
💡 이 글의 내용은 MySQL 8.0 이상 + InnoDB 스토리지 엔진 환경을 기준으로 작성되었습니다.
💡 이 글은 사이드 프로젝트 “여기서 놀자”의 호텔 검색 기능을 구현하고 성능을 개선한 과정을 정리한 글입니다.
구현할 기능 - 호텔 검색
지역, 카테고리, 숙박 날짜, 숙박 인원 등을 통해 조건에 맞는 호텔을 검색하는 기능
[요구사항]
- 카테고리, 상세 지역으로 필터링이 가능하다. [완료]
- 페이징을 지원한다. [완료]
- 호텔 이름, 평점, 가격, 주소, 지역, 카테고리 등 필요한 정보를 보여준다.
- 지역으로 필터링이 가능하다.
- 설정한 인원이 묵을 수 있는 객실이 있는 호텔들을 우선적으로 노출한다.
- 각 호텔에서 예약 가능한 가장 저렴한 객실의 가격을 표시한다.
- 지정한 날짜에 예약이 가능한 객실이 있는 호텔들을 우선적으로 노출한다.
- 가격 범위를 지정하여 검색이 가능하다.
목표
- 필요한 정보 노출
- 지역으로 필터링
필요한 정보 노출시키기
일단은 현재까지는 SELECT * 로 hotels 테이블의 모든 데이터를 불러왔다. 이제는 원하는 정보들만 보여줄 수 있도록 해보자.
SELECT h.name AS hotel_name,
h.rating AS hotel_rating,
h.address AS hotel_address,
dr.name AS detail_region_name,
c.name AS category_name
FROM hotels h
JOIN detail_regions dr ON h.detail_region_id = dr.id
JOIN categories c ON h.category_id = c.id
WHERE h.id > 100000
ORDER BY h.id
LIMIT 20;기존 쿼리에서 카테고리 이름과 상세 지역 이름을 가져오기 위해 JOIN이 추가되었다.
여기서 성능을 향상시키기 위해서 categories 테이블이나 detail_regions 테이블의 데이터를 hotels 테이블에 포함시키는 역정규화를 고려해볼 수 있다.
역정규화를 했을 때의 장점
- 쿼리 성능 향상:
hotels테이블에 다른 테이블의 정보가 포함되면,hotels테이블에 대한 쿼리만으로 필요한 정보를 얻을 수 있다. 이는 조인 연산을 없애므로 쿼리 성능을 향상시킨다. - 복잡성 감소:
hotels테이블을 쿼리할 때 마다 다른 테이블을 조인하지 않아도 되므로, 쿼리의 복잡성이 감소합니다.
역정규화를 했을 때의 단점
- 데이터 불일치 위험: 만약 다른 테이블의 데이터가 변경되면,
hotels테이블에서도 해당 데이터를 업데이트해야 한다. 이는 두 테이블 간에 데이터 불일치를 일으킬 수 있다. - 저장 공간 증가: 다른 테이블의 데이터를
hotels테이블에 복제하면, 저장 공간이 증가한다.
더 확실히 장단점을 파악하기 위해 역정규화를 하기 전과 하고난 뒤를 비교해보자.
역정규화 이전
역 정규화를 하기 전의 실행 계획을 살펴보자.
