자료 구조는 크게 선형 자료 구조와 비선형 자료 구조로 나뉜다.
- 선형 자료 구조: 연결 리스트, 배열(선형 리스트), 스택, 큐, 벡터 등.
- 비선형 자료 구조: 그래프, 트리, 해시 테이블, 힙, 맵, 셋, 우선순위 큐 등.
비선형 자료 구조 (Non-Linear Data Structures)
- 비선형 자료 구조란 데이터 요소들 간에 계층적인 관계가 없는 자료 구조를 의미한다.
- 데이터 요소들이 일렬로 연결되어 있지 않으며, 자료 순서나 관계가 복잡한 구조로 각 요소가 다른 요소와 관련성을 갖는 경우가 많다.
- 비선형 자료 구조는 선형 자료 구조와 대조되며, 선형 자료 구조는 요소들이 일렬로 나열되어 있는 구조를 가진다.
1. 그래프 (Graph)
- 그래프는 다양한 형태의 객체 간 연결 관계를 표현하는 데 사용된다. 각종 네트워크(소셜/컴퓨터 네트워크), 도로망 등을 모델링하는 데 유용하다.
- 그래프는 정점과 간선으로 이루어진 자료 구조이다.
- 어떠한 곳에서 어떠한 곳으로 무언가를 통해 간다고 했을 때 '어떠한 곳'은
정점(vertax)이 되고, '무언가'는간선(edge)이 된다.
1-1. 그래프의 구성 요소 (정점, 간선, 가중치)
- 정점 (Vertax / Node)
- 정점(또는 노드)은 객체나 개체를 나타낸다.
- 예시로는 소셜 네트워크에서 각 사용자, 도로망에서 각 교차로, 컴퓨터 네트워크에서 각 컴퓨터는 정점으로 표현될 수 있다. 또한, A라는 사람이 B라는 사람이 있는 곳을 향해 간다고 했을 때, A라는 사람과 B라는 사람은 하나의 정점이고, B로 향하는 길은 간선이 된다.
- 간선 (Edge)
- 간선(엣지)은 정점(노드)들을 연결하는 선으로, 그래프 내의 두 정점 간의 관계를 나타낸다.
- 두 정점 간의 관계는 양방향 혹은 단방향이다.
- 가중치 (Weight)
- 가중 그래프에서 간선은 가중치를 가질 수 있다.
- 가중치는 간선과 정점 사이에 드는 비용을 의미한다.
- 예시로는 1번 노드(정점)에서 2번 노드(정점)까지 가는 비용(거리)가 1칸이라면, 1번 노드에 2번 노드까지의 가중치가 1칸이라는 의미이다.
- 가중 그래프는 실제 세계의 다양한 상황을 모델링하는 데 유용한데, 최단 경로 문제, 네트워크 흐름 최적화, 스패닝 트리 등의 다양한 문제에 응용된다.
1-2. 그래프의 종류
- 무방향 그래프(Undirected Graph)
- 간선에 방향이 없는 그래프로, 간선은 두 정점을 양방향으로 연결한다.
- 사용 예시
- 소셜 네트워크 그래프: 여러 사용자 간의 친구 관계를 표현할 때, 사용자를 정점으로, 친구 관계를 무방향 간선으로 나타낼 수 있다. 간선의 방향성이 없으며 친구 관계는 양방향이다.
- 도로 네트워크: 도로와 교차로를 정점으로 나타내고, 도로를 무방향 간선으로 표현한다. 차량은 양방향으로 이동할 수 있으므로 간선의 방향성이 없다.
- 방향 그래프 (Directed Graph / Digraph)
- 간선에 방향이 있는 그래프로, 간선은 한 정점에서 다른 정점으로 방향을 가지며, 단방향으로 이동한다.
- 사용 예시
- 웹 페이지 링크 그래프: 웹 페이지를 정점으로 나타내고, 하나의 웹 페이지에서 다른 웹 페이지로의 하이퍼링크를 방향 간선으로 표현한다. 이러한 방식으로 웹 검색 엔진은 웹 페이지의 중요성을 계산하고 검색 결과를 반환한다.
- 전자 메일 통신 그래프: 사용자 간의 이메일 통신을 나타내는 그래프에서, 이메일 메시지는 보낸 사람에서 받는 사람으로의 방향 간선으로 표현된다. 각 이메일은 단방향 통신을 나타낸다.
- 가중 그래프 (Weighted Graph)
- 간선에 가중치가 할당된 그래프로, 간선마다 추가 정보(가중치)가 포함된다.
- 사용 예시
- 도시 간 비행 노선 그래프: 여러 도시를 정점으로 나타내고, 도시 간의 항공 노선을 가중치가 있는 간선으로 표현한다. 가중치는 비행 거리나 비용을 나타내어 최소 비용 경로를 찾는 데 사용된다.
- 소셜 네트워크 친밀도 그래프: 사용자 간의 친밀도를 나타내는 그래프에서, 간선의 가중치는 두 사용자 사이의 친밀도 또는 상호 작용의 정도를 나타낸다. 이를 통해 친밀한 관계를 분석하거나 추천 시스템을 개발할 수 있다.
2. 트리 (Tree)
- 트리는 계층적 자료 구조로서, 정점(노드)과 간선(edge)으로 이루어져 있다.
- 노드(Node)들이 연결된 방식을 나타내는 자료 구조로, 트리는 하나의 루트 노드(root node)에서 시작하여 여러 개의 자식 노드(child node)들로 확장되는 구조를 갖는다.
- 각 노드는 부모 노드와 자식 노드 사이의 관계를 가지며, 이러한 관계는 계층적인 구조를 형성한다.
- 루트 노드, 내부 노드, 리프 노드 등으로 구성된다.
- 트리로 이루어진 집합을
숲이라고 한다.
