집합(SET)
: 순서(order/sequence)와 달리 순서가 아니라 존재여부가 중요함
keyword: UNION, IN, EXIST, CONTAIN, NULL, Explicit Set
SET 연산자
sql은 어떤 집합 연산자를 직접 사용할 수 있다.
UNION, Set Difference[MINUS], Intersection operations [INTERSECT]
- set operation들의 결과는 “sets of tuples(튜플들의 집합)” 로 중복된 tuple들은 결과에서 제거
- ‘union compatible relation’들에게만 적용
→ (1) 동일한 attribute들을 가져야 함 + (2) 동일한 순서를 가져야 함
Join
결과 튜플인 'Cartesian Product' 중에서 Left 속성값과 Right 속성값 간의 조건 있는 결과 집합
equal인 또는 왼쪽 attribute나 오른쪽 attribute 중 큰 쪽 등 조건을 만족하는 결합들
= ‘조건이 있는 결과 집합’
- cartesian product를 구해서 주어진 join condition에 맞춰 왼쪽 튜플과 오른쪽 튜플이 결합되어 출력되는 형태로 결과물은 cartesian product의 subset이다.
Query 들의 중첩
‘Nested Query’
또다른 query(= outer query)의 WHERE절 안에 명시 될 수 있는 완전한 SELECT query
-
Nesting 형태를 통해 다른 형태로 query를 표현할 수 있다.
join query ←→ nested query (= inner query ) -
일반적으로 nested query들을
다중 level로 할 수 있다. -
선언이 없는 unqualified attribute에 대한 참조의 경우, 가장 가까운 innermost nested query에 있는 relation을 선택한다.
→ 내부에 선언된 query가 밖에 query의 relation을 참조하는 경우
= “correlate(상호연관) 됨’
Correlated Nested Query
외부 질의(E) 안에 선언된 어떤 Relation의 attribute를 Inner Query(S)가 참조하면, 이 두 질의들은 ‘correlated’됨
중첩이 복잡한 경우에 E, S등 특수변수를 사용해 간단히 표현
- 중첩된 질의의 결과(correlated inner query)는 외부 질의의 튜플 값에 따라 바뀜 → 외부 질의를 따름
- Nested query는 outer query에 있는 각 tuple에 대한 다른 결과를 가짐
- 비교 연산자 (comparison operators) ‘=’ 또는 ‘IN’ 사용해서 표현
- 'single block query' : 항상 original로 바꿀 수 있음
Set Comparison
Subset 관계를 명시하고, 이 조건을 만족하는 튜플이 답이 된다.

outer set 중 inner set을 포함해야 WHERE절이 TRUE가 된다
→ 이때의 EMPLOYEE 튜플이 답이 됨
1st nested query가 2nd nested query를 포함하고 있는 것이 답이 된다.
두 nested query는 수행과정에서 서로 관계가 없지만, 결과는 연관을 맺고 있다.
But!! Outer Query인 EMPLOYEE와 1st Nested Query는 correlated 되어있다!
집합 내 존재 유무 확인 질의
EXIST Function
The EXIST function / NULLs / Explicit Sets
EXISTS 함수
결과가 존재하는가? → True / False
correlated nested query의 결과가 ‘empty’인지 아닌지를 check 할 때 사용
NOT EXIST
inner가 false가 되어야 결과가 나옴
EX. 부양가족이 없는 직원이름 출력

EXPLICIT SETS
괄호 안에 원소가 명시된 집합
Nested query를 쓰지 않고, WHERE-절 내에 괄호로 둘러 쌓인 명확한 value들의 집합을 사용할 수 있다.
NULL
모르는 경우/ 정의 안된 경우/ 필요없는 경우 NULL을 사용
→ 다 같은 의미의 NUll이 아님 다 다른 의미로 null존재
- SQL은 Null값과 비교하기 위해
‘IS’‘IS NOT’을 사용 - NULL 에 대한 Join연산은 무시됨
→ null과의 equality 비교는 무조건 false로 간주하기 때문 - 📍 equality comparison은 적당하지 않음
‘!=’
NULL값을 비교하는 이유
: 각 NULL값은 다른 NULL 값들과 구분(distinct)될 수 있다.
Aggregate Function과 Grouping
Aggregate Function
집계 함수:
COUNT , SUM, MAX, MIN, AVERAGE

- 관계모델 아님
→ relational algebra는 set을 지원하지만, Aggregate 함수는 multi-set을 지원하기 때문- 무척 유용
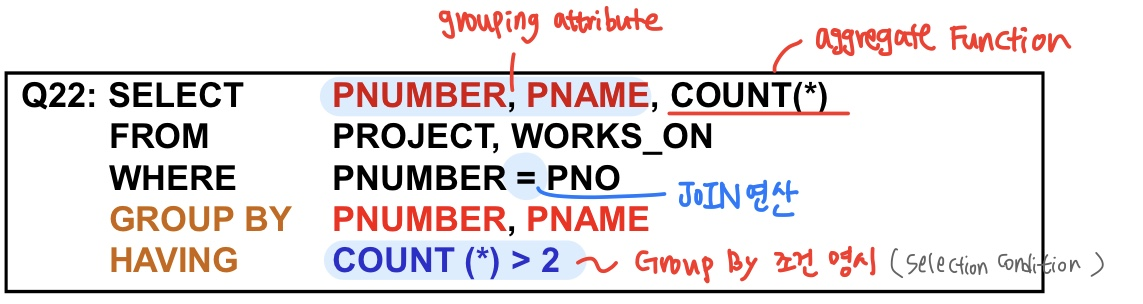
Grouping 함수(‘GROUP BY’)
튜플들의 sub group을 만들어서 sub group들 간의 aggregate(연산 된) value를 원할 때
(ex. 부서별 월급 평균, 부서별 인원수 ~~ group by해서 aggregate 하겠다!)subgroup
grouping attribute가 같은 값을 가지는 tuple들을 subgroup이라고 함
- 그룹핑 함수는 각 독립적인 subgroup에 적용됨.
- GROUP BY-절 을 가진다면 , SELECT-절 내에 그 grouping attribute들이 반드시 나타나야 한다.
- GROUP BY(그룹핑)와
JOIN도 함께 사용가능- SELECT 절에 반드시 GROUP BY Attribute를 꼭 가져야함
HAVING: GROUP BY에 조건을 부여할 때만 사용

Aggregate function & Grouping
sub-group을 만들어서 그 곳에서의 연산을 진행할 수 있다.
ex. 부서별 COUNT / 부서별 평균
- tuple들이 WHERE-절 조건에 따라 여러개의 sub-group으로 나누어 진다.
- 독립적용 : Aggregate function들은 tuple들의 각 group에 분리되어 적용된다
- SELECT-절 안에 Aggregate function이 포함된다.
- Group By Attribute(
groupping attriubte)는 꼭 SELECT절에 포함해야 한다.
Having
GROUP BY에 조건을 부여
EX. DNO 5번 이상인 부서
- 구해진 Group에 대해서만 조건을 붙일 때 HAVING-절 사용
- 그룹들에 대한 Selection condition을 명시할 때 사용 (not individual)