
주제: 깊이 우선 탐색(DFS: Depth-First Search)
DFS란?
- DFS는 깊이 우선 탐색이라고 부르며, 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘입니다.
- 이 알고리즘은 특정한 경로를 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후, 다시 돌아가 다른 경로로 탐색하는 알고리즘입니다.
활용
- 위상 정렬
- 순환 감지
- 미로 퍼즐과 같은 경로 탐색
- 희소 그래프에서 연결된 구성 요소 찾기
동작 방식
- DFS는 두 가지 주요 방법으로 구현될 수 있습니다.
재귀 함수 활용
- 각 정점을 방문할 때마다 재귀적으로 인접 정점을 방문합니다.
- 방문 여부를 기록하는
visited배열을 사용하여 이미 방문한 정점을 다시 방문하지 않도록 합니다. - 재귀 함수가 깊이 들어갈수록 스택이 쌓이므로, 재귀 깊이에 주의해야 합니다.
스택 활용
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 합니다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 하며, 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냅니다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복합니다.
DFS의 기능을 생각하면 순서와 상관없이 처리해도 되지만, 코딩 테스트에서는 번호가 낮은 순서부터 처리하도록 명시하는 경우가 종종 있습니다. 따라서 관행적으로 번호가 낮은 순서부터 처리하도록 구현하는 편입니다.
구현
Graph와 연동
스택 활용
public struct Stack<Element> {
private var storage: [Element] = []
public init() { }
public init(_ elements: [Element]) {
storage = elements
}
public mutating func push(_ element: Element) {
storage.append(element)
}
public mutating func pop() -> Element? {
storage.popLast()
}
// 스택의 마지막 요소 확인하기 (stack.isEmpty의 전초)
public func peek() -> Element? {
storage.last
}
public func isEmpty() -> Bool {
peek() == nil
}
}
extension Graph where Element: Hashable {
func depthFirstSearch(from source: Vertex<Element>) -> [Vertex<Element>] {
var stack = Stack<Vertex<Element>>()
var pushed: Set<Vertex<Element>> = []
var visited: [Vertex<Element>] = []
stack.push(source)
pushed.insert(source)
visited.append(source)
outer: while let vertex = stack.peek() { // 1
let neighbors = edges(from: vertex) // 2
guard !neighbors.isEmpty else { // 3
stack.pop()
continue
}
for edge in neighbors { // 4
if !pushed.contains(edge.destination) {
stack.push(edge.destination)
pushed.insert(edge.destination)
visited.append(edge.destination)
continue outer // 5
}
}
stack.pop() // 6
}
return visited
}
}
print(graph2.depthFirstSearch(from: tokyo2))
[1: Tokyo, 3: Detroit, 6: Austin Texas, 4: San Francisco, 5: Washington DC, 7: Seattle]
- 스택의 맨 위에 있는 정점을 체크하고 스택이 비어질 때까지 이를 반복하며, 외부 루프를 라벨링하여 중첩된 루프에서도 다음 정점으로 계속 진행할 수 있습니다.
- 현재 vertex의 모든 인접 엣지를 저장합니다.
- 만약 현재 정점에 인접한 간선이 하나도 없다면, 스택에서 해당 정점을 꺼내고, 다시 반복문의 상위 레벨로 돌아갑니다.
- 현재 Vertex와 연결된 각 간선을 순환하면서 이웃 정점이 이미 방문한 정점인지를 확인하고, 그렇지 않은 경우에는 스택에 넣고 visited 배열에 추가합니다.
- 새로 방문할 이웃 노드를 찾았으므로, 새롭게 푸시된 이웃 노드로 이동합니다.
- 스택에서 제거하고 다음 정점으로 이동합니다.
재귀함수 활용
func depthFirstSearchNoStack(from source: Vertex<Element>) -> [Vertex<Element>] {
var visited: [Vertex<Element>] = []
var pushed: Set<Vertex<Element>> = []
func dfs(vertex: Vertex<Element>) {
pushed.insert(vertex)
visited.append(vertex)
let neighborEdges = edges(from: vertex)
for edge in neighborEdges {
if !pushed.contains(edge.destination) {
dfs(vertex: edge.destination)
}
}
}
dfs(vertex: source)
return visited
}
print(graph2.depthFirstSearchNoStack(from: tokyo2))
[1: Tokyo, 3: Detroit, 6: Austin Texas, 4: San Francisco, 5: Washington DC, 7: Seattle]
- 이 구현에서는 재귀 함수
dfs를 정의하고, 시작 정점source에서 재귀를 시작합니다. - 현재 정점에서 연결된 모든 이웃 정점에 대해 재귀적으로
dfs를 호출합니다. - 이 방식은 스택을 명시적으로 사용하는 것보다 간결하지만, 스택 오버플로우 위험이 있을 수 있습니다.
Int형 2차원 리스트에서 간단한 DFS 활용하기
재귀함수 활용
let testGraph = [
[],
[2,3,8],
[1,7],
[1,4,5],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
var visited = [Bool](repeating: false, count: testGraph.count)
func dfs(_ graph: [[Int]], _ start: Int) {
visited[start] = true
print(start, terminator: " ")
for i in graph[start] {
if !visited[i] {
dfs(graph, i)
}
}
}
dfs(testGraph, 1)
print()
1 2 7 6 8 3 4 5 Stack 활용
let testGraph = [
[],
[2,3,8],
[1,7],
[1,4,5],
[3,5],
[3,4],
[7],
[2,6,8],
[1,7]
]
var visited = [Bool](repeating: false, count: testGraph.count)
func dfsStack(_ graph: [[Int]],_ start: Int) {
var stack = Stack<Int>()
stack.push(start)
while let value = stack.pop() {
guard !visited[value] else {
continue
}
print(value, terminator: " ")
visited[value] = true
for i in graph[value] {
if !visited3[i] {
stack.push(i)
}
}
}
}
dfsStack(testGraph, 1)
1 8 7 6 2 3 5 4
예제
단어 변환 - 프로그래머스 LV3
문제 설명
- 두 개의 단어 begin, target과 단어의 집합 words가 있습니다. 아래와 같은 규칙을 이용하여 begin에서 target으로 변환하는 가장 짧은 변환 과정을 찾으려고 합니다.
- 한 번에 한 개의 알파벳만 바꿀 수 있습니다.
- words에 있는 단어로만 변환할 수 있습니다.
- 예를 들어 begin이 "hit", target가 "cog", words가 ["hot","dot","dog","lot","log","cog"]라면 "hit" -> "hot" -> "dot" -> "dog" -> "cog"와 같이 4단계를 거쳐 변환할 수 있습니다.
- 두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해주세요.
제한사항
- 각 단어는 알파벳 소문자로만 이루어져 있습니다.
- 각 단어의 길이는 3 이상 10 이하이며 모든 단어의 길이는 같습니다.
- words에는 3개 이상 50개 이하의 단어가 있으며 중복되는 단어는 없습니다.
- begin과 target은 같지 않습니다.
- 변환할 수 없는 경우에는 0를 return 합니다.
입출력 예
begin target words return
"hit" "cog" ["hot", "dot", "dog", "lot", "log", "cog"] 4
"hit" "cog" ["hot", "dot", "dog", "lot", "log"] 0입출력 예 설명
예제 #1
- 문제에 나온 예와 같습니다.
예제 #2
- target인 "cog"는 words 안에 없기 때문에 변환할 수 없습니다.
풀이
- 처음 문제를 보고나서 어떻게 문제를 풀어야할지 고민을 했었다. 단어는 하나만 변경되고 원하는 타겟에 맞추기 까지 최소 변환 값을 받아야 하기 때문에, 탐색 문제라고 생각하고 해당 문제를 접근했다.