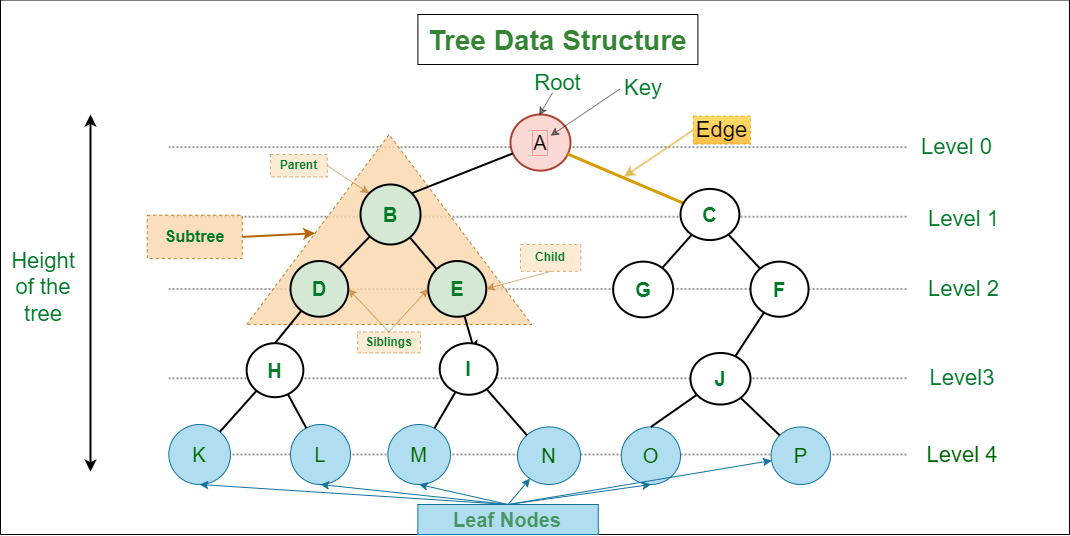
!https://velog.velcdn.com/images/jiyaho/post/63479e15-c5ef-4c38-8e79-6aae8315219b/image.png
{kind=link}
이미지 출처:
https://www.geeksforgeeks.org/introduction-to-tree-data-structure-and-algorithm-tutorials/
2-1. 트리의 구성
루트 노드(Root Node): 트리에서 최상위에 있는 노드.내부 노드(Internal Node): Leaf Node가 아닌 노드.리프 노드(Leaf Node): 자식이 없는 노드. '잎 노드', '단말 노드', '말단 노드'라고도 부른다.부모 노드(Parent Node): 어떤 노드보다 위에 있는 노드.자식 노드(Child Node): 어떤 노드보다 아래에 있는 노드.형제 노드(Sibling Node): 같은 부모를 가지는 노드.간선(Edge): 노드를 연결하는 선 ('Link' 혹은 'Branch'라고도 한다.)
2-2. 트리 관련 용어 (트리의 높이와 레벨 등)
크기(size): 자신을 포함한 모든 자손 노드의 개수깊이(depth): 루트 노드에서 특정 노드까지 최단 거리로 도달하기 위해 거쳐야 하는 간선의 수레벨(level): 트리의 레벨은 주어지는 문제마다 조금씪 다르지만 보통 깊이와 같은 의미를 지닌다. 트리의 특정 깊이(레벨)를 가지는 노드의 집합이다.서브트리(subtree): 트리 내의 하위 집합(부분 집합)으로, 트리 내의 어떤 노드와 그 노드의 모든 자손 노드로 이루어진 부분 트리를 말한다.차수(degree): 하위 트리의 개수 / 간선 수 = 각 노드가 지닌 가지의 수트리의 차수(degree of tree): 트리의 최대 차수트리의 높이(height of tree): 루트 노드에서 가장 멀리 있는 리프 노드까지의 거리- 간선 수 = 노드 수 - 1
2-3. 트리의 종류 (이진 트리, 이진 탐색 트리, AVL 트리, 레드 블랙 트리)
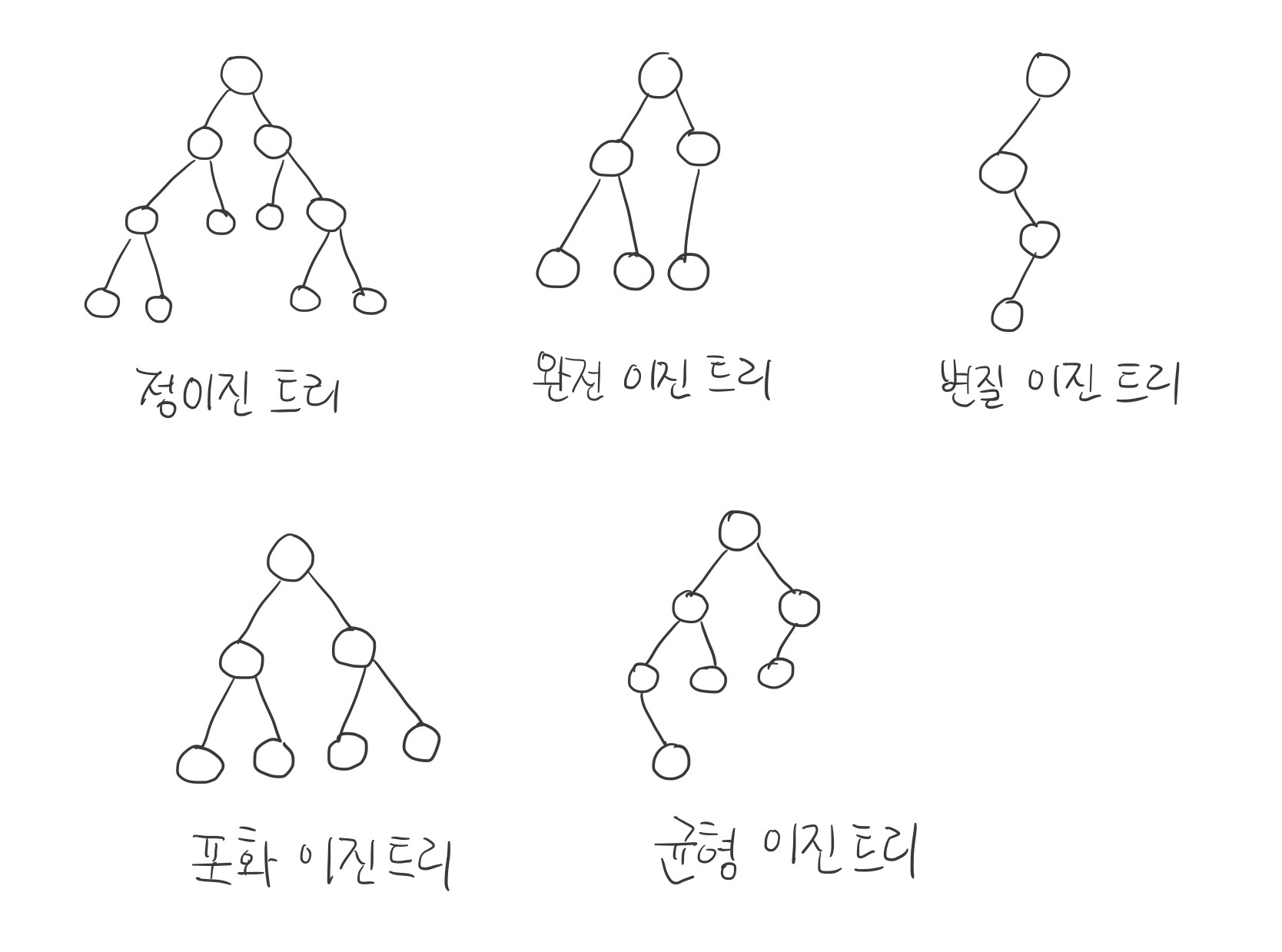
🌲 이진 트리 (Binary Tree): 자식의 노드 수가 2개 이하인 트리이다.
