Linguistic structure에는 2가지 view가 있da.
1. Context-free grammars(CFGs)
Phrase structure라고도 불리우며 이는 단어들을 nested constituents로 묶는다.
단어 하나로부터 시작해서 단어들을 phrase로 묶다가 좀더 큰 phrases로 묶음
이러한 process를 통해 진행

phrase를 묶는 방법에 따라서 더 큰 범위로 확장할 수 있다는 점에서 큰 확장성을 가지고 있다.
2. Dependency structure
Dependency structure는 다른 단어들 과의 의존관계를 나타내는 structure이다.

Why do we need sentence structure?
사람은 복잡한 생각을 단어들의 결합을 통해 전달한다.
듣는 이는 이 결합들의 의미를 파악하기 위해서 문장의 구조를 알아야 하고,
이는 model에서도 human language를 제대로 이해하기 위해서는 필요한 지식이다.
Prepositional phrase attachment ambiguity
언어는 ambiguity를 항상 가지고 있는데, 이를 잘 이해하는것이 중요하다.
어떤 방식으로 phrase를 만드는 지에 따라서 의미가 달라질 수도 있따.
Dependency paths help extract semantic interpretation : Extracting protein-protein interaction
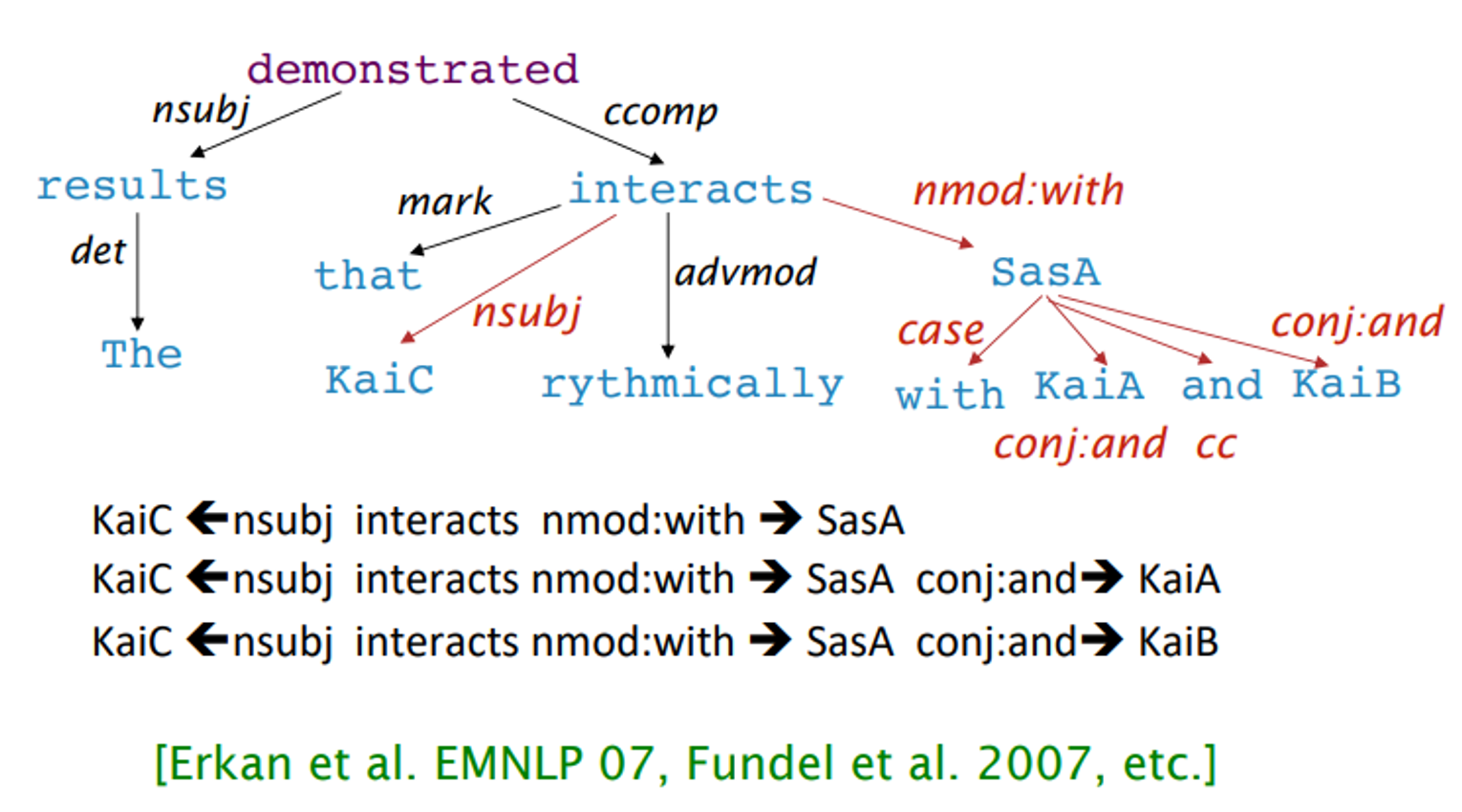
이런식으로 단백질을 분해하듯이 문장을 나눌 수도 있다. protein-protein interaction은 단백질끼리의 관계를 나타내는 다이어그램 같은거라고 한다…
Dependency Grammar and Dependency Structure
arrow로는 dependency를 나타내고, 어휘들 사이의 관계를 나타내어 준다.
