StandardScaler는 간단히 말하자면 "표준화"이다
표준화란?
평균을 빼고 단위 분산에 맞게 조정하여 변수의 범위를 scaling 해주는 것이다.
간단히 말하면 특성들의 평균을 0으로 분산을 1로 스케일링하는 것이다.
scaling(스케일링)
머신러닝을 위해 데이터셋을 정제할 때 특성별로 데이터 스케일이 다르다면 성능이 낮아질 수 있다
따라서 모든 특성의 범위를 같게 만들어줘 성능을 높힐 수 있다.
scikit-learn에서 StandardScaler를 사용할 때
- fit : 훈련 데이터의 분포 학습
- transform : 학습한 분포를 적용해 스케일링 조정
데이콘에서 <쇼핑몰 지점별 매출액 예측>을 하는데
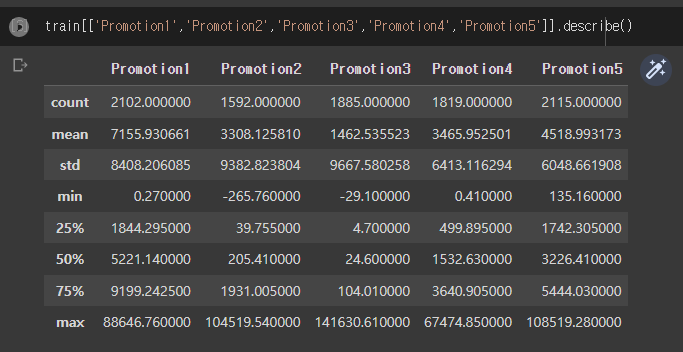
이와 같이 각 특성이 다른 분포를 가지고 있을 때
StandardScaler를 통해 스케일링을 한다고 한다.