정이진 트리(full binary tree): 자식 노드가 0 또는 2개인 이진 트리.완전 이진 트리(complete binary tree): 왼쪽에서부터 채워져 있는 이진 트리. 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽부터 채워져 있다.변질 이진 트리(degenerate binary tree): 자식 노드가 하나밖에 없는 이진 트리.포화 이진 트리(perfect binary tree): 모든 노드가 꽉 차 있는 이진 트리.균형 이진 트리(balanced binary tree): 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리. map, set을 구성하는 레드 블랙 트리는 균형 이진 트리 중 하나이다.
!https://velog.velcdn.com/images/jiyaho/post/3fa8ebb1-573f-4ef2-a6f6-1f331bbecd67/image.jpg
{kind=link}
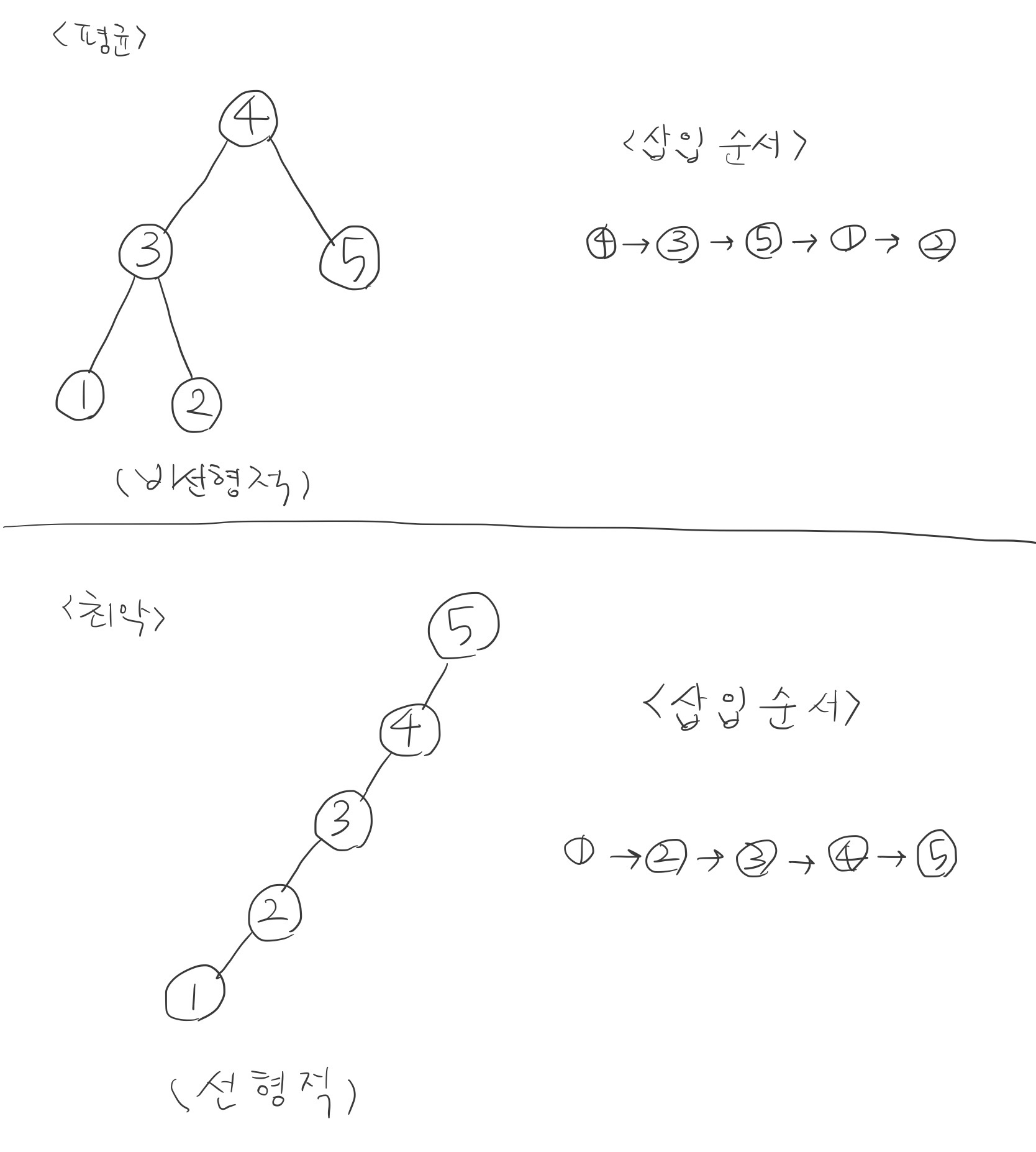
🌲 이진 탐색 트리 (BST, Binary Search Tree)
- 노드의 오른쪽 하위 트리에는 '노드 값보다 큰 값'이 있는 노드만 포함되고, 왼쪽 하위 트리에는 '노드 값보다 작은 값'이 들어 있는 트리를 말한다.
- 검색을 하기에 용이하다.
- 시간 복잡도: 평균적으로
O(log n)이 걸린다. 최악의 경우O(n)이 걸린다. (삽입 순서에 따라 선형적일 수 있기 때문에.)
!https://velog.velcdn.com/images/jiyaho/post/92baadf0-d25d-4051-b7e6-aae1fd11ea3c/image.jpg
{kind=link}
🌲 AVL 트리 (Adelson-Velsky and Landis Tree)
- AVL 트리는 위에서 설명한 최악의 경우 선형적인 트리가 되는 것을 방지하고 항상 균형을 잡는 이진 탐색 트리, 즉 자가 균형 이진 탐색 트리(self-balancing binary search tree)이다.
- 두 자식 서브트리의 높이는 항상 최대 1만큼 차이 난다는 특징이 있다.
- 시간 복잡도: 탐색, 삽입, 삭제 모두
O(log n)이다. (n: 노드의 개수) - 삽입, 삭제를 할 때마다 균형이 안 맞는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로
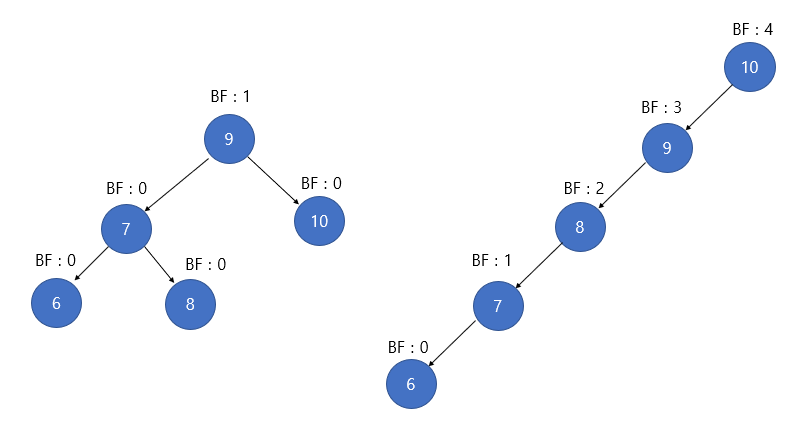
회전(rotation)시키며 균형을 잡는다. - AVL 트리에서 균형이 무너졌는지 판단을 위해
Balance Factor(BF)를 활용한다.BF(K) = K의 왼쪽 서브트리의 높이 - K의 오른쪽 서브트리의 높이
- AVL 트리는 모든 Node의 BF가 -1, 0, 1 중 하나여야 한다. 이를 벗어나면 균형이 깨졌다는 것을 의미하고, 회전(rotation)을 하게 된다.
