아직 정답을 모르는 상태로 글을 작성하는 점 유의해주시기 바랍니다.
이번 1,2강은 word2vec 논문리뷰와 여러가지 GloVe등 논문에 관련된 지표를 비교하는 수업이었다. 영어를 수강하느라고 시간이 좀 걸렸지만, 좀 힘들었다...
Part 1
Corpus(말뭉치 : 문단 또는 책등 여러가지가 될 수 있음)로부터 다음과 같은 Co-Occurrence plot을 완성하는 코드를 작성해야 했다.
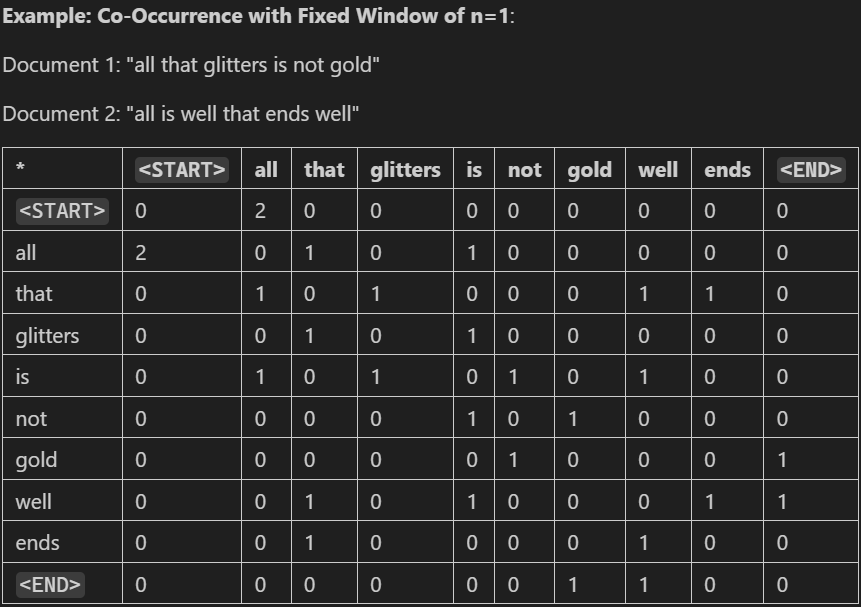
Part 1
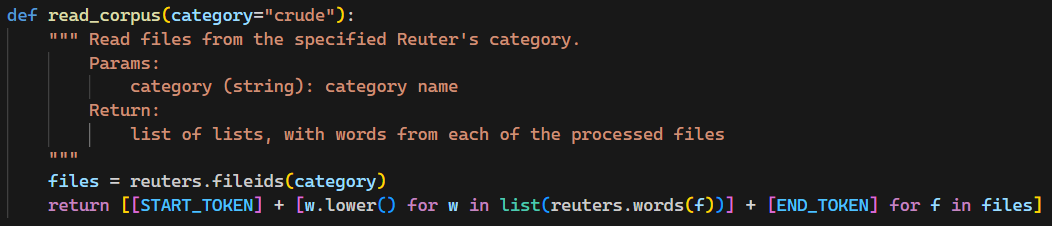
read_corpus를 제공해 주었고, 이의 결과값은 다음과 같았다.
대충 이런식으로 corpus안에 space를 기준으로 전부 나누어주고, 이를 list로 저장해 주었다.
Q 1.1

문제를 보면, corpus_words를 만들어주는 함수를 작성하는 것이다.
corpus_words 에는 단어들이 중복될 수 없고, sorted 해야했다.
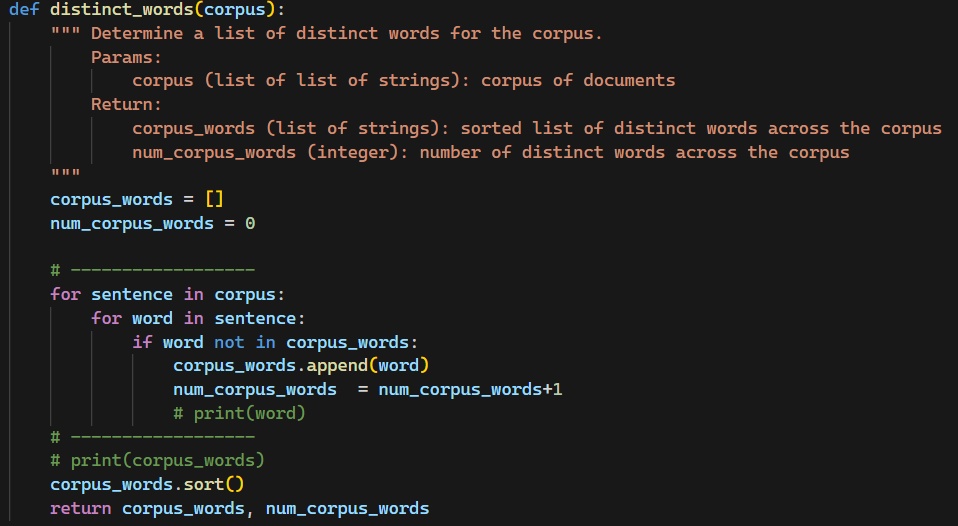
코드를 다음과 같이 작성했고, test를 돌린 결과 성공
Q 1.2
여기서부터 조금 난관이다.

