WordNet(dictionary by human)
Common NLP solution(과거에 사용하던 것들이다)
synonym sets와 hypernyms(상위어)들을 구분해 두었다.
cons :
- need lots of human resource
- lack of nuances
- missing new meanings of words(keep update is impossible)
- Can’t compute accurate word similarity
Representation words as discrete symbols(as one-hot vector)

cons :
- Vector dimension = number of words in vocabulary( 500,000 dim)
- Can’t represent similarity with words
Solution
learn to encode similarity in the vectors themselves
Representing words by their context
Use Distribunal semantics
Distributional semantics : Word’s meaning is given by the words that frequently appear close-by
if word appears in a text, its context is the set of words that appear nearby(within a fixed-size window)
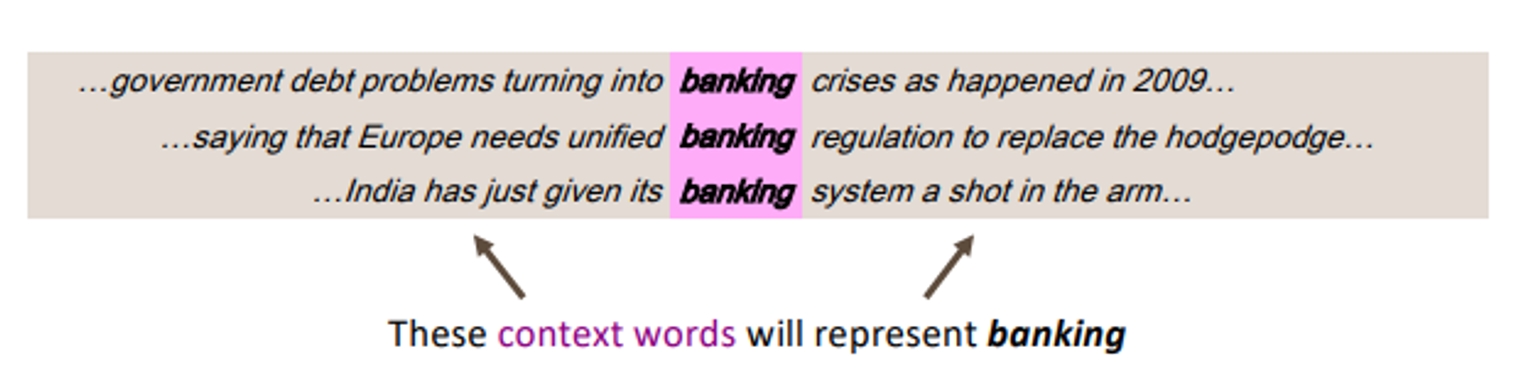
