


💡 교보문고의 도서를 추천하는 시스템을 만들 던 중 책소개를 이용하여 유의미한 키워드를 추출하고 싶다는 생각이 들었고 알게 된 것이 바로 WordRank였다. 지금부터 한글로 구성된 텍스트에서 유의미한 키워드를 추출하기 위해 찾아봤던 방법들을 요약 해볼까 한다!
텍스트 요약
텍스트 요약에는 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)으로 나눠진다.
추출적 요약은 기존의 글에서 중요도가 높거나 핵심이 되는 문장을 그대로 추출해서 요약문을 만드는 것이다.
추상적 요약이란 새로운 단어와 새로운 문장을 생성해서 요약을 하는 방법이다.
✍🏻 개요
추출적 요약법의 가장 대표적인 알고리즘이다.
🔗 관련 논문 : http://infolab.stanford.edu/~backrub/google.html
🔗 TextRank : https://sungmooncho.com/2012/08/26/pagerank/
📄 PageRank
하이퍼링크를 가지는 웹 페이지에 대해서 얼마나 참조가 되었는지, 얼마나 유입되었는지 등으로 페이지의 순위를 매기는 알고리즘이다.
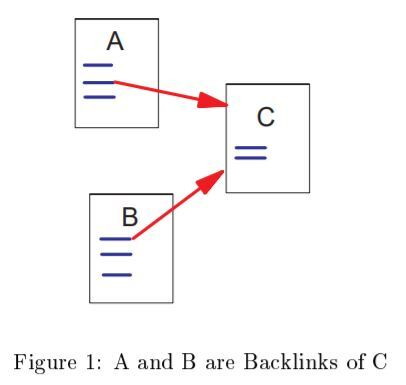
다른 페이지에서 오는 링크를 같은 비중으로 세는 대신에, 그 페이지에 걸린 링크 숫자를 ‘정규화(normalize)’하는 방식을 사용한다.
PR(A) = (1-d)/N + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
- PR PageRank의 줄임말
- PR(A) ‘A’라는 웹페이지의 페이지 랭크를 의미한다.
- T1, T2, … Tn 그 페이지를 가리키는 다른 페이지들을 의미한다.
- PR(T1) T1이라는 페이지의 페이지 랭크값이다.
- d ‘Damping Factor’을 뜻(어떤 마구잡이로 웹서핑을 하는 사람이 그 페이지에 만족을 못하고 다른 페이지로 가는 링크를 클릭할 확률)
- (T1) T1이라는 페이지가 가지고 있는 링크의 총 갯수를 의미한다.
예를 들어 A의 페이지 랭크는 A라는 페이지를 가리키고 있는 다른 페이지의 페이지 랭크값이 높을수록 (즉, 더 중요할수록) 더 높아진다.
💡 왜 정규화를 할까?
▶︎
페이지 랭크의 단순 합산이 아니기 때문이다. 예를 들어, T1의 페이지 랭크가 높다고 하더라도, 그 페이지에서 링크를 수천 개 달아놓았다면(즉, C(T1)값이 높다면) 그 페이지가 기여하는 비중은 낮아진다.
🗣️ TextRank
TextRank 모델은 PageRank의 알고리즘을 활용한 것으로, 페이지의 개념을 단어의 개념으로 바꾼 알고리즘이다. 즉, 텍스트로 이루어진 글에서 특정 단어가 다른 문장과 얼마만큼의 관계를 맺고 있는지를 계산하는 것이다.
TextRank는 그래프 기반의 랭킹모델로 순위를 매기는 방법이 문단의 추출적 요약에 매우 효과적이라 생각으로 개발되었다.
🔗 논문 : https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
🔗 참고 사이트 : https://www.dinolabs.ai/288
🏅 어떻게 순위를 매길까?
▶︎ 논문에 의하면 'voting'과 'recommendation'과 같은 아이디어를 사용했다고 한다. 한 단어(vertex)가 다른 단어(vertex)와 연결된다면 이를 연결한 vertex에 투표를 했다고 한다. 즉, 투표를 많이 받은 vertex의 중요도가 커지게 된다고 볼 수 있고 투표수는 순위를 결정하는 값이 된다.
📄 KR-WordRank
WordRank는 일본어와 중국어의 Unsupervised word segmentation을 위해 제안된 방법으로 한국어에 적용할 시 좋은 결과를 낼 수 없다.
WordRank
WordRank는 띄어쓰기가 없는 중국어와 일본어에서 그래프 랭킹 알고리즘을 이용해 단어를 추출하기 위해 제안된 방법이다. WordRank는 substring graph를 만든 뒤, 그래프 랭킹 알고리즘을 학습한다.