- 예제1를 잘 보면 변환 가능 조건이 있는데, 단어의
count - 1개즉, 한 단어만 빼고 동일해야지 변경 할 수 있다는 것을 알게되었고, 주어진 words 값 만큼 dfs를 수행하면 문제를 해결 할 수 있다고 생각했다. 또한 한 번 찾으면 끝나는 문제가 아니라 다시 돌아가서 다른 경로도 찾아봐야 하기 때문에 백트래킹 문제라고 생각했다. - 하지만 계속해서 테스트 3에서 시간 초과 또는 실패가 나와서 원인이 뭘가 나의 알고리즘이 문제였을까 고민하고 계속 봤지만 다시 보니 변환 가능 조건을
count -1이 아니라 단어가 3개일때를 기준으로 2로 잡아서 그랬던 것이었다. - 문제 조건을 꼼꼼히 확인하자.
재귀함수를 활용한 문제 풀이
import Foundation
func solution(_ begin:String, _ target:String, _ words:[String]) -> Int {
// 최소 값 비교를 위한 최초 값
let INF = 99999999
var result = INF
// 방문처리를 위한 배열
var visited = [Bool](repeating: false, count: words.count)
func dfs(_ value: String,_ changeNum: Int) {
// 조건을 넘으면 조기 종료
if changeNum > result { return }
// 해당 사이클에서 target과 같다면 result 최신화 후 사이클 종료
if value == target {
result = min(result, changeNum)
return
}
for (idx, word) in words.enumerated() {
// 방문 했거나, 본인을 가리키는 단어라면 무시
if visited[idx] || value == word { continue }
// zip을 활용하여 비교 값과 틀린 단어 몇개인지 확인
let diff = zip(value, word).filter { $0 != $1 }.count
if diff == 1 {
// 백트래킹
visited[idx] = true
dfs(word, changeNum + 1)
visited[idx] = false
}
}
}
dfs(begin,0)
// dfs 탐색 후 매칭된 값이 없을 땐 '0'
return result == INF ? 0 : result
}- 각 사이클에 대해서 깊게 탐색하고 전부 탐색했을 경우 그 전 사이클로 돌아가서 다른 경로를 탐색하는 방법입니다.
스택을 활용한 문제 풀이
import Foundation
func solution(_ begin: String, _ target: String, _ words: [String]) -> Int {
let INF = 999999999
var result = INF
var visited = [Bool](repeating: false, count: words.count)
// 스택에는 (현재 단어, 변환 횟수, 방문 상태 배열)을 저장
var stack: [(String, Int, [Bool])] = [(begin, 0, visited)]
while !stack.isEmpty {
let (currentWord, changeNum, currentVisited) = stack.removeLast()
if currentWord == target {
result = min(result, changeNum)
continue
}
for (idx, word) in words.enumerated() {
if currentVisited[idx] || currentWord == word { continue }
let diff = zip(currentWord, word).filter { $0 != $1 }.count
if diff == 1 {
var newVisited = currentVisited
newVisited[idx] = true
stack.append((word, changeNum + 1, newVisited))
}
}
}
return result == INF ? 0 : result
}- 스택을 활용해서 깊이 탐색합니다.
- 즉, 해당 문제는 DFS를 활용해서 깊게 탐색하다가 해당 조건에서 탐색을 종료하는 것 입니다.
visited의 차이점
- 재귀 함수 방식
- 재귀 함수를 사용할 떄, 각 함수 호출은 새로운
단계를 만듭니다. 재귀 호출이 끝나고 이전 단계로 돌아갈 때, 이전 단계의visited상태로 되돌려야 합니다. - 이를 위해 재귀 호출 후에
visited[idx] = false를 설정하는 것 입니다. - 이렇게 되돌리는 과정은 다음 가능한 경로를 탐색할 때 이전 경로의 영향을 받지 않도록 하기 위해서 입니다.
- 재귀 함수를 사용할 떄, 각 함수 호출은 새로운
- 스택 방식
- 스택 방식은, 모든 탐색 상태를 스택에 저장합니다. 새로운 탐색 상태를 만들 때 마다, 현재의
visited상태의 복사본을 만들어 스택에 넣습니다. 이렇게 하면, 각 탐색 상태는 완전히 독립적이게 됩니다.
- 스택 방식은, 모든 탐색 상태를 스택에 저장합니다. 새로운 탐색 상태를 만들 때 마다, 현재의
불량 사용자 - 프로그래머스 LV3 (19 카카오 인턴십)
문제 설명
- 개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 불량 사용자라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다.