!https://velog.velcdn.com/images/jiyaho/post/ec39146b-8b3e-4ea6-8c33-144a5a4d9a8c/image.png
{kind=link}
🌲 레드 블랙 트리 (Red-Black Tree)
- 레드 블랙 트리는 자가 균형 이진 탐색 트리(self-balancing binary search tree)이다.
- 각 노드는 빨간색 또는 검은색의 색상을 나타내는 추가 비트를 저장하며, 삽입 및 삭제 중 트리가 균형을 유지하도록 하는 데 사용된다.
- "모든 리프 노드와 루트 노드는 블랙이고, 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다." 등의 규칙을 기반으로 균형을 잡는 트리이다.
- 시간 복잡도: 탐색, 삽입, 삭제 모두 O(log n)이다.
!https://velog.velcdn.com/images/jiyaho/post/a775abc3-0caf-4b04-9b82-0b096fd08484/image.svg
{kind=link}
- cf.
NIL: 트리 구조를 나타낼 때, 어떤 노드는 자식(child)를 하나만 가질 수 있고, 리프 노드는 데이터를 담을 수 있다. 레드-블랙 트리도 이와 같은 방법으로 나타내 볼 수 있지만, 그런 표현 방식으로는 레드-블랙 트리의 특성이 변하고, 알고리즘과 상충될 수 있다. 그래서, 위 이미지에서는 "nil leaves" 나 "null leaves"를 표현하고 있는데, 이 "null leaf"는 위의 그림에서와 같이 자료를 갖지 않으며, 트리의 끝을 나타내는 데만 쓰인다. 트리 구조를 그림으로 표현할 때, 종종 이 "null leaf"를 생략하고 그리는 경우가 많은데, 그러면 그림상으로는 레드-블랙 트리의 특성을 만족하지 못하는 것처럼 보일 수 있으나 실제로는 그렇지 않다. 이렇게 함으로써, 모든 노드들은 설령 하나 또는 두개의 자식이 "null leaf" 일지라도, 두개의 자식(children)을 가지게 된다.
3. 힙 (Heap)
- 힙은 완전 이진 트리 기반의 자료 구조이다.
- 최소힙과 최대힙 두 가지가 있고, 해당 힙에 따라 특정한 특징을 지킨 트리를 말한다.
- 최소 힙의 삽입과 삭제 연산은 주로 우선순위 큐(Priority Queue)와 같이 최소값 또는 최대값을 효율적으로 관리해야 하는 경우에 사용된다.
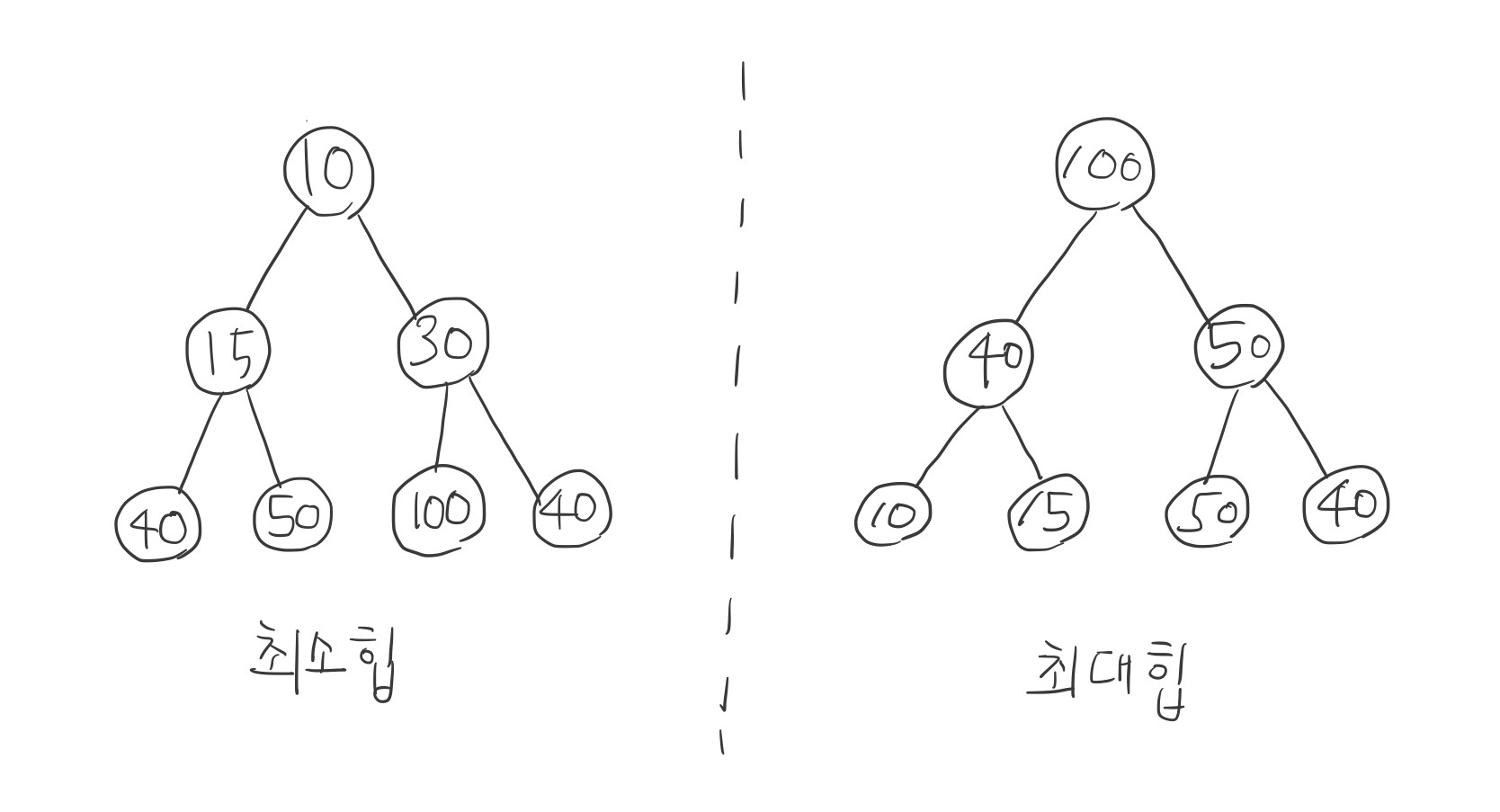
▼ 최소힙과 최대힙
!https://velog.velcdn.com/images/jiyaho/post/9abce36b-055a-4795-af65-4a87f837f721/image.jpg
{kind=link}
3-1. 최소 힙 (Min Heap)
- 최소힙에서 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 최솟값이어야 한다. 또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 한다.