- Explain Analyze
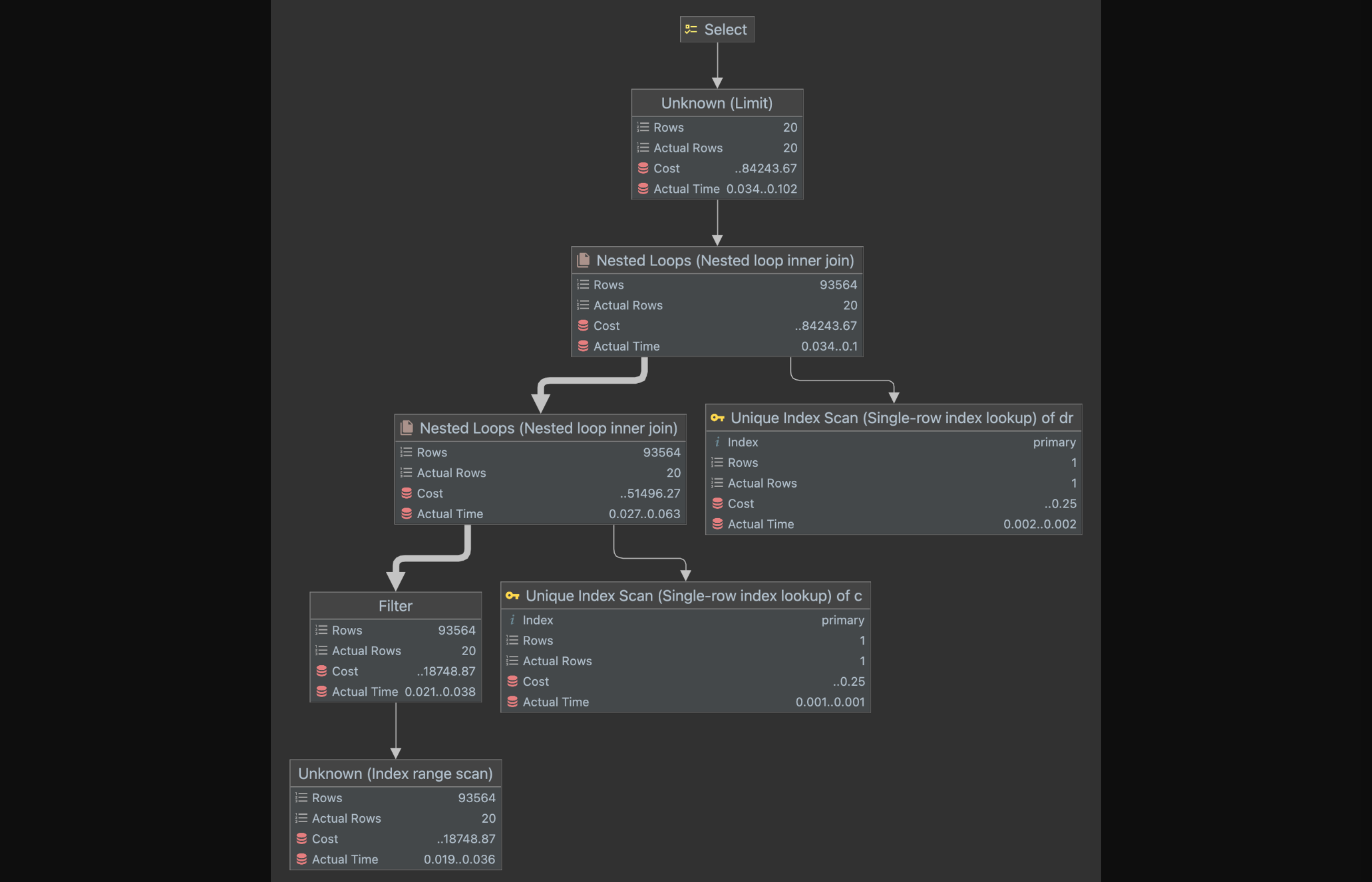
실행 계획을 살펴보면 상세 지역 이름, 카테고리 이름을 가져오기 위해 hotels 테이블과 detail_regions 테이블과 categories 테이블을 조인하고있다.
역정규화 이후
이제 역정규화를 진행해보자.
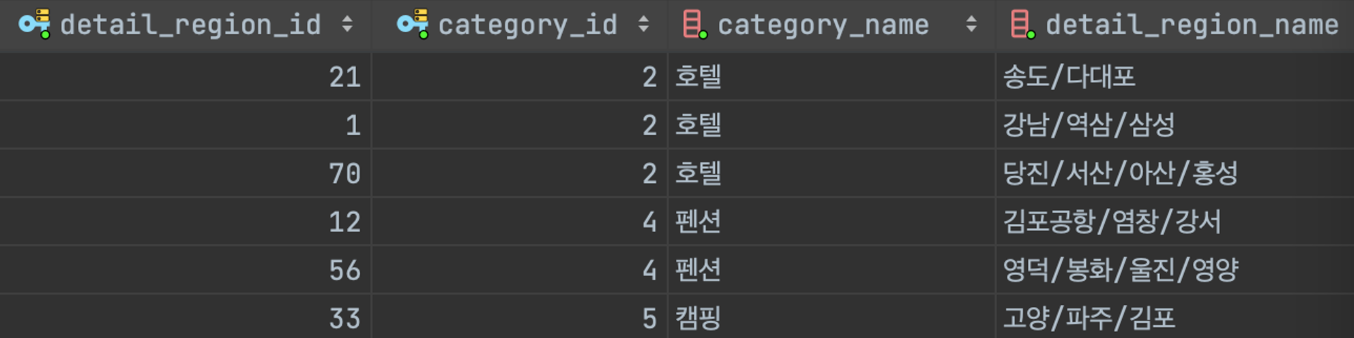
위와 같이 hotels 테이블에 category_name, detail_region_name 컬럼을 추가했다.