Word Vector
representin words as n-dimensional vector(not one-hot)
word vector also called word embeddings

Word2vec
Word2vec : framework for learning word vectors
Idea
- Corpuses(문단, 문장 등등) are consisted of lots of texts
- Every word in a fixed vocabulary is represented by a vector
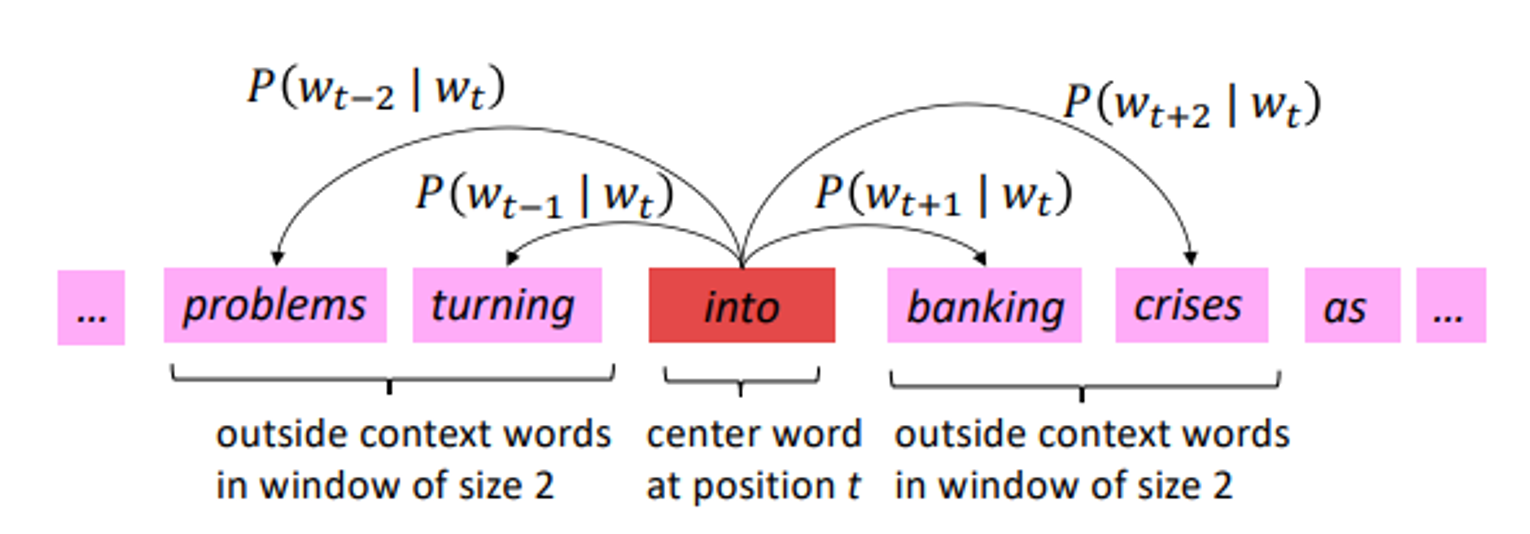
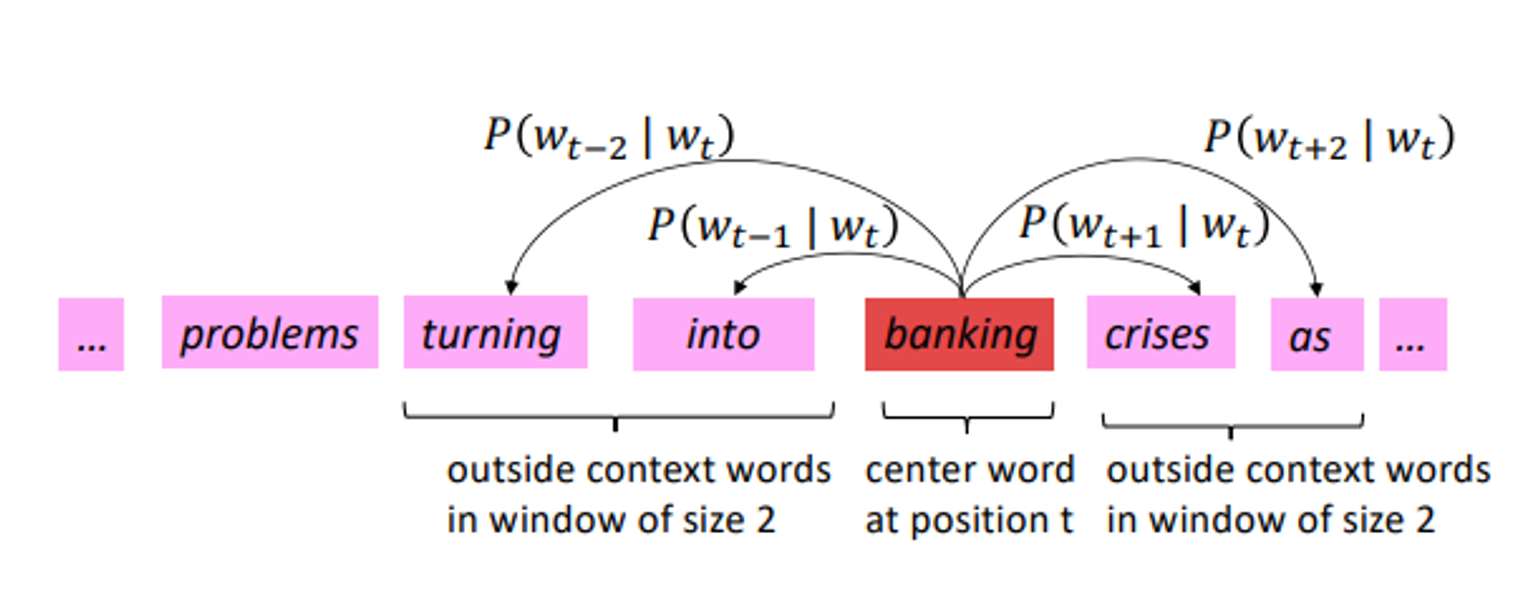
- Go through each position t in the text, which has a center word c and context (“outside”) words o
- Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
- 주어진 center word에 대해서 outside word인 “o”가 등장할 확률을 similarity of word vectors(c &o)를 이용해 구한다. (o를 통해 c를 구하기도 함)
- Keep adjusting the word vectors to maximize this probability
objective function
For each position , predict context words within a
window of fixed size , given center word .