compute_co_occurrence_matrix함수를 작성하는것이 과제인데, 이는 위에서 보여주었던 Co-Occurrence table을 corpus와 window size를 제공받으면 작성해 주어야했다.
내가 짠 코드는 다음과 같은데 여러가지 문제가 생겼다.
1차시도
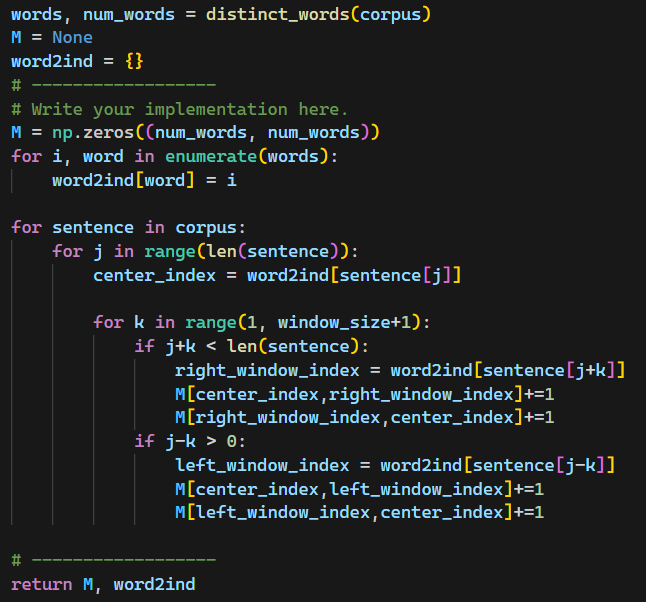
이렇게 작성했더니, test결과가 좀 이상하게 나왔다.
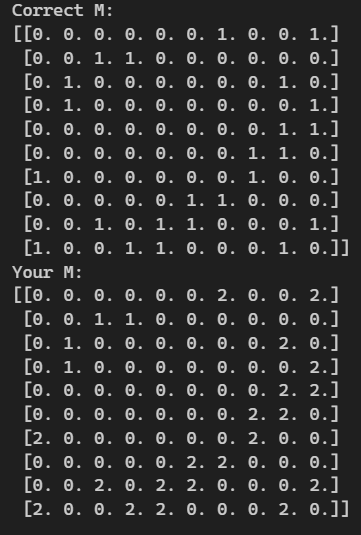
실제 나와야 하는 M과 나의 M이 맞는부분도 있었지만 1만큼 차이가 났다..
왜그런지를 살펴보다 직접 표를 그려보니 알았다

이렇게 한 축씩을 center, context로 설정하고 한번에 한 줄씩(center를 기준으로) 작성했어야 했는데, 가운데를 기준으로 대칭이라 생각하고 코드를 작성하다 보니 문제가 생겼던 것이었다.
그래서 코드를 다음과 같이 고쳤다.
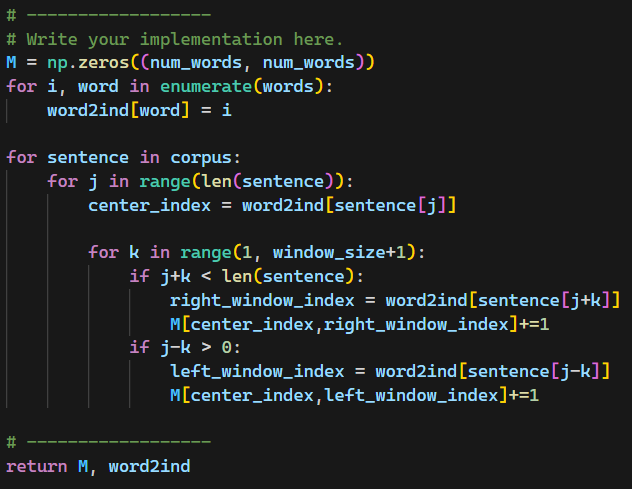
근데 테스트를 통과하지 못했다...
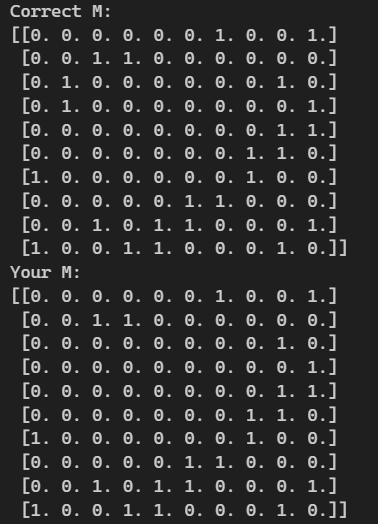
이론상으로 분명이 대각선 기준으로 대칭이 되어야 하는데 index (2,1), (3,1)이 0으로 잘못 나와있다.
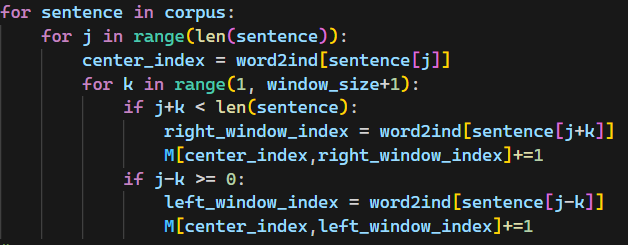
여러가지 실험을 거친 결과 if j-k>0이 아니라 j-k >=0 이어야 함을 깨달았다....

기분좋은 테스트 성공...

좋네요.. 팔로우 부탁드려요 ㅎㅎ 교류합시다