저번에 구현하고 아직 멈춰있던 파이썬 크롤링을 진행한다.
우선순위가 인증번호보다 이게 더 높기때문에..!
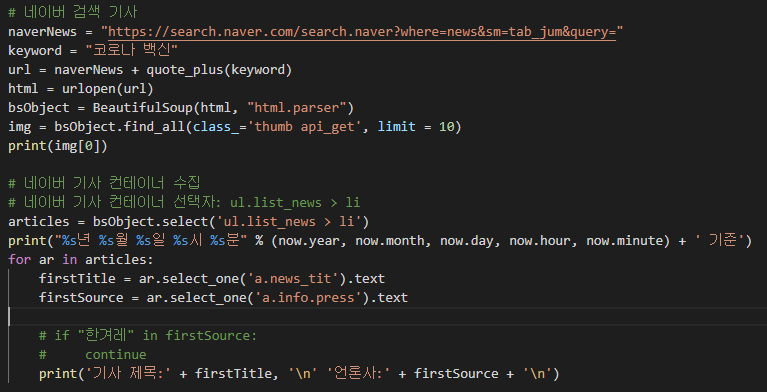
저번에 어디까지 구현했냐면, 네이버에 '코로나 백신' 입력했을 때 뉴스 영역 게시물들의 언론사와 제목을 가져오는 것까지
구현했다.
오늘은 이미지도 가져와서 저장하는 걸 구현해보려한다.
이미지도 가져오려면 url을 구성요소로 구문 분석을 해야한다.
from urllib.parse import quote_plus요런 패키지를 추가해준다.
한글 단어를 퍼센트로 인코딩해주는 기능을 한다.
사용할 때는
url = naverNews + quote_plus(keyword)요렇게.
네이버 뉴스 검색 창에서 키워드를 검색 후 노출되는 이미지를 가져올 것이기 때문에,
naverNews 로 url을 지정해주고.
keyword 로 '코로나 백신'을 지정해줬다.
img = bsObject.find_all(class_='thumb api_get', limit = 10)
이미지의 공통된 class 들을 이용해서 최대 10개까지 가져오게 지정한 코드다.
공통된 class 라는건~
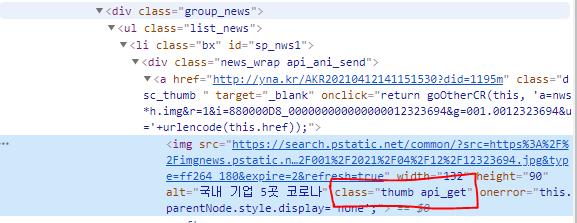
이미지들이 각각 저 유니크한 class 를 가지고 있기에 저것만 가져와주면 이미지들을 가져올 수 있는것이다.
print(img[0]) 은 잘가져왔나 확인하기 위한 코드.
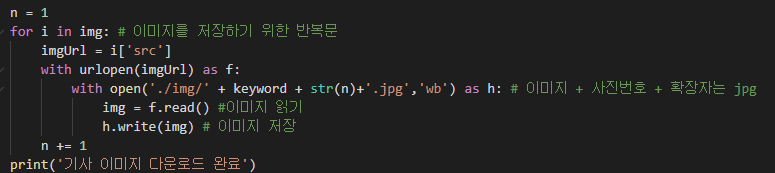
반복문을 돌리는데,
헷갈렸던 부분이 'src' 저 부분이다.
나는 가져왔을 때 'src=' 의 형태로 가져오는데 다른분들이 하신걸보면 'data-source=' 이렇게 가져오던데..
이유는 모르겠다 ㅠㅠ 아무튼 print로 다른 부분을 확인하고 수정해줬다.
이미지 파일은 img라는 폴더를 생성해주고 거기에 넣어줬다.
폴더를 꼭 저 부분에 들어갈 이름처럼 생성해줘야한다.
경로를 꼭 확인할 것~
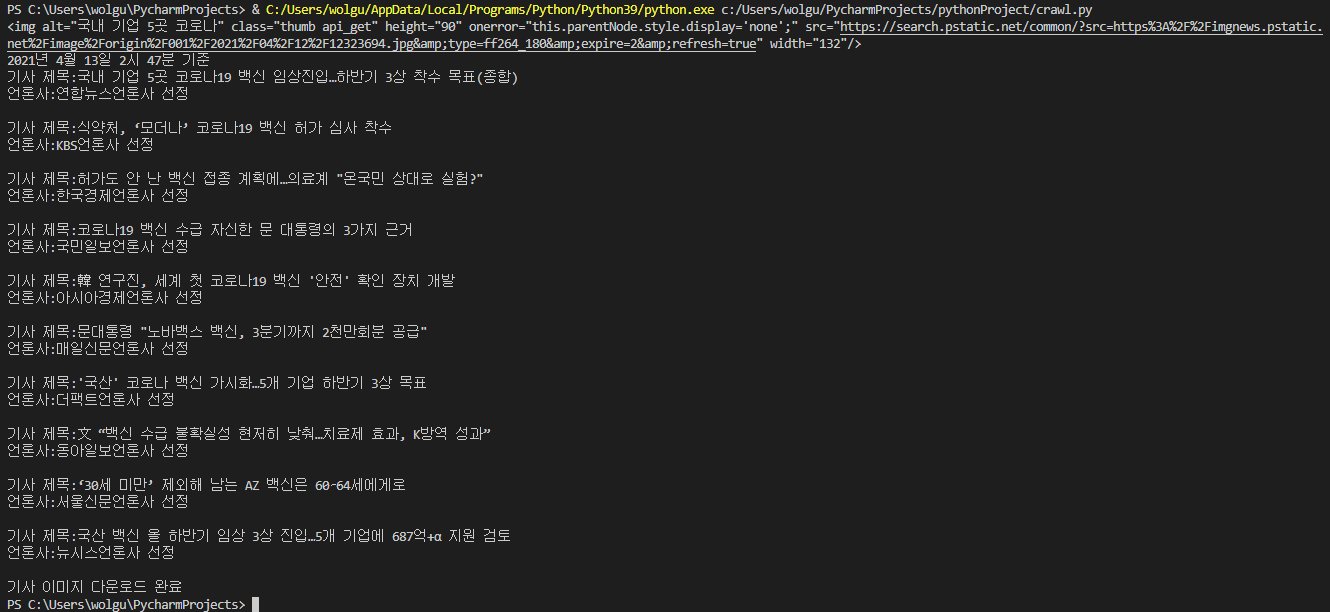
실행하면 요렇게 결과값이 나오고.

이미지 저장도 잘된다~
역시 크롤링도 문제는 web 연결인가.. ㅎㅎ
오늘의 코멘트: 인증번호도 크롤링처럼 착착되면 얼마나 좋니 ㅎㅎ