3-2. 최대힙 (Max Heap)
- 루트 노드에 있는 키는 모든 자식에 있는 키 중에 최댓값이어야 한다. 또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 한다.
3-3. 동작 방식
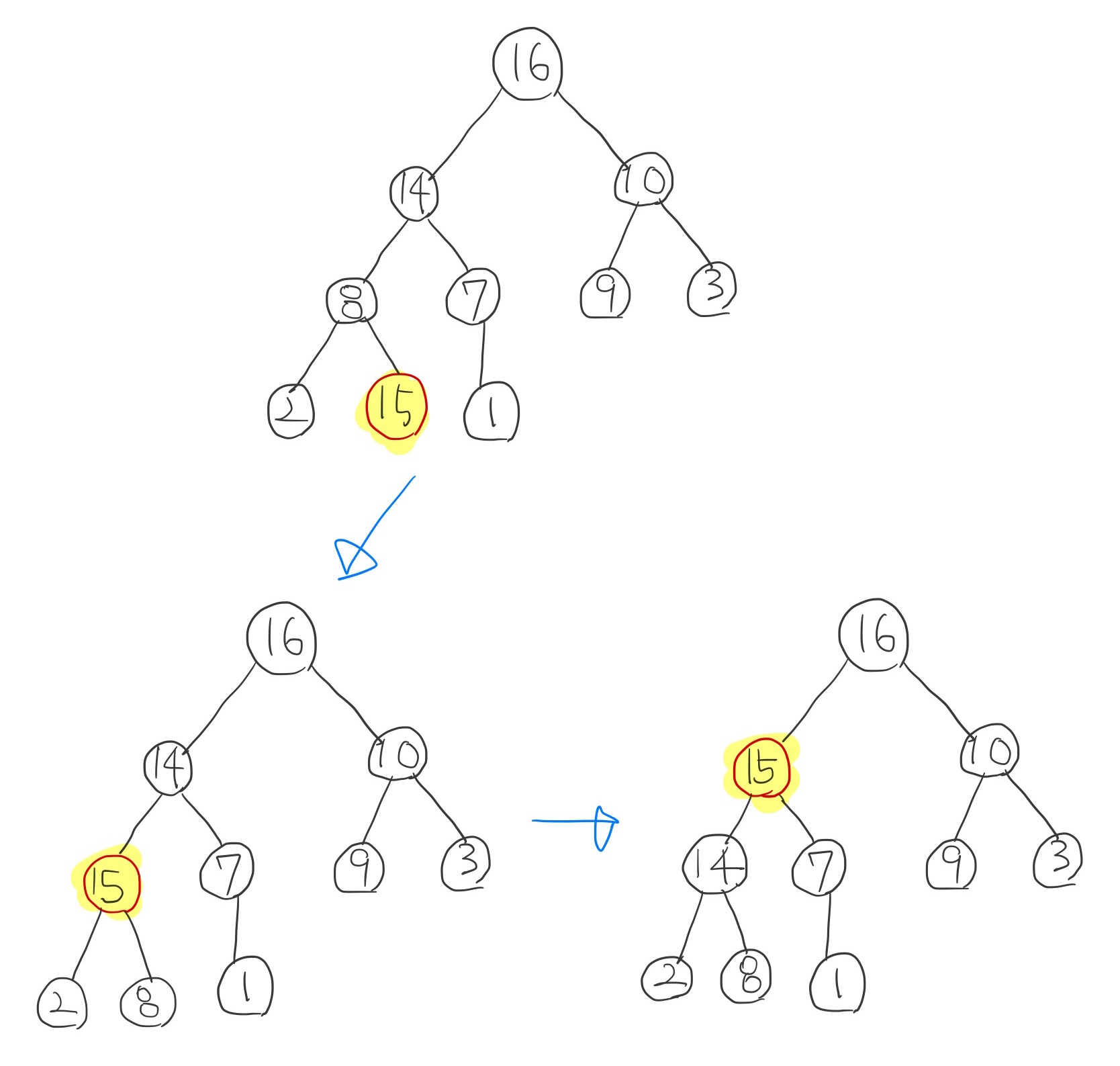
📌 삽입
- 새로운 노드를 트리의 마지막 노드에 추가한다. 이 새로운 노드를 부모 노드와의 크기를 비교한다.
- 최대 힙인 경우: 추가한 노드가 부모 노드보다 크면 자리를 바꾼다.
- 최소 힙인 경우: 추가한 노드가 부모 노드보다 작으면 자리를 바꾼다.
- 크기를 비교하여 스왑(swap)하는 작업을 힙의 성질을 만족시킬 때 까지 반복한다.
▼ 최대힙의 삽입
!https://velog.velcdn.com/images/jiyaho/post/6984df95-b38c-46cb-9406-02c36e30a26a/image.jpg
{kind=link}
📌 삭제
- 루트 노드에서 값을 제거한다.
- 마지막 노드를 루트 노드로 옮긴다.
- 자식 노드와 대소관계를 비교한다.
- 최대 힙인 경우: 자식 노드 중 더 큰 노드와 부모 노드의 자리를 바꾼다.
- 최소 힙인 경우: 자식 노드 중 더 작은 노드와 부모 노드의 자리를 바꾼다.
- 크기를 비교하여 스왑(swap)하는 작업을 힙의 성질을 만족시킬 때 까지 반복한다.
