4.4.1 관계형 데이터베이스
관계형 데이터베이스( Relational DataBase )란
관계형 데이터베이스는 1970년대에 IBM에서 일하던 에드거 F. 커드가 제안한 데이터베이스 모델이다.
관계형 데이터 베이스는 데이터를 테이블 형태로 저장한다.
쉽게 생각하면 엑셀 표에 데이터를 저장하는 것과 동일하다고 보면된다.
실제로 각 데이터 항목들은 행(row)에 저장되고, 항목의 속성은 열(column)이라고 표현한다. 열은 항목의 속성인 만큼 입력되는 데이터의 유형이 정해진다.
용어 정리
- 열(column) : 필드(field) 라고도 부르며, 항목의 속성(명칭)을 나타낸다. 필드 마다 각각 정수, 텍스트 같은 데이터 유형을 정할 수 있다.
- 행(row) : 레코드(record) 라고도 부르며, 각 데이터 항목을 저장한다.
- 스키마(schema) : 필드는 데이터 유형뿐만 아니라 제약사항도 지정할 수 있는데 이러한 제약사항을 스키마라고 부른다. 예를들어 필드는 중복 값을 해당 행에 저장할 수 없다거나, 반드시 값을 가져야 한다(not null)는 조건 등을 걸 수 있다.
관계형 데이터베이스에서의 관계
관계형 데이터베이스는 왜 관계라는 이름이 붙여졌을까?
결론부터 말하자면 각 테이블의 행과 행이 연결되는 관계를 맺을 수 있기 때문이다.
테이블 간의 관계는 일 대 일(1:1), 일 대 다(1:N), 다 대 다(N:N) 의 관계가 있다.
우리는 하나의 테이블에 필요한 모든 필드를 넣고 모든 데이터 항목을 저장할 수 있다. 하지만 이렇게하면 데이터들이 중복해서 저장되는 상황이 발생할 수 있어 다음 그림 테이블과 같이 비효율적이다.
< 하나의 테이블에 모든 데이터를 넣는 경우 >
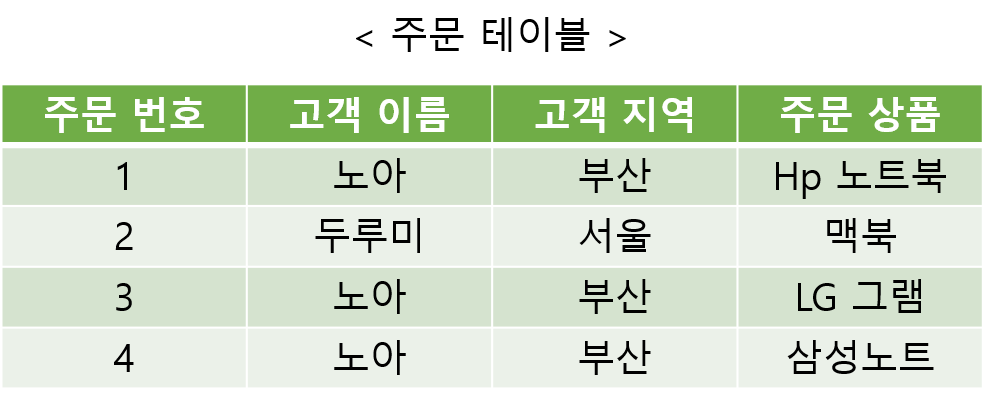
그림과 같이 고객의 상품 주문을 저장하는 테이블이 있다고 가정하면 특정 고객이 여러 상품을 구매하는 경우 고객 이름과 고객 지역 데이터가 계속 해서 중복된다. 얼핏보기에는 별 문제 없어보이지만 만약에 고객의 지역이 변경된다고 생각해보자.
그림은 데이터가 3개 뿐이지만 만약 수십, 수백만 그 이상의 데이터라면 쉬운일이 아니다.
그래서 관계형 데이터베이스 모델에서는 다음 그림과 같이 테이블을 분리하여 행과 행을 연결할 수 있다.
< 테이블을 분리시키고 각 테이블 간 행과 행 사이에 관계를 형성하는 경우 >

그림과 같이 테이블 간의 관계는 기본 키(primary key) 와 외래 키(foreign key) 라는 개념을 사용하여 맺어질 수 있다.
기본 키는 고유한 ID 필드로 그림에서는 고객 번호 필드이다. 이 필드는 각 행이 중복된 값을 가질 수 없다.
외래 키는 기본 키를 참조하는 필드로 그림에서는 주문 테이블의 고객 번호 필드이고 각 테이블의 행을 연결시켜주는 역할을 한다.
이렇게 테이블을 분리하고 관계를 형성해 데이터를 효율적으로 관리할 수 있다.
( 테이블을 분리하고 중복 데이터를 제거하는 과정을 정규화 라고 한다.)
SQL(Structured Query Language) 이란
관계형 데이터베이스에서 주요한 특징 중 하나는 SQL이라는 구조화 질의어를 사용한다는 것이다. SQL은 RDBMS에서 사용하는 프로그래밍 언어라고 보면 된다. SQL을 통해 RDBMS에서 데이터를 검색하고, 추가하고, 업데이트하고, 삭제하는 작업 등 데이터를 관리한다.
SQL의 종류로는 데이터 정의 언어, 데이터 조작 언어, 데이터 제어 언어 가 있는데 결국 RDBMS를 다루려면 모두 알아야하기 때문에 종류가 나뉘어 진다라는 정도만 알면 될 것 같다.
트랜잭션(transaction)이란
트랜잭션은 데이터베이스 관리시스템(DBMS)에서 하나의 작업의 단위이다.
데이터베이스는 여러 사람들이 데이터를 공유하고 사용할 목적으로 사용된다. 그렇기 때문에 다수의 사람들이 동시에 사용하더라도 데이터에 문제가 없어야한다. 트랜잭션은 모든 명령문을 완벽하게 처리하거나, 하나의 명령문이라도 문제가 발생하면 모든 명령문을 수행하지 않고 데이터를 보존하는 기능을 하고 해야한다.
트랜잭션의 예시에 가장 적합한게 은행이라고 볼 수 있다. 예를들어 A계좌에 1000원이 있다고 하자. 이때 서로 다른 2대의 ATM 기기에서 동시에 A계좌의 1000원을 인출하려고 한다. 정말 거의 동시에 인출을 시도했을 때 트랜잭션이 제대로 기능하지 않아 두명 다 각각 1000원씩 인출해 간다면 은행은 아마 파산할 것이다. 그래서 은행은 두 트랜잭션을 모두 수행하지 않거나, 0.000001 초라도 빠른 사람의 요청을 수행하고 나머지 사람에게는 지급부족으로 요청을 거절해야 한다.
이러한 트랜잭션의 기능을 제대로 수행하기 위해서는 네 가지 특성을 만족해야하는데 ACID 특성이라고 부른다.
- 원자성 (Atomicity) : 원자성이란 트랜잭션이 수행하는 연산들을 모두 정상적으로 처리하거나 모두 처리하지 않아야 한다는 all-or-nothing 방식을 의미한다.
- 일관성 (Consistency) : 일관성은 트랜잭션이 성공적으로 수행된 이후에도 데이터베이스의 데이터는 일관된 상태를 유지해야 한다는 의미이다.
- 격리성 (Isolation) : 격리성은 하나의 트랜잭션이 완료될 때까지 다른 트랜잭션이 간섭하지 못하도록 하여 각각의 트랜잭션이 독립적으로 수행되어야 한다는 의미이다.
- 지속성 (Durability) : 지속성은 트랜잭션이 성공적으로 완료된 이후에 데이터베이스의 데이터들이 영구적으로 보존되어야 한다는 의미이다.
4.4.2 NoSQL 데이터베이스
NoSQL이란?
NoSQL은 초기엔 주로 탈 RDBMS를 의미하는 표준화된 구조적 질의 언어가 없는 데이터베이스(No SQL) 또는 관계를 갖지 않는 데이터베이스로 정의하였지만 현재는 앞의 두 가지 의미 외에도 SQL뿐만 아니라 여러 가지 기능을 제공(Not Only SQL)한다는 의미로 일반화되었습니다.
NoSQL DB 종류
NoSQL 데이터베이스의 종류는 키-값 데이터베이스, 도큐먼트 데이터베이스, 칼럼 패밀리 데이터베이스, 그래프 데이터베이스로 나뉩니다.
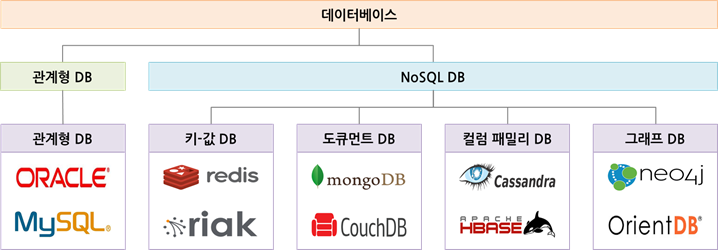
- 키-값 데이터베이스 : 키와 값으로 구성된 배열구조의 데이터베이스로 NoSQL 데이터베이스 중 가장 단순한 구조입니다.
- 도큐먼트 데이터베이스 : 필드와 값의 형태로 구성된 데이터를 JSON 포맷으로 관리하는 데이터베이스로 NoSQL 데이터베이스 중 가장 인기가 높습니다.
- 칼럼 패밀리 데이터베이스 : 칼럼과 로우로 구성된 데이터베이스로 칼럼은 이름과 값으로 구성되고 로우는 각기 다른 칼럼으로 구성이 가능합니다.
- 그래프 데이터베이스 : 노드와 관계로 구성된 데이터베이스로 근접한 객체를 모델링할 목적으로 설계되었습니다.
NoSQL DB 특징
- 유연성 : 스키마 선언 없이 필드의 추가 및 삭제가 자유로운 Schema-less 구조입니다.
- 확장성 : 스케일 아웃에 의한 서버 확장이 용이합니다.
- 고성능 : 대용량 데이터를 처리하는 성능이 뛰어납니다.
- 가용성 : 여러 대의 백업 서버 구성이 가능하여 장애 발생 시에도 무중단 서비스가 가능합니다.
[참고링크]
