어제에 이어서 계속 진행한다.
먼저 프로젝트 기사 쪽 페이지가 어느정도 나왔냐면,

이정도 나왔다.
여기서 크롤링을 '어떻게' 사용하느냐를 세밀하게 정해야한다.
지금 생각나는 건,
- 각 언론사를 클릭했을 때
- 모든 기사를 클릭했을 때
- 검색필드에서 원하는 언론사를 검색했을 때
- 크롤링 주기는 어떻게 할 것인가
- 기사(데이터)는 계속 축적을 하는가
이렇게 5가지가 되겠다.
2번: 지금의 형태 그대로 가져가면 된다.
애초에 이 형태가 네이버 뉴스에 '코로나 백신'을 검색했을 때의 첫번째 페이지에 존재하는
기사 제목, 기사 언론사, 기사 이미지, 기사 URL을 받아오고 있기 때문.
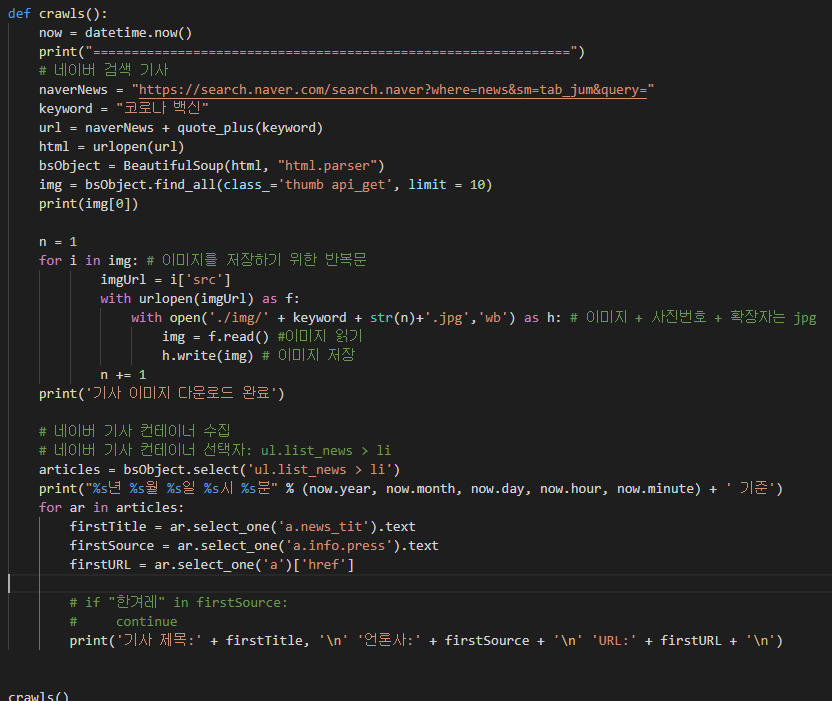
3번: 언론사 크롤링 함수에 검색한 값을 인자값에 넣으면 된다. 그리고 그 값을 keyword에 넣으면 해결.
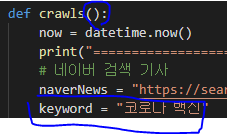
1번: 3번과 마찬가지라고 생각하는데 3번에서는 검색한 값을 받아온다면, 1번에선 지정되어 있는 값을 받아오면 된다.
ex) jtbc, mbc ...
4번: 이건 2가지로 생각중이다.
-1) 페이지에서 버튼을 이용하거나 검색을 이용한 행동을 한 시점.
-2) 특정 시간에 함수 자동 실행. ex) 12시, 3시, 6시, 9시 ..
5번: 계속 축적한다고 해서 데이터가 거대하거나 그러진 않을 것이다.
한 페이지당 9개씩 배분을 해주면 되는거고.. 문제가 되진 않을 것으로 예상한다.
또한 주의해야할 점으로는..
- 기사가 중복되는가?
- 네이버 뉴스에 검색 시, 몇 페이지까지가 검색 범위인가?
오.. 요거 2개는 구현하면서 더 생각해봐야겠다. 당장에는 해결점이 떠오르질 않는다.
5개 밖에 안된다고 생각하지만 이 안에는 여러가지 개념과 응용이 들어갈 것이다.
잘 헤쳐나가야 인증번호 검증하는 API도 얼른 완성하지..
아 그러고보니 디폴트를 '모든기사'버튼이 클릭되어 있는 상태여야겠구나..
내일부터 저 위에 있는 5개의 작업을 진행한다.
오늘의 코멘트: 방향성을 잡아놓고 시작~