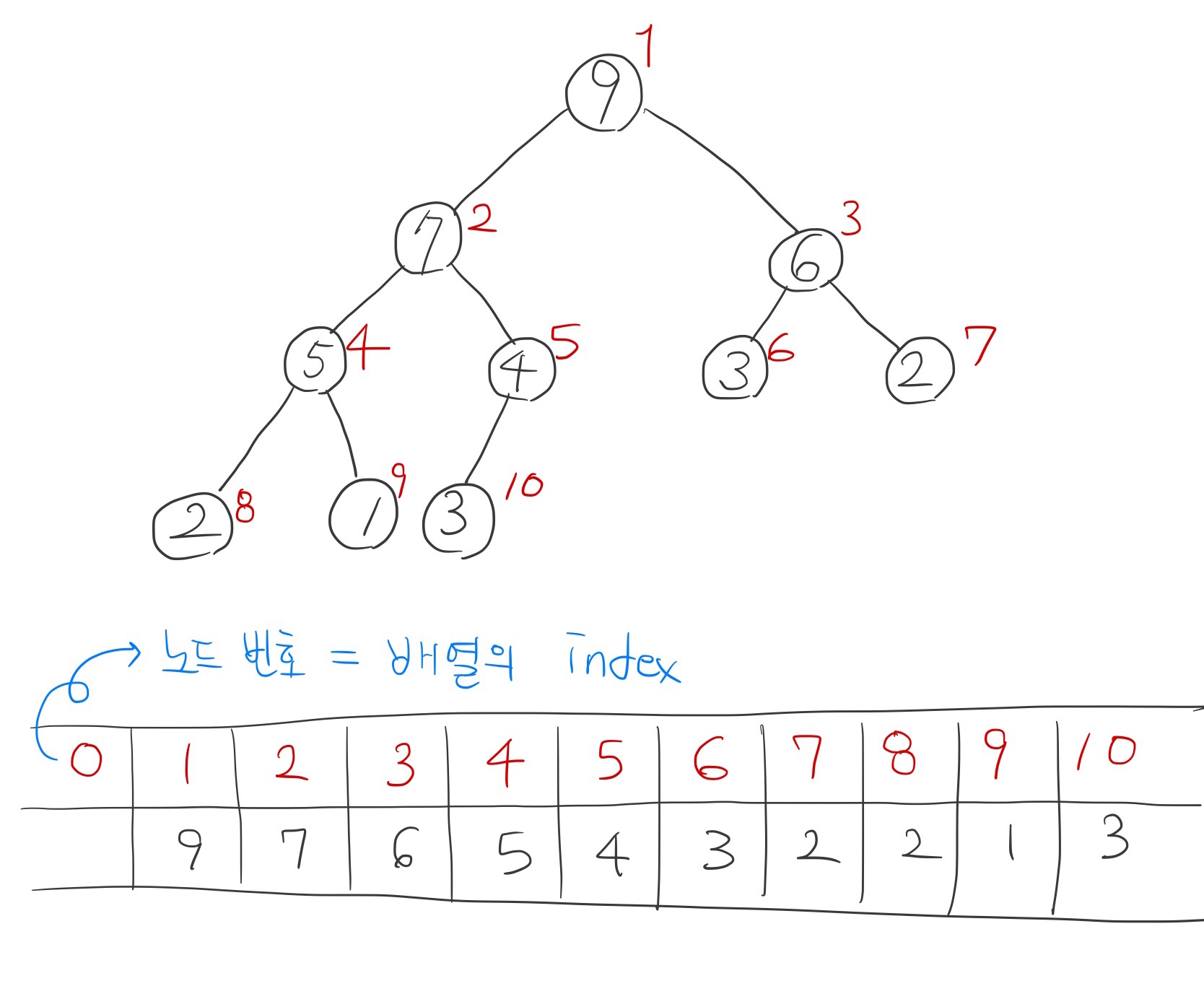
3-4. 힙의 구현
▼ 배열을 이용하여 구현한 힙
!https://velog.velcdn.com/images/jiyaho/post/0a3f3c21-33c2-44e5-a54a-984f81e089ae/image.jpg
{kind=link}
- 왼쪽 자식노드 index = (부모 노드 index) * 2
- 오른쪽 자식노드 index = (부모 노드 index) * 2 + 1
- 부모 노드 index = (자식노드 index) / 2
4. 우선순위 큐 (Priority Queue)
- 일반적인 큐(Queue)는 먼저 집어넣은 데이터가 먼저 나오는 선입선출(FIFO, First In First Out)의 구조로 저장하는 선형 자료 구조이다.
- 하지만 우선순위 큐는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 것을 말한다.
- 우선순위 큐는 우선순위 대기열이라고도 하며, 대기열에서 각 요소에 우선순위를 할당하고, 우선순위가 가장 높은 요소를 먼저 반환하도록 설계된 자료 구조이다.
- 우선순위 큐는 힙(heap)을 기반으로 구현된다.
4-1. 동작 방식
- enqueue(): 요소는 우선순위 큐에 삽입될 때 해당 요소의 우선순위에 따라 정확한 위치에 삽입된다. 일반적으로 우선순위가 높은 요소는 큐의 앞쪽에 위치하게 된다.
- dequeue(): 우선순위 큐에서는 주로 우선순위가 가장 높은 요소를 삭제하고 반환하는 연산이 수행된다. 이 연산을 "최소값 추출(Min Extract)" 또는 "최대값 추출(Max Extract)"이라고도 한다.
- peek(): Queue에서 최대 우선순위 요소를 반환한다. 최대 우선순위 값은 항상 루트에 있으므로 루트 값을 반환한다.
4-2. 시간 복잡도
| 구현 방법 | 삽입 | 삭제 |
|---|---|---|
| 배열 | O(1) | O(N) |
| 연결 리스트 | O(1) | O(N) |
| 정렬된 배열 | O(N) | O(1) |
| 정렬된 연결 리스트 | O(N) | O(1) |
| 힙 | O(logN) | O(logN) |
5. 맵 (Map)
- 맵은 특정 순서에 따라
키(key)와 매핑된값(value)의 조합으로 형성된 자료 구조, 즉 Key와 Value를 쌍으로 데이터를 저장하는 자료 구조이다. 'key' : 1과 같이string : int형태로 값을 할당해야 할 때, 해시 테이블(Hash Table)을 구현할 때 등 사용한다.- 레드 블랙 트리(Red Black Tree) 자료 구조를 기반으로 형성된다.
- Map은 Key를 사용하여 데이터를 검색, 추가, 삭제, 수정할 수 있으며, 각 Key는 고유해야 한다.
- 일반적으로 Map은 동적 크기를 갖는다. 데이터가 추가되거나 삭제될 때 자동으로 크기를 조절 및 정렬한다.
- Map은 데이터를 효율적으로 저장하고 검색하기 위해 해시 함수(hash function)를 사용한다.
- JavaScript의 Map은 ECMAScript 6 (ES6) 스펙부터 공식적으로 추가되었다.
5-1. 맵 - 프로그래밍 언어별 구분
- 해시 맵 (Hash Map 또는 Hash Table)
- 가장 일반적으로 "Map"이라고 불리는 자료 구조는 해시 맵 또는 해시 테이블이다. 이 자료 구조는 키-값(key-value) 쌍을 저장하고 검색하는 데 사용된다. 키를 해시 함수를 통해 해싱하고, 그 결과를 배열의 인덱스로 사용하여 값을 저장하거나 검색한다. JavaScript에서는 Map 객체가 이러한 해시 맵을 구현하는 데 사용된다. 삽입, 삭제, 검색 연산의 평균 시간 복잡도가 O(1)에 가깝다.
- Map에서 key로 사용 가능한 데이터 타입: 문자열, 숫자, 객체, 함수 등 다양한 데이터 타입을 키로 사용 가능하다. (cf. 자바스크립트에서 Object의 Key는 문자열과 Symbol(ES6부터 지원)만 사용할 수 있다.)
- C++ STL의 Map
- C++ 언어에서 "Map"은 키-값 쌍을 저장하는 자료 구조로, 레드-블랙 트리(Red-Black Tree) 기반의 자료 구조이다. 이는 키 값이 정렬되어 있으며, 검색, 삽입 및 삭제 연산의 시간 복잡도가 O(log N)이다. C++ 표준 라이브러리(STL)에서 std::map으로 구현되어 있다.