화살표는 주로 문법적인 단어로 나타내어진다.

화살표는 head로 부터 dependent로 이어지게 만들어준다
보통 dependency는 tree를 형성한다.

화살표는 다음과 같이 시작이 head이고 끝이 그 head를 modify하는 dependent로 이어진다.
Fake ROOT(원래는 없음)을 이용해 모든 단어들이 정확히 1개 이상의 node로부터 dependent하게 만들어준다.
The rise of annotated data
Treebank를 만드려는 시도와 이미 만들어진 좋은 treebank가 있다. 하지만 이는 사람의 손보다 느리다.
하지만 이로 인한 이점이 상당히 존재하는데,
- reusability of labor
- broad coverate
- frequency and distrivutional information
- away to evaluate NLP systems
등등이 있다.

Dependency Conditioning Preferences
Dependency parsing 의 source가 뭘까?
- Bilexical affinities - "discussion → issues" 는 plausible하다. 두 단어쌍이 나타나는 빈도에 따라 통계적인 측정을 한다.
- Dependency distance - 대부분의 dependency들은 비슷한 위치 상에 있다. 대부분의 의존 관계는 문장내에서 서로 가까운 단어들 사이에서 발생하고, 단어들이 멀면 의존관계가 떨어지는 성향이 있다
- Intervening material - dependency관계에 있는 단어들 사이에 있는 다른 단어나 구문들떄문에, 의존관계를 파악하는데 방해되지 않도록 처리한다.
- valency of heads - head가 가질 수 있는 의존관계의 수를 나타낸다.
Projectivity(투사성)
투사성을 가진다라는 뜻은 모든 단어들의 의존관계(화살표, arc)가 cross하지 않고 선형적으로 놓여있는 상태를 projective parse라고 한다.
CGF(context free grammar) tree는 projective해야한다.
대부분의 syntactic structure는 projective하다.

Greedy transition-based parsing
Greedy discriminative dependency parser의 간단한 form이다.
Parser은 “bottom-up action”동작을 순차적으로 진행한다.
Bottom-up action : “shift”또는 “reduce”를 진행한다. “reduce”는 dependency를 형성할 떄만 사용하고, 주변의 head가 있을 때만 진행하게 된다.
Parser
- stack , top to right과 함께 쓴다.
- ROOT symbol을 가지고 시작
- buffer , top to left와 함께 쓴다.
- input sentence를 가지고 시작
- dependency arcs A
- 빈 상태로 시작
- set of actions
Basic transition-based dependency parser

Left-acr 또는 Right-Acr는 일때, 가 의 modifier이면 이를 흡수해 버리고, 로 나타내는 것이다. 화살표가 Left acr여서 다음과 같이 표현된다.

Left acr
1,2,3번은 전부 “Reduce”의 method이다.
쭉 진행하면 결국 이 된다.