SELECT name,
rating,
address,
detail_region_name,
category_name
FROM hotels
WHERE id > 100000
ORDER BY id
LIMIT 20;이제 위와 같이 쿼리를 바꾸고 성능을 측정해보자.
- Explain Analyze
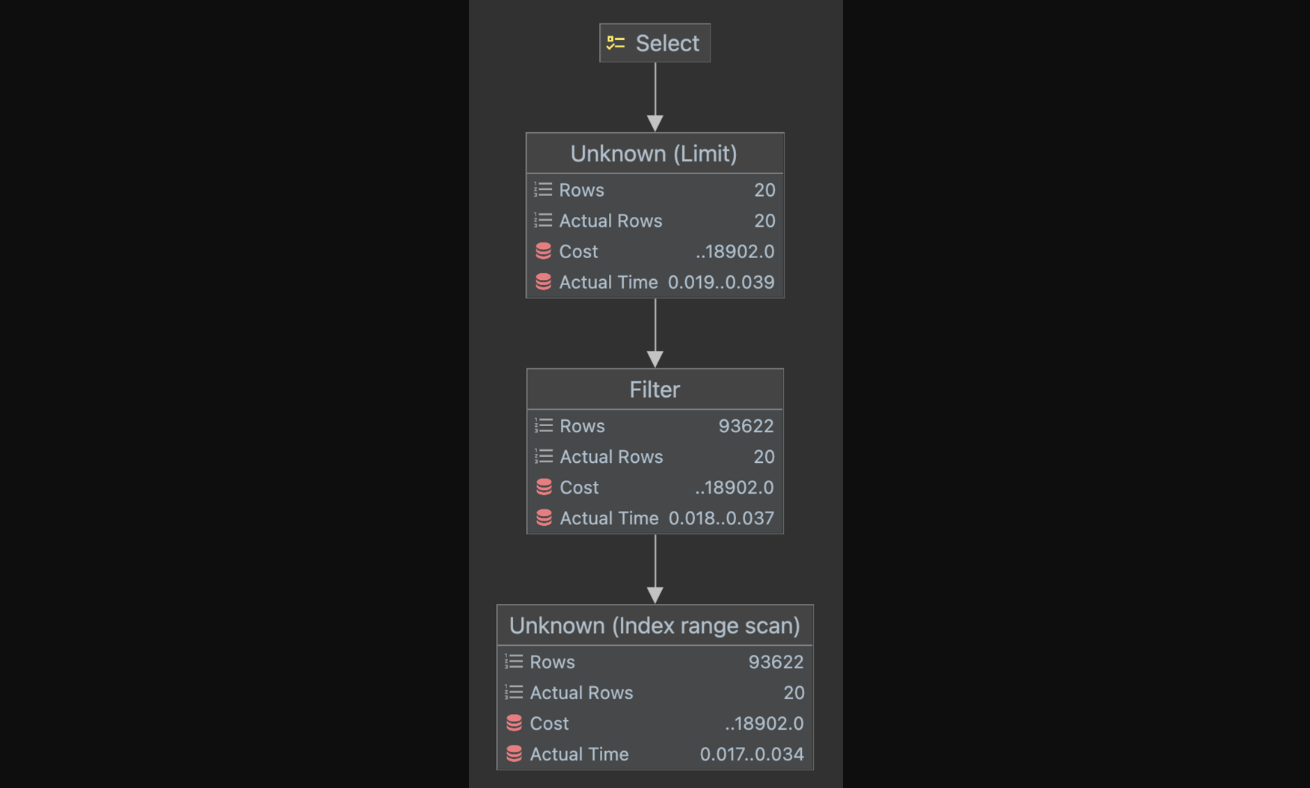
쿼리도 단순해졌고, 성능도 역정규화 전보다 60%(0.1ms → 0.04ms)정도 향상된 모습이다.