- Java의 Map 인터페이스
- Java에서 "Map"은 키-값 쌍을 저장하고 검색하는 인터페이스를 나타낸다. Java에서는 HashMap, TreeMap, LinkedHashMap 등과 같은 구체적인 구현체를 제공한다. HashMap은 해시 맵, TreeMap은 레드-블랙 트리를 기반으로 한 맵, LinkedHashMap은 링크드 리스트를 사용하여 순서를 유지하는 맵이다.
- Python의 딕셔너리(Dictionary)
- Python에서 "Map"은 딕셔너리(dictionary)로 구현되며, 키와 값의 쌍을 저장하고 검색하는 데 사용된다. 딕셔너리는 중괄호 {}를 사용하여 정의하며, 키와 값을 콜론(:)으로 구분한다.
5-2. 맵의 활용
- Map은 데이터를 저장하고 검색하는 데 빠르고 효율적이다. 예를 들어, 프로그래밍에서는 변수의 이름과 값을 연결하는 데 Map을 사용하거나, 데이터베이스 캐싱, 웹 애플리케이션에서 사용자 세션 관리, 빅데이터 처리, 그래프 알고리즘 등 다양한 분야에서 활용된다.
- 여러 프로그래밍 언어와 라이브러리에서 Map을 제공하며, 각각의 언어나 라이브러리에서 구현 및 활용 방법이 다를 수 있다.
5-3. 기본 Method (JavaScript 기준)
📌 삽입 (Insertion)
set(key, value): 새로운 키-값 쌍을 Map에 추가한다. 만약 이미 동일한 키가 존재하면 해당 키의 값을 갱신한다.
const myMap = new Map();
myMap.set('name', 'John');
myMap.set('age', 30);📌 검색 (Lookup)
get(key): 특정 키에 연결된 값을 검색한다.
const name = myMap.get('name'); // 'John'📌 삭제 (Deletion)
delete(key): 특정 키-값 쌍을 삭제한다.
myMap.delete('age'); // 삭제📌 크기 (Size)
size: Map에 저장된 키-값 쌍의 개수를 반환한다.
const size = myMap.size; // 1 (age 키가 삭제되었으므로 1개의 키-값 쌍만 남음)📌 존재 여부 확인 (Existence Check)
has(key): 특정 키가 Map 내에 존재하는지 확인한다.
const hasName = myMap.has('name'); // true
const hasAge = myMap.has('age'); // false📌 키 목록 및 값 목록 검색 (Key and Value Retrieval)
keys(): Map 내의 모든 키의 목록을 반환한다.values(): Map 내의 모든 값을 반환한다.entries(): Map 내의 모든 키-값 쌍을 [key, value] 형태의 배열로 반환한다.
const keys = Array.from(myMap.keys()); // ['name']
const values = Array.from(myMap.values()); // ['John']
const entries = Array.from(myMap.entries()); // [['name', 'John']]📌 모든 요소 제거 (Clear)
clear(): Map 내의 모든 키-값 쌍을 제거한다.
myMap.clear(); // 모든 키-값 쌍 제거📌 반복 (Iteration)
for...of와forEach메서드를 활용하여 Set 순회
const myMap = new Map();
myMap.set('name', 'John');
myMap.set('age', 30);
myMap.set('city', 'New York');
// for...of 반복문을 사용하여 Map 순회
for (const [key, value] of myMap) {
console.log(`${key}: ${value}`);
}
// forEach 메서드를 사용하여 Map 순회
myMap.forEach((value, key) => {
console.log(`${key}: ${value}`);
});6. 셋 (Set)
- 셋은 중복 요소가 없이 유일한 값을 저장하는 자료 구조이다.
- Map과 마찬가지로 JavaScript의 Set은 ECMAScript 6 (ES6) 스펙부터 공식적으로 추가되었다.
- Set은 순서를 보장하지 않으므로 요소가 추가된 순서대로 나열되지 않는다. Set은 중복 요소를 허용하지 않으므로 동일한 값을 여러 번 추가하더라도 하나의 값만 유지된다. 따라서 중복 요소를 효과적으로 관리할 때 사용된다.
- 셋에 추가된 데이터는 내부적으로 항상 객체로 저장된다. 셋은 원시 데이터 유형과 객체를 모두 저장할 수 있는 자료 구조이다. 셋은 각 요소를 구분하기 위해 데이터를 내부적으로 객체로 변환한다. 그러므로 원시 데이터 값이 Set에 저장되면 내부적으로 객체 형태로 변환된다.
6-1. 기본 Method (JavaScript 기준)
📌 삽입 (Insertion)
add(value): Set에 새로운 값을 추가합니다. 이미 Set에 존재하는 값을 추가하더라도 중복 값은 저장되지 않습니다.
const mySet = new Set();
mySet.add(1);
mySet.add(2);
mySet.add(3);
console.log(mySet); // Set { 1, 2, 3 }📌 삭제 (Deletion)
delete(value): Set에서 지정된 값을 삭제합니다. 삭제가 성공하면 true를 반환하고, 삭제할 요소가 없으면 false를 반환합니다.
const mySet = new Set([1, 2, 3]);
mySet.delete(2); // 삭제 성공, true 반환
mySet.delete(4); // 삭제 실패 (요소가 없음), false 반환
console.log(mySet); // Set { 1, 3 }
📌 크기 (Size)
size또는length프로퍼티: Set의 요소 개수를 반환합니다.
const mySet = new Set([1, 2, 3]);
console.log(mySet.size); // 3📌 존재 여부 확인 (Existence Check)
has(value): Set에 지정된 값을 가지고 있는지 확인합니다. 존재하면 true를, 존재하지 않으면 false를 반환합니다.
const mySet = new Set([1, 2, 3]);
console.log(mySet.has(2)); // true
console.log(mySet.has(4)); // false📌 모든 요소 제거 (Clear)
clear(): Set의 모든 요소를 삭제하여 빈 Set으로 만듭니다.
const mySet = new Set([1, 2, 3]);
mySet.clear();
console.log(mySet); // Set {}📌 반복 (Iteration)
for...of와forEach를 활용하여 Map 순회
// for...of 반복문을 사용하여 Map 순회
const mySet1 = new Set(['apple', 'banana', 'cherry']);
for (const item of mySet1) {
console.log(item);
}
// 출력:
// 'apple'
// 'banana'
// 'cherry'
// forEach 메서드를 사용하여 Map 순회
const mySet2 = new Set([1, 2, 3]);
mySet2.forEach((value) => {
console.log(value);
});
// 출력:
// 1
// 2
// 36-2. 셋(Set)과 배열(Array)의 차이
Set과 배열(Array)은 모두 값(데이터)의 컬렉션을 저장하는 자료 구조이지만, 몇 가지 중요한 차이점이 있다.
- 중복 요소의 처리
- Set: Set은 중복 요소를 허용하지 않는다. 즉, Set에 동일한 값을 여러 번 추가해도 중복 요소가 저장되지 않는다. Set은 값의 유일성을 보장한다.
- 배열: 배열은 중복 요소를 허용한다. 동일한 값을 배열에 여러 번 추가할 수 있다.
- 요소 순서
- Set: Set은 요소를 저장할 때 순서를 보장하지 않는다. Set에 추가한 순서대로 요소가 저장되지 않으며, 순서가 정해져 있지 않다.
- 배열: 배열은 요소를 저장한 순서를 유지한다. 즉, 배열에 요소를 추가한 순서대로 요소가 저장되며, 순서가 중요하다.
- 인덱싱
- Set: Set은 인덱싱(indexing)을 지원하지 않는다. 즉, Set에서 특정 위치의 요소에 직접 접근할 수 없다.
- 배열: 배열은 요소에 대한 인덱스를 사용하여 특정 위치의 요소에 직접 접근할 수 있다.
- 반복
- Set: Set은 forEach 메서드 또는 for...of 반복문을 사용하여 요소를 순회할 수 있다.
- 배열: 배열은 forEach 메서드, for...of 반복문, 또는 일반 for 반복문을 사용하여 요소를 순회할 수 있다.
- 메서드 및 기능
- Set: Set은 값의 유일성과 집합 연산을 지원하는 메서드(예: add, delete, has, clear)를 제공한다.
- 배열: 배열은 요소의 추가, 삭제, 검색, 정렬 등 다양한 메서드와 기능(예: push, pop, shift, unshift, sort, filter, map)을 지원한다.
6-3. 셋(Set)과 배열(Array)의 평균 시간 복잡도 비교
- 셋(Set)
add(value): O(1) (해시 함수를 사용하므로 해시 충돌이 적으면 O(1)이다.)delete(value): O(1)has(value): O(1)size 또는 length: O(1)
- 배열(Array)
push(value): O(1) (배열의 크기가 동적으로 조정되면 O(N)의 복잡도가 발생할 수 있다.)pop(): O(1)shift(): O(N) (모든 요소를 앞으로 이동해야 하므로)unshift(value): O(N) (모든 요소를 뒤로 밀어야 하므로)splice(): O(N) (삭제 또는 삽입하는 요소의 수에 따라 다르다.)
👉🏻 따라서 Set은 요소 추가, 삭제 및 확인 연산에서 일반적으로 상수 시간 복잡도 O(1)을 가지므로, 중복 요소를 허용하지 않고 요소 존재 여부를 빠르게 확인하는 데 적합하다.
👉🏻 배열은 요소의 순서가 중요하거나 동적 크기 조정이 필요한 경우에 유용하다. 예를 들어, 인덱스를 사용하여 특정 요소에 직접 접근하거나 요소를 정렬하거나 필터링하는 경우 배열이 유용하다.
7. 해시 테이블 (Hash Table)
- 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료 구조로 빠르게 데이터를 검색할 수 있는 자료구조이다. 매우 큰 숫자 데이터나 문자열과 같은 임의의 길이를 가진 Key값을 고정된 유한한 크기의 값으로 매핑한 테이블로, O(1)의 빠른 속도로 데이터를 찾을 수 있다.
- 해시 테이블은 해시 함수를 사용해서 변환한 값을 배열(버킷)의 index로 정하고 값을 저장한다.
- 해시 함수는 Key값을 받아 해시 함수를 사용하여 고정 크기의 해시 코드(해시 값)를 반환한다. 이 해시 코드는 배열의 index로 사용되어 값을 저장하거나 검색하는 데 사용된다. 여기서 실제 값이 저장되는 장소를 Bucket 또는 Slot이라고 한다.
- 해시 함수는 여러 종류가 있고, Key를 해시 코드로 변환하고 충돌을 최소화하기 위한 목적으로 설계 된다.
7-1. 해시 함수(Hash Function)의 종류
- Division Method (나눗셈 방법): 이 방법은 키를 테이블 크기로 나눈 나머지를 해시 코드로 사용한다. 즉,
hash(key) = key % table_size와 같은 형태로 표현된다. 이 방법은 간단하고 빠르지만, 특정 키 패턴에 대해서는 충돌이 발생할 수 있다. - Multiplication Method (곱셈 방법): 이 방법은 키를 0과 1 사이의 실수로 변환한 다음 테이블 크기를 곱한 후 정수 부분을 취한다.
hash(key) = floor(table_size * (key * A - floor(key * A)))와 같은 형태로 표현된다. 상수 A는 일반적으로 0보다 크고 1보다 작은 값을 사용한다. 이 방법은 좋은 분포를 제공하는데, 충돌을 최소화하는 데 도움이 된다. - Folding Method (접기 방법): 이 방법은 키를 일정한 크기의 부분 키로 나누고 이를 합하여 해시 코드를 생성한다. 예를 들어, 123456789을 12, 34, 56, 78, 9로 나누고 합쳐서 해시 코드를 생성할 수 있다.
- Mid-Square Method (중앙제곱 방법): 이 방법은 키를 제곱한 다음 중간 일부 자리를 선택하여 해시 코드로 사용한다. 예를 들어, 1234를 제곱하면 1522756이고, 여기서 중간의 3자리인 227을 해시 코드로 사용할 수 있다.
- SHA-1, SHA-256 등 암호학적 해시 함수: 보안이 중요한 경우, 암호학적 해시 함수를 사용할 수 있다. 이러한 함수는 충돌을 최소화하고, 무작위성과 안전성을 제공합니다. 하지만 일반적인 해시 테이블에 비해 계산 비용이 높을 수 있다.
!https://velog.velcdn.com/images/jiyaho/post/30364f4d-e419-4886-ba64-182137be90c7/image.svg
{kind=link}
7-2. 시간 복잡도
- 평균:
O(1), 최악:O(N) - 각각의 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균
O(1)의 시간복잡도로 데이터를 조회할 수 있다. - 하지만 데이터의 충돌이 발생한 경우 연결 리스트 또는 다른 자료 구조를 순회하여 검색해야 하므로 최악의 경우에는
O(N)까지 시간복잡도가 증가할 수 있다.
[참고링크]
- https://velog.io/@jiyaho/CS-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0%EC%9D%98-%EB%B6%84%EB%A5%98-%EB%B9%84%EC%84%A0%ED%98%95-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0%EA%B7%B8%EB%9E%98%ED%94%84-%ED%8A%B8%EB%A6%AC-%ED%9E%99-%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90-%EB%A7%B5-%EC%85%8B-%ED%95%B4%EC%8B%9C-%ED%85%8C%EC%9D%B4%EB%B8%94
- https://velog.io/@jiyaho/CS-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0%EC%9D%98-%EB%B6%84%EB%A5%98-%EB%B9%84%EC%84%A0%ED%98%95-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0-2-%ED%9E%99-%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90-%EB%A7%B5-%EC%85%8B-%ED%95%B4%EC%8B%9C-%ED%85%8C%EC%9D%B4%EB%B8%94
- https://velog.io/@jiyaho/CS-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0%EC%9D%98-%EB%B6%84%EB%A5%98-%EB%B9%84%EC%84%A0%ED%98%95-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0-3-%EB%A7%B5-%EC%85%8B-%ED%95%B4%EC%8B%9C-%ED%85%8C%EC%9D%B4%EB%B8%94