Substring graph 는 아래 그림의 (a), (b) 처럼 구성된다.
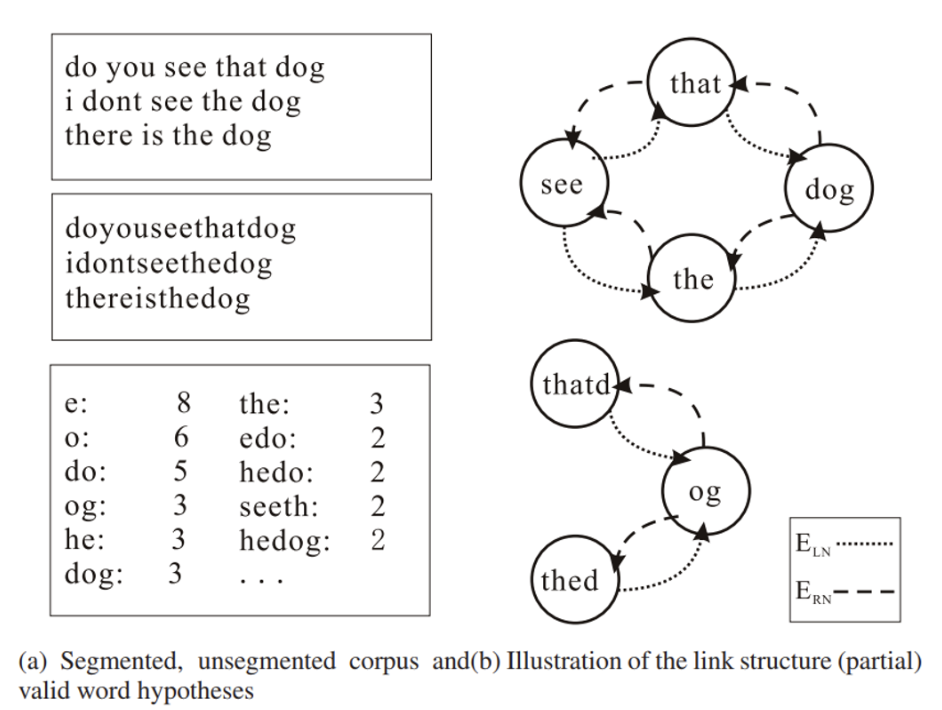
WordRank 알고리즘을 한국어에 적용하게 되면 한 글자들이 높은 ranking 을 지니게 된다. 한국어의 한글자는 그 자체로 단어이기도 하며, 관형사나 조사로 이용되는 글자들이 많아 단어로 등장하기 때문에 한국어의 특성을 반영한 알고리즘을 이용해야한다.
KR-WordRank
한국어는 띄어쓰기 정보를 이용해야한다. 띄어쓰기 정보를 이용하지 않으면 두 어절의 양끝에 걸친 substring 역시 단어 후보에 포함된다.
<
substring('이번봄에는') = [이번, 번봄, 봄에, 에는, 이번봄, 번봄에, ...]
subsrting('이번 봄에는') = [이번, 봄에, 에는, 봄에는]
한국어의 특징은 어절의 왼쪽에 위치한 글자들이 의미를 지니는 단어들이며, 오른쪽에 위치한 글자들은 문법기능을 하는 조사와 어미라는 점이다. 우리가 어절의 왼쪽부분을 이용해 단어사전으로 만들 것이다.
WordRank 알고리즘은 keyword extraction 능력이 있다. ranking 이 높은 마디는 단어일 뿐 아니라, 그 데이터셋에서 자주 등장하는 단어이므로 데이터를 요약하는 keywords 로 이용될 수 있다.