역정규화를 진행함으로써 데이터 일관성을 신경써야하고, 전체 데이터 용량도 늘어났지만 결국 아래와 같은 이유들로 역정규화를 진행하는 것이 좋다고 판단하였다.
- categories, detail_regions 테이블의 데이터 추가, 변경, 삭제가 적다. (호텔의 카테고리나 새로운 상세지역이 추가, 변경, 삭제될 일이 거의 없을 것이라고 판단)
- 쿼리의 성능이 60% 정도 향상된다.
지역으로 필터링
이번에는 지역으로 필터링 할 수 있는 기능을 추가해보자.
SELECT h.name AS hotel_name,
rating,
address,
detail_region_name,
category_name
FROM hotels h
JOIN detail_regions dr ON detail_region_id = dr.id
WHERE dr.region_id = 1
AND h.id > 100000
ORDER BY h.id
LIMIT 20;지역 id는 detail_regions테이블에 있으므로 위와 같이 JOIN을 수행해야한다.
이제 실행계획을 살펴보자.
- Explain Analyze
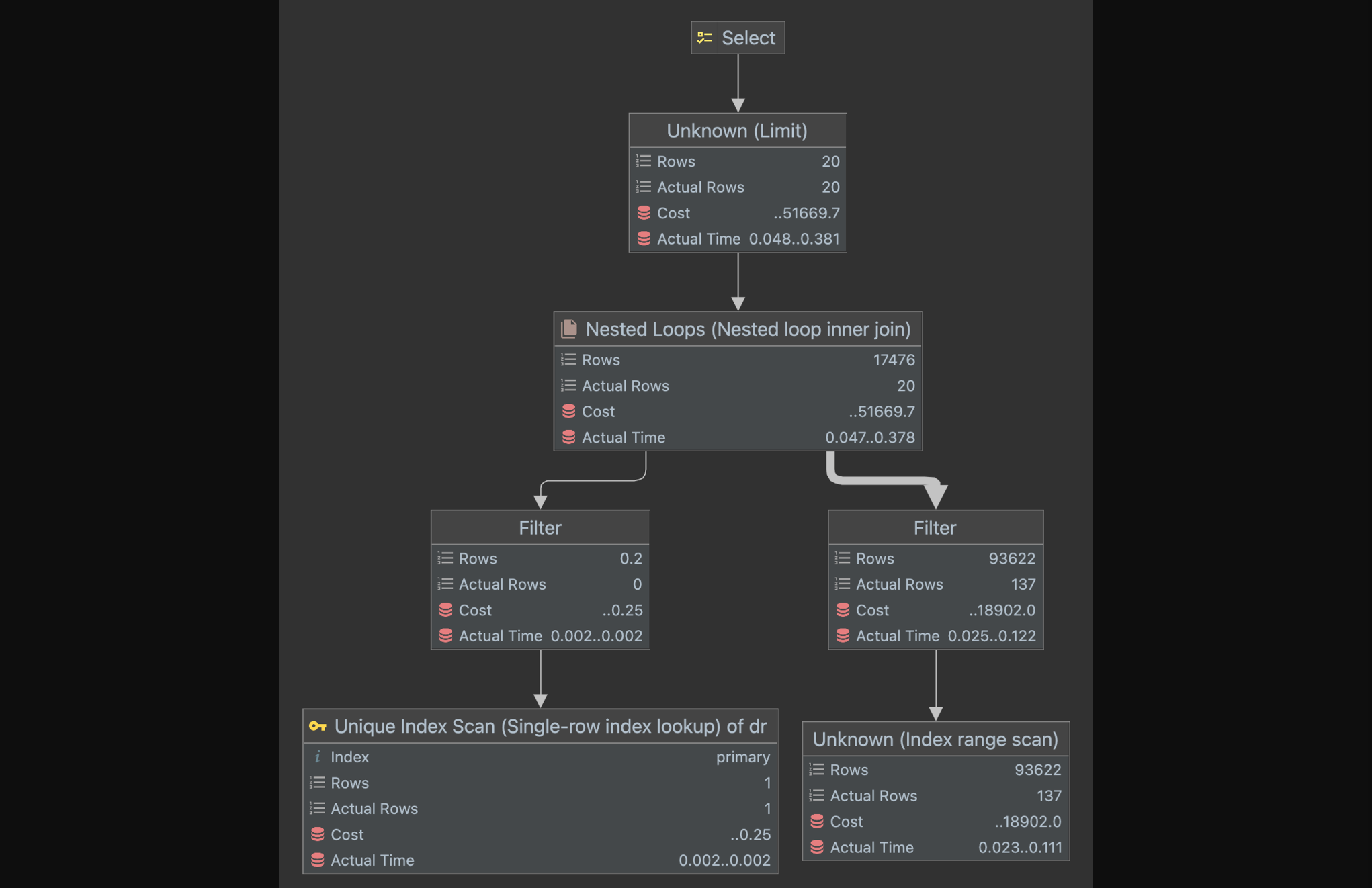
실행 계획을 분석해보면 아래와 같다.