Likelihood =
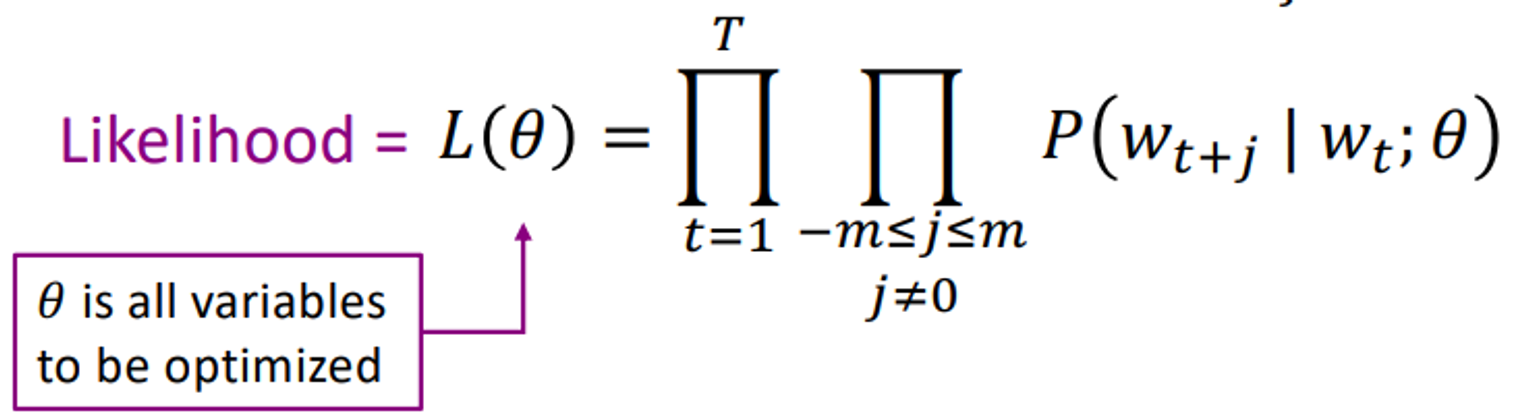
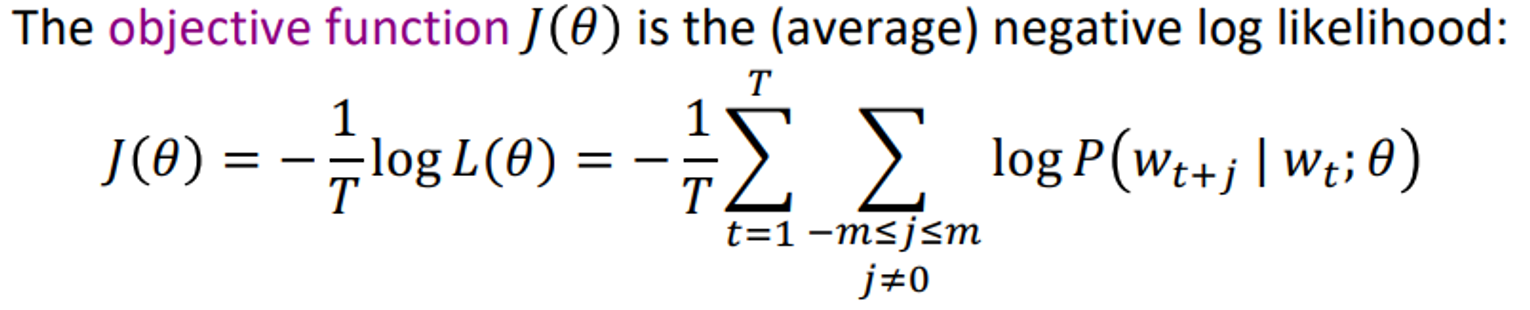
이를 통해
Minimizing objective function Maximizing predictive accuracy
Q : How to calculate ?