진행순서를 조금더 자세하게 “I ate fish”라는 sentence를 통해서 살펴보면
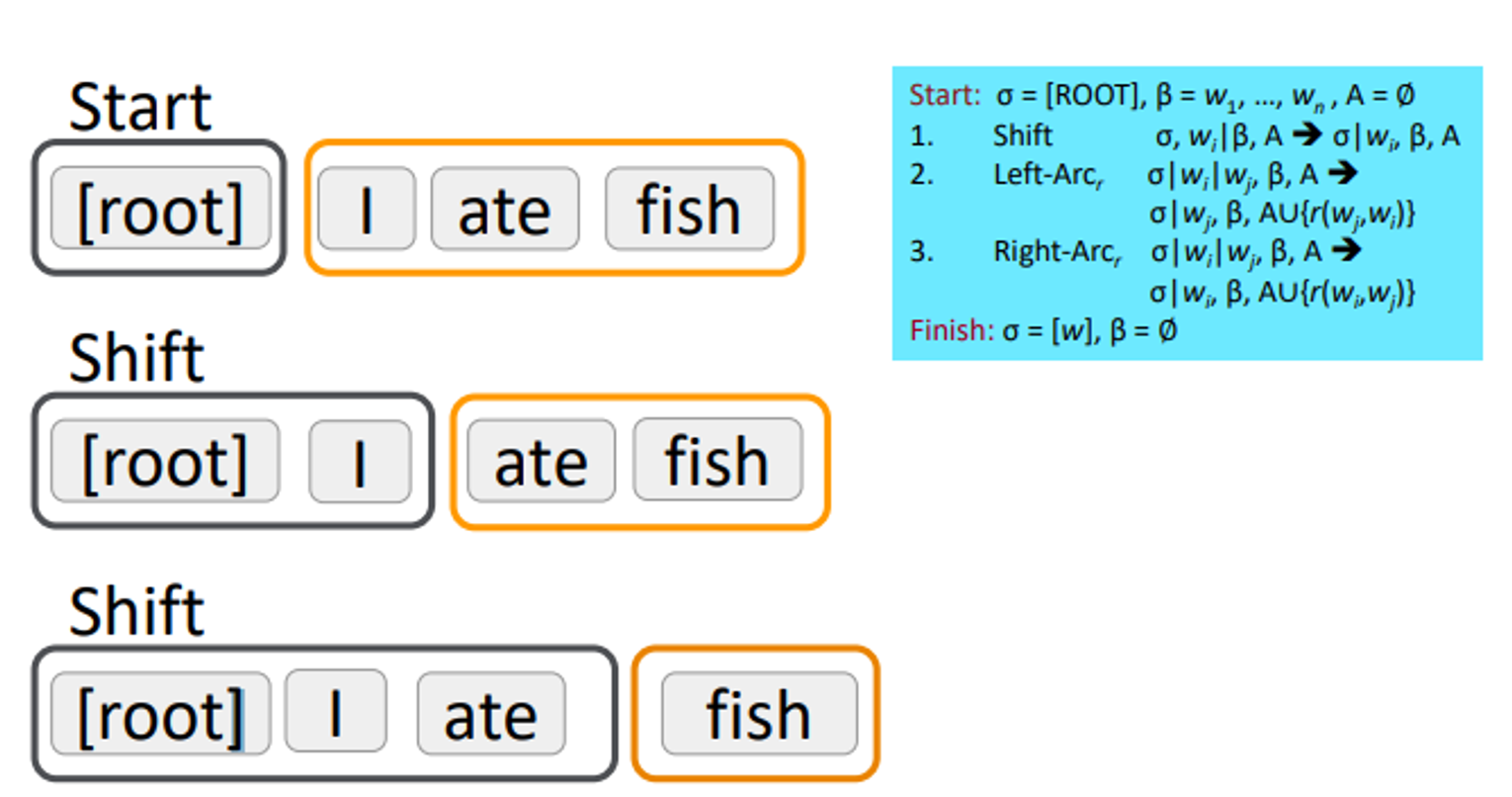
