
프로젝트 개요
이름: 여기서 놀자!
설명: 호텔을 검색하고 예약할 수 있는 웹 서비스
목적: 대규모의 데이터를 처리하고, 성능을 개선하는 경험을 하는 것
진행 과정
- 요구사항에 맞는 쿼리를 작성
- 쿼리의 실행 계획을 분석하여 문제점을 파악한 뒤 문제에 맞는 적절한 기술을 사용하여 성능을 개선
- 부하테스트를 통하여 목표 성능에 도달했는지 확인
- 목표 달성 실패시 추가 개선 진행, 목표 달성 시 목표 상향
- 설계 및 구현 과정에서 책에서 배운 내용을 적용 및 진행 과정을 글로 기록
프로젝트 성과
-
레코드 500만건 이상, 용량 약 1GB의 대규모 데이터가 들어가있는 MySQL 환경에서 예약이 가능한 호텔을 검색하는 쿼리 작성
-
Explain 쿼리를 이용해 쿼리의 실행 계획을 파악한 뒤 문제 상황에 맞는 적절한 기술을 도입하여 성능을 개선
-
index merge실행 계획을 확인하여 카디널리티가 높은 컬럼을 선행 컬럼으로한 복합 인덱스를 적용, 여러 방식의 페이징 기법을 비교하여 요구사항에 가장 잘 맞는 커서 방식 페이징을 적용 -
변경이 거의 없는
categories,detail_regions의 데이터를hotels에 추가하는 역정규화 작업을 통해 불필요한JOIN연산을 제거 -
WITH문을 사용하여 쿼리의 가독성 향상 및 필터링 조건을 먼저 적용하여 검색 대상을 감소시키는 방식으로 쿼리를 수정
-
-
실행 시간이 튜닝 이전 39498ms → 튜닝 후 22.7ms로 감소하여 성능이 99.942% 향상
- 튜닝 이전 Explain Analyze
-> Group aggregate: min(ar.price) (cost=12787 rows=0) (actual time=30141..39498 rows=242 loops=1) -> Nested loop inner join (cost=12787 rows=0) (actual time=30139..39494 rows=306 loops=1) -> Filter: (h.detail_region_id = 1) (cost=10474 rows=925) (actual time=8.45..9359 rows=410 loops=1) -> Index lookup on h using hotels_ibfk_2 (category_id=1) (cost=10474 rows=66606) (actual time=3.39..9355 rows=33382 loops=1) -> Index lookup on ar using <auto_key0> (hotel_id=h.id) (cost=0.25..2.5 rows=10) (actual time=73.5..73.5 rows=0.746 loops=410) -> Materialize (cost=0..0 rows=0) (actual time=30130..30130 rows=129667 loops=1) -> Filter: (coalesce(max(rc.count),0) <= r.count) (actual time=29907..29946 rows=129667 loops=1) -> Table scan on <temporary> (actual time=29906..29925 rows=131412 loops=1) -> Aggregate using temporary table (actual time=29906..29906 rows=131412 loops=1) -> Nested loop left join (cost=181917 rows=150937) (actual time=1.42..29596 rows=155575 loops=1) -> Filter: ((r.max_people_count >= 3) and (r.price >= 50000) and (r.price <= 200000)) (cost=63424 rows=22874) (actual time=1.01..2104 rows=131412 loops=1) -> Table scan on r (cost=63424 rows=617789) (actual time=0.999..1991 rows=619984 loops=1) -> Filter: (rc.stay_date between '2023-06-22' and '2023-06-25') (cost=4.52 rows=6.6) (actual time=0.206..0.209 rows=0.383 loops=131412) -> Index lookup on rc using reservation_check_ibfk_1 (room_id=r.id) (cost=4.52 rows=6.6) (actual time=0.179..0.205 rows=5.85 loops=131412)
- 튜닝 후 Explain Analyze
-> Limit: 10 row(s) (actual time=22.7..22.7 rows=10 loops=1) -> Sort: h.id, limit input to 10 row(s) per chunk (actual time=22.7..22.7 rows=10 loops=1) -> Table scan on <temporary> (actual time=22.6..22.6 rows=123 loops=1) -> Aggregate using temporary table (actual time=22.6..22.6 rows=123 loops=1) -> Nested loop inner join (cost=85.4 rows=0) (actual time=20.3..21.1 rows=155 loops=1) -> Table scan on ar (cost=2.5..2.5 rows=0) (actual time=20.2..20.3 rows=155 loops=1) -> Materialize CTE available_rooms (cost=0..0 rows=0) (actual time=20.2..20.2 rows=155 loops=1) -> Filter: (coalesce(max(rc.count),0) <= r.count) (actual time=20.1..20.2 rows=155 loops=1) -> Table scan on <temporary> (actual time=20.1..20.2 rows=157 loops=1) -> Aggregate using temporary table (actual time=20.1..20.1 rows=157 loops=1) -> Nested loop left join (cost=597 rows=149) (actual time=0.255..19.8 rows=187 loops=1) -> Nested loop inner join (cost=481 rows=22.5) (actual time=0.144..8.22 rows=157 loops=1) -> Filter: ((h.category_id = 1) and (h.detail_region_id = 1) and (h.id > 100000)) (cost=40.8 rows=196) (actual time=0.0528..0.375 rows=196 loops=1) -> Covering index range scan on h using detail_regions_categories_idx over (detail_region_id = 1 AND category_id = 1 AND 100000 < id) (cost=40.8 rows=196) (actual time=0.0499..0.295 rows=196 loops=1) -> Filter: ((r.max_people_count >= 3) and (r.price >= 50000) and (r.price <= 200000)) (cost=1.94 rows=0.115) (actual time=0.0386..0.0397 rows=0.801 loops=196) -> Index lookup on r using hotel_id (hotel_id=h.id) (cost=1.94 rows=3.11) (actual time=0.037..0.0388 rows=3.12 loops=196) -> Filter: (rc.stay_date between '2023-06-22' and '2023-06-25') (cost=4.5 rows=6.6) (actual time=0.072..0.0731 rows=0.382 loops=157) -> Index lookup on rc using reservation_check_ibfk_1 (room_id=r.id) (cost=4.5 rows=6.6) (actual time=0.0613..0.0688 rows=5.86 loops=157) -> Single-row index lookup on h using PRIMARY (id=ar.hotel_id) (cost=0.561 rows=1) (actual time=0.00508..0.00511 rows=1 loops=155)
- 튜닝 이전 Explain Analyze
-
프로시저를 활용하여 실제 데이터와 유사한 더미 데이터를 삽입
- 관련 글 링크(더미 데이터 넣기)
- 호텔 테이블의 데이터 예시
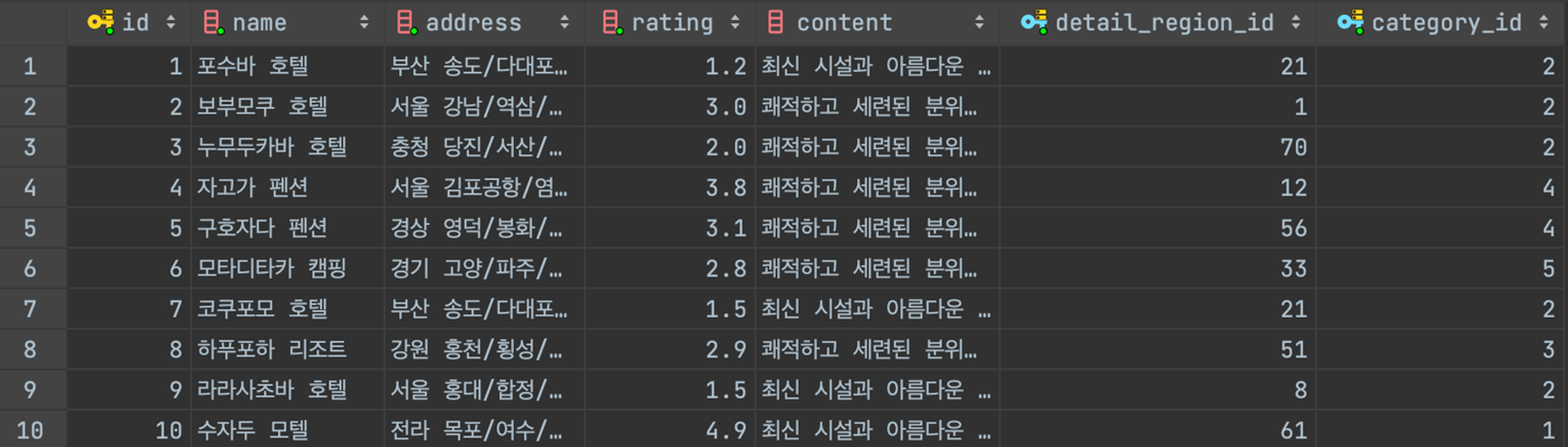
-
튜닝 이전 쿼리
SELECT h.id, h.name AS hotel_name, MIN(ar.price) AS min_price, h.rating, h.address, dr.name, c.name FROM hotels h IGNORE INDEX (detail_regions_categories_idx) JOIN ( SELECT r.id, r.hotel_id, r.price FROM rooms r LEFT OUTER JOIN reservation_check rc ON r.id = rc.room_id AND rc.stay_date BETWEEN {숙박_시작_날짜} AND {숙박_종료_날짜} WHERE r.max_people_count >= {숙박_인원} AND r.price >= {최저_가격} AND r.price <= {최대_가격} GROUP BY r.id, r.count HAVING COALESCE(MAX(rc.count), 0) <= r.count ) AS ar ON h.id = ar.hotel_id JOIN categories AS c ON c.id = h.category_id JOIN detail_regions AS dr ON h.detail_region_id = dr.id WHERE h.detail_region_id = {상세_지역_id} AND h.category_id = {카테고리_id} GROUP BY h.id ORDER BY h.id; -
튜닝 이후 쿼리
WITH available_rooms AS ( SELECT r.id, r.hotel_id, r.price FROM rooms r JOIN hotels h ON r.hotel_id = h.id LEFT OUTER JOIN reservation_check rc ON r.id = rc.room_id AND rc.stay_date BETWEEN {숙박_시작_날짜} AND {숙박_종료_날짜} WHERE r.max_people_count >= {숙박_인원} AND r.price >= {최저_가격} AND r.price <= {최대_가격} AND h.detail_region_id = {상세_지역_id} AND h.category_id = {카테고리_id} AND h.id > {직전에_조회한_호텔의_id} GROUP BY r.id, r.count HAVING COALESCE(MAX(rc.count), 0) <= r.count ) SELECT h.id, h.name AS hotel_name, MIN(ar.price) AS min_price, h.rating, h.address, h.detail_region_name, h.category_name FROM hotels h JOIN available_rooms ar ON h.id = ar.hotel_id GROUP BY h.id ORDER BY h.id LIMIT 10;
프로젝트 진행 배경
“내가 백엔드 개발자로 취업을 하려면 무엇을 해야할까?”라는 고민을 최근에 많이 하였다. 내가 내린 결론은 기업이 요구하는 사항을 파악하고 이에 맞는 공부를 해야한다는 것이다. 나는 여러 기업들의 채용공고들을 확인하던 중 “성능 개선”, “대규모 데이터 처리”와 같은 키워드를 볼 수 있었다.
주니어 개발자가 성능 개선이나 대규모 데이터 처리 경험을 할 수 있는 방법이 무엇이 있을까 고민하다가, DB에 더미 데이터를 넣어서 대규모의 데이터를 처리하는 경험을 해보고, 쿼리 튜닝을 통해 저하되는 개선해보며 비슷한 경험을 할 수 있지 않을까? 라는 생각이 들었다.
그리하여 “여기서 놀자”라는 사이드 프로젝트를 진행하기로 계획하였고, 프로젝트를 진행하며 경험한 내용을 글로 정리하려고 한다.
기능 요구사항 - 호텔 검색
지역, 카테고리, 숙박 날짜, 숙박 인원 등을 통해 조건에 맞는 호텔을 검색하는 기능
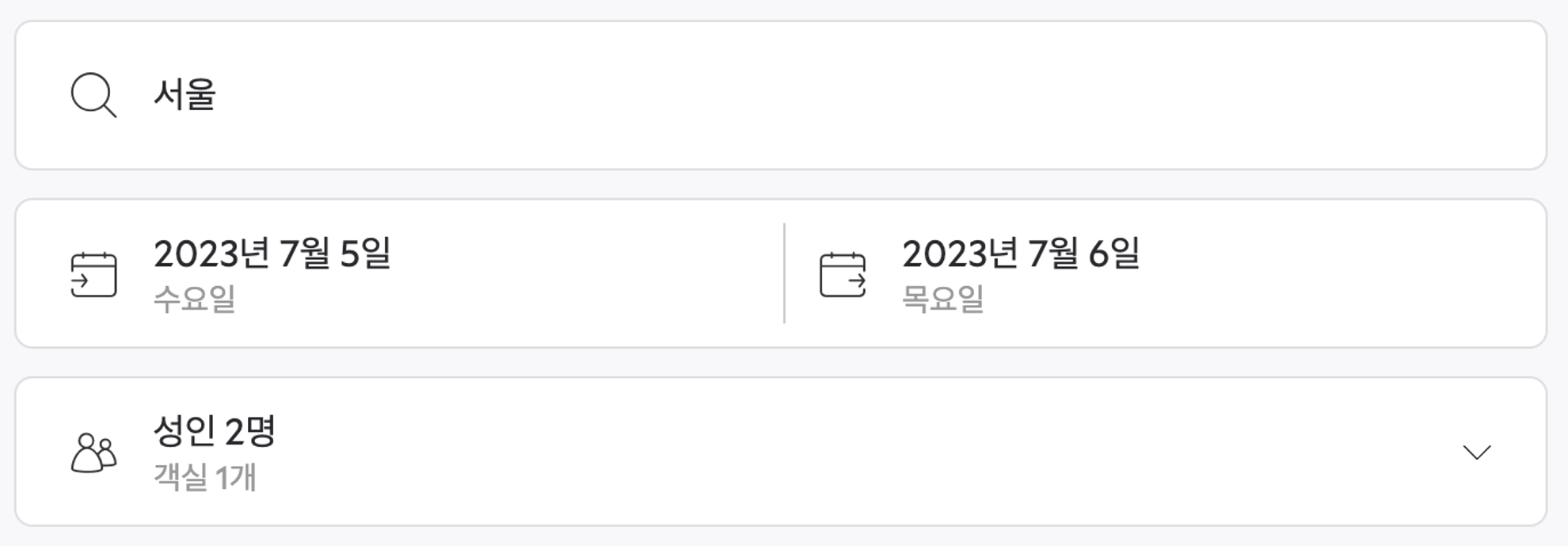
[세부사항]
- 카테고리, 상세 지역 등으로 필터링이 가능하다.
- 페이징을 지원한다.
- 호텔 이름, 평점, 가격, 주소, 지역, 카테고리 등 필요한 정보를 보여준다.
- 지역으로 필터링이 가능하다.
- 설정한 인원이 묵을 수 있는 객실이 있는 호텔들을 우선적으로 노출한다.
- 각 호텔에서 예약 가능한 가장 저렴한 객실의 가격을 표시한다.
- 지정한 날짜에 예약이 가능한 객실이 있는 호텔들을 우선적으로 노출한다.
- 가격 범위를 지정하여 검색이 가능하다.
MySQL 관련 정리글
💡 해당 프로젝트를 진행하기 전 MySQL에 대해 공부한 내용을 정리한 글 목록입니다.