- "무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 제재 아이디 라고 부르기로 하였습니다.
- 예를 들어, 이벤트에 응모한 전체 사용자 아이디 목록이 다음과 같다면
| 응모자 아이디 |
|---|
| frodo |
| fradi |
| crodo |
| abc12 |
| frodoc |
다음과 같이 불량 사용자 아이디 목록이 전달된 경우,
| 불량 사용자 |
|---|
| frd |
| abc1** |
불량 사용자에 매핑되어 당첨에서 제외되어야 야 할 제재 아이디 목록은 다음과 같이 두 가지 경우가 있을 수 있습니다.
| 제재 아이디 |
|---|
| frodo |
| abc123 |
| 제재 아이디 |
|---|
| fradi |
| abc123 |
- 이벤트 응모자 아이디 목록이 담긴 배열 user_id와 불량 사용자 아이디 목록이 담긴 배열 banned_id가 매개변수로 주어질 때, 당첨에서 제외되어야 할 제재 아이디 목록은 몇가지 경우의 수가 가능한 지 return 하도록 solution 함수를 완성해주세요.
[제한사항]
- user_id 배열의 크기는 1 이상 8 이하입니다.
- user_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 응모한 사용자 아이디들은 서로 중복되지 않습니다.
- 응모한 사용자 아이디는 알파벳 소문자와 숫자로만으로 구성되어 있습니다.
- banned_id 배열의 크기는 1 이상 user_id 배열의 크기 이하입니다.
- banned_id 배열 각 원소들의 값은 길이가 1 이상 8 이하인 문자열입니다.
- 불량 사용자 아이디는 알파벳 소문자와 숫자, 가리기 위한 문자 '*' 로만 이루어져 있습니다.
- 불량 사용자 아이디는 '*' 문자를 하나 이상 포함하고 있습니다.
불량 사용자 아이디 하나는 응모자 아이디 중 하나에 해당하고 같은 응모자 아이디가 중복해서 제재 아이디 목록에 들어가는 경우는 없습니다.- 제재 아이디 목록들을 구했을 때 아이디들이 나열된 순서와 관계없이 아이디 목록의 내용이 동일하다면 같은 것으로 처리하여 하나로 세면 됩니다.
[입출력 예]
user_id banned_id result
["frodo", "fradi", "crodo", "abc123", "frodoc"] ["fr*d*", "abc1**"] 2
["frodo", "fradi", "crodo", "abc123", "frodoc"] ["*rodo", "*rodo", "******"] 2
["frodo", "fradi", "crodo", "abc123", "frodoc"] ["fr*d*", "*rodo", "******", "******"] 3풀이
- 각 신고 id마다 동일한 userId를 저장하고 있는 2차원 배열을 새롭게 만듭니다. 이는 인접 리스트 형식으로 표현 할 수 있습니다.
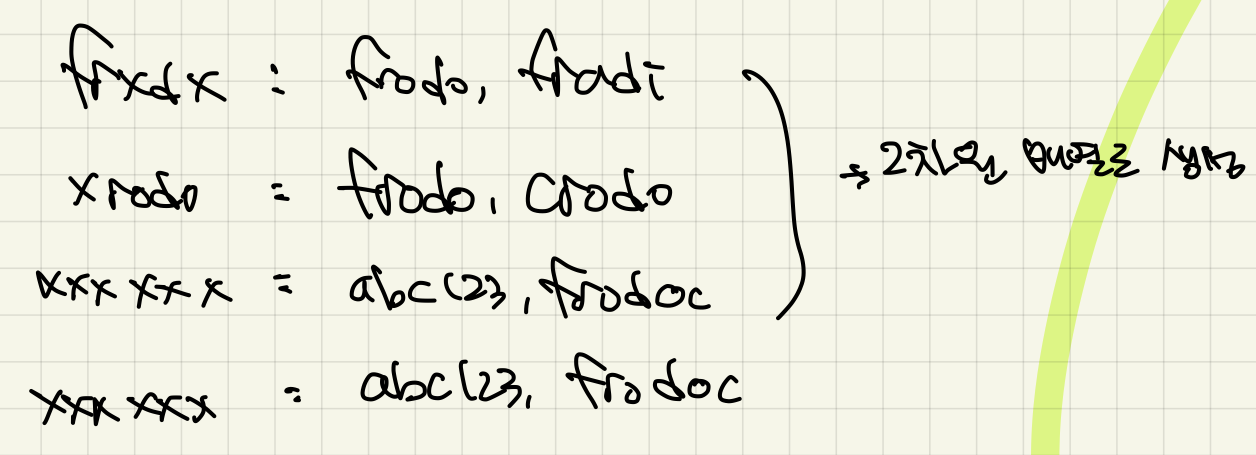
- 해당 인접 리스트에 대해서 dfs를 진행해주면 됩니다. 즉, 각 각 선택할 수 있는 항목들을 결과 배열에 저장하고 해당 배열에 대해서 공통된 값을 제거 해주면 됩니다.