- hotels 테이블의 id 인덱스를 사용하여
id > 100000조건을 만족하는 row를 필터링한다. - detail_regions 테이블의 region_id 인덱스를 사용하여
region_id = 1조건을 만족하는 row를 필터링한다. - Nested Loop Join을 사용하여 hotels 테이블과 detail_regions 테이블을 조인한다. 이 조인은 detail_region_id와 id 컬럼을 사용한다.
LIMIT 20절을 적용하여 최종 결과를 20개의 row로 제한한다.
실행 계획을 보면 Nested Loop Join 작업에서 조인 결과를 필터링하는 과정에서 약간의 성능 저하가 발생한다. 이는 detail_regions 테이블에서 region_id = 1 조건을 만족하는 로우가 많아서 발생하는 문제이다.
이를 해결하기 위해서는 역시나 역정규화를 고려할 수 있다. 역정규화를 진행해서 성능을 비교해보자.
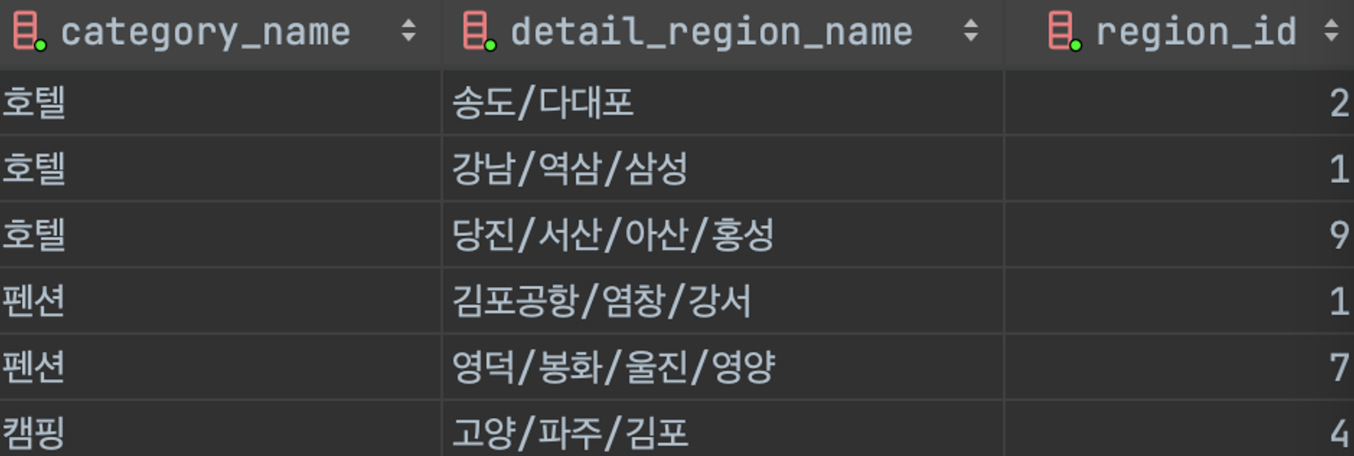
위와 같이 hotels 테이블에 region_id 컬럼을 추가했다.
SELECT h.name AS hotel_name,
rating,
address,
detail_region_name,
category_name
FROM hotels h
WHERE h.region_id = 1
AND h.id > 100000
ORDER BY h.id
LIMIT 20;이제 위와 같이 쿼리를 바꾸고 성능을 측정해보자.
