 대해서는 벡터 내적을 취했을 때, 내적이 0이 나게 되면서 서로 다른 범주는 독립적이라는 것을 표현하게 함.
one-hot encoding 라이브러리를 불러온다.
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)이때 sparse 의 기본값은 True 이며, False 로 설정하면 Array, True로 설정하면 Matrix 값이 나온다.
일반적으로 Array 로 사용을 하기때문에 False 를 사용한다.
이를 사용해서 one_hot_enocoded 데이터를 만든다.
one_hot_encoded = ohe.fit_transform(label.values.reshape(-1,1))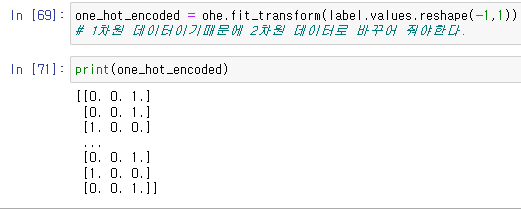
이를 통해서 성별별로 분류가 된다.
6)Unsupervised Learning(비지도학습, 자율학습)
기계학습의 일종으로, 데이터가 어떻게 구성되었는지 알아내는 문제의 범주
이 방법은 지도학습 혹은 강화학습과는 달리 입력값에 대한 목표치(정답)가 주어지지 않는다.
k-Mean Clustering
클러스터링 알고리즘중 대표적인것이다.
step1 : 각 데이터 포인트에서 가장 가까운 중심점을 찾아 그 중심점에 해당되는 클러스터 할당
step2 : 할당된 클러스터를 기반으로 새로운 중심점 계산, (이때 중심점은 클러스터 내부 점들의 좌표의 산술 평균)
step3: 각 클러스터의 할당이 바뀌지 않을때까지 반복.
학습을 하지않고 데이터를 주면 쪼갠다.
1.Manhattan Distance : 각 축에 대해 수직으로만 이동하는 방식(수직,수평 이동)
2.Enclidean Distance: 점과 점 사이의 가장 짧은 거리를 계산하는 거리 측정방식.(최단경로)
이 알고리즘을 확인하기 위해서 와인의 데이터를 import 한다.
from sklearn.datasets import load_wine
wine = load_wine()
data = wine.data
label = wine.target
columns = wine.feature_names
data = pd.DataFrame(data,columns=columns)와인의 종류별로 수치값이 다르기때문에, 모든 값들이 단위 크기와 상관없이 중요한 영향력을 가질수 있게 하기 위해서 min-Max scaling을 하기위해서
MinMaxScaler 라이브러리를 불러온다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)또한 와인의 데이터는 13차원의 데이터이기때문에, 그래프로써 활용하기 위해서 PCA 라이브러리를 불러온다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
data = pca.fit_transform(data)
이를 통해서 cluster 하기 위한 데이터를 준비했다.
그 후. Kmean 를 사용하기 위해서 라이브러리를 불러온다.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)KMeans 의 K는 몇개인가를 의미하고 n_clusters=3 의 의미는 정확한 cluster의 갯수는 모르지만, 임의로 3으로 설정하고, 그에 맞게 군집을 지정하는 뜻이다.
데이터를 kmeans 를 통해서 클러스터링을 하고, 그 예측값을 통해서 그래프를 그린다.
kmeans.fit(data)
cluster = kmeans.predict(data)
plt.scatter(data[:,0],data[:,1],c=cluster,
linewidth=1, edgecolor='k')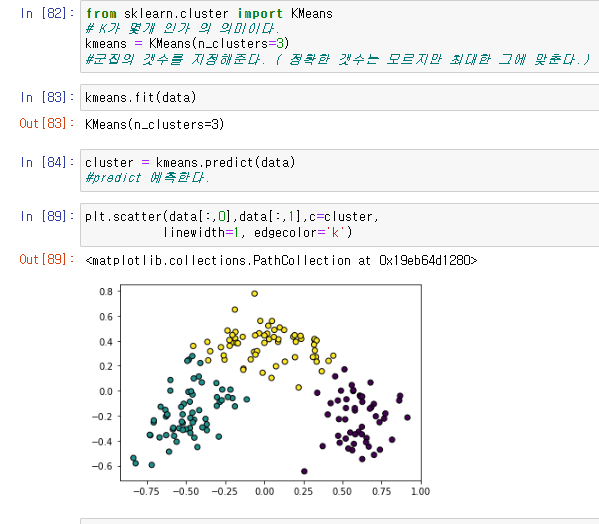
Hierarchical Clustering
거리 또는 유사도를 기반으로 클러스터를 형성하는 알고리즘.
Hierarchical Cluster 진행단계
step1: 각 데이터 포인트를 클러스터로 할당(n개의 클러스터)
step2: 가까운 클러스터끼리 병합
step3: 1개의 클러스터가 될 때까지 반복.
토너먼트처럼 진행된다.
1.single linkage
두 클러스터 내의 가장 가까운 점 사이의 거리
2.complete linkage
두 클러스터 내의 가장 먼 점사이의 거리
3.average linkage
두 클러스터 내의 모든점 사이의 평균거리
2.학습내용 중 어려웠던 점

수업중 분류용 데이터를 설정하는 과정에서 오류가 많이 나게되었다.
3.해결방법
수업을 진행하는 과정에서 설명을 듣게되었고
오류가 발생하는 원인은 여러가지가 있고, 그에 따른 코드가 추가되는데, 이번의 수업에서는 특히 필요한 코드들이 많은 것을 알수있었다, 그 이유로는 클러스터 안에 클래스가 1개씩만 들어가야하고, 반복이 없어야 한다, 또한 데이터들이 서로 얼마나 관련이 있는지도 설정해야하고, 중복을 얼마나 허용할것인가도 또한 중요한 요소란것을 배울수있었다.
4.학습소감
라이브러리가 다양하다보니, 라이브러리를 적재적소에 맞게 활용하는것이 어려웠지만,
수업에서는 강사님이 이미 적절하게 사용되는 라이브러리들을 정해진대로 사용하는것을 따라하는것으로 이해는 할수있었다, 하지만 기초가 되는 정보가 없을때 적절한 라이브러리를 사용하는것은 연습이 더 필요할것같다.