공통 함수
- user_id와 banned_id에서 공통의 값을 찾아내서 인접 리스트를 만드는 함수 입니다.
func checkId(_ user_id: String, _ banned_id: String) -> Bool {
guard user_id.count == banned_id.count else { return false }
let xCount = banned_id.filter { $0 == "*" }.count
var sameCount = 0
for (user, banned) in zip(user_id, banned_id) {
if user == banned { sameCount += 1 }
}
return sameCount + xCount == user_id.count ? true : false
}스택으로 풀이
func solution(_ user_id: [String], _ banned_id: [String]) -> Int {
var bannedList: [[String]] = []
for ban in banned_id {
var tempArray: [String] = []
for user in user_id {
if checkId(user, ban) {
tempArray.append(user)
}
}
bannedList.append(tempArray)
}
// bannedList index번호와 누적된 ban id list
var stack: [(index: Int, banIdList: [String])] = []
var result: [[String]] = []
// 최초 값 저장하기
for banId in bannedList[0] {
stack.append((0, [banId]))
}
while stack.count > 0 {
let current = stack.removeLast()
// banned id 끝까지 다 탐색했을 경우
if current.index == bannedList.count - 1 {
result.append(current.banIdList)
continue
}
let index = current.index + 1
// 다음 bannedId List에서 가능한 banend id 배열에 넣기
for banned in bannedList[index] {
var banIdList = current.banIdList
// visited되었다면 해당 값은 무시 (값 중복 필터링)
if banIdList.contains(banned) { continue }
banIdList.append(banned)
stack.append((index, banIdList))
}
}
// 중복 패턴 제거
return Set(result.map { $0.sorted() }).count
}재귀함수로 풀이
func dfs(
_ bannedList: [[String]],
_ index: Int,
_ banIdList: [String],
_ result: inout Set<[String]>) {
if index == bannedList.count {
result.insert(banIdList.sorted())
return
}
for banned in bannedList[index] {
if !banIdList.contains(banned) {
// 해당 값이 없다면 배열 값을 추가하고 재귀 함수 실행
dfs(bannedList, index + 1, banIdList + [banned], &result)
}
}
}
func solution(_ user_id: [String], _ banned_id: [String]) -> Int {
var bannedList: [[String]] = []
for ban in banned_id {
var tempArray: [String] = []
for user in user_id {
if checkId(user, ban) {
tempArray.append(user)
}
}
bannedList.append(tempArray)
}
var result: Set<[String]> = []
dfs(bannedList, 0, [], &result)
return result.count
} 출처(참고문헌)
- https://www.kodeco.com/books/data-structures-algorithms-in-swift/v4.0/chapters/39-breadth-first-search-challenges
- 이것이 코딩 테스트이다 - 나동빈
- https://school.programmers.co.kr/learn/courses/30/lessons/43163
- https://school.programmers.co.kr/learn/courses/30/lessons/64064
제가 학습한 내용을 요약하여 정리한 것입니다. 내용에 오류가 있을 수 있으며, 어떠한 피드백도 감사히 받겠습니다.
감사합니다.