keyword extraction : 원본 문서를 가장 잘 타나내는 중요한 용어 또는 구문을 찾아내는 작업
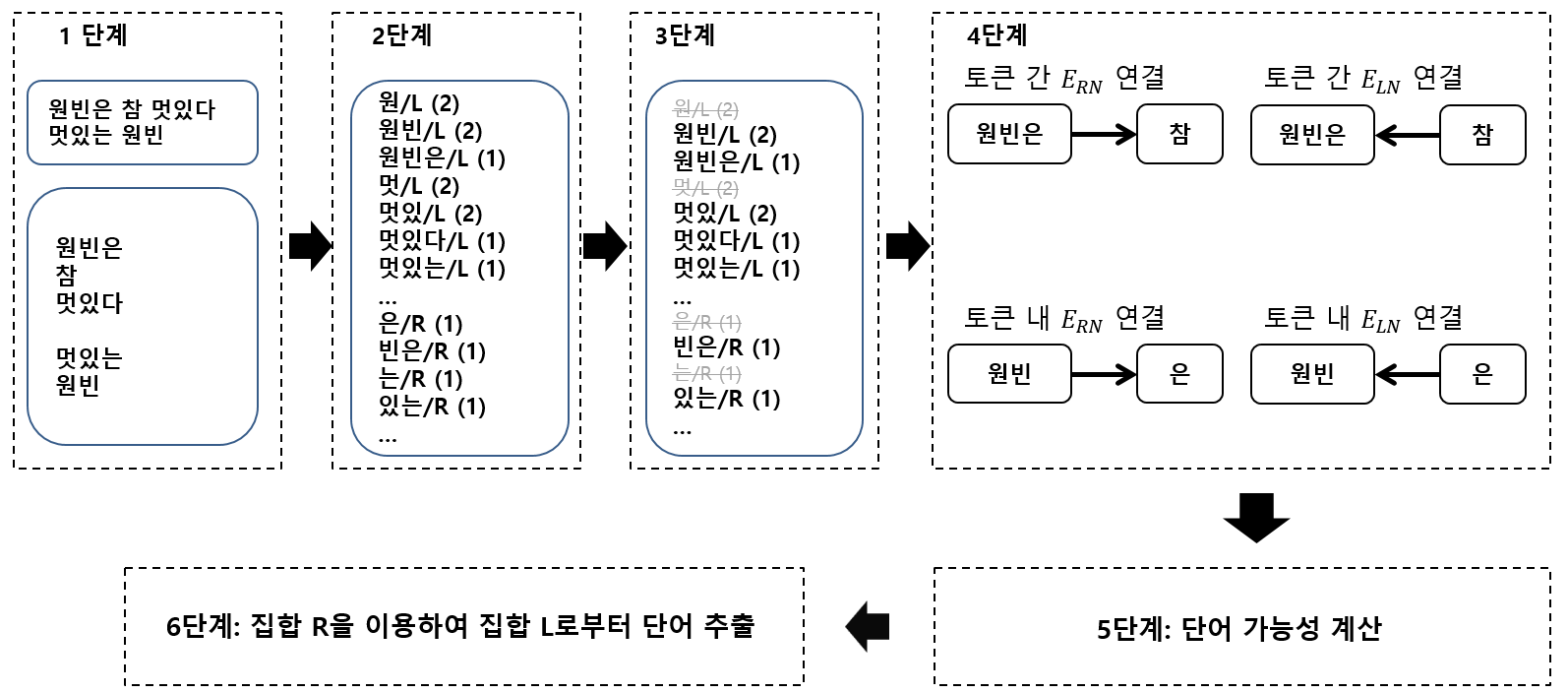
🔁 전체적인 과정
💻 KR-WordRank의 활용
- df['책소개']는 ‘\n’을 포함하여 하나의 문장으로 이루어져 있기 때문에 이를 여러 개의 문장으로 나눠야 한다.
<for text in df['책소개']:
text.split('\n')
text_list.append(text.split('\n'))
text_list[:2]

- normalize 함수를 이용하여 불필요한 특수 기호를 제거한다.
ex) ‘▶︎', ’!’, ‘★’ 등…
from krwordrank.hangle import normalize
texts = [[normalize(text, english=True, number=True) for text in texts] for texts in text_list]
texts[:2]
- texts를 df에 ‘책소개 전처리’라는 열(column)이름으로 추가한다.
KRWordRank패키지를 이용하여 ’책소개 전처리’ 열에서 중요한 키워드를 추출하고, 이를 기존 Dataframe에서 '책소개 키워드 수정본' 열로 추가한다.
from krwordrank.word import KRWordRank
from konlpy.tag import Okt
def KeyWord(x):
sentence = []
wordrank_extractor = KRWordRank(
min_count = 1, # 단어의 최소 출현 빈도수 (그래프 생성 시)
max_length = 10, # 단어의 최대 길이
verbose = True
)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 20
keywords, rank, graph = wordrank_extractor.extract(x, beta, max_iter)
word_list = list()
for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True)[:30]:
if r >=1:
word_list.append(word)
# 한 문장으로 합친다.
sent = ' '.join(word_list)
sentence.append(sent)
# 형태소 추출
okt = Okt()
OKT = okt.pos(sent)
keyword_list = []
# 조사와 접미사를 제외한 나머지만을 키워드로 채택
for word, tag in OKT:
if (tag not in ['Josa']) and (tag not in ['Suffix']):
keyword_list.append(word)
return keyword_list
df['책소개 키워드 수정본'] = df['책소개 키워드'].apply(KeyWord)