
💡 이 글의 내용은 MySQL 8.0 이상 + InnoDB 스토리지 엔진 환경을 기준으로 작성되었습니다.
💡 이 글은 사이드 프로젝트 “여기서 놀자”의 호텔 검색 기능을 구현하고 성능을 개선한 과정을 정리한 글입니다.
구현할 기능 - 호텔 검색
지역, 카테고리, 숙박 날짜, 숙박 인원 등을 통해 조건에 맞는 호텔을 검색하는 기능
[요구사항]
- 카테고리, 상세 지역 등으로 필터링이 가능하다.
- 페이징을 지원한다.
- 호텔 이름, 평점, 가격, 주소, 지역, 카테고리 등 필요한 정보를 보여준다.
- 지역으로 필터링이 가능하다.
- 설정한 인원이 묵을 수 있는 객실이 있는 호텔들을 우선적으로 노출한다.
- 각 호텔에서 예약 가능한 가장 저렴한 객실의 가격을 표시한다.
- 지정한 날짜에 예약이 가능한 객실이 있는 호텔들을 우선적으로 노출한다.
- 가격 범위를 지정하여 검색이 가능하다.
목표
- 카테고리와 상세 지역으로 필터링
- 페이징 구현
카테고리와 상세 지역으로 필터링
SELECT *
FROM hotels
WHERE category_id = 1
AND detail_region_id = 1;나는 위와 같은 쿼리로 카테고리와 상세 지역으로 필터링이 가능한 호텔 검색 쿼리를 구현하려고 한다.
일단 위 쿼리의 실행 계획을 분석해보자.
- Explain
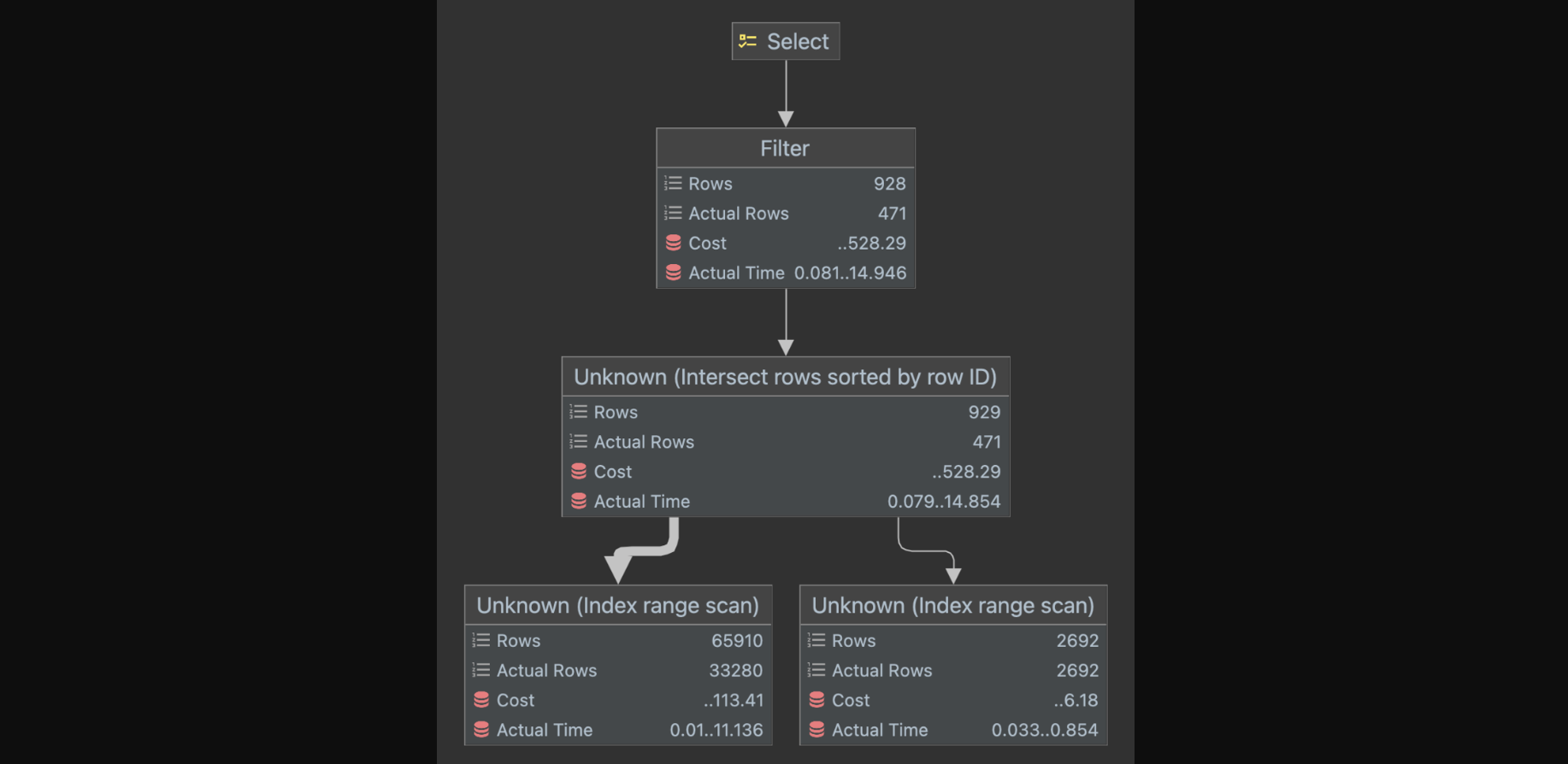
id select_type table type key key_len ref rows filtered Extra 1 SIMPLE hotels index_merge detail_region_id,category_id 8,8 null 928 99.94 Using intersect(detail_region_id,category_id); Using where - Explain Analyze
위 결과로 알 수 있는 것으로는 아래의 사항들이 있다.
- Explain 쿼리의 type 파라미터의 값이
index_merge인데, 이 경우는 2개 이상의 인덱스를 이용하여 여러 결과를 만들어낸 후 그 결과를 병합해서 처리하는 방식이다. - 위 쿼리의 실행 과정을 살펴보면
detail_region_id를 사용하여 검색한 결과와,category_id를 사용하여 검색한 결과를 교집합 연산으로 합친다.- InnoDB 스토리지 엔진이 외래 키에도 자동으로 인덱스를 생성하기 때문에 왜래키인
detail_region_id와category_id에 인덱스가 자동으로 생성되어 적용되어 있다.
- InnoDB 스토리지 엔진이 외래 키에도 자동으로 인덱스를 생성하기 때문에 왜래키인
index_merge 는 아래와 같은 단점이 있다.
- 여러 인덱스를 읽어야 하므로 인덱스 레인지 스캔 보다 효율이 떨어진다.
- 여러 결과들에 교집합, 합집합, 중복 제거와 같은 추가적인 연산을 수행해야 해서 성능이 떨어진다.
결국 이 쿼리는 두개의 인덱스를 각각 사용한 뒤 그 결과를 합치는 연산을 한다.
복합 인덱스로 성능 개선하기(1)
위와 같은 상황은, 복합 인덱스를 생성하여 성능을 개선할 수 있다.
create index categories_detail_regions_idx on hotels (category_id, detail_region_id);이제 다시 Explain과 Explain Analyze로 실행 계획을 분석해보자.
- Explain
id select_type table type key key_len ref rows filtered Extra 1 SIMPLE hotels ref categories_detail_regions_idx 16 const,const 471 100 null - Explain Analyze
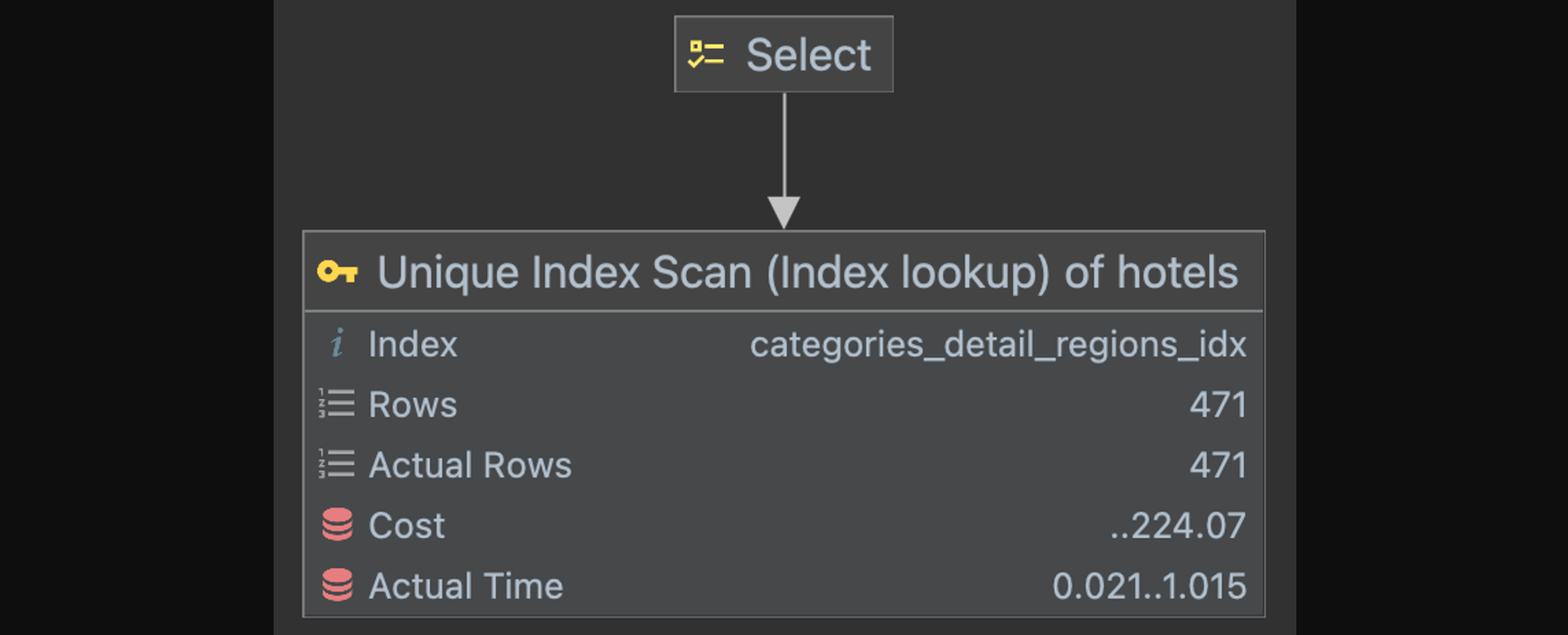
이제 두 인덱스가 아닌 하나의 복합 인덱스를 통해서 데이터를 조회한다.
복합 인덱스로 성능 개선하기(2)
하지만, 복합 인덱스를 생성할 때 선행 컬럼은 카디널리티가 높은 컬럼으로 하는 것이 좋다.
왜냐하면, 복합 인덱스 사용 시 선행 컬럼에 대한 조건으로 필터링을 한 뒤 그 뒤의 컬럼으로 필터링을 하는데, 선행 컬럼의 카디널리티가 높으면 뒤에 조건을 확인해야할 레코드 수가 줄어들기 때문이다.
- 참고로, 카테고리는 6개, 상세 지역은 75개의 고유한 값을 갖고있으므로, 상세 지역의 카디널리티가 더 높다.
create index detail_regions_categories_idx on hotels (detail_region_id, category_id);이번에는 위와 같은 인덱스를 생성해서 다시 쿼리를 실행해보자.
- Explain Analyze
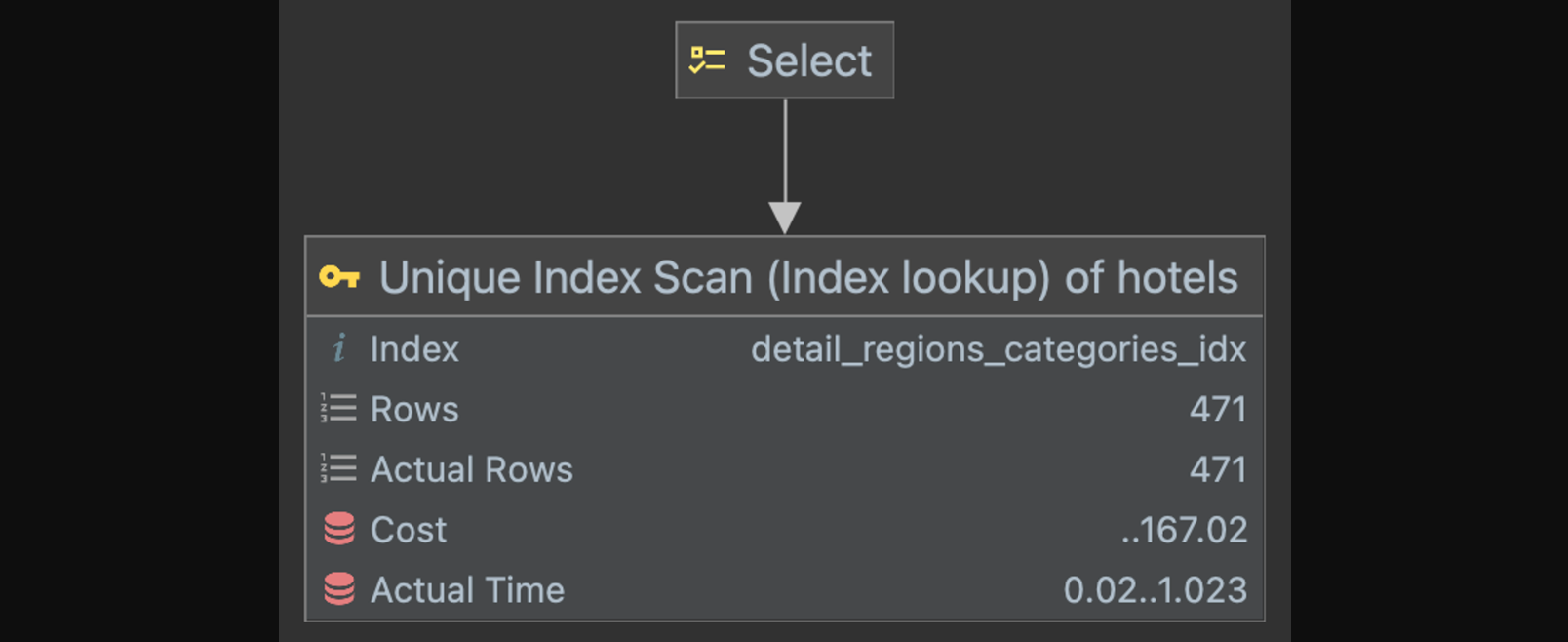
확인해보면 cost가 224에서 167로 상당히 감소한 것을 알 수 있다.
이처럼, 복합 인덱스는 쿼리 성능 향상에 큰 영향을 미치고, 복합 인덱스의 순서 또한 중요하다.
페이징 구현
만약 hotels 테이블에 데이터가 100만건이 있는 상태에서 호텔을 검색하는 쿼리를 실행하면 어떻게 될까? 그렇게 되면 hotels 테이블의 모든 데이터 100만건을 조회하여 가져올 것이다.
하지만, 웹 서비스에서 테이블 전체 데이터를 한번에 요구하는 일은 거의 없다. 이때, 페이징 기법을 사용해서 조회한 결과를 필요한 만큼만 제한할 수 있다.
페이징 기법은 크게 Offset 방식, 커버링 인덱스 방식, 커서 방식 이렇게 세 가지가 있다. 이제 각 페이징 기법을 적용해보고, 장단점을 설명하도록 하겠다.
Offset 방식 페이징
Offset 방식은 가장 기본적인 페이징 기법으로, LIMIT과 OFFSET을 이용하여 페이징을 구현한다.
아래와 같이 Offset 방식을 이용하여 페이징을 구현해보자.
SELECT *
FROM hotels
WHERE detail_region_id = 1
AND category_id = 1
LIMIT 10 OFFSET 0;위 쿼리는 쿼리의 결과를 0번째 부터 10개만 가져오겠다는 쿼리이다. 위 쿼리의 실행 계획을 확인해보자.
- Explain Analyze
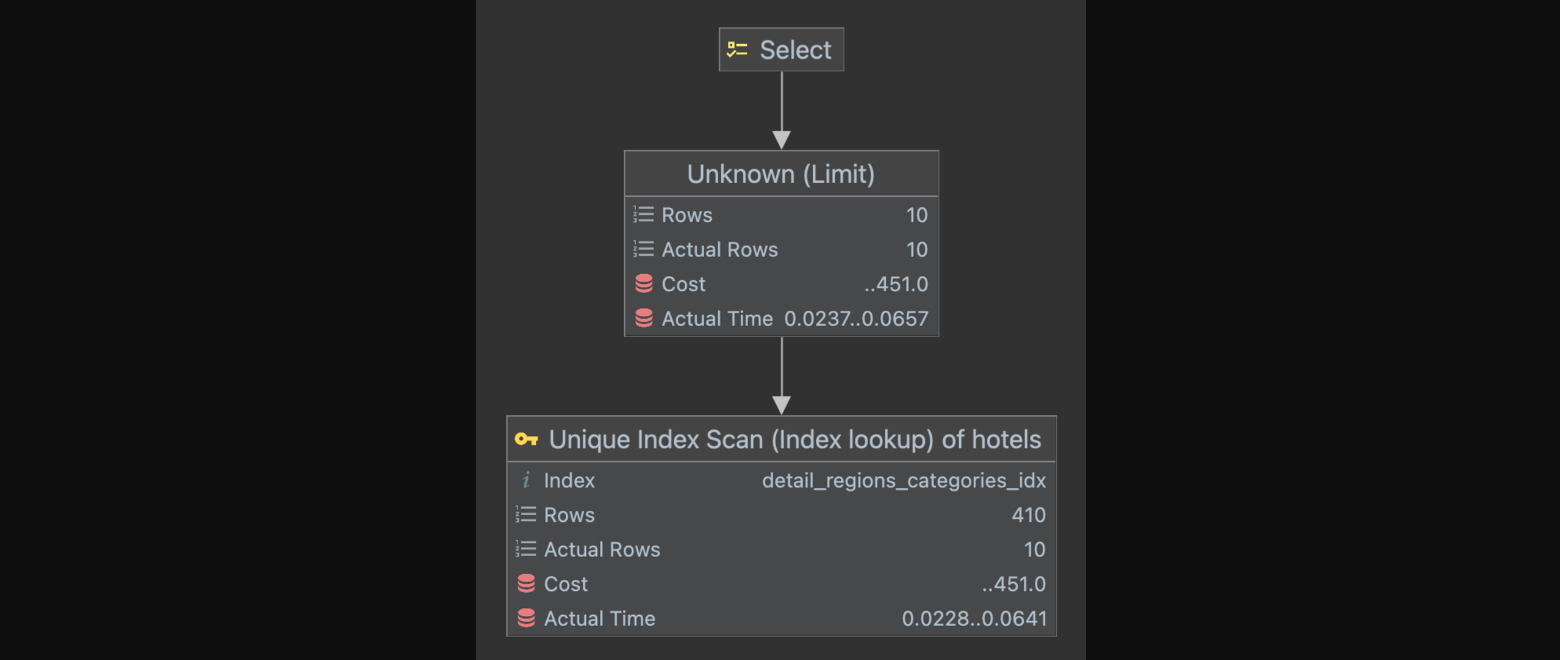
결과를 확인해보면, 실제로 조회하는 row수가 10개인 것을 확인할 수 있다.
하지만, 만약 가장 끝 페이지를 조회해야 한다면 어떻게 될까?
SELECT *
FROM hotels
WHERE detail_region_id = 1
AND category_id = 1
LIMIT 10 OFFSET 400;위 쿼리의 실행 계획을 분석해보자.
- Explain Analyze
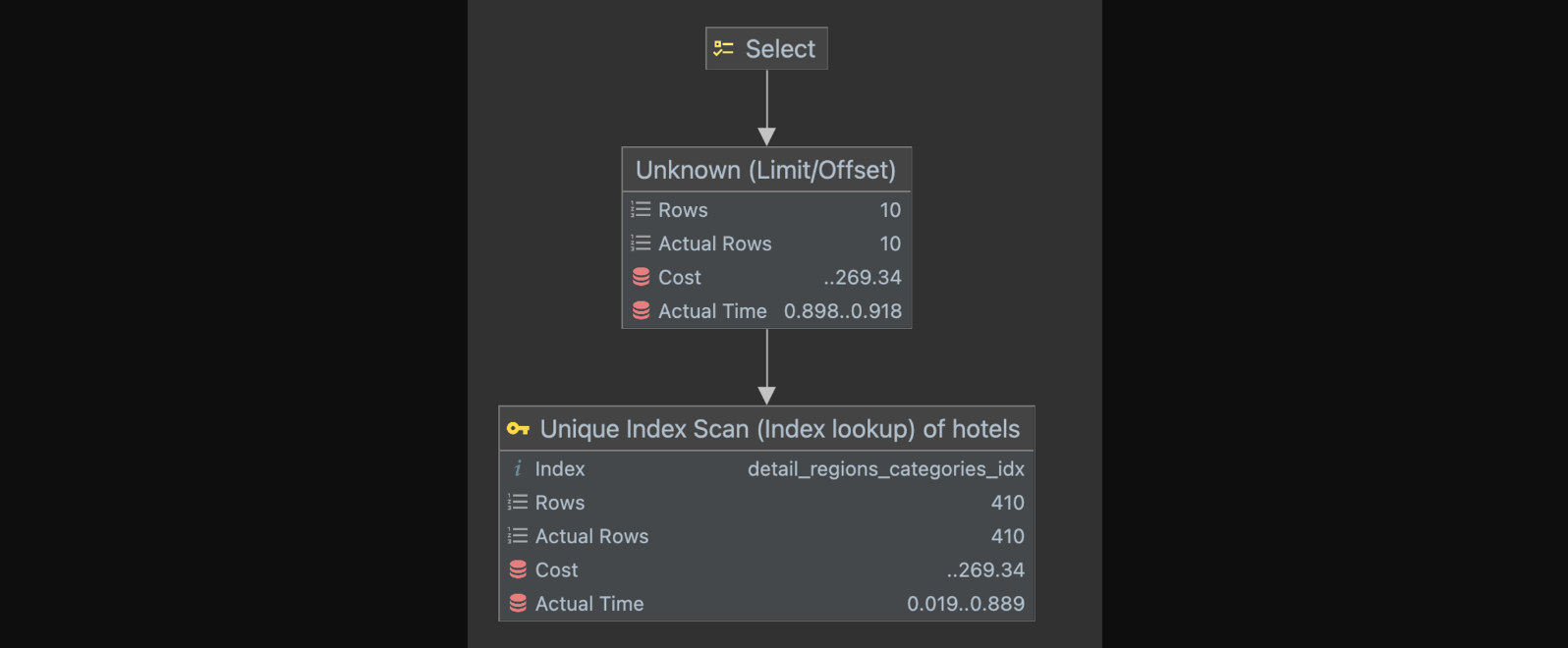
확인해보면 나는 10개의 데이터만 조회하고 싶었지만, 실제로 조회한 row수는 410개임을 볼 수 있다. 즉, 10개의 데이터만 읽고 싶지만 실제로는 모든 데이터를 읽어온 셈이다. 또한, 실행시간이 0.066ms 에서 0.918ms로 매우 크게 증가했다.
이처럼 Offset 페이징 방식은 끝 페이지에 있는 데이터를 읽을 수록 쿼리의 성능이 낮아지는 문제가 있다.
커버링 인덱스 방식 페이징
이번에는 커버링 인덱스 방식으로 이전 방식보다 성능을 개선해보자.
기존 쿼리를 아래와 같이 바꿔보자.
SELECT *
FROM hotels as h
JOIN (SELECT id
FROM hotels as h2
WHERE detail_region_id = 1
AND category_id = 1
LIMIT 10 OFFSET 400) as temp
ON temp.id = h.id;위 쿼리를 설명하면, 인덱스만으로 처리되는(커버링 인덱스) 서브 쿼리를 이용해서 id값들을 얻고, 그 id값들로 데이터들을 찾는다. 이제 위 쿼리의 실행 계획을 살펴보자.
- Explain
id select_type table type key ref rows filtered Extra 1 PRIMARY ALL null null 410 100 null 1 PRIMARY h eq_ref PRIMARY temp_hotel.id 1 100 null 2 DERIVED hotels ref detail_regions_categories_idx const,const 410 100 Using index - Explain Analyze
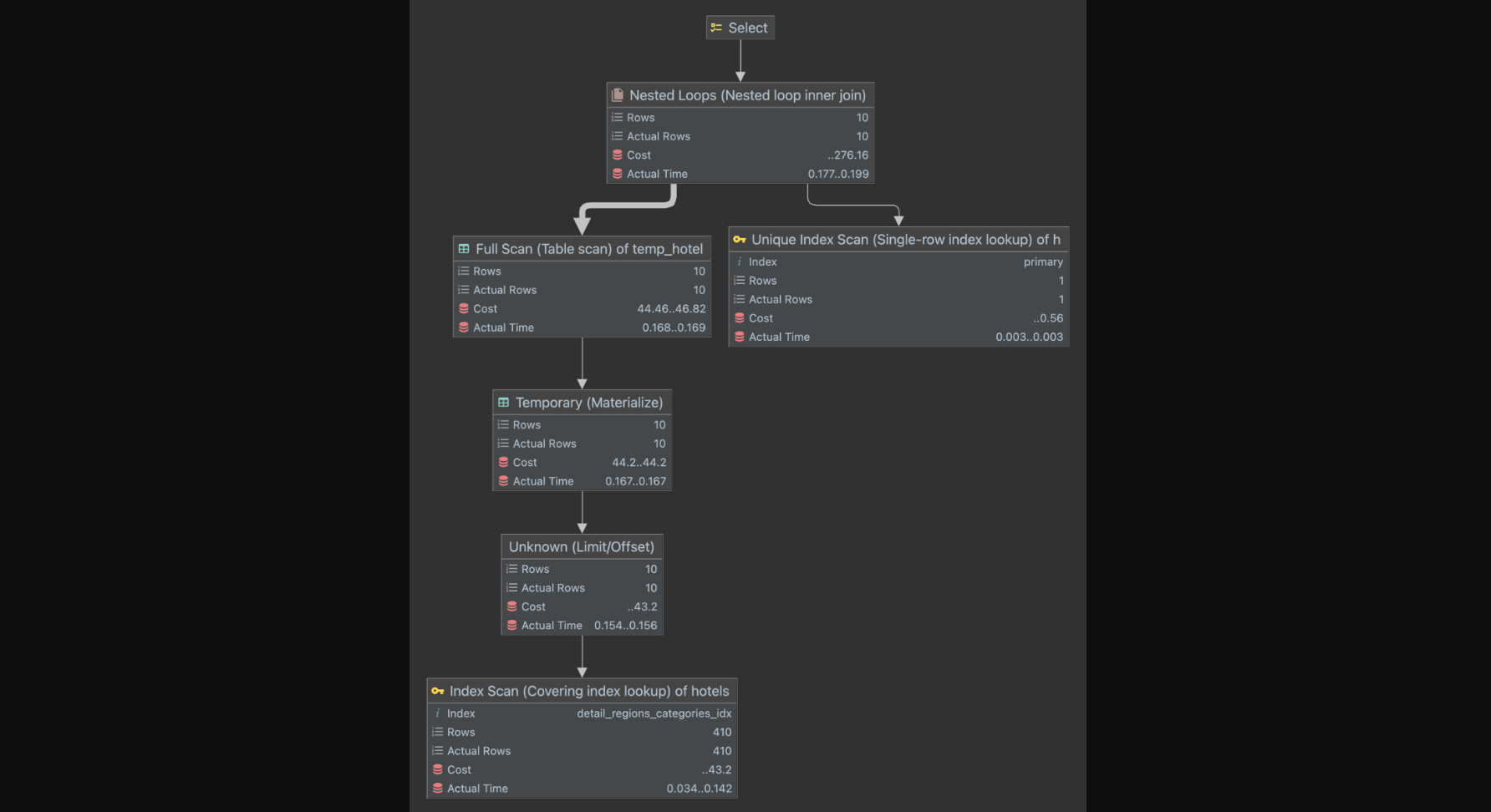
다이어 그램을 기반으로 쿼리를 분석해보면
- 우선
detail_regions_categories_idx인덱스를 이용해서 410개의 데이터를 스캔 후 400번째 부터 10개만 가져오고 나머지는 버린다. (LIMIT 10 OFFSET 400) 그리고 이 과정에서 커버링 인덱스가 적용된다. - 그렇게 가져온 10개의 id를 가지고 loop를 돌며 hotels 테이블에서 해당 id에 해당하는 데이터들을 가져온다.
이렇게 커버링 인덱스 방식 페이징을 적용시켜서 실행 시간을 0.918ms 에서 0.199ms로 많이 감소시켰다.
하지만, 커버링 인덱스 방식 페이징은 아래와 같은 단점이 있다.
- 너무 많은 인덱스가 필요하다.
커서 방식 페이징
만약 UI가 아래와 같거나, 무한 스크롤 방식이라면 어떨까?

위와 같은 경우에는 다음 페이지나 이전 페이지 밖에 없기 때문에 다음에 불러올 데이터의 시작 위치를 알 수 있다.
이렇게 시작 위치를 알 수 있다면, 기존 쿼리를 아래와 같이 바꿔볼 수 있다.
SELECT *
FROM hotels
WHERE detail_region_id = 1
AND category_id = 1
AND id > 192821 #직전 조회 결과의 마지막 id
LIMIT 10;위 쿼리의 실행 계획을 살펴보자.
- Explain
id select_type table type key key_len ref rows filtered Extra 1 SIMPLE hotels index_merge detail_regions_categories_idx,category_id 24,16 null 1 100 Using intersect(detail_regions_categories_idx, category_id); Using where - Explain Analyze
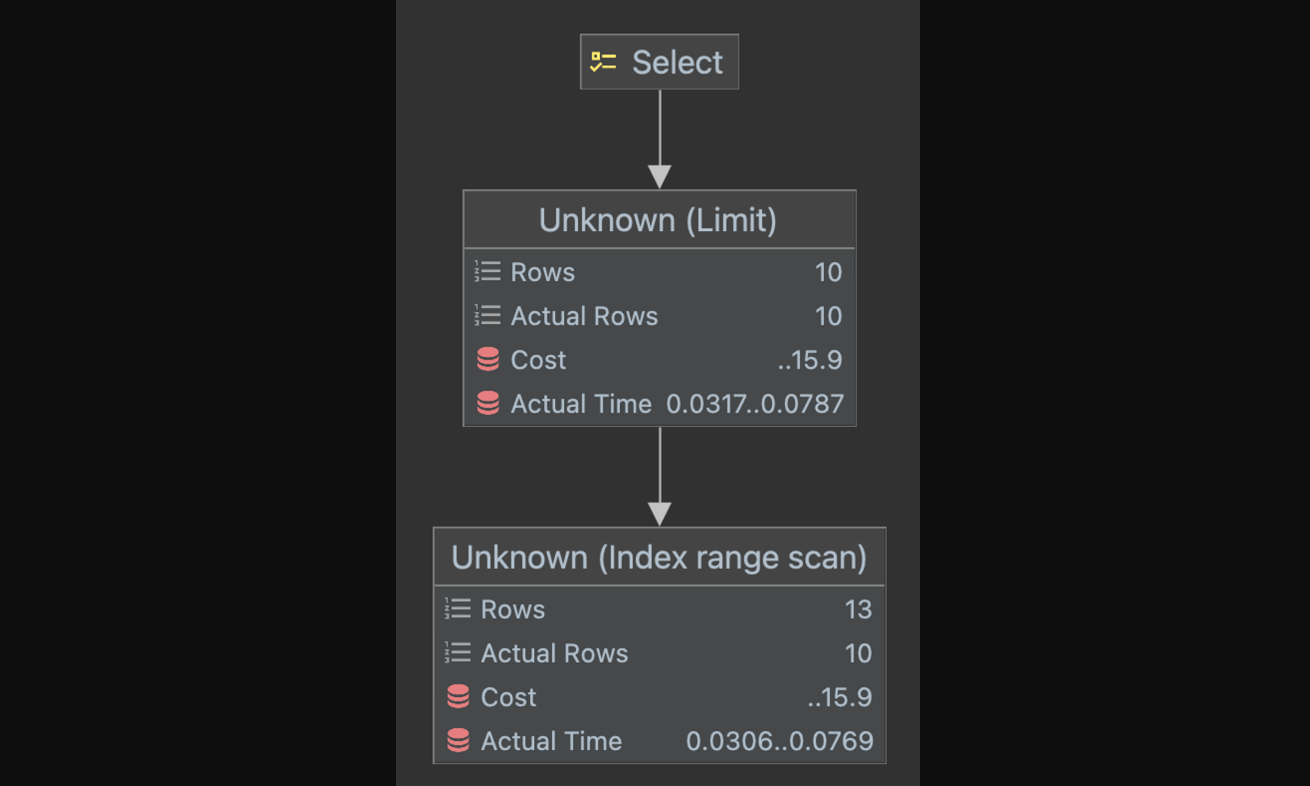
엇.. Cost는 매우 감소했지만, 실행시간은 오히려 증가한 모습이다. 위 결과를 통해 분석해보면 category_id인덱스로 가져온 결과와 detail_regions_categories_idx인덱스로 가져온 결과를 교집합 연산으로 합친다.
정확한 이유는 모르겠지만, 옵티마이저가 잘못된 인덱스를 사용하는 것 같다. 아래와 같이 기존 쿼리에 인덱스 힌트를 붙혀서 detail_regions_categories_idx 인덱스를 사용하도록 수정해보자.