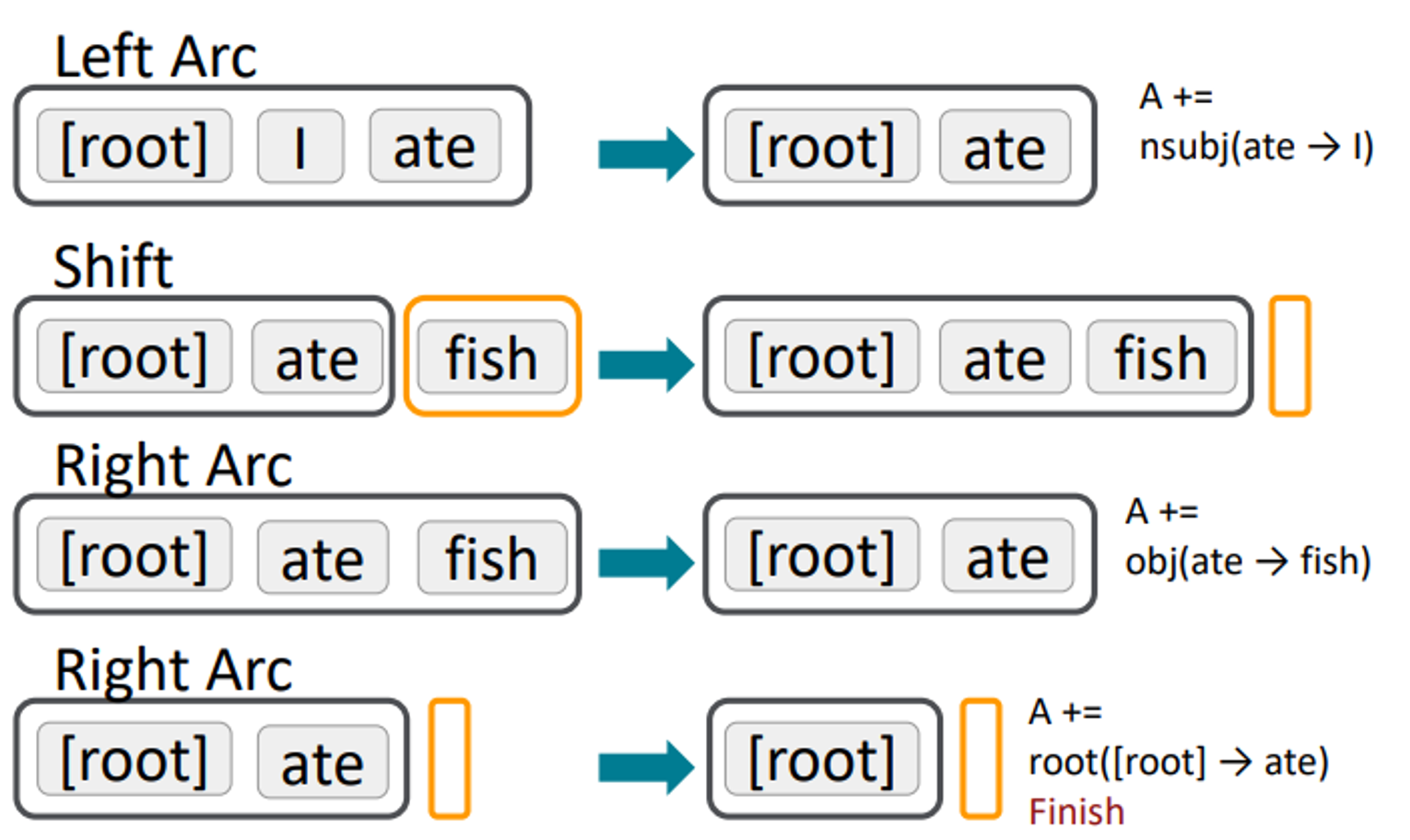
다음과 같은 순서를 따라 정리된다. 결국 root만 남게 된다.