A : use two vectors per word
- : w is center word
- : w is context word
→ If center word “c” and context word is “o”
- u에 T를 붙이는 이유 : u와 v는 똑같은 dim의 column vector이다. 이를 similarity로 표현하고 싶으면 u를 전치한 후에 내적을 통해 similarity를 구해야한다.
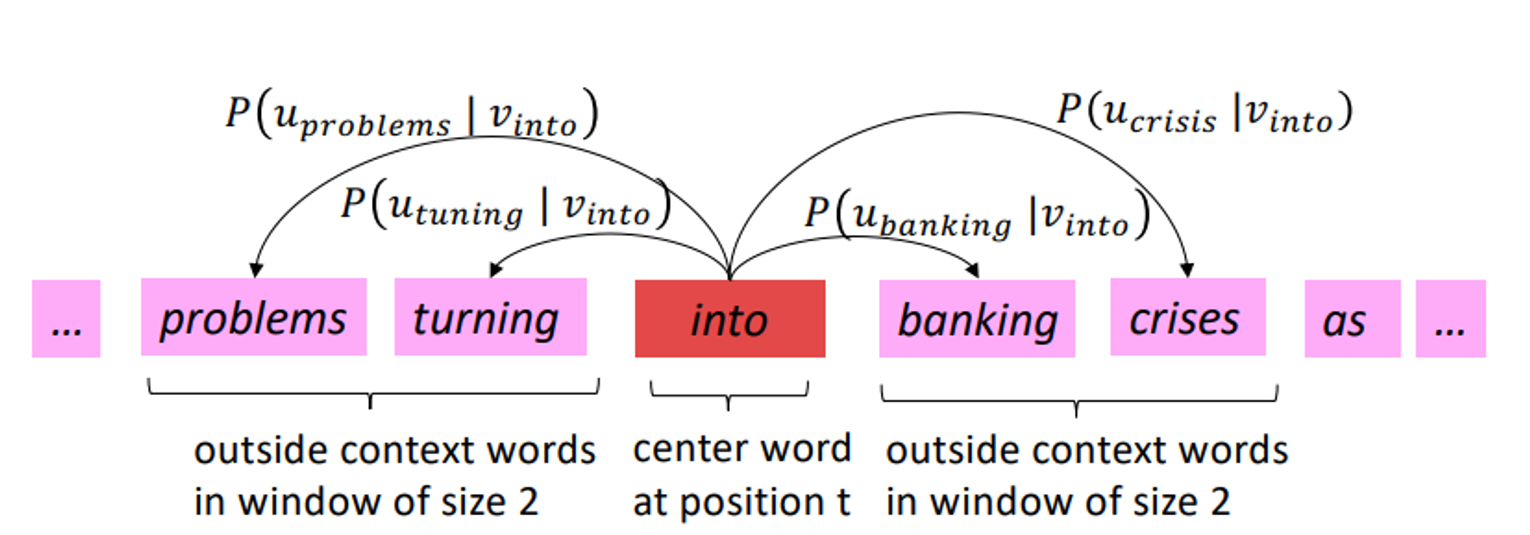

To trian the model : Optimize value of parameters to minize loss
2dV = each word has two vectors(v,u) and word vectors have size of V