SELECT *
FROM hotels USE INDEX (detail_regions_categories_idx)
WHERE detail_region_id = 1
AND category_id = 1
AND id > 192821 #직전 조회 결과의 마지막 id
LIMIT 10;- Explain
id select_type table type key key_len ref rows filtered Extra 1 SIMPLE hotels range detail_regions_categories_idx 24 null 13 100 Using index condition - Explain Analyze
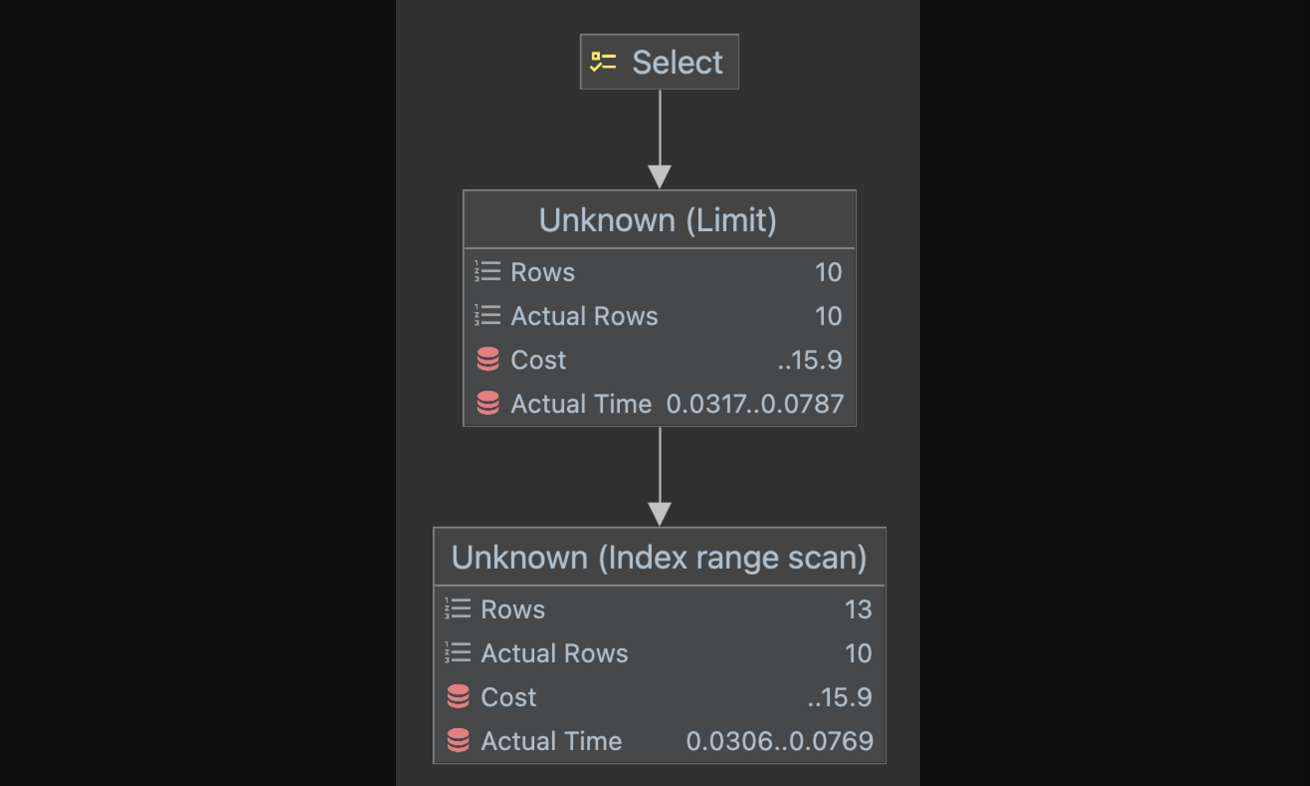
인덱스 힌트를 사용하지 않은 쿼리보다 코스트는 증가하였지만, 실행시간이 확실히 감소하였다. 왜 이전 실행 계획의 코스트가 더 높은지는 더 알아보아야 할 것 같다.
그리고 커버링 인덱스 방식 페이징 보다 실행 시간이 0.199ms에서 0.08ms로 감소하였다.
커서 방식 페이징은 데이터의 수가 많아질 수록 성능 개선의 효과가 훨씬 증가한다. 하지만 이전 데이터의 id를 알아야 사용이 가능하기 때문에 UI를 이에 맞게 변경해야하는 단점이 있다.
페이징 방식 결론
각 서비스와 기능의 요구 사항에 따라 위 페이징 방식들 중 가장 적절한 방식을 선택하면 된다.
내가 구현 중인 호텔 검색 기능의 경우 사용자가 여러 페이지를 건너 뛰어야 하는 경우가 거의 없고, 대부분의 호텔 예약 사이트들이 무한 스크롤 방식을 사용하고 있으므로 커서 방식을 사용하는 것으로 결정하였다.