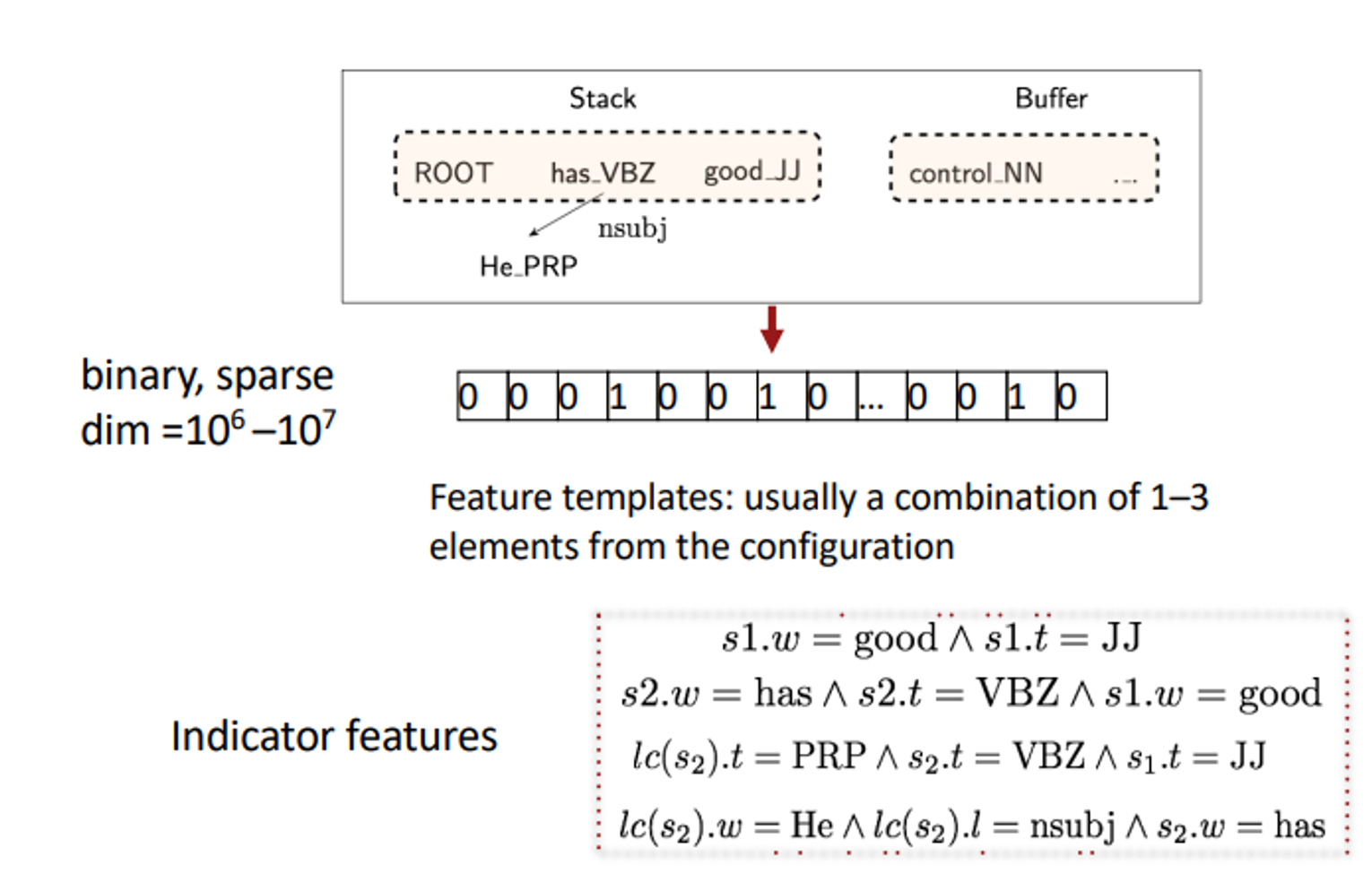
Conventional Feature Representation
- Stack & Buffer: 스택은 현재 처리 중인 문장의 단어들을 나타내며, 버퍼는 아직 처리되지 않은 단어들을 나타낸다. 스택에는 'ROOT'로 시작하여, 이미 처리된 단어들이 쌓여 있다. 예를 들어, 이미 처리된 "He has good control" 이라는 문장의 일부가 스택에 표시된다.
- Binary, Sparse Feature Representation: 여기서 "Binary"은 특징이 존재하면 1, 아니면 0으로 표시되는 것을 의미하고, "Sparse"는 전체 가능한 특징 공간 중 매우 적은 부분만이 실제로 사용된다는 것을 의미한다. 차원(dim)은 대략 10^6에서 10^7 정도로 매우 큼
- Feature Templates: 일반적으로 1-3개의 구성 요소를 조합하여 만들어진다. 예를 들어, 스택의 첫 번째 워드(s1)가 "good"이고 태그(t)가 "JJ"라는 정보를 사용하여 특징을 생성한다.
- Indicator Features: 특정 조건이 참일 때 활성화되는 특징, 예를 들어, 스택의 두 번째 단어(s2)가 "has"이고, 그 태그가 "VBZ"이며, 스택의 첫 번째 단어(s1)가 "good"이고 그 태그가 "JJ"일 때, 이를 표현하는 특징이 활성화된다.
