📌
[SELECT
FROM] ←requirement clause
(WHERE) ← 생략가능
[GROUP BY
HAVING
ORDER BY] ← option clause
Substring Comparison
🔑(LIKE / ARITHMETIC / ORDER BY DESCENT or ASCENT / AS)
서브 스트링 비교 연산
LIKE
: 스트링 매치 비교 연산
‘% ~ %’ : 첫번째 % 앞쪽과 두번째 %의 뒤쪽에 임의의 스트링이 와도 상관없음
‘___’ : 어떤 문자가 와도 됨
- 집합에서는 하나의 attribute value들은 더이상 나눌 수 없다고 하는데(atomic하다 = Relational Model규칙 )
LIKE에서 문자열을 나눠서 비교하니까 ⇒ Relational Model 어김! - Relational Model을 어겼지만 매우 유용!
ARITHMETIC OPERATIONS
사칙연산자 +, -,*, /
- relational model에 속하지 않음 = 'extension'이다.
- 데이터를 변경, 갱신하는 것이 아니라 출력할 때만 연산해서 원하던 결과를 출력한다.
ORDER BY
정렬 연산자
- ordering attribute는 SELECT문에 정의하는게 바람직함
2.ORDER BY옆에 ordering attribute를 명시해준다(GROUP-BY에서 grouping attribute 명시해주는 것과 동일 ) - 기본은 오름차순 정렬 연산
DESC/ASCSELECT문에서도 Ordering attribute를 명시해줌
추가 1
AS
SELF- JOIN 연산 시, AS연산자를 통해 alias를 표현 할 수 있다.
- ①Table의 이름을 바꿀 때, ②Attribute name을 바꿀 때
AS를 사용한다. - 점차 사라지는 추세
ex. EMPLOYEE AS E, EMPLOYEE AS S기존에 있던 attribute의 이름을 바꿔서 표현하고 싶다면 AS를 쓰고 E 하면서 renamed 할 수 있다.
추가 2
SET operations
Multi-Set Operation으로 UNION, EXCEPT, INTERSECT
IN : SET과 SET사이 , 명백한 SET을 주고 그 안에 속하면 ‘TRUE’로 Nested query를 사용하지 않고 명시된 explicit sets이다 .
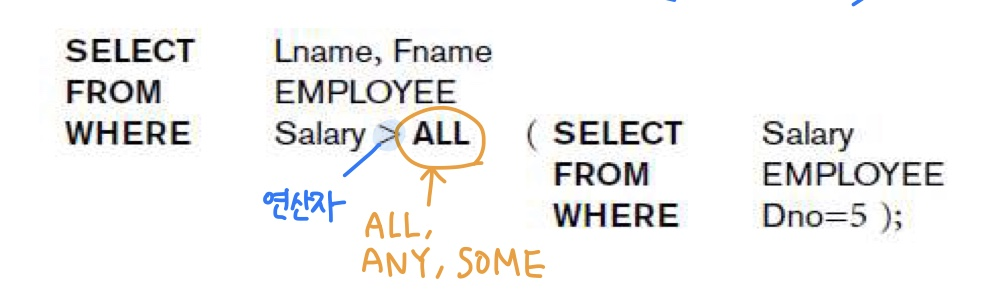
*basic sql(3) 참고ALL, ANY, SOME : 비교 연산자 사용시 (‘<, > , = , <=, >=’) ALL, SOME, ANY 를 사용해 값과 비교 할 수 있다.
USE OF NOT EXISTS
double negation
NOT EXIST , EXCEPT
제외한 것에 존재하지 않는 모든것 = for all = double negation.
→ 시간이 오래걸려서 부정의 부정을 하기보다 긍정으로 하는게 좋음
WHERE NOT EXIST …
EXCEPT … ⇒ `Double negation` 추가 3
절 clause 별로 올 수 있는 것 및 특징
1. SELECT- 절
- attribute list가 옴
- aggregation Function ( COUNT / SOME / AVERAGE / MIN / MAX )
- DISTINCT
2. FROM - 절
- Alias
- FROM절에 relation이 n개 오면 join n-1번 발생
3. WHERE- 절
- 대상이 될 튜플들을 찾음 (조건명시)
- 현재 보고 있는 튜플이 true / false 인지 (조건)
- JOIN을 명시해주기도 함
- 왼쪽, 오른쪽 둘 다 join attribute이면 ⇒ JOIN
- 왼쪽 join attribute + 오른쪽 value ⇒ SELECTION (즉, value를 선별.)
4. GROUP BY
- GROUP BY 키워드 옆에 grouping attribute가 나옴
- group by attribute는 SELECT-절 에서 정의해줘야 함
5. HAVING
- GROUP BY에서 선택된 attribute value들 중에 조건을 명시하고 싶을 때
6. ORDER BY
- 정렬 순서를 주고 싶을 때
- SELECT절에 명시되어야 함
- 기본적으로 오름차순
- DESC(내림) / ASC(오름)
7. UPDATE 명령
🔑 ( INSERT / DELETE / UPDATE ) → 데이터베이스 STATE 갱신
- INSERT
- Simple Form
: 릴레이션에 한개의 tuple을 추가함 (INSERT INTO/VALUES)
*Attribute Value 들의 순서는 CREATE TABLE 에서 선언한 순서와 똑같이 써야함

( positional matching ) -
value 값에 NULL을 집어넣고 싶으면 → 그 value 자리에
, ,or‘ ‘로 비워넣기 -
ALTERNATE Form
새로운 tuple의 value 들에 대응되는 attribute 이름을 명시적으로 기록

- another alternate
‘내가 원하는 VALUE에다가만 넣고 싶다’- 하나의 명령어로 한 릴레이션들 내에 다중 tuple들의 삽입 허용
- 기존 정보들로 재구성된 새로운 Table을 생성하면, 데이터를 전달해줘야 함
→INSERT INTO를 통해 3개의 재구성된 ATTRIBUTE에 대해 SQL 문을 작성해서 값 INSERT

💡 original 데이터가 변경되어도 DEPTS_INFO 속 value들은 UP - TO - DATE 되지 않는다. = 'Dirty함'
- DELETE
WHERE절에 DELETE 될 Tuple들을 선정하고 조건에 맞는 것들이, 삭제되고 회복되지 않음 .
- UPDATE
기존에 튜플이 있어야 업데이트 즉 수정될 수 있음
(UPDATE / SET)
WHERE절에 만족할 조건을 달고, SET절에 수정될 NEW values들을 명시해준다.

→ 부서번호가 오른쪽에 있는 Nested Query에서 '연구' 부서의 부서번호를 대상으로 Salary를 10% 인상 해서 바꿔라
+attribute들의 순서가 매우매우 중요함!