- Explain Analyze
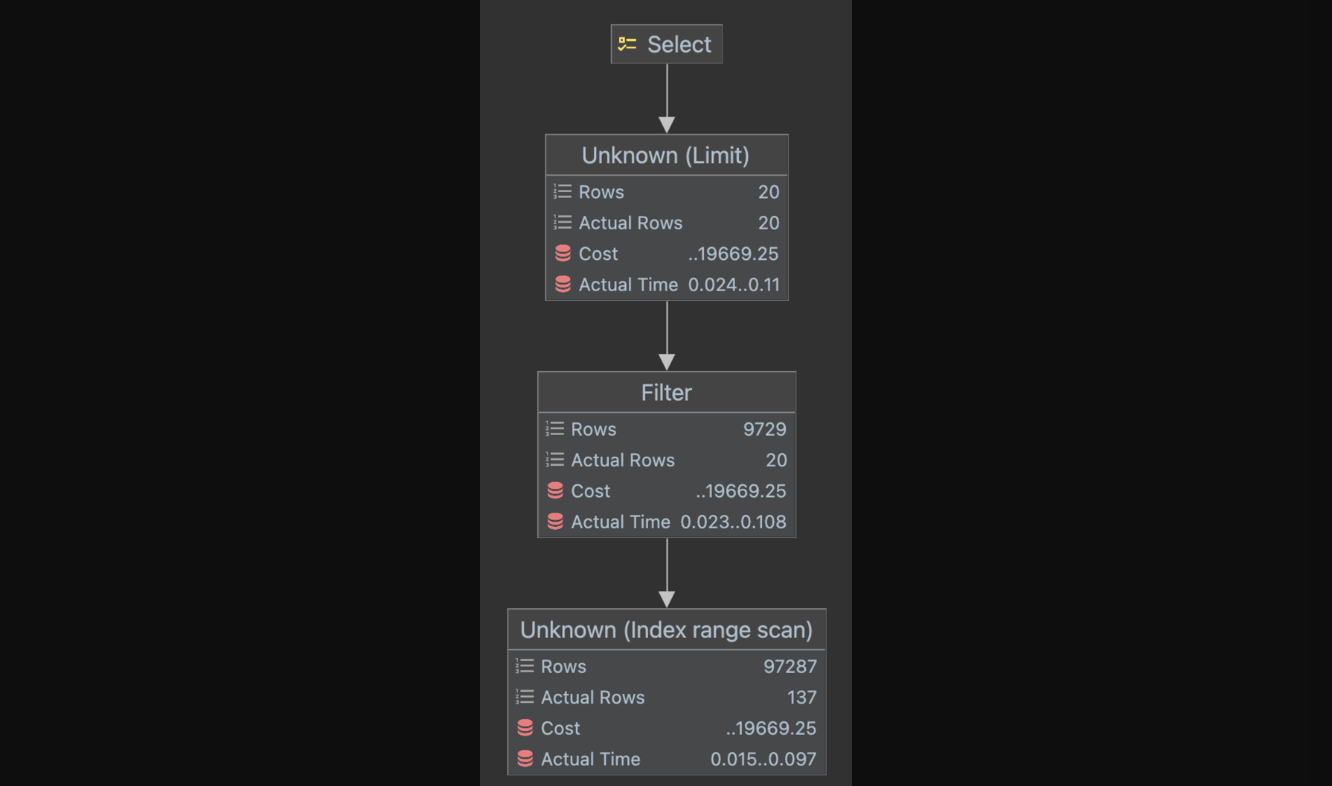
쿼리의 복잡도도 감소하고, 성능도 역정규화 전보다 71%(0.38ms → 0.11ms)정도 향상된 모습이다.
숙소의 지역 정보는 변경될 일이 거의 없고, 추가되는 데이터도 작기 때문에 역정규화를 진행하는 것으로 결정하였다.
역정규화를 진행함으로써 데이터 일관성을 신경써야하고, 전체 데이터 용량도 늘어났지만 결국 아래와 같은 이유들로 역정규화를 진행하는 것이 좋다고 판단하였다.
- regions 테이블의 데이터 추가, 변경, 삭제가 적다.
- 쿼리의 성능이 71% 정도 향상된다.