Evaluation of Dependency Parsing : (labeled) dependency accuracy
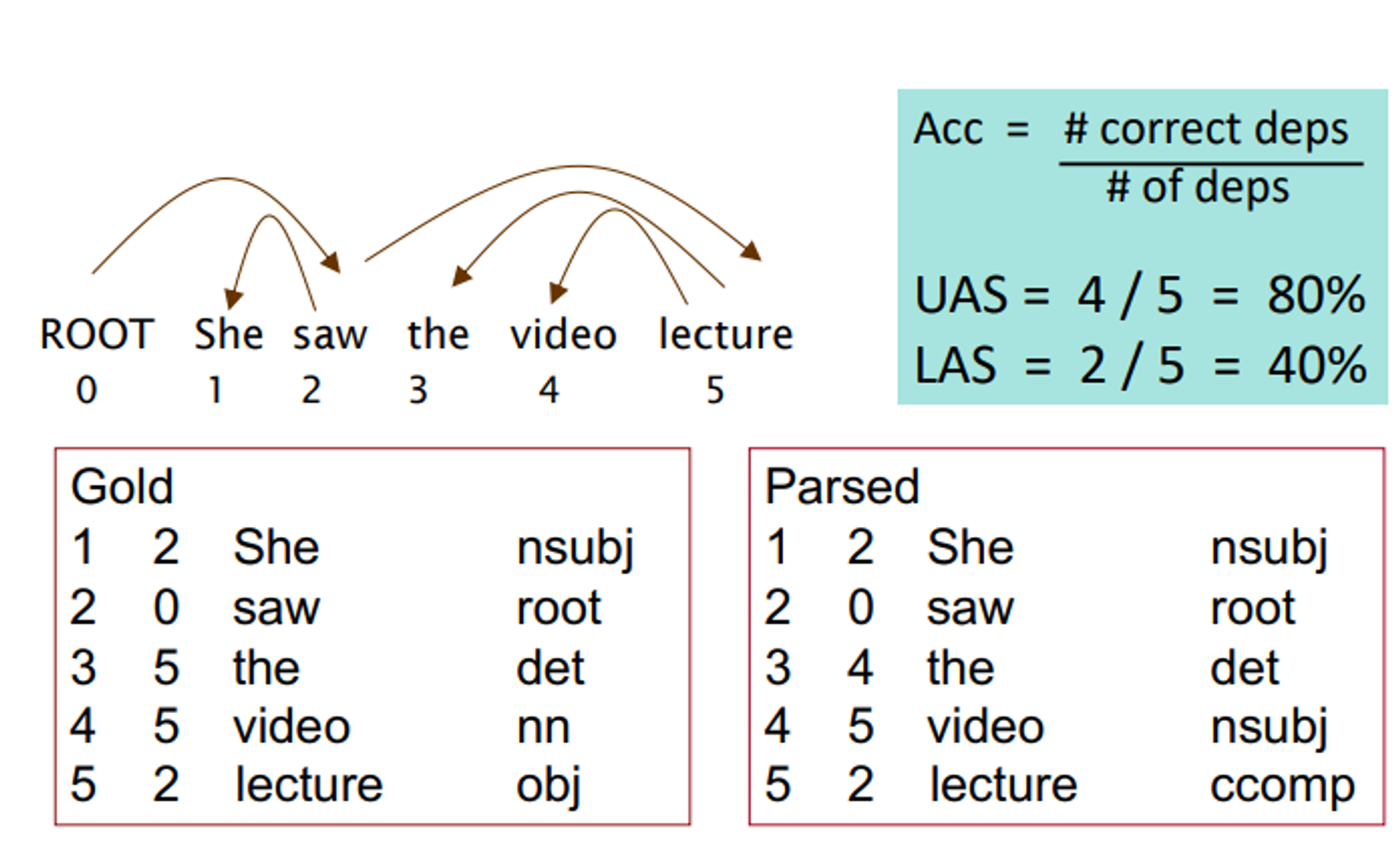
평가하는 방법에 대해 설명하는데, 까먹음...
사실 연구실에서 스터디 진행중에 하는거라 Lecture 4는 할 필요 없었지만 5강이 이해가 안돼서 잠깐 정리해보았다.

너무 좋아용 ㅎㅎ